R-CNN(2014):用于精确目标检测和语义分割的丰富特征层次结构,两阶段检测开山鼻祖
导出时间:2025/11/23 20:25:18
1、R-CNN的背景和动机
一、R-CNN 出现之前的困境
在 R-CNN 出现前,计算机视觉中的目标检测主要依赖于 人工设计的特征(如 SIFT、HOG)加上传统分类器(如 SVM)。
- SIFT / HOG ——“手工做的放大镜”
你可以把 SIFT尺度不变特征转换(Scale-invariant feature transform ) / HOG 想象成 工匠手工打磨的放大镜:
- 它们能帮我们在图像里找到一些“关键点”和“方向”,比如边缘在哪里、轮廓朝哪边。
- 就好比你戴上一个“只能看清边缘的眼镜”,能看见物体的大概形状,但看不到更复杂的东西(比如纹理、颜色组合、抽象的特征)。
👉 所以,SIFT / HOG 只能捕捉很局部的低层次信息,像是“狗耳朵有个尖角”“车轮是圆的”,但没法很好地理解整体“这是只狗”或者“这是辆车”。
- DPM(可变形部件模型)——“拼装玩具机器人”
DPM 就像是一个 用零件拼装机器人的模型:
- 它会把一个物体拆成多个部分,比如“头、身体、四肢”,或者“车头、车身、车轮”。
- 每个部分用 HOG 特征来描述(比如“车轮是圆的边缘”)。
- 最后再把这些部分拼起来,判断是不是一个完整的物体。
这种方法在简单场景里还不错,就像拼乐高玩具时零件都很标准。
但在复杂场景下——
- 如果物体被遮挡(比如人被桌子挡住一半),某些零件找不到,就拼不完整。
- 如果物体姿态变化大(比如人转了个怪姿势),这些零件的位置和角度就不对了,模型就容易认错。
👉 所以,DPM 就像一个“靠拼装零件识别东西的机器人”,在理想情况下很聪明,但一旦环境复杂,就容易迷糊。
二、ImageNet 引爆深度学习
2012 年,AlexNet 在 ImageNet 图像分类比赛上大幅领先(错误率降低了近 10%)。它用 卷积神经网络(CNN) 自动学习图像特征,而不是人工设计。
- 这让大家看到:CNN 的特征远比 HOG、SIFT 更强大。
- 于是研究人员开始思考:既然 CNN 在分类任务上这么好,那能不能把它用于目标检测?
问题是:分类只要判断整张图片里是什么,而检测需要知道目标在哪里(位置 + 类别),难度要高很多。
三、R-CNN 的动机
R-CNN 的作者(Ross Girshick 等)正是从这个问题出发:
- CNN 怎么用来定位物体?
- 分类 CNN 只能输入固定大小的图片,输出一个类别。
- 但目标检测要在图像中找到多个不同大小和位置的目标。
- 如果直接用“滑动窗口 + CNN”方式(把窗口在图像里一个个滑过去),计算量极大,而且效果不好。
- 训练数据不足怎么办?
- CNN 是“高容量模型”,需要海量数据。
- 但是目标检测数据集(如 PASCAL VOC)很小,不足以直接训练一个大网络。
- 作者想到:先用 ImageNet 分类数据预训练 CNN,再在小数据集上微调,解决了数据不足问题。
四、R-CNN 的核心思路
于是 R-CNN 提出一个 折中方案:
- 先找“候选区域”(Region Proposals),比如一张图找 2000 个可能含目标的框。
- 把这些框送进 CNN 提取特征。
- 再用 SVM 分类器 判定这个框里是“人”、“车”还是“背景”。
这样就把 “分类 CNN” 和 “检测任务” 结合起来,既利用了 CNN 的强大特征,又避免了滑动窗口的计算灾难。
实验结果表明:R-CNN 在 PASCAL VOC 上的平均精度(mAP)比以前最好的方法提升了 20 个点以上,效果震惊了整个计算机视觉领域。
2、R-CNN 的核心创新点
🔑 核心创新点 1:区域建议(Region Proposals)
以前的做法:像个“笨巡警”,拿着放大镜在整张图片上滑动,一点点看是不是有目标(滑动窗口法),又慢又容易漏。
R-CNN 的做法:先用一个“聪明助手”给你推荐“可能藏人的地方”。
- 比如一张街景图,它会先提出大概 2000 个区域(可能是人、车、猫狗的位置)。
- 这叫 区域建议,相当于“缩小搜索范围”。
👉 创新点:不用在整张图傻傻乱扫,只在“更有可能的地方”去看,大大减轻计算量。
🔑 核心创新点 2:用 CNN 提取特征(而不是手工特征)
以前的做法:靠“手工特征”(HOG、SIFT),就像画家用简单线条描物体,但往往不够丰富。
R-CNN 的做法:把每个候选区域丢进一个已经在 ImageNet 上训练好的 CNN,让它提取深度特征。
- CNN 就像一个“有丰富经验的专家”,能自动学到边缘、纹理、形状,甚至更抽象的语义特征。
- 这样提取的特征,比手工特征要强得多。
👉 创新点:第一次把深度 CNN 引入目标检测,大幅度提升了识别能力。
🔑 核心创新点 3:预训练 + 微调(Transfer Learning)
问题:目标检测数据集(比如 PASCAL VOC)很小,直接训练 CNN 会过拟合。
R-CNN 的做法:
- 先在 ImageNet 分类任务上预训练 CNN(学到很多“通用知识”)。
- 再把这个 CNN 拿来在检测数据集上“微调”(Fine-tune),让它适应目标检测。
这就像:
- 先在“大学”学通用知识(ImageNet 预训练),
- 再去“警察学校”专门训练侦查技能(VOC 微调)。
👉 创新点:提出了 预训练+微调 的范式,解决了数据不足的问题,这个思路直到今天(例如 BERT、GPT)仍然在广泛使用。
🔑 补充小招式:SVM 分类 + 边界框回归
- CNN 负责提特征,最后用 SVM 来分类(人/车/猫…)。
- 为了让检测框更精准,作者还加了一个 边界框回归器,对框的位置做“微调”。 就像侦探拿放大镜先确定大概位置,然后再仔细调整到准确范围。
🌟 一句话总结
R-CNN 的核心创新点是:
- 区域建议 → 只看“可能有目标”的地方,不再全图乱扫。
- CNN 提特征 → 把深度学习真正引入检测,替代了手工特征。
- 预训练+微调 → 用大数据学“通用知识”,小数据学“专门技能”。
这三点结合,让 R-CNN 在当时的目标检测性能上实现了质的飞跃。
3、模型的网络结构
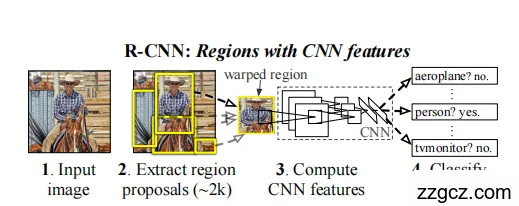
- Input image(输入图像)
- 就是一张普通的图片,比如你上传的牛仔骑马的场景。
- 任务目标:在这张图里找到“人”、“马”或者其他目标。
👉 相当于“侦探拿到一张案发照片”。
- Extract region proposals(区域建议,约 2000 个)
- 系统不会直接在整张图上乱扫,而是用一种方法(比如 Selective Search)生成大约 2000 个候选框。
Selective Search选择性搜索算法生成候选框
你可以把它想象成“先切碎,再拼合”:
- 初步分割图像
- 把原图像分割成很多小块(比如几十上百个超像素区域)。
- 每个小块可能是一点背景、物体的一角等等。
- 相似区域合并
- 算法会不断把“看起来相似的邻近区域”合并,比如颜色接近、纹理相似、边缘接壤。
- 这样就能逐步合并出一些“可能是物体”的大区域。
- 生成候选框
- 在这些合并出的区域外面画上矩形框,作为“候选区域”。
- 一般能得到大约 2000 个候选框,它们里头可能有目标,也可能只是背景。
- Compute CNN features(CNN 提取特征)
- 对每个候选框,先把它裁剪/变形到固定大小(比如 227×227),丢进 卷积神经网络(CNN)。
- CNN 会自动提取高层次的特征,比如边缘、形状、纹理、物体部件等。
- 结果是一个 特征向量(例如 4096 维),用来表示这个区域的“内容”。
👉 相当于“侦探拿放大镜仔细观察每个可疑区域,提炼出详细特征线索”。
- Classify regions(分类每个候选区域)
- 对每个候选区域的特征,送入 分类器(SVM) 判断:
- 是人吗?是/否
- 是马吗?是/否
- 是飞机吗?否
- …
- 同时,还有一个 边界框回归器,对框的位置进行微调,让目标框更精确。
它就像一个“修图助手”:
- 看一下现在的框和里面的内容;
- 决定:框要不要往左/往右移动一点,放大/缩小一点;
- 最后让框贴得更紧,更准确。
为了修正一个矩形框,其实只需要 4 种操作:
- 左右移动(框中心点往左/往右一点)。
- 上下移动(框中心点往上/往下一点)。
- 水平缩放(让框更宽或更窄)。
- 垂直缩放(让框更高或更矮)。
这 4 个动作的幅度,就是 回归器输出的 4 个数。
训练的时候:
- 算差值:系统先算出“候选框”和“真实框”的差别(比如:中心点差了 10 像素,宽度要放大 1.2 倍)。
- 作为学习目标:这些差值就变成了网络要学习的“正确答案”。
- 训练网络:网络会尝试输出 4 个数(预测的偏移量),并和真实的差值对比。
- 不断纠正:如果预测不准,就调整参数;训练多次后,网络学会了“看特征 → 输出合适的调整量”。
推理时(实际用的时候)
- 网络拿到候选框和它的特征,输出 4 个调整量。
- 根据这 4 个数,对候选框做“移动+缩放”。
- 最终得到一个更精准的检测框。
🌟 总结(结合图的直观理解)
- 第一步:拿到一张图。
- 第二步:挑出大约 2000 个可能的“嫌疑区域”。
- 第三步:每个区域丢进 CNN,提取深度特征。
- 第四步:用分类器判断区域里是什么,并微调位置。
最终结果:我们就能在图里准确框出“人”、“马”等目标。
4、模型的重大缺陷和未来基于此的改进模型
4.1、R-CNN 的重大缺陷
虽然 R-CNN 在当时算是革命性突破,但它也有明显的短板:
- 计算速度太慢 🚶♂️💨
- 一张图要生成大约 2000 个候选框。
- 每个框都要单独送进 CNN 计算一次特征。
- 在 CPU 上跑一张图可能要 几十秒,根本达不到实时检测。
👉 就像一个侦探,要对 2000 个嫌疑人逐个审问,效率极低。
- 训练复杂 😵
- 训练过程分三步: ① 先训练 CNN(预训练+微调), ② 再训练 SVM 分类器, ③ 最后还要训练边界框回归器。
- 这三步是分开训练的,流程复杂,不够端到端。
👉 就像“警察学院、侦查班、测量班”都分开训练,流程很繁琐。
- 存储开销巨大 💾
- 每张图大约 2000 个候选框,每个候选框都要存一份 4096 维特征。
- 数据量庞大,占用大量硬盘空间。
👉 就像侦探每次审问都要写长篇记录,堆满了档案室。
4.2、基于 R-CNN 的改进模型
研究人员意识到这些问题后,逐步提出了一系列改进模型,形成了“检测家族树”:
Fast R-CNN(2015)
- 改进点:
- 不再对 2000 个候选框逐个跑 CNN,而是整张图只跑一次 CNN,得到 特征图。
- 再从特征图上用 RoI Pooling 提取每个候选框的特征。
- 优势:速度快了一个数量级,训练也变成了端到端(CNN + 分类 + 回归一起训练)。
👉 类比:侦探先用无人机扫完整个案发现场(整图 CNN),再对嫌疑区域放大查看(RoI Pooling)。