YOLO v3(2018):增量改进,多尺度预测
导出时间:2025/11/23 20:26:56
1、yolov3改进点
更强大的骨干网络:Darknet-53 替代 Darknet-19
YOLOv2 使用 Darknet-19(19层卷积),而 YOLOv3 升级为 Darknet-53(53层卷积),并引入 残差连接(ResNet思想)。
- 改进点:
- 更深网络:53层比19层能提取更丰富的特征,提升检测精度。
- 残差结构:解决深层网络训练时的梯度消失问题,使训练更稳定39。
- 通俗解释:
- 就像看书,YOLOv2只能看19页,而YOLOv3能看53页,并且每看几页就回顾一下前面的内容(残差连接),避免忘记重点。
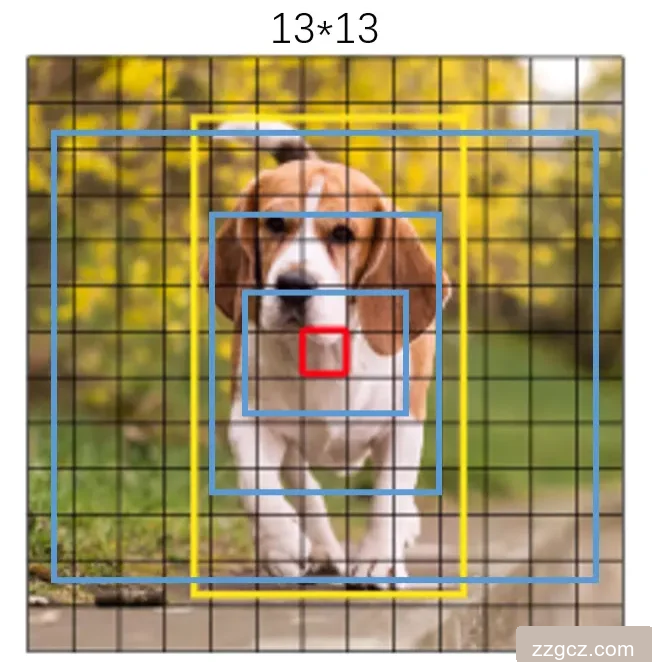
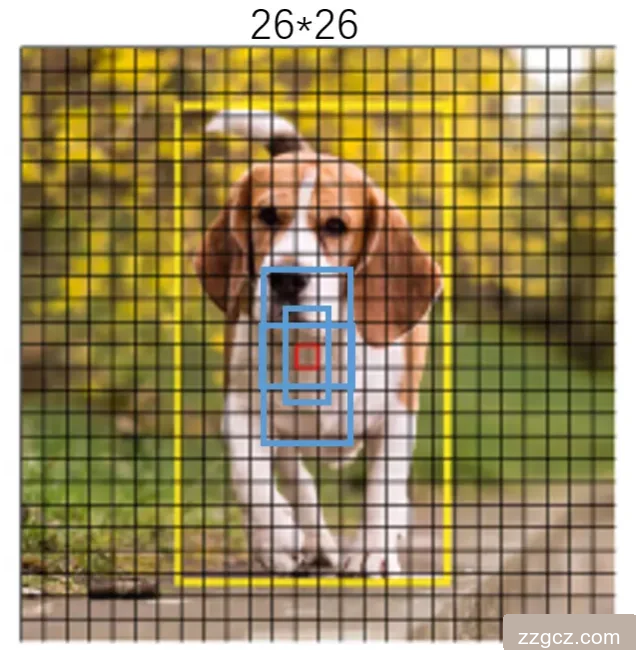
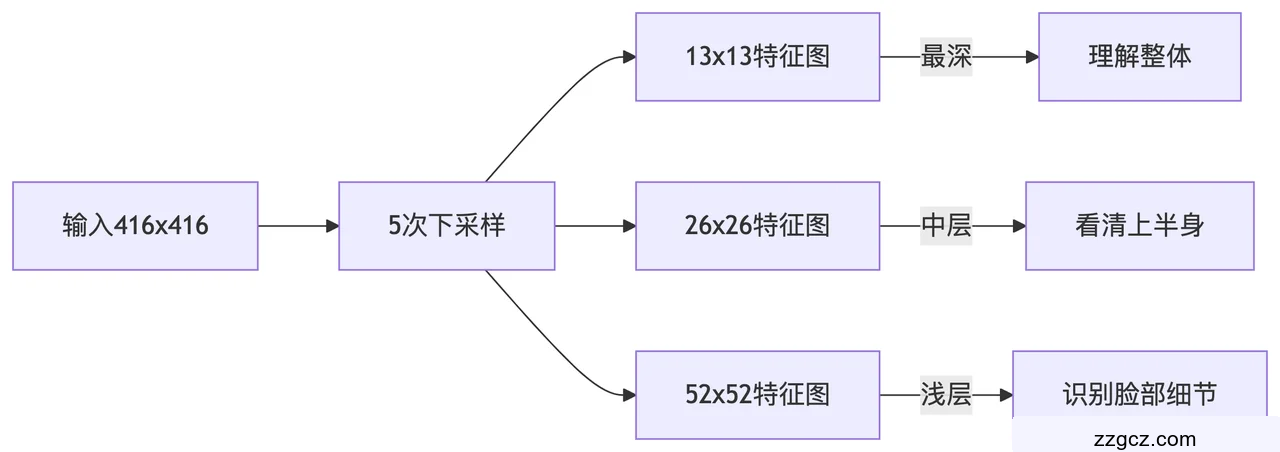
多尺度预测(FPN结构)
 |  |  |
YOLOv2 只在 13×13 特征图上做预测,对小目标检测效果差。
YOLOv3 借鉴 FPN(特征金字塔网络),在 3个尺度(13×13、26×26、52×52) 上进行预测:
- 改进点:
- 大目标(13×13):感受野大,适合检测大物体(如汽车)。
- 中目标(26×26):平衡大小,适合中等物体(如行人)。
- 小目标(52×52):感受野小,适合检测小物体(如手机)39。
- 通俗解释:
- 就像用不同倍数的放大镜看东西:
- 低倍数(13×13)看整体(大物体)。
- 中倍数(26×26)看中等物体。
- 高倍数(52×52)看细节(小物体)。
- 就像用不同倍数的放大镜看东西:
更精细的Anchor Box(先验框)设计
YOLOv2 用 5个Anchor Box(通过k-means聚类得到)。
YOLOv3 用 9个Anchor Box(3个尺度×3种比例):
- 改进点:
- 大尺度(13×13):分配 大Anchor(如 116×90、156×198、373×326)。
- 中尺度(26×26):分配 中Anchor(如 30×61、62×45、59×119)。
- 小尺度(52×52):分配 小Anchor(如 10×13、16×30、33×23)39。
- 通俗解释:
- 就像准备不同大小的盒子装东西:
- 大盒子(大Anchor)装大物体(冰箱)。
- 中盒子(中Anchor)装中等物体(微波炉)。
- 小盒子(小Anchor)装小物体(手机)。
- 就像准备不同大小的盒子装东西:
用逻辑回归(Logistic)替代Softmax分类
YOLOv2 用 Softmax,假设每个物体只能属于一个类别(如“狗”不能同时是“哈士奇”)。
YOLOv3 改用 独立逻辑回归(Logistic),支持 多标签分类:
- 改进点:
- Softmax问题:假设类别互斥(如“女人”和“人”不能同时成立)。
- Logistic改进:每个类别独立预测(如“女人”和“人”可以同时为真)48。
- 通俗解释:
- 以前考试只能选一个正确答案(Softmax),现在可以多选(Logistic),比如一个人既是“医生”又是“女性”。
损失函数优化(二元交叉熵)
YOLOv2 用 Softmax + MSE(均方误差) 计算分类和定位损失。
YOLOv3 改用 二元交叉熵(BCE):
- 改进点:
- 分类损失:用BCE替代Softmax,更适合多标签任务。
- 置信度损失:同样用BCE,使训练更稳定78。
- 通俗解释:
- 以前评分标准太死板(MSE),现在更灵活(BCE),能更好处理“部分正确”的情况。
总结:YOLOv3的核心优势
改进点
| YOLOv2
| YOLOv3
| 提升效果
|
骨干网络
| Darknet-19
| Darknet-53(残差连接)
| 特征提取更强
|
多尺度预测
| 仅13×13
| 13×13, 26×26, 52×52
| 小目标检测更好
|
Anchor Box
| 5个
| 9个(3尺度×3比例)
| 定位更精准
|
分类方式
| Softmax
| Logistic(多标签)
| 支持重叠类别
|
损失函数
| MSE
| 二元交叉熵(BCE)
| 训练更稳定
|
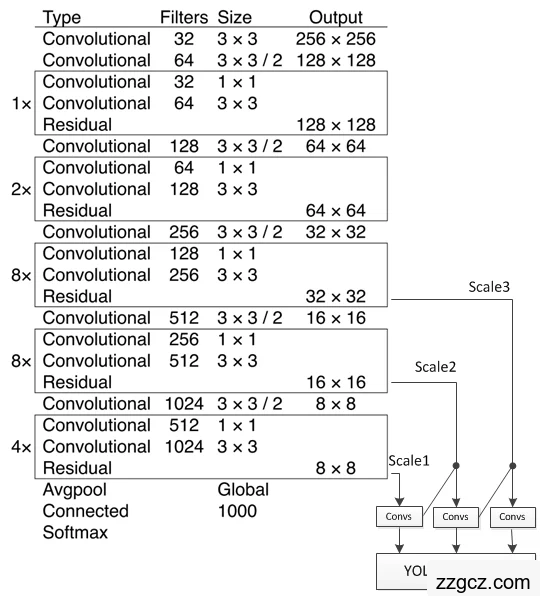
2、完整的网络结构
完整的YOLOv3网络是由4个部分组成:输入层、Backbone特征提取部分,也就是Darknet-53,Neck特征拼接部分,head头分类部分。
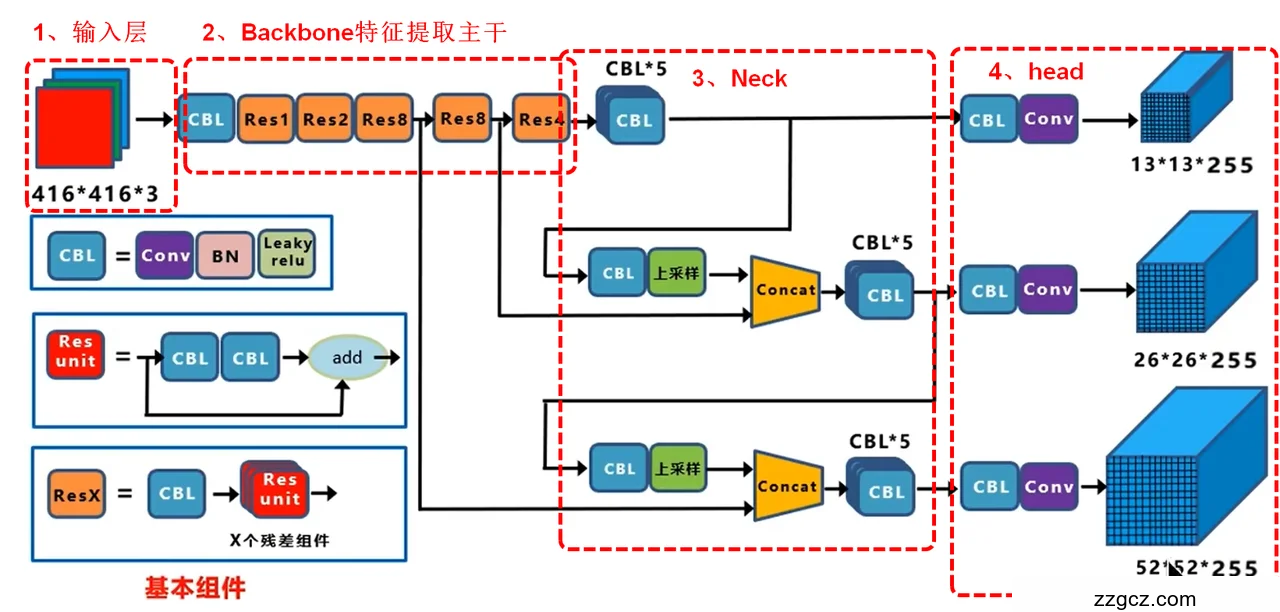
Backbone主干网络负责从输入图像中提取有用的特征。它通常是在大规模图像分类任务(例如 ImageNet)上训练的卷积神经网络 (CNN)。主干网捕获不同尺度的层次特征,在较早的层中提取较低级别的特征(例如边缘和纹理),在较深层中提取较高级别的特征(例如对象部分和语义信息)。
Neck颈部是连接脊柱和头部的中间部件。它聚合和细化主干提取的特征,通常侧重于增强不同尺度的空间和语义信息。颈部可能包括额外的卷积层、特征金字塔网络(FPN)或其他机制来改善特征的表示。
就像多倍望远镜组合使用:
- 低倍镜(13x13):看全景(发现远处有人)
- 中倍镜(26x26):看局部(认出是穿红衣服的人)
- 高倍镜(52x52):看细节(确认是戴眼镜的张老师)
head头部是物体探测器的最后一个部件;它负责根据主干和颈部提供的特征进行预测。它通常由一个或多个特定于任务的子网络组成,这些子网络执行分类、定位以及最近的实例分割和姿势估计。头部处理颈部提供的特征,为每个候选对象生成预测。最后,后处理步骤(例如非极大值抑制 (NMS))会过滤掉重叠的预测,并仅保留最置信度的检测。
每个尺度的检测头都像三个小机器人在网格里工作:
坐标机器人:用尺子测量位置
置信度机器人:举牌子打分(0-1分)
分类机器人:拿分类手册查类别(支持多标签)
3、yolov3损失函数
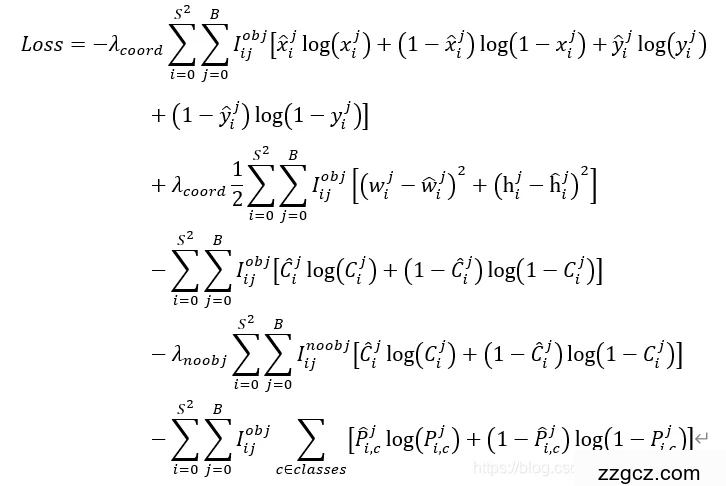
1. 坐标损失(BBox Regression)
▶ 作用:
精确调整预测框的位置和大小
▶ 直观解释:
就像用两种尺子测量:
- 普通尺子量中心点(x,y)
- 弹性尺子量宽高(w,h)——小误差会被放大
置信度损失(Confidence Loss)
▶ 作用:
判断框内是否有物体(物体置信度) + 框的准确度(IOU)
▶ 直观解释:
就像老师批改选择题:
- 答对(有物体)得1分
- 答错(无物体)扣0.5分(λ_noobj控制惩罚力度)
分类损失(Class Loss)
▶ 作用:
预测物体所属类别(支持多标签分类)
▶ 直观解释:
就像多选题评分:
- 每个选项(类别)单独判断对错
- 不限制正确选项数量