SSD(2016):多尺度检测
导出时间:2025/11/23 20:26:19
1、背景
在目标检测的发展中,Faster R-CNN 和 YOLOv1 是两条不同的路线:
- Faster R-CNN(两阶段检测器)
先生成一堆候选框(Region Proposal),再对这些框分类和回归。
- 优点:检测精度高,小目标识别能力强。
- 缺点:步骤多、计算复杂,即使加速后也只有几帧每秒,很难实时应用。
- YOLOv1(单阶段检测器)
把目标检测看作一个回归问题,一次性预测出目标的位置和类别。
- 优点:速度快,能做到实时。
- 缺点:精度比不上两阶段方法,尤其是对小目标、密集目标的检测不够好。
因此,当时的目标检测领域面临一个 两难选择:
- 要么选择 高精度但很慢(Faster R-CNN)。
- 要么选择 很快但精度不够(YOLOv1)。
2、动机
SSD(Single Shot MultiBox Detector)就是在这个背景下提出的,它的目标是:
👉 结合 Faster R-CNN 的高精度和 YOLO 的高速度。
具体来说:
- 像 YOLO 一样快
- SSD 也是单阶段检测器,不需要额外的候选框生成步骤。
- 整个检测过程就是一次前向传播,速度非常快(59 FPS)。
- 比 YOLO 更准
- 引入了 多尺度特征图:高分辨率特征图检测小目标,低分辨率特征图检测大目标。
- 使用了 不同长宽比的默认框(default boxes),提升了对目标形状和大小的适应性。
- 这样,SSD 在精度上不仅超过 YOLOv1,还接近甚至超越 Faster R-CNN。
✨ 一句话总结:
SSD 的动机就是想要 速度快得像 YOLO,精度高得像 Faster R-CNN,通过引入多尺度特征和默认框,找到了一个在速度与精度之间的平衡点,让目标检测真正走向实时落地。
3、SSD 的最核心创新点
- 多尺度特征图做检测
- 想象一下:YOLOv1 只用最后一张“模糊的大地图”找目标 → 小东西很容易看不清。
- SSD 不一样,它会在 不同清晰度的地图上同时找目标:
- 高清地图(前面的高分辨率层) → 擅长找小目标。
- 模糊地图(后面的低分辨率层) → 擅长找大目标。
- 启发:SSD 就像带了几副不同焦距的眼镜,看远处的大物体也行,看近处的小东西也行。
- 默认框(Default Boxes)
- Faster R-CNN:要先想“候选框”,再去筛选和修正,很慢。
- YOLOv1:直接把图像分网格,每个格子只能预测固定数量的框,灵活性差。
- SSD:聪明地在每个特征图位置放上一些 不同大小、不同形状的“默认框”,网络只需要在这些框的基础上稍微调整。
- 启发:就像在画布上先盖好一堆标准“印章”,模型只要挑选合适的印章,再微调一下位置和大小,就能快速得到目标框。
- 一次前向传播就完成检测(Single Shot)
- Faster R-CNN:两步走(先提框 → 再分类),速度慢。
- YOLOv1:一步走,速度快,但精度差。
- SSD:也是一步走,但因为结合了 多尺度特征图 + 默认框,所以 速度快 + 精度高。
- 启发:SSD 就像是“即使快递小哥只送一次货,但他同时带上了大箱子和小包裹,能兼顾各种需求”。
一句话总结
SSD 的核心创新点就是:
👉 在不同分辨率的特征图上同时检测目标 + 在每个位置放不同形状的默认框。
这样,它既比 YOLO 更准,又比 Faster R-CNN 更快。
4、 SSD 默认框(Default Boxes)
- 你可以把 默认框 理解成 一堆预先摆好的“候选模子”。
- 在 SSD 中,每个特征图位置(相当于“网格点”)都会预先放置几个框,这些框有:
- 不同大小(尺度):有的大,有的小。
- 不同形状(长宽比):有的长条形,有的正方形,有的扁平矩形。
👉 网络不需要凭空“创造”边界框,而是只要回答:
- “这个默认框里有没有目标?”
- “如果有,需要把它挪动/拉伸多少,才能更贴合目标?”
这样一来,检测就变成了 选择+微调,比从零开始找目标框要容易得多。
- 怎么选择默认框?
默认框的设计是 SSD 的关键之一,它考虑了 尺度 和 长宽比:
- 尺度(大小)
- SSD 在不同层的特征图上设置不同大小的默认框。
- 比如:
- 在高分辨率的特征图放小框 → 负责找小目标。
- 在低分辨率的特征图放大框 → 负责找大目标。
- 这样就自然形成了 多尺度检测。
- 长宽比(Aspect Ratios)
- 在每个特征点位置,SSD 通常会设置几种常见的长宽比:
- 比如:1:1(正方形)、2:1(长方形)、1:2(扁长条)。
- 这样无论目标是人(细长形)、汽车(长方形)、动物(接近正方形),都有一个默认框和它的形状比较接近。
- 在每个特征点位置,SSD 通常会设置几种常见的长宽比:
👉 默认框的这些尺度和长宽比是 人工设定的(论文里推荐的组合),不是模型自动学出来的。
- 为什么这样设计有效?
- 如果没有默认框,模型要学会“凭空”预测出目标的大小和形状,难度太高。
- 有了默认框,模型就好比“先有一堆积木模子”,它只需要在这些模子的基础上稍微挪动和缩放,就能快速贴合目标。
- 这种设计大大减轻了学习难度,提高了检测速度和精度。
5、 模型的网络架构
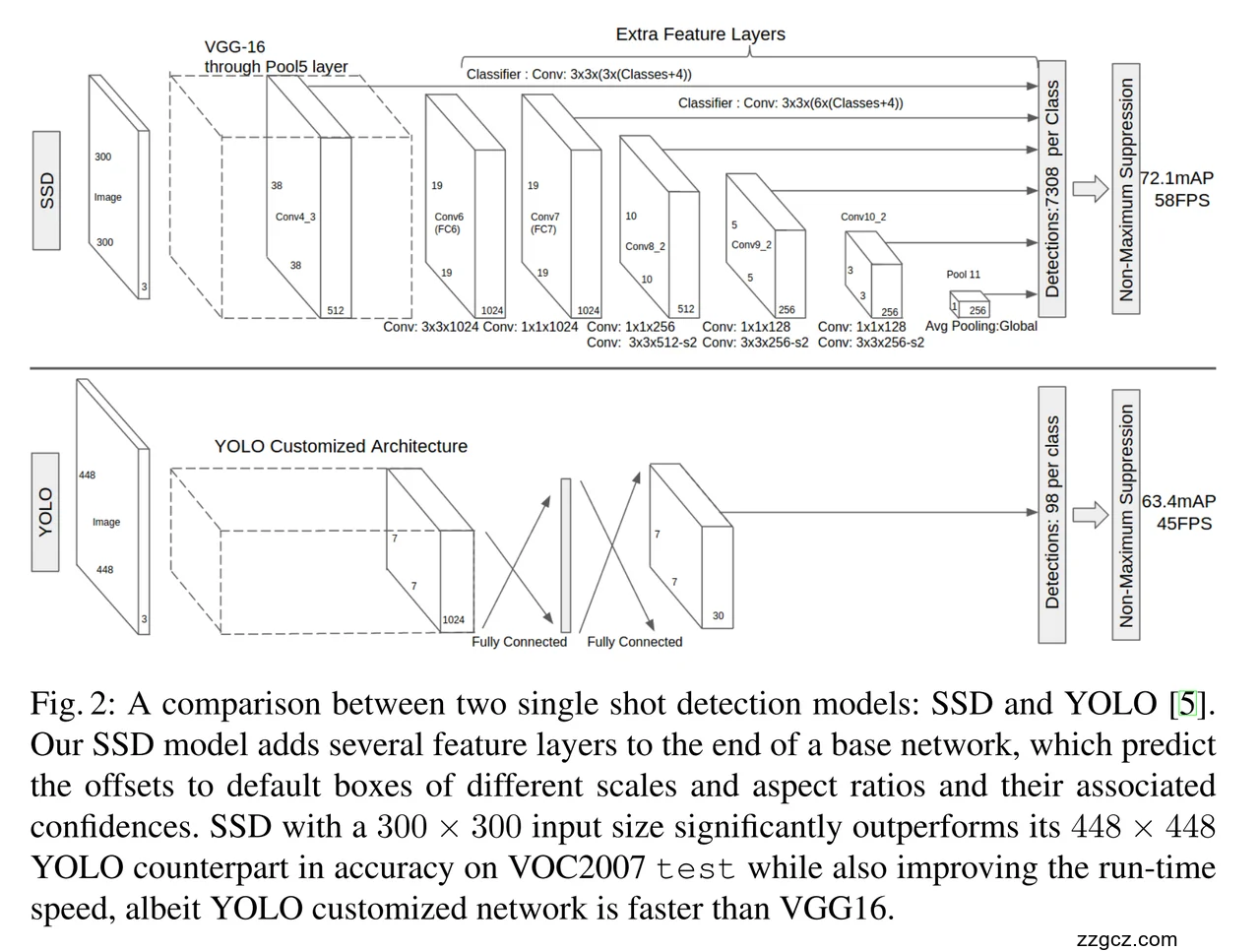
输入图像
- SSD:输入是 300×300 的图片。
- YOLOv1:输入是 448×448 的图片。 👉 虽然 YOLO 输入图像更大,但 SSD 用 300×300 也能得到更高的精度。
骨干网络(特征提取)
- 你可以把骨干网络想成一个“特征提取工厂”。
- 一张输入图片(比如 300×300)进去,经过好多层卷积,最后变成一堆“特征地图”。
- 这些特征地图就像不同清晰度的“显微镜下的画面”:
- 前面层(高分辨率) → 细节很多,适合看小东西(比如猫眼睛、螺丝钉)。
- 后面层(低分辨率) → 更抽象,适合看大东西(比如整辆车、整个人)。
👉 这就是 多尺度特征图 的来源。
- YOLOv1:用了自己定制的 CNN 架构,最后输出的是 7×7 的特征图(图中标出来)。
默认框(Default Boxes)
- 在每个特征图的位置上,SSD 先放一堆“预设的模子”(不同大小、不同长宽比)。
- 模子可能是:正方形、长方形、瘦长条、大框、小框。
- 模型的任务就是回答:
- 这个模子里面有没有目标?
- 如果有,模子要稍微挪一挪、放大缩小一下,才能更贴合?
👉 就好像你在一张纸上要画各种形状的框,如果凭空画很难,但如果先有几个模子(印章),你只要“盖章 + 修一修”就很快了。
- YOLOv1:每个格子只能预测固定的几个框 → 灵活性不足。
👉 直观理解:YOLO 就像“每个格子只能放固定的两种印章”;SSD 是“在每个格子里放六七种印章(大、小、胖、瘦都有)”,更适应各种目标。
预测层(分类 + 回归)
- SSD:在每一层特征图上,都接两个小卷积:
- 一个预测类别(是不是车?是不是狗?)。
- 一个预测位置偏移(框要往哪儿挪、缩放多少)。
- 图里写的 Conv: 3×3×(Classes各个类别的概率(比如车、狗、猫、人…)+4边界框的 4 个坐标偏移量(cx, cy, w, h)) 就是这个意思。
- 最后 SSD 会在 7308 个默认框 上同时做预测(图右侧标注)。
- YOLOv1:在 7×7 特征图上,用全连接层预测固定数量的框(图里标注:每类只有 98 个预测,7×7 = 49 个网格。每个网格预测 2 个边界框。)。
输出与后处理
- SSD:从所有特征层收集预测结果,一次性得到上千个候选框,然后用 非极大值抑制(NMS) 合并掉重复框,输出最终结果。
- YOLOv1:输出的框数本身比较少(98个/类),靠全连接直接预测 → 精度受限。
性能对比(图右侧数据)
- SSD (300×300):
- 72.1 mAP(检测精度更高)。
- 58 FPS(速度快,接近实时)。
- YOLOv1 (448×448):
- 63.4 mAP(精度低很多)。
- 45 FPS(虽然也快,但不如 SSD)。
👉 直观理解:YOLO 就像一个跑得快的短跑选手,但眼神不好,小目标看不清;SSD 是一个戴着多副眼镜的侦查兵,不仅跑得快,还看得准。
6、SSD 的重大缺陷
- 小目标检测差
- 原因:
- 虽然 SSD 用多层特征图来检测不同尺度,但早期的高分辨率特征层(如 Conv4_3)语义信息比较弱,不够聪明。
- 结果就是:小物体(如远处的行人、交通标志)容易漏检。
- 默认框设计固定、不灵活
- SSD 的默认框(default boxes)是人工预设的(几种长宽比、固定尺度)。
- 问题:数据集如果和这些框的分布差很多 → 检测效果会受限。
- 类比:你准备了几种“模子”,但是如果真实目标的形状/大小和模子差很多,就很难匹配。
- 难以处理密集目标
- YOLOv1 只能预测 98 个框,而 SSD 虽然能预测几千个框,但在同一区域如果有很多重叠目标(如人群、车流),仍然会混淆。
- 类比:你有很多钥匙(默认框),但一旦一堆锁挤在一起,你还是会分不清哪把钥匙该开哪把锁。
- 特征利用不够好
- SSD 虽然用多层特征图,但层与层之间基本是独立预测。
- 它没有像后来的模型那样“融合”高层的语义和低层的细节 → 表达能力有限。
7、基于 SSD 的后续改进模型
7.1、RetinaNet
- 解决问题:前景-背景样本极度不平衡(大多数默认框是背景)。
- 改进方法:提出 Focal Loss,降低容易分类的负样本权重,让训练更关注难样本。
- 类比:老师不会给学生重复“1+1=2”这样的题,而是专注训练学生不会的难题。
7.2、YOLOv2 / YOLOv3 / YOLOv4 …
- 解决问题:
- SSD 里的默认框设计不灵活 → YOLOv2 引入 Anchor Boxes(数据驱动的框形状)。
- 多尺度特征利用不足 → YOLOv3 借鉴 FPN,在不同层级特征上检测。
- 类比:YOLO 系列借鉴了 SSD 的“多层检测”思想,但改进了框和损失函数设计。
7.3、EfficientDet
- 解决问题:特征融合和模型效率。
- 改进方法:提出 BiFPN(双向特征金字塔),并且用复合缩放策略(backbone/neck/head一起缩放)。
- 类比:SSD 就像只用了一根简单的水管连层;EfficientDet 是给它装上了水泵和过滤器,让水在各层之间流动更充分。