Sparse R-CNN(2021):基于可学习提议的端到端目标检测,稀疏候选框,Query-based 思路
导出时间:2025/11/23 20:29:20
1、Sparse R-CNN 的研究背景与动机
背景一:目标检测长期依赖“密集候选框”
在传统的目标检测方法中,核心流程往往需要生成大量候选框(dense proposals),比如:
- 一阶段检测器(YOLO、RetinaNet):直接在特征图的每个位置、每个尺度上预设数十万的锚框(anchor),再预测目标边界框和类别。
- 二阶段检测器(Faster R-CNN):虽然最终只保留几百个候选框,但最初依然要从密集锚框里筛选,再经过 RPN(Region Proposal Network)过滤。
这种“密集先验”方式虽然有效,但也有明显弊端:
- 计算冗余大:数十万候选框大多数都是无效的,需要后续大量筛选。
- 依赖手工设计:锚框的数量、尺度、长宽比等超参数需要人工精调,迁移到新任务时往往需要重新设计。
- 需要后处理:密集预测通常产生冗余结果,因此必须依赖 NMS(非极大值抑制) 来去除重叠框。
- 训练复杂:多对一的标签分配策略复杂,网络依赖启发式规则来确定正负样本
背景二:端到端稀疏检测的尝试(DETR)
近年来,DETR(Detection Transformer) 提出了一种新范式:
- 把检测任务转化为 集合预测(set prediction);
- 使用少量(如 100 个)learnable queries 与全图特征交互;
- 可以直接输出最终预测结果,无需 NMS 或手工设计锚框。
但 DETR 存在问题:
- 训练收敛极慢(通常需要 500 个 epoch,远高于传统 R-CNN 系列);
- 每个 query 必须与全局特征交互,导致计算量大,不算真正意义上的“稀疏”方法
动机:能否构建真正的“纯稀疏”检测器?
Sparse R-CNN 的提出正是为了回答这个问题:
- 我们能否 完全抛弃密集候选框,直接用少量(如 100 个)可学习的稀疏候选框来完成检测?
- 能否设计一种架构,既不依赖手工锚框,也不需要全局密集交互,却依然能达到主流检测器的精度?
Sparse R-CNN 的核心思路:
- 用 固定数量的可学习候选框(learnable proposals)替代 RPN 或锚框。
- 每个候选框自带一个特征向量(proposal feature),用于驱动“动态预测头”。
- 整个流程从输入到输出保持稀疏化:
- 输入是有限的候选框集合;
- 输出直接是目标预测,无需 NMS 后处理。
✅ 一句话总结: Sparse R-CNN 的研究动机是要摆脱密集锚框与复杂后处理的束缚,提出一种真正稀疏、端到端的目标检测方法,在效率和精度之间取得更优的平衡。
2、Sparse R-CNN 的核心创新点总结
1. 稀疏候选框(Sparse Proposals)
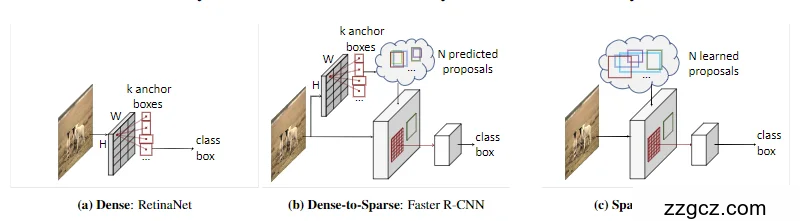
- 传统检测器:Faster R-CNN 用 RPN 生成数千候选框;YOLO/RetinaNet 直接基于数十万锚框预测。
- Sparse R-CNN:直接定义一个 固定数量(如 100 个)的可学习候选框,这些候选框在训练中不断更新,最终学会覆盖不同的目标。
- 意义:彻底摆脱了 anchor 的依赖,避免人工设计锚框的复杂性,也减少了大量冗余计算。
Proposal Feature + 动态预测头(Dynamic Head)
- 每个候选框不仅有坐标,还携带一个 proposal feature(可学习特征向量)。
- 这个特征向量驱动一个 动态预测头(dynamic instance interactive head),来生成分类和回归参数。
- 对比:传统检测器的预测头参数是共享的,而 Sparse R-CNN 让 每个候选框都有专属预测头,使得检测更加灵活、针对性更强。
迭代精炼(Cascade-like Refinement)
- Sparse R-CNN 将多个动态预测头 串联起来,类似级联检测器(Cascade R-CNN)。
- 每一阶段都会基于上阶段的输出进一步 refine 候选框和特征。
- 优势:提高定位精度,减少一次性预测的误差累积。
Query-based 思路(与 DETR 的关系)
- DETR:query 是“内容查询”,需要和全局图像特征交互(注意力机制),训练收敛慢。
- Sparse R-CNN:query 就是 proposal + feature,更直接、更高效,不需要全局密集 attention。
- 改进:保留了 query-based 的简洁性,同时解决了 DETR 的训练收敛慢问题。
真正端到端(NMS-free)
- Sparse R-CNN 输出的预测数量固定(如 100 个),每个目标由不同 query 表示。
- 无需 NMS 来去重,因为不同 proposal 已经在训练过程中被学习到负责不同目标。
- 对比:YOLO、Faster R-CNN 等仍然依赖 NMS 来消除冗余框。
✨ 总结一句话
Sparse R-CNN 的核心创新点是:
👉 用 少量可学习稀疏候选框 代替传统密集 anchor,结合 proposal feature + 动态预测头 和 迭代精炼,实现了 真正稀疏、端到端、NMS-free 的目标检测。
它相当于在 Faster R-CNN 的两阶段思路 和 DETR 的 query-based 思路 之间找到了一种更高效、更优雅的折中。
3、Sparse R-CNN 网络架构详解(结合图示)
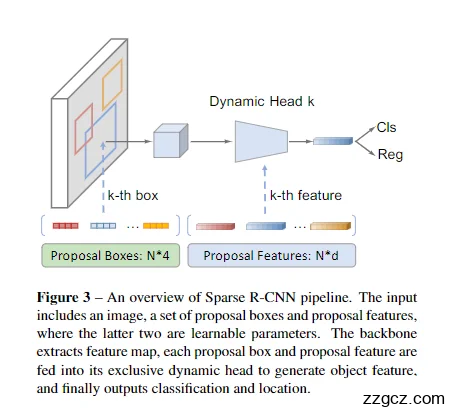
1. 输入:固定数量的候选框 + 特征向量
- 在传统 YOLO 或 Faster R-CNN 里:候选框是密集的(成千上万个锚框)。
- 在 Sparse R-CNN 里:一开始就只有 固定数量的候选框(比如 100 个),就像是提前准备好的“100 个探测器”。
- 每个候选框还带有一个小小的 特征向量(proposal feature),可以把它想象成“候选框的个性化说明书”,告诉网络这个框应该怎么去找目标。
👉 类比:
你派出 100 个“侦探”(候选框),每个侦探手里都有一张任务卡(特征向量),任务卡会指导他应该更关注图像里的哪部分。
Backbone 特征提取
- 输入图片先通过 Backbone(ResNet 或其他卷积网络)生成一张特征图,就像是把整张图分解成“语义地图”。
- 所有候选框和它们的任务卡,会从这张地图里抽取对应的信息。
👉 类比:
一张城市地图(特征图)生成后,每个侦探根据自己手里的任务卡,去地图上找相关区域的信息。
动态预测头(Dynamic Head)
- 图中右边的 Dynamic Head k 就是每个候选框专属的小脑袋。
- 不同于 YOLO 或 Faster R-CNN 那种 共享的预测头,Sparse R-CNN 给每个候选框配备一个 动态预测头:
- 输入:候选框坐标 + 特征向量;
- 输出:两个东西
- 分类结果(Cls) → 这个框里是什么类别
- 回归结果(Reg) → 框的位置(中心点、宽高)。
👉 类比:
每个侦探有一顶“智能头盔”(Dynamic Head),头盔会根据任务卡的内容动态生成不同的观察方式,最终报告“我看到的是猫,而且在这个位置”。
迭代精炼(Refinement)
- Sparse R-CNN 不会只让候选框预测一次,而是会经过 多轮动态预测头,逐步 refine(精炼)框的位置和特征。
- 就像 Cascade R-CNN 那样,每一轮预测都比上一轮更精确。
👉 类比:
侦探们不是只看一眼就报告,而是来回确认几次:第一次大概找位置,第二次更精确地锁定,最后给出很靠谱的答案。
输出:直接得到目标结果(NMS-free)
- 最终,每个候选框会给出一个预测结果(类别 + 边框)。
- 因为一开始候选框就是有限的(比如 100 个),所以不需要 NMS 去掉冗余框。
👉 类比:
你只派了 100 个侦探,每个人都有不同的任务卡,所以最终的报告不会重复、也不会互相抢活儿。
✨ 总结(形象化比喻版)
可以把 Sparse R-CNN 想象成:
- 你派出 固定数量的侦探(稀疏候选框),
- 每个侦探带着 任务卡(proposal feature),
- 他们通过 智能头盔(Dynamic Head) 在城市地图(特征图)里找目标,
- 一轮一轮 refine,最终报告目标是什么、在哪里。
- 由于侦探数量有限,结果直接就是最终答案,不需要额外筛选(NMS-free)。
4、Sparse R-CNN:主要缺陷
- 必须依赖“迭代精炼 + 动态头”,否则性能崩塌
- 仅把 RPN 换成“可学习提案框(learnable proposals)”而不做其它改动,AP 直接从 Faster R-CNN 的 40.2 掉到 18.5(表 3 的第一行与起始行对比)。只有叠加 迭代精炼、再加上 动态实例交互头 才能一路回升到 42.3 AP(表 3、表 5)。这说明模型对这些组件强依赖,结构脆弱性较大
- 对“提案数量/阶段数”高度敏感,换性能要加时延与训练时间
- 提案数从 100→300→500,AP 42.3→43.9→44.6,但 FPS 23→22→20,训练时间 19h→24h→60h——显著上涨(表 7)。
- 迭代阶段从 1→6,AP 21.7→42.3 才“饱和”,阶段越多推理越慢(表 8)。这意味着 算力/延迟 与 精度 的权衡很尖锐
- 第一阶段定位很“粗”,需要多轮校正
- 论文明确把初始提案视作“统计先验、与图像无关的粗定位”,在未迭代时仅 21.7 AP;必须多阶段把框逐步推向真值,才能达到可用精度(表 8、图 5);这天然增加了推理链路的深度与不确定性
- 模块化复杂(RoIAlign + 动态头 + 自注意力 + 级联),工程落地门槛高
- 相比“单次密集预测”的一阶段范式,这套 RoI 对齐 + 多阶段动态头 的流水线在内存访问、实现与调参上复杂得多;论文也给出其典型速度仅 22–23 FPS(R50-FPN, 3×),并非极致实时(表 1、推理细节)
注:作者证明了对提案初始化相对鲁棒(中心/整图/网格/随机差异很小,表 6),因此这点不是主要缺陷
5、已被证实有效的改进与后续创新方向
这些改进大多就在论文中做了系统实证,可视作 “基于 Sparse R-CNN 的改/增法则”。
- 更强的迭代结构与特征复用
- 单纯“级联”帮助有限;把前一阶段的对象特征显式复用(拼接/交互) 才带来大幅增益(表 4、表 3),说明 “把阶段信息传下去” 是关键改进点
- 动态实例交互头(而非共享/注意力头)
- 把“每个提案特征”转成该提案专属的卷积权重对 RoI 特征做两次 1×1 动态变换,显著优于多头注意力替代(42.3 vs 35.7,表 9;图 4伪代码)——后续工作延展时,保留/强化动态参数化 是优先级很高的方向
- 适配场景:提案数/阶段数的“弹性配置”
- 拥挤场景(CrowdHuman)把提案数扩到 500,显著优于 Faster/RetinaNet/FCOS,甚至较 Deformable-DETR 也有优势(表 11)。这提示按场景自适应地分配提案与阶段 是务实的工程策略
- 更强的骨干网络(Backbone)
- 用 Transformer 主干(PVT、Swin)替代 ResNet,可带来 +0.7~+2.9 AP(表 13)。因此,“更强主干 + 稀疏头” 是稳健可复用的升级路径
- 自监督预训练权重
- 换上 DetCo / SCRL 等自监督权重,R50 模型从 45.0 → 46.5/46.7 AP(表 12)。这条路线对小数据/跨域迁移尤为实用
- 与 query-based 家族的互补:更快收敛、保留稀疏
- 与 DETR 系列相比,Sparse R-CNN 36 个 epoch 即可稳定收敛,而 DETR 常需 500(图 2;表 1),同时在小目标上更好(APs 26.7 vs 22.5)。后续研究可把 “可学习提案 + 局部交互” 与 “变形注意/稀疏注意” 等机制融合,进一步提升收敛与效率
实践小结(给到落地建议)
- 算力紧/时延严苛:优先减少提案数与阶段数;保持动态头但简化宽度;必要时换更快骨干。
- 精度优先/拥挤场景:提案数 300–500,阶段 6,打开自注意力与动态头;结合自监督预训练与更强主干。
- 跨域/小样本:强烈建议自监督预训练(表 12),收益稳定。
一句话:Sparse R-CNN 的“弱点”恰恰指向它的“优化旋钮”——提案数、阶段数、动态头、特征复用、预训练与主干。顺着这些旋钮去做模块化增强或轻量化剪裁,就是后续改进与创新的主线