YOLO v1(2016):统一的实时目标检测,从两阶段检测到单阶段检测,YOLO系列开始鼻祖
1、摘要
You Only Look Once: Unified, Real-Time Object Detection 您只能查看一次: 统一的实时对象检测
现有研究将分类器重新用于目标检测,而我们则将其重构为一个回归问题:通过空间分离的边界框及其对应类别概率进行检测。该方法仅需单个神经网络即可在 评估阶段直接从完整图像中预测边界框和类别概率。 由于整个检测流程由单一网络实现,因此可直接对检测性能进行端到端优化
- “把分类器重新用于检测” 是啥?
- 以前的做法(R-CNN 系列): 先在图上撒一堆候选框(Region Proposal),再把每个框当成一张小图片,送进“图片分类器”里问:“框里是猫、狗还是背景?” —— 就像先拿放大镜一块块看拼图,再判断每块是什么。
- YOLO 的做法: 不撒候选框了,直接把整张图一次性塞进一个神经网络。 网络吐出两件事: ① 每个格子可能包含物体的“框”(x, y, 宽, 高); ② 这个框里物体的类别(猫、狗、车等)。 —— 就像一眼看完整张拼图,直接说“左上角有只猫,右下角有辆车”。
- “重构为回归问题” 是啥?
- 回归 = 直接猜数字。
比如:
- 不用问“这张图是不是猫?”(分类问题),
- 而是问“猫的框左上角坐标是(120, 90),宽是200,高是150,类别是‘猫’”的概率0.99(回归问题)。 YOLO 网络最后几层就是连续的数字输出,直接对应框的位置和类别概率。
- “端到端优化” 是啥?
- 以前的多步骤流程: 候选框 → 分类器 → 后处理(NMS),三个模块分开训练,中间可能“各管各的”。
- YOLO 的单一网络: 从“原始图像”到“最终框+类别”,一个网络全搞定,可以直接用“检测结果好不好”来反传梯度优化。
我们的基础YOLO模型以每秒45帧的速度实时处理图像。网络的较小版本 fast YOLO,以每秒155帧的速度处理图像,同时仍能达到其他实时检测器两倍的mAP
- “速度” 部分怎么理解?
- 基础 YOLO:45 帧/秒 ≈ 实时视频(常见摄像头 30 帧/秒)。
- Fast YOLO:155 帧/秒 ≈ 慢动作视频,但精度还能打别人两倍(mAP 高)。
- 为什么快?没有候选框、没有反复提特征,一次前向传播就完事。
YOLO虽然定位误差更多,但背景环境中预测误报的概率更低。此外,YOLO能够学习到物体的通用表征。当从自然图像推广到艺术品等其他领域时,其性能优于DPM和R-CNN等其他检测方法
- “定位误差多,但背景误报少” 是啥?
- 定位误差:YOLO 的框可能不够紧贴物体(比如把猫的耳朵漏在外面)。
- 背景误报少:它很少把“空草地”误判成“狗”。 —— 因为 YOLO 看的是“全局上下文”,不像 R-CNN 可能只盯着一小块草地就瞎猜。
- “泛化到艺术品” 是啥?
- 其他方法(如 DPM、R-CNN)在自然照片上训练后,遇到油画、抽象画就“懵”了。
- YOLO 学的是“物体的通用形状和纹理”,比如“猫有尖耳朵、长尾巴”,所以油画里的猫也能认出来。 —— 就像 你学会了“猫长啥样”,不管照片、漫画还是毕加索画都能认。
2、介绍
像可变形部件模型(DPM)这样的系统采用滑动窗口方法, 其中分类器在整个图像[10]上以均匀间隔的位置运行。
一、DPM(Deformable Part Model,可变形部件模型)
步骤 1:准备模板
- 先对“猫”这类物体,人工设计好一个整体模板(比如猫的大致轮廓)。
- 再设计几个小部件模板(猫头、猫腿、猫尾巴)。
步骤 2:滑动窗口
- 把模板当成“印章”,从图像左上角开始,一格一格往右滑、往下扫,每个位置都算一个“匹配分数”。
- 同时把模板放大缩小成不同尺寸,再扫一遍(为了检测远近不同的猫)。
- 就像用**“猫形印章”**在图上按格子盖章,哪一格盖出来的形状最像猫,分数最高。
步骤 3:拼部件
- 高分位置不一定完整是一只猫,可能只是猫的脑袋。
- 于是再用“猫头模板”找脑袋,“猫腿模板”找腿……
- 最后把这些部件拼起来,如果整体分数够高,就判定“这里有一只猫”。
缺点
- 滑窗+多尺度 = 计算量爆炸(一张图要跑几万次模板匹配)。
- 模板是人工设计的,换个动物就得重新设计一套模板。
如R-CNN,使用区域提议该方法首先在图像中生成潜在的边界框,然后对这些 候选框进行分类器检测。分类完成后,通过后处理步 骤对边界框进行精炼,剔除重复检测结果,并根据场 景中的其他物体重新评估边界框[13]。由于每个独立 组件都需要单独训练,这种复杂的流程不仅运行缓 慢,优化难度也较大
二、R-CNN(Region-CNN)
步骤 1:生成候选框(Region Proposal)
- 用Selective Search这类算法,在图上快速圈出2000个左右“可能包含物体”的方框(不管里面是猫狗还是汽车)。
- 就像**“海选”**:先把图上所有看起来像东西的区域都框起来,宁可错杀一千,不放过一个。
步骤 2:对每个框提特征
- 把每个候选框裁剪成小图片,送进一个预训练的CNN(如AlexNet),提取出4096维的特征向量。
- 相当于对每个框说:“来,拍张证件照,我来记住你的长相。”
步骤 3:分类
- 把每个框的特征向量送进SVM分类器(一个类别一个SVM,比如猫SVM、狗SVM……)。
- 分类器回答:“这个框有80%概率是猫,5%是狗……”
- 如果最高分数超过阈值,就保留这个框。
步骤 4:后处理(NMS + 回归修正)
- NMS(非极大值抑制):如果多个框重叠且都说是猫,只留分数最高的那个,删掉其余。
- 回归修正:用一个小网络微调框的位置(比如把框往左挪一点,更贴合猫的身体)。
缺点
- 2000个框 × CNN前向传播 = 慢到离谱(GPU上几十秒一张图)。
- 每个模块(候选框、CNN、SVM、回归)分开训练,像拼积木,调参痛苦。
3、统一检测核心思想
我们的系统将输入图像划分为一个S×S的网格。如果某个物体的中心落在某个网格单元内,那么该网格 单元就负责检测该物体。
每个网格单元都会预测边界框及其置信度分数。这些置信度分数既反映了模型对边界框内物体存在的置 信程度,也体现了模型对边界框预测准确性的判断。 从数学定义上说,置信度可表示为Pr(物体)×IOU(pred, truth)。当该网格单元中不存在物体时,置信度应 为零;若存在物体,则置信度需等于预测边界框与真 实边界框的交并比(IOU)。 每个边界框包含5个预测:x、y、w、h和置信度。 x,y)坐标表示框中心相对于网格单元边界的坐 标。宽度和高度是相对于整个图像进行预测的。最 终,置信度预测值代表了预测框与任意真实框之间的 交并比(IOU)。
每个网格单元还会预测C类条件概率Pr(类别i对 象)。这些概率是在网格单元包含对象的条件下得出 的。我们仅进行预测。
1️⃣ 先切柜门——S×S 网格
2️⃣ 每个柜子发一张“快递单”——边界框 5 个数
字段
| 大白话解释
| 范围
|
x, y
| 快递中心在本格子内部的相对坐标(0~1)
| 左上角(0,0),右下角(1,1)
|
w, h
| 快递宽、高占整幅图的比例(0~1)
| 小快递 w,h≈0.1;大快递≈0.8
|
confidence(信任分)
| 两个信息相乘:①格子里确实有快递吗?②框得有多准?用 IOU 打分
| 0~1
|
IOU计算方法
3️⃣ 每个柜子再贴一张“类别标签”——C 类条件概率
- 类别概率:安检员只有一张“类别标签”,不管几只框都贴同一张。
- 两个框:安检员手里有两张透明胶片(框 1、框 2),哪张与真实框重叠高(IOU 高),哪张就被留下,另一张作废。
- 训练时只让 IOU 高的那张框学习,另一张躺平 → 这样两只框慢慢学会“各盯各的尺寸/形状”,提升召回。
4️⃣ 最终输出长啥样?
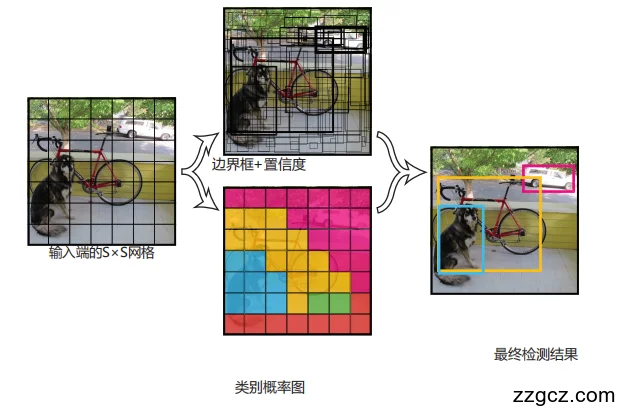
4、模型架构
该网络包含24个卷积层,后接两个 全连接层。不同于GoogLeNet采用的inception模 块,我们直接使用1×1的归一化层,再接三个3×3的 卷积层
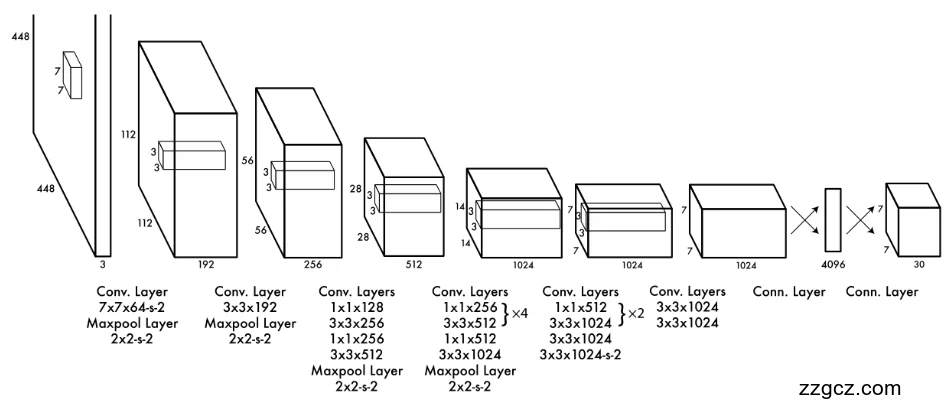
① 先想好“地基”——借 GoogLeNet 的骨架
- 灵感来源:GoogLeNet(2014 年 ImageNet 冠军)(也称为Inception v1)。其核心创新是Inception模块,通过并行多尺度卷积和1×1卷积降维。“GoogLeNet 就是一层里套了 4 条小路,把 1×1、3×3、5×5、池化同时做,再把结果拼起来,既省计算又提精度。为什么需要 Inception?(痛点)
- 但不学它的 Inception 模块(• YOLO 要速度极限,Inception 的 4 条路并行 → GPU 同步开销大)
- YOLO 的替代方案: 1×1 卷积(降维) → 3×3 卷积 ×3(提特征)
② 24 层卷积在干嘛?——“把照片变成高维特征图”
- 输入:448 × 448 × 3 的 RGB 图
- 经过 24 层卷积 + 池化后,得到 7 × 7 × 1024 的“浓缩精华图” (尺寸缩了 64 倍,但通道变厚,语义信息变强)
③ 2 层全连接——“把高维特征拍扁成检测结果”
- 第 1 个全连接:把 7×7×1024 拉平 → 4096 维向量
- 第 2 个全连接:4096 → 7×7×30(直接就是最终输出) 每个 1×1×30 的小条子,对应原图上 64×64 的区域,里面装: • 2 个框的 (x, y, w, h, confidence) = 2×5 = 10 个数 • 20 个类别概率(PASCAL VOC 有 20 类)
④ Fast YOLO——“瘦身版”
- 层数砍到 9 层卷积(差不多砍了 2/3)
- 每层 filter 数量也砍半(通道数减少)
- 其余训练和测试参数完全不变 结果:速度从 45 FPS 飙到 155 FPS,精度只是略降,仍是当时实时检测的王者。
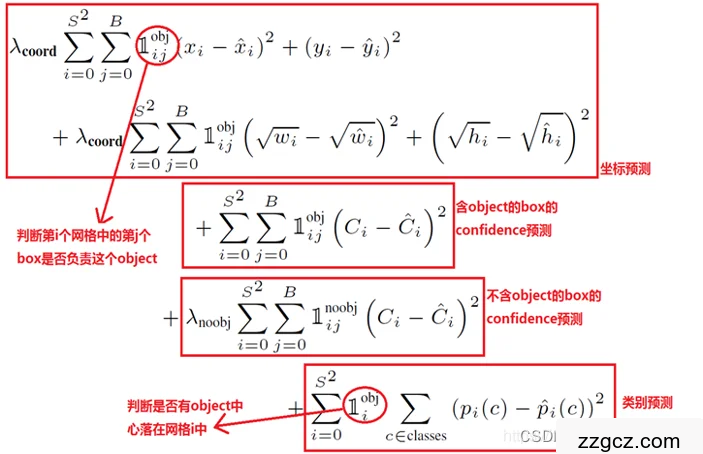
5、损失函数
6、yolov1局限性
YOLO对边界框预测施加了严格的空域约束,因为 每个网格单元仅能预测两个边界框且只能包含一个类 别。这种空间限制导致模型难以准确识别邻近物体的 数量。
我们的模型在处理成群出现的小型物体时表现 不佳,例如鸟群等群体形态。 由于我们的模型是通过学习数据来预测边界框的, 因此在处理具有新奇或特殊纵横比或配置的对象时, 模型难以进行泛化。
此外,由于架构中包含多个从输 入图像下采样层,我们的模型在预测边界框时采用了 相对粗糙的特征。 最后需要说明的是,虽然我们在训练时采用的损失 函数是基于检测性能进行优化的,但该函数对小边界 框和大边界框的误差处理方式存在差异。对于大边界 框而言,微小的定位误差通常影响较小,但对于小边 界框来说,微小误差对交并比(IOU)的影响则会显 著加剧。我们发现主要的误差来源是定位精度不足