RetinaNet(2018):密集目标检测的Focal Loss焦点损失,解决类别不平衡问题
导出时间:2025/11/23 20:26:42
1、背景
在目标检测领域,有两大类主流方法:
- 两阶段检测器(Two-stage detector)
- 代表模型:Faster R-CNN
- 思路:先在图片里找一堆可能有目标的位置(候选框),再对这些位置进行精细分类和边界框回归。
- 特点:准确率高,但结构复杂,速度慢。
- 单阶段检测器(One-stage detector)
- 代表模型:YOLO、SSD
- 思路:直接在密集的网格上预测目标的位置和类别,不需要“先提候选框”。
- 特点:速度快,结构简单,但准确率通常比不上两阶段检测器。
研究者们长期以来有一个疑问:
👉 能不能既快又准?
也就是让单阶段检测器的准确率追上甚至超过两阶段检测器。
- 难点:类别不平衡问题
单阶段检测器在训练时会遇到一个致命问题:
- 在一张图里,模型会生成成千上万个候选框(锚框)。
- 绝大多数是背景(负样本),只有极少数是真正的目标(正样本)。
- 比如比例可能是 1:1000。
这样会导致:
- 简单的背景样本太多,它们对损失函数的贡献远远大于少数难分的目标。
- 结果模型大部分时间都在学“背景”,对真正的目标学不好。
以前大家用一些“技巧”来缓解,比如:
- OHEM(在线困难样本挖掘):只挑难样本来训练。
- 采样比例:人为控制正负样本比例(如 1:3)。 但这些方法要么效率低,要么效果有限。
2、RetinaNet 的动机
RetinaNet 的作者(Facebook AI Research)发现:
- 单阶段检测器之所以不如两阶段,关键就在于类别不平衡。
- 于是他们提出了一个核心创新:焦点损失(Focal Loss)。
👉 焦点损失的作用:
- 自动降低“容易分类的负样本”的权重;
- 把训练精力集中在“困难样本”和“真正的目标”上。
这样一来:
- 单阶段检测器可以更高效地学习;
- 既保留了单阶段的速度优势,又大幅提升了准确率;
- 最终 RetinaNet 成功超越了当时所有的两阶段检测器。
✅ 小结: RetinaNet 的提出背景是——单阶段检测器快,但准度差;两阶段检测器准,但慢。它的动机就是通过焦点损失解决类别不平衡,让单阶段检测器既快又准,真正做到“鱼和熊掌兼得”。
3、RetinaNet 的灵魂——焦点损失 (Focal Loss)
回顾:普通的交叉熵损失 (Cross Entropy, CE)
在分类任务里,常用的损失函数是 交叉熵损失。问题来了:
在目标检测中,背景样本超级多,很多又都是“很容易分对的负样本”。
它们的损失加起来特别大,结果就“盖住了”真正难学的正样本。
👉 模型被迫花大量时间在“水很浅的题目”上,没精力学“难题”。
焦点损失 (Focal Loss) 的核心思想
焦点损失就是对交叉熵的一种改造:
👉 把简单样本的损失压小,把难样本的损失放大。
它在公式里加了一个调节因子:
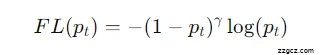
解释一下:
- pt:模型预测的正确类别的概率。
- (1−pt)γ:调节因子。
- γ:一个超参数,控制调节的强弱。
通俗举例
假设 γ=2,来看看效果:
- 容易样本:
- 比如一个背景框,模型预测“背景”的概率是 0.95,说明它很容易分对。
- 在交叉熵下,它还是有损失值。
- 在焦点损失下,因为 1−pt=0.05,再平方 → 变成 0.0025,损失直接缩小 400 倍!
- 所以这些简单背景样本几乎不影响训练了。
- 困难样本:
- 比如一个模糊的猫,模型只预测“猫”的概率 0.3。
- 这时候 1−pt=0.7,平方后还是 0.49,不会被缩小太多。
- 损失仍然比较大,模型会重点学习这些难样本。
类比理解
你可以把它想象成老师在布置作业:
- 普通的交叉熵 = 老师每天给你一堆简单题和少量难题,但批改时简单题也算很多分。你每天忙着做海量简单题,提升有限。
- 焦点损失 = 老师在算分时把简单题分值压低,把难题分值提高。这样你不会被简单题绑住,可以花精力啃难题,能力提升更快。
关键点
- γ=0 时,焦点损失就是普通交叉熵;
- γ越大,越强调“难样本”,越忽略“简单样本”;
- 实验表明,γ=2 效果最好。
✅ 小结: 焦点损失的原理就是 动态调节样本的权重:
- 容易分的样本 → 权重降低,影响几乎忽略;
- 难分的样本 → 权重保留甚至放大,让模型专注于学习它们。
这正好解决了单阶段检测器里“背景样本海量淹没目标”的问题,让 RetinaNet 既快又准
4、RetinaNet 的网络结构设计
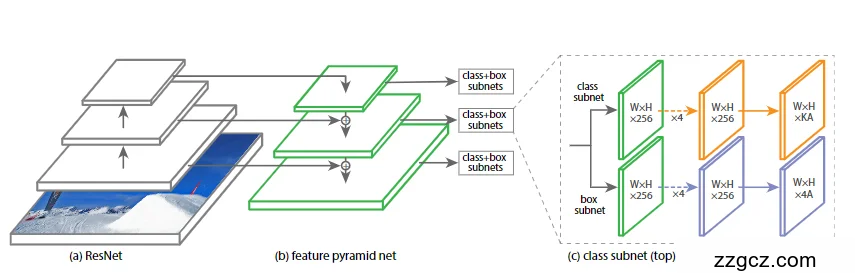
整体思路
RetinaNet 是一个 单阶段检测器,它的结构分为三部分:
- 主干网络(Backbone):用来提取图像特征。
- 特征金字塔网络(FPN):让模型能在多个尺度上检测不同大小的目标。
- 两个子网络(Subnets):
- 分类子网络(Class Subnet):判断目标类别。
- 回归子网络(Box Subnet):预测目标的边界框位置。
(a) ResNet(主干网络)
- 左边灰色的方块就是 ResNet,常用 ResNet-50 或 ResNet-101。
- 它的作用:对输入图像做卷积运算,提取出不同层级的特征。
- 低层特征:分辨率高,但语义信息少。
- 高层特征:语义信息强,但分辨率低。
(b) Feature Pyramid Network(特征金字塔网络,FPN)
- 图中绿色部分就是 FPN。
- 它把 ResNet 的不同层特征“融合”起来,构建一个 自上而下 + 横向连接 的结构:
- 自上而下:把高层的语义特征往下传递;
- 横向连接:结合低层的细节特征。
- 这样,每一层都能同时保留 “细节 + 语义”,就可以检测不同尺度的目标。
- 比如小目标用高分辨率层,大目标用低分辨率层。
(c) Class Subnet(分类子网络,右上绿色)
- 每一个特征层都会接上一个分类子网络。
- 结构:
- 输入:W×H×256 的特征图;
- 经过 4 个卷积层(每层 256 通道,带 ReLU 激活);
- 输出:W×H×(A×K),其中
- A:每个位置的锚框数量(通常 9 个);
- K:类别数(比如 COCO 里是 80)。
- 作用:预测每个锚框属于某个类别的概率(比如“猫”的概率 0.8)。
(d) Box Subnet(回归子网络,右下蓝色)
- 与分类子网络并行,输入同样是特征图。
- 结构:
- 也经过 4 个卷积层;
- 输出:W×H×(A×4),这里的 4 表示边界框的偏移量 (x, y, w, h)。
- 作用:预测每个锚框如何调整,才能更准确地包住目标。
- 总结(结合图像的整体流程)
- 图像输入 ResNet,提取多层特征。
- 通过 FPN 构建特征金字塔,每层都能检测不同大小的目标。
- 在每层特征图上:
- 分类子网络 → 判断“是什么”;
- 回归子网络 → 判断“在哪儿”。
- 最终得到所有目标的类别和位置,再经过 NMS(非极大值抑制)去掉重复框,输出检测结果。
✅ 一句话总结图示: RetinaNet = ResNet + FPN 提供多尺度特征,再加上 两个轻量子网络(分类 + 回归),用 焦点损失来解决类别不平衡问题,既快又准。
5、RetinaNet 的重大缺陷
- 计算量大,推理速度受限
- 虽然 RetinaNet 是单阶段检测器,但由于 特征金字塔 + 每层都预测 + 上万个锚框,计算量还是很大。
- 实际速度并没有像 YOLO 那样快,很多实时应用场景(自动驾驶、视频监控)不太够用。
- 锚框(Anchor)依赖严重
- RetinaNet 需要人为设计锚框(不同尺度、长宽比)。
- 锚框设计不合理会导致检测精度下降。
- 同时,锚框数量庞大,带来了 训练和推理的冗余计算。
- 对小目标检测仍不够理想
- 虽然用了 FPN 来处理多尺度,但小目标依然容易漏检。
- 这是因为小目标的信息在深层卷积里丢失严重。
- 焦点损失的超参数敏感
- Focal Loss 的 γ\gammaγ 和 α\alphaα 需要精心调节,迁移到新任务时往往要重新实验。
- 有时过度抑制简单样本,会导致模型训练不稳定。
6、后续模型的改进方向
研究者们围绕上述缺陷,提出了不少改进:
- 针对锚框的改进 —— “无锚框(Anchor-free)” 检测器
- FCOS (Fully Convolutional One-Stage Object Detection, 2019)
- 去掉了锚框设计,直接在特征图的每个像素点预测物体中心点和边界框。
- 减少了冗余计算,也让训练更简单。
- ATSS (Adaptive Training Sample Selection, 2020)
- 自动选择正负样本,减少了锚框分配时需要设定的 IoU 阈值。
👉 这些改进让检测器更高效、更易用,避免了 RetinaNet 对锚框的高度依赖。
- 针对速度和效率的改进 —— 更轻量化、更快
- YOLOv3、YOLOv4、YOLOv5/7/8
- 在速度和精度之间找到更好平衡,比 RetinaNet 更适合实时场景。
- EfficientDet (2019)
- 引入 BiFPN(加权双向特征金字塔),更高效地融合特征。
- 配合 EfficientNet 主干网络,在参数更少的情况下精度超过 RetinaNet。
- 针对小目标检测的改进
- NAS-FPN (2019)
- 用神经架构搜索自动寻找最优特征融合方式,比手工设计的 FPN 更强。
- DetectoRS (2020)
- 提出了 Recursive Feature Pyramid(递归 FPN),增强对小目标的检测效果。
- 针对焦点损失的改进
- GHM Loss (Gradient Harmonized Mechanism, 2018)
- 从梯度分布角度平衡简单样本和困难样本,而不是直接靠参数控制。
- Varifocal Loss (2020)
- 用预测质量(比如 IoU-aware)来调整样本权重,比 Focal Loss 更灵活。
👉 可以说,RetinaNet 是“承上启下”的经典模型:它解决了单阶段检测器精度不足的问题,但同时也暴露了锚框和效率的瓶颈,直接推动了 Anchor-free 和 EfficientDet 等新一代检测器的发展。