RT-DETR(2024):在实时目标检测中,号称击败当时的YOLO ,DETR的重大的创新改进
导出时间:2025/11/23 20:30:09
1、RT-DETR 的研究背景与动机
YOLO 系列的优势与局限
YOLO 一直是实时目标检测的“代名词”。它的优势是:
- 速度快:单阶段检测,不像两阶段的 Faster R-CNN 需要 region proposal。
- 精度还不错:YOLOv5/7/8 在 COCO 上表现都很好,速度和精度平衡。
但是 YOLO 有一个“隐藏的瓶颈”——NMS(非极大值抑制)。
- 模型会生成大量候选框,这些框之间有重叠,就要靠 NMS 来筛掉。
- NMS 本质上是一个后处理步骤,不是端到端的,带来几个问题:
- 拖慢推理速度:尤其在小目标密集场景,大量候选框让 NMS 成为瓶颈。
- 依赖人工阈值:NMS 要设定置信度阈值和 IoU 阈值,不同场景下要调不同参数,结果不稳定。
- 速度与精度难两全:阈值设低 → 框多、速度慢;阈值设高 → 框少、容易漏检。
这就好像 YOLO 是一台高速打印机,能一下子“打印”出很多结果,但最后还要人工去“筛选”,这就拖了后腿
DETR 的优势与挑战
DETR(基于 Transformer 的检测器)带来了一个革命性的思路:
- 去掉 NMS:它直接用 匈牙利匹配 做一对一预测,每个 object query 负责一个目标。
- 端到端:输入图片 → 输出结果,中间没有复杂的手工设计。
但是 DETR 的问题也很明显:
- 计算成本太高:尤其是多尺度特征交互,序列太长,Transformer 编码器成为瓶颈。
- 训练慢:收敛速度比 YOLO 慢很多。
- 查询机制难优化:初始 query 的选择常常带来不确定性,导致检测不稳定
打个比方,DETR 就像是一个“全自动的智能系统”,它不需要你去手动筛选结果,但它太“耗电”,还反应慢,实时性差。
RT-DETR 的研究动机
研究者们想解决的问题很直观:
👉 能不能结合 YOLO 的快,和 DETR 的端到端优势?
于是提出了 RT-DETR(Real-Time DETR),目标是:
- 消灭 NMS 的拖累 → 保留 DETR 的端到端特性。
- 提升速度,满足实时应用 → 重新设计编码器,加快多尺度特征处理。
- 提升精度 → 用更聪明的查询选择方法,避免选到“模糊不清”的特征。
- 灵活性 → 通过调整解码器层数,不用重新训练,就能适配不同场景(比如无人机要快,医疗影像要精)。
最终效果:
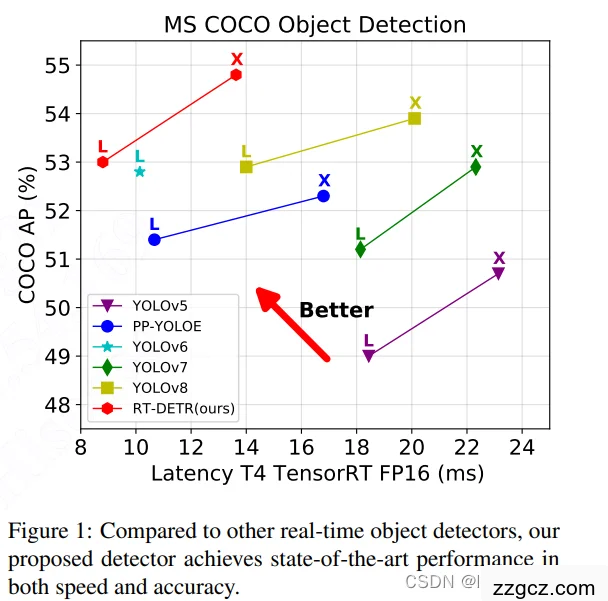
- RT-DETR 在 COCO 数据集 上,速度和精度都超过了 YOLOv8。
- 比如 RT-DETR-R50 在 T4 GPU 上跑到 108 FPS,比 DINO-DETR 快 21 倍,而且精度还提升了
✅ 形象化理解
- YOLO:像一个高速打印机,但要你自己拿剪刀(NMS)去修正结果。
- DETR:像一个全自动裁剪机,直接给你最终结果,但速度慢、能耗高。
- RT-DETR:像一个升级版的智能裁剪机,不仅省电,还能实时运行,自动把结果切得又快又准。
2、RT-DETR 的核心设计思路与创新点
1. 总体架构思路
RT-DETR 仍然是 主干网络 + 编码器 + 解码器 的 DETR 框架,但在关键地方动了“大手术”,目标就是——
👉 既要端到端(摆脱 NMS),又要快(满足实时)
研究者主要在两个方向发力:
- 快:解决计算瓶颈 → 提出高效混合编码器。
- 准:解决查询不确定性 → 提出最小不确定性查询选择。
- 灵活:速度精度可调节 → 通过调整解码器层数,不用重训,就能适配不同应用。
创新点一:高效混合编码器(Efficient Hybrid Encoder)
问题
原始 DETR 使用 多尺度 Transformer 编码器,虽然能增强语义,但代价是:
- 序列太长(每个尺度都展开拼接),
- 计算量暴涨,
- 编码器成了速度瓶颈
思路
作者发现:
- 高层特征(语义丰富)才值得用自注意力去做“同尺度交互”;
- 低层特征(细节多但语义弱)和高层交互反而冗余、会混淆。
于是提出一个“混合方案”:
- 同尺度交互(AIFI):只在高层特征上做 Transformer 注意力,提取物体之间的关系。
- 跨尺度融合(CCFF):低层特征用卷积方式和高层特征做融合,而不是全靠 Transformer。
就像一个工厂流水线:
- 高层部门开会(注意力机制),分析产品定位;
- 低层部门只负责把零件加工好(卷积融合),然后交给上层整合。
👉 这样一来,计算减少很多,速度大幅提升,同时精度还能提高
创新点二:最小不确定性查询选择(Uncertainty-Minimized Query Selection)
问题
DETR 里的 object queries 是关键,但怎么初始化这些 queries?
- 之前的方法通常用分类得分来选前 K 个特征。
- 但目标检测不仅要“分对类”,还要“定位准”。
- 如果只看分类分数,可能选到位置模糊的框 → 结果就不稳定
思路
RT-DETR 提出一个“最小不确定性”策略:
- 同时考虑 分类和定位,计算它们之间的差异(认知不确定性)。
- 选出 既分类可靠、又定位准确 的特征作为初始查询。
👉 这样解码器一上来就拿到“高质量的候选人”,减少了后期优化负担。
这就好比你组建一个足球队:
- 以前只看“进球能力”(分类分数),结果有人射门准但跑位差。
- RT-DETR 同时看“进攻+站位”综合能力,招进来的队员更靠谱,队伍磨合更快。
结果:平均精度(AP)显著提升
创新点三:解码器可调节(Flexible Speed-Accuracy Tradeoff)
思路
DETR 解码器是多层堆叠,每层都会 refine 一遍查询。
- RT-DETR 发现:用完全部层数,精度虽最好,但其实 中间层就已经很准了。
- 所以在推理阶段,可以只跑前 4~5 层,就能在几乎不掉精度的情况下提升 FPS。
👉 这就像一场考试:
- 学霸做到第 5 道题就能拿高分,没必要全做完。
- RT-DETR 给了用户“自由调速”的开关。
这样,无需重新训练,就能适配不同场景:
- 无人驾驶:宁可稍微牺牲精度,也要更快;
- 医疗检测:宁可慢一点,也要更准
总结
RT-DETR 的三大创新点:
- 高效混合编码器:解耦同尺度交互与跨尺度融合 → 又快又准。
- 最小不确定性查询选择:高质量初始 query → 精度更稳。
- 解码器可调节:灵活切换速度与精度,无需重训。
最终效果:
- 在 COCO 数据集 上,RT-DETR-R50 达到 108 FPS + 53.1% AP,
- 超越了同尺寸的 YOLOv8 和 DINO-DETR
3、RT-DETR 的“整机爆炸图”
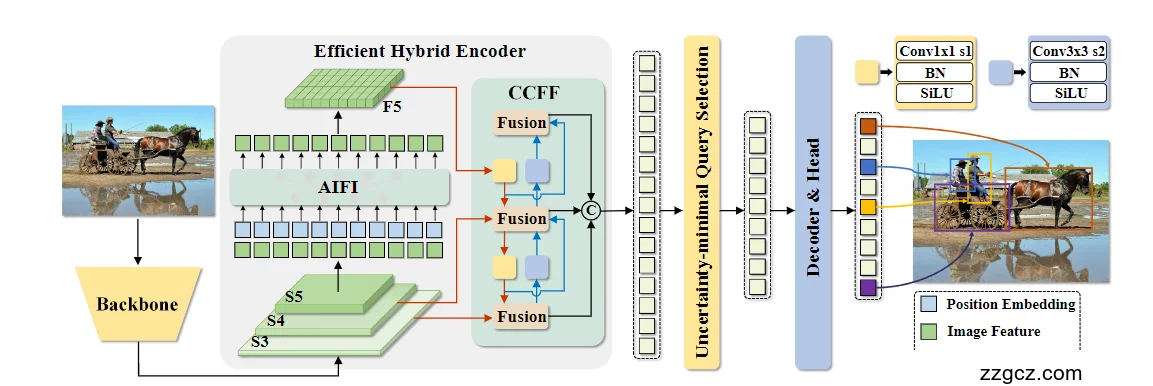
1. Backbone(左侧黄色块)
- 作用:提取多尺度特征。
- 输出:主干最后 三个阶段 S3 / S4 / S5(通常是 ResNet-50 或-101 的 stage3/4/5),作为后续编码器的输入。
- 动机:只取后三个高层特征,既保留语义、又控制序列长度,给实时性让路。
Efficient Hybrid Encoder(中间大绿色框)
这是 RT-DETR 的核心“加速器”,由两部分组成:AIFI(同尺度交互) 与 CCFF(跨尺度融合)。关键思想是:
👉 把“同尺度的关系建模”和“跨尺度的信息融合”解耦,分别用最合适/最省算力的模块去做,从而降低计算瓶颈、还把精度抬上去。
2.1 AIFI:Attention-based Intra-scale Feature Interaction(图中浅绿横条)
- 做什么:只在高层特征 S5 上做一次轻量的 Transformer 自注意力(图中 S5 → AIFI → 得到 F5)。
- 为什么:高层特征语义强、概念清晰,值得用注意力来建模对象间关系;而在底层做注意力既“费电”又容易引入噪声,所以不做。
- 数学形式(论文里给出):将 S5 展平成序列做 Q=K=V,经 AIFI 得到 F5,再还原形状。
- 2304.08069v3_translated
直观比喻:让“高层部门”开会(注意力讨论对象关系),底层只提供素材,不参与“高层会议”。
2.2 CCFF:CNN-based Cross-scale Feature Fusion(图中右侧“Fusion”纵向结构)
- 做什么:用卷积把 S3 / S4 与 F5 做跨尺度融合,形成统一的图像特征序列(图中蓝/黄小方块即融合块的 1×1-Conv 与 3×3-Conv,带 BN、SiLU;黑圈“⊕/C”表示逐级融合与拼接/展平)。
- 结构要点:每个“融合块”包含 1×1 卷积(调通道) + 若干 RepConv/3×3 复用块,沿路径逐级融合相邻尺度,最后得到融合后的表征。
- 为什么:跨尺度信息的“对齐/汇合”更适合用卷积做,又快又稳定;把注意力留给“同尺度的关系建模”,整体算力更省。
直观比喻:CCFF 像“物流分拣+组装线”(卷积),把不同尺寸的零件(多尺度特征)按工序接好,统一交付下一站。
Flatten + Position Embedding(图中绿色小格 + 位置嵌入图例)
- 将经过 AIFI+CCFF 的多尺度融合结果展平为连续图像 token 序列,并加入位置嵌入,为后续解码器提供“在哪儿”的线索。
Uncertainty-minimal Query Selection(黄色竖条)
- 做什么:从编码器输出中挑选 K 个(默认 300)“高质量”特征,作为解码器的初始 object queries(包含内容与位置两部分)。
- 关键:不是像以往那样只看分类分数,RT-DETR 同时刻画分类与定位的一致性,显式构造“不确定性 U”,选取 U 最小的特征做查询;这样“既分得准又定位准”的 token 才会被选中。
- 效果:减少“糊里糊涂的初始查询”,提高收敛质量与最终精度。
直观比喻:选队员不只看“会不会进球”(分类),还要看“跑位是否到位”(定位);招进来的都是“稳定发挥”的球员,整队磨合更快。
Transformer Decoder & Heads(蓝色竖条 + 右上角输出)
- 解码器:多层堆叠(默认 6 层),逐层迭代精炼这些 queries;每一层后接辅助预测头(分类 + 框回归),训练时层层监督,推理时可灵活裁剪层数。
- 可调速:实践发现,中后层的增益在变小,因此推理时可只跑前 4–5 层就能保持几乎相同的 AP,同时显著提速——无需重新训练。
- 端到端输出:采用 一对一集合预测(匈牙利匹配)训练,不需要 NMS,推理只用分数阈值做简单筛选。
直观比喻:每一层像一次“审稿迭代”,越到后面改得越少;着急上线时,可以提前定稿,速度立刻上来。
端到端流程(对照你的图,一行看懂)
- Backbone 提取 S3 / S4 / S5。
- AIFI:仅在 S5 上做注意力 → 得到 F5。
- CCFF:用卷积把 S3、S4 与 F5 逐级跨尺度融合 → 统一图像特征序列。
- Flatten + PosEmb:展平并加位置嵌入。
- Uncertainty-minimal Query Selection:从序列里挑 K=300 个不确定性最小的 token,作为初始查询(含内容与位置)。
- Decoder & Head:多层解码器迭代精炼,每层有辅助头;最终输出 类别与边界框,无需 NMS。
设计取舍与默认超参(便于你复现/对照)
- 典型主干:ResNet-50/101(ImageNet 预训练)。
- 查询数:300;解码器层数:6(推理可裁剪)。
- 训练 Recipe 基本沿用 DINO(优化器 AdamW、EMA、数据增强等)。
- 这套设计带来:实时(T4 上可达百帧)且端到端(无 NMS),同时 AP 提升。
4、RT-DETR 的主要缺陷
虽然 RT-DETR 在速度和精度上都超越了很多同类模型,但论文也明确指出了它的一些不足:
- 小目标检测性能不足 和其他 DETR 系列模型类似,RT-DETR 在检测小目标时仍然不如 YOLO 等强大的实时检测器。实验中,RT-DETR-R50 在小目标上的 AP 下降了约 0.5% ➡️ 原因是 DETR 类模型过于依赖全局注意力和较高层次特征,小尺度信息在编码器/解码器中容易被稀释。
- 精度仍落后于大型 YOLO 模型 与 YOLOv8-L 和 YOLOv7-X 等大模型相比,RT-DETR 的精度仍有差距(平均精度低 0.9% 左右),说明它在端到端优势和轻量化之间做了权衡
- 继承了 DETR 的一些通病 如训练依赖较大数据集,收敛虽然比原始 DETR 好,但相比 YOLO 仍不够快;此外,目标查询机制虽然改进,但在复杂场景下仍可能存在不稳定的问题
5、基于 RT-DETR 的后续改进模型
1. RT-DETRv2 ——“不改结构,白嫖收益”的升级包
怎么改:
- 在解码器的可变形注意力里,不同尺度各自用不同数量的采样点,更聪明地取多尺度信息;
- 提供一个离散采样算子替代
grid_sample,部署更友好(很多推理库/硬件对grid_sample不友好); - 训练侧加了动态数据增强和尺度自适应超参,不牺牲速度地提精度。 直观理解:像给旧车做“免拆升级”:胎压、火花塞、机油都换更合适的——跑得更稳、还不加油耗。 arXiv
RT-DETRv3 ——“训练期加料,推理零开销”的强化版
怎么改:
- 加了一个CNN 辅助分支,在训练期提供密集正样本监督,让编码器特征更扎实;
- 设计自注意力扰动的学习策略,给不同 query 组分配更丰富的正样本;
- 再加一个共享权重的解码器分支做密集监督;
- 以上模块只在训练期存在,推理时开销不变,但 COCO 上 mAP 明显涨。 直观理解:像给球队安排“分组对抗 + 加练”,正式比赛不增加负担,但整体战术素养更高。 arXiv
Drone-DETR(基于 RT-DETR 的无人机场景版)
怎么改:
- 面向超广角/复杂背景的航拍,提出 ESDNet 小目标增强网络:保留细节、减少冗余计算、整体更轻;
- 目标是提升小目标(远景目标、密集场景)的可检测性。 直观理解:相当于给 RT-DETR 换了“长焦镜头 + 去抖”,更擅长拍远处的小东西。 PMC
Small-Object-DETR(面向小目标的两点式加强)
怎么改:
- 提出细粒度路径增强:不仅用 backbone 最高层语义,还把低层细节(边缘/纹理)引进 Transformer;
- 提出自适应特征融合:给不同层级特征学得会的权重,多尺度融合更到位;
- 直接点名 RT-DETR 小目标偏弱的问题并对症下药。 直观理解:给“高层决策”补充“前线情报”,再配个会分配资源的“调度员”。 arXiv
Weather-Aware OD Transformer(面向雾天/恶劣天气的 RT-DETR 加强)
怎么改:
- 感知蒸馏的域自适应损失:学到“晴天/雾天都稳定”的表征;
- 天气自适应注意力:在注意力里加入“雾强度”相关的缩放;
- 双流融合编码器:清晰流 + 雾化流,最后再做跨流融合。 直观理解:给模型加了“防雾护目镜”和“晴雾双摄”,在坏天气也能看清。 arXiv
还有不少面向具体工业场景的改版也以 RT-DETR 为底座: • 钢铁表面缺陷检测的 MESC-DETR(在两个工业数据集上超 RT-DETR 的 mAP50)MDPI; • 印花布料缺陷的 RT-DETR-FFD(蒸馏 + 轻量结构,兼顾精度与速度)MDPI。
一句话对比
- v2:主要是“训练与部署友好化 + 采样细化”,属于白嫖提升;
- v3:只在训练期加料的密集正样本监督,推理零额外成本;
- 场景化改版(Drone/Small-Object/Weather/工业):围绕小目标、恶劣环境、行业数据做针对性加强。