Faster R-CNN(2016):通过区域提议网络实现实时目标检测,引入RPN再次对R-CNN创新
导出时间:2025/11/23 20:25:57
1、Faster R-CNN的背景和动机
1.1、 背景:Fast R-CNN 的瓶颈
虽然 Fast R-CNN 在速度和训练方式上比 R-CNN 有巨大提升,但它依然有一个严重的短板:
- 候选框生成(Region Proposal)太慢
- Fast R-CNN 仍然依赖 Selective Search 生成候选框。
- Selective Search 在 CPU 上跑,一张图要 2 秒左右,比检测网络本身还慢。
- 即使换更快的 EdgeBoxes,也要 0.2 秒/张,仍然拖慢整个检测流程。
- 不是完全端到端
- 候选框生成是“外包”的,和 CNN 特征提取、分类、回归是分离的。
- 导致检测系统还是“两段式”,效率低,无法充分利用 GPU。
👉 总结:Fast R-CNN 的速度瓶颈完全在“候选框生成”这一步。
1.2、动机:让“候选框”也交给 CNN
研究者(Shaoqing Ren、何凯明、Ross Girshick、孙健)思考:
- 既然 CNN 提取的特征已经很强大,那 能不能直接用 CNN 来生成候选框?
- 如果候选框生成和目标检测共享同一张特征图,就能把“检测”和“候选”统一起来,省去额外计算。
于是他们提出:
- 区域建议网络(RPN, Region Proposal Network)
- 在卷积特征图上直接生成候选框;
- 预测每个位置是不是目标,以及框的精确位置;
- 这一切都在 GPU 上完成,几乎是“零额外开销”。
👉 这样就避免了 Selective Search,整个检测系统终于可以 真正端到端:
输入一张图 → CNN 提特征 → RPN 出候选框 → Fast R-CNN 分类+回归 → 输出检测结果。
1.3、 一句话总结背景与动机
- 背景:Fast R-CNN 仍依赖 Selective Search 生成候选框,速度慢,不端到端。
- 动机:提出 RPN,让 CNN 自己学会生成候选框,与检测网络共享特征,实现 更快、更准、完全端到端 的目标检测。
2、Faster R-CNN 的核心创新点
2.1、区域建议网络(RPN, Region Proposal Network)
- 过去:R-CNN 和 Fast R-CNN 都依赖 Selective Search 这样的传统算法生成候选框,既慢又无法学习。
- 创新:Faster R-CNN 提出了 RPN,利用 CNN 特征图直接生成候选框。
- 在特征图的每个位置,RPN 会预测:
- 是否有目标(前景/背景分类);
- 边界框调整量(位置回归)。
- 在特征图的每个位置,RPN 会预测:
- 优势:
- 候选框生成速度从 秒级 → 毫秒级;
- 框的质量更好,可学习、可优化。
👉 相当于给检测网络配了一个“AI 助手”,不用再依赖外部工具。
2.2、Anchor 机制(多尺度/多比例的候选框)
- 问题:目标在图像里大小不一、长宽比差异大,单一大小的候选框难以覆盖。
- 创新:在特征图的每个位置,预定义 多尺度(不同大小)和多长宽比 的矩形框(称为 anchors)。
- 比如常见设置是 3 种尺度 × 3 种比例 = 9 个 anchor。
- 优势:
- 能灵活覆盖小目标、大目标、长条物体等不同情况;
- 不再依赖 Selective Search 的分割思路。
👉 就像在每个网格点上都备好多种尺寸的“捕捉网”,保证各种大小的猎物都能抓到。
2.3、特征共享:RPN 与检测网络共用卷积层
- 过去:候选框生成(Selective Search)和检测 CNN 各干各的,无法共享。
- 创新:RPN 和 Fast R-CNN 使用 同一张卷积特征图。
- 优势:
- 候选框生成几乎不增加额外计算;
- 检测速度大幅提升,实现真正的 端到端 训练和推理。
👉 就像安检时,行李只需要过一次扫描,既能标记可疑区域(RPN),又能分析内容(Fast R-CNN)。
3、Faster R-CNN 工作流程(结合图片)
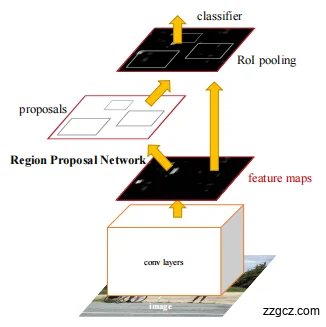
- 输入图像(image → conv layers)
- 一张原始图像输入网络。
- 经过深度 CNN(如 VGG16、ResNet)的卷积层处理,得到一张 特征图(feature map)。
- 这一步只计算一次,后面所有步骤都共享这张特征图。
👉 类比:用“X光机”把整张图扫描一遍,得到一张“影像图”。
- 区域建议网络(Region Proposal Network, RPN)
- 在特征图上滑动一个小窗口(3×3卷积),对每个位置预测:
- 这里是否可能有目标(前景/背景分类)。
- 如果有目标,框的位置需要怎么调整(边界框回归)。
- 每个位置会生成多个 anchor 框(不同大小、比例),这样能覆盖各种形状的目标。
- 最后输出若干个候选框(proposals)。
👉 类比:安检系统在X光图上,自动给你标出“可能有违禁品”的区域。
- RoI Pooling(固定大小特征)
- 候选框在特征图上大小不一。
- RoI Pooling 把每个候选框裁剪出来,并压缩成同样大小(比如 7×7)。
- 这样才能送入后续的全连接层。
👉 类比:无论行李大小,最终都要放进统一规格的托盘里检查。
- 分类器 + 边界框回归
- 每个候选框的固定特征向量送入全连接层。
- 分类器:判断它是什么类别(人?车?狗?还是背景?)。
- 边界框回归器:进一步微调框的位置,让边界更贴合目标。
👉 类比:安检员拿到托盘后,仔细分析:① 里面是什么;② 精确标出范围。
🌟 一句话总结(结合图)
这张图展示了 Faster R-CNN 的完整流程:
- 整图卷积(共享特征图) →
- RPN 生成候选框(替代慢速的 Selective Search) →
- RoI Pooling 统一大小 →
- 分类+位置微调(得到最终检测结果)。
方面
| R-CNN
| Fast R-CNN
| Faster R-CNN
|
候选框生成
| 使用 Selective Search(约 2000 个 RoI)
| 仍然使用 Selective Search(约 2000 个 RoI)
| RPN(Region Proposal Network)直接在特征图上生成候选框,替代 Selective Search
|
CNN 特征提取
| 每个候选框单独裁剪 → 输入 CNN 计算特征
| 整张图只过一次 CNN,得到共享特征图
| 与 Fast R-CNN 相同,整图共享卷积特征
|
候选框特征获取
| 直接裁剪图像区域送 CNN
| 在共享特征图上用 RoI Pooling 提取固定大小特征
| 与 Fast R-CNN 相同,使用 RoI Pooling(后续改进为 RoI Align)
|
分类器
| 用 SVM 分类
| 用 Softmax 分类
| 与 Fast R-CNN 相同,使用 Softmax 分类
|
边界框回归
| 单独训练一个线性回归器
| 融合进网络,多任务一起训练
| 与 Fast R-CNN 相同,但与 RPN 联合优化,整体更精确
|
训练方式
| 分三步:① 微调 CNN ② 训练 SVM ③ 训练回归器
| 端到端,多任务联合训练(分类+回归一起优化)
| 候选框生成 + 分类 + 回归统一端到端训练
|
存储开销
| 需要存储每个候选框的特征(上百 GB)
| 不存储中间特征,直接在 GPU 里处理
| 与 Fast R-CNN 相同,计算和存储更高效
|
速度
| 非常慢(几十秒/张图)
| 快很多(几百毫秒/张图)
| 接近实时(百毫秒级),大幅提升实际应用可行性
|
精度
| 提升了传统方法,但受限于效率
| 精度相当甚至更好
| 候选框质量更好,精度继续提升,检测更鲁棒
|
4、 Faster R-CNN 的缺陷
虽然 Faster R-CNN 已经比前两代强大很多,但依然不是“终极方案”,主要问题在:
- 速度依然不足 🐢
- 虽然比 Fast R-CNN 快很多,但 每张图还是需要数百毫秒(如 200~300ms),很难做到真正的实时(30fps+)。
- 对于视频监控、自动驾驶等需要高帧率的应用,仍然太慢。
- 结构复杂,部署困难 ⚙️
- 整个网络分两部分:RPN + 检测头,虽然共享特征图,但训练和部署仍然相对复杂。
- 对工业落地来说,不够轻量。
- 对小目标不够友好 🔎
- Anchor 机制虽然覆盖多尺度,但对极小目标、密集目标效果有限。
- 小目标容易被忽略或与背景混淆。
- 对实时性应用不友好 ⏱️
- 比如无人机检测、自动驾驶中的目标检测,需要快速响应(几十毫秒)。
- Faster R-CNN 更适合离线场景(科研、图像分析),实时性还是短板。
5、基于 Faster R-CNN 的改进方向
研究者们发现:Faster R-CNN 属于 两阶段检测器(two-stage detector),精度高但速度慢。于是,后来有了两个发展方向:
1️⃣ 改进两阶段方法(保持高精度)
- Mask R-CNN(2017)
- 在 Faster R-CNN 基础上增加 分割分支,实现 实例分割(检测+像素级掩码)。
- 代表方向:不仅检测框,还要得到物体的精确轮廓。
- Feature Pyramid Network (FPN, 2017)
- 引入特征金字塔,多尺度融合特征,更好地检测小目标。
- Cascade R-CNN(2018)
- 多阶段回归框,不断精修边界框,提高检测精度。
👉 这类方法特点:精度不断提升,但速度往往下降,更适合需要“极致精度”的应用。
2️⃣ 一阶段检测器(追求实时)
- YOLO 系列(You Only Look Once, 2016 起)
- 把目标检测当成一个回归问题,一次性预测出所有框和类别。
- 从 YOLOv1 → v5/v7/v8,逐步提升精度和速度,成为工业界最常用检测器。
- 特点:实时(甚至 >60 FPS)、端到端、部署简单。
- SSD(Single Shot MultiBox Detector, 2016)
- 在不同尺度的特征图上直接预测目标,兼顾速度和精度。
- RetinaNet(2017)
- 提出 Focal Loss,解决一阶段方法正负样本极度不平衡的问题。
👉 这类方法特点:牺牲部分精度,换取极高速度,特别适合自动驾驶、监控、移动端等实时应用