YOLOX(2021):2021年超越所有YOLO系列
导出时间:2025/11/23 20:29:00
1、研究背景和动机
YOLO 系列的发展脉络
YOLO 系列从 YOLOv1 到 YOLOv4 一直围绕一个核心目标:
👉 在保证较高检测精度的同时,最大化推理速度,从而适应实时场景。
- YOLOv1 (2016):首次将目标检测任务转化为单个回归问题,实现了“端到端”的实时检测,但定位精度有限。
- YOLOv2 / v3:引入锚点机制(anchor-based)、残差网络(ResNet/DarkNet53)、多尺度检测,大幅提升了精度。
- YOLOv4 (2020):集成了 Bag-of-Freebies(如 Mosaic 增强)和 Bag-of-Specials(如 CSPDarkNet、PANet 等),达到了速度与精度的最佳平衡点之一。
可以看到,YOLO 系列一直是“速度–精度权衡”中的典型代表,并在工业界被大量应用。
新的研究趋势
然而,在 YOLOv4/v5 出现后,目标检测领域出现了新的方向:
- 无锚点检测器 (Anchor-free detectors)
- 代表模型:FCOS、CenterNet。
- 优势:避免锚点聚类和调参,简化训练与推理;在移动端和边缘设备上更高效。
- 先进的标签分配策略
- 代表方法:OTA(Optimal Transport Assignment)、SimOTA。
- 优势:通过动态分配正负样本,解决了正负样本比例失衡的问题,提高模型收敛速度和最终精度。
- 端到端检测器(无需 NMS)
- 代表方法:DETR、Sparse R-CNN。
- 优势:用一体化训练代替启发式后处理,简化检测流程。
但是,这些前沿方法并没有被整合进 YOLO 系列中,因此 YOLOv4、YOLOv5 虽然性能强大,但仍停留在 锚点驱动 + 手工规则标签分配 的范式
YOLOX 的提出动机
YOLOX 的研究团队(旷视科技 Megvii)正是看到了这一差距:
- 实际问题:
- YOLOv3 依然是工业界用得最广的版本,但其 anchor-based 流程和固定的样本分配规则已经过时。
- YOLOv4/v5 虽然更强,但对 anchor 的依赖、对超参数的敏感性让它们在不同任务和硬件上的泛化性不足。
- 研究目标:
- 将 anchor-free 思想 引入 YOLO,简化训练与推理,减少依赖人工调参。
- 使用 解耦检测头 (decoupled head),分离分类与回归任务,加快收敛、提升性能。
- 应用 SimOTA 动态标签分配策略,让模型更智能地选择正样本,提高检测精度。
- 保持 YOLO 系列的优势 —— 实时性 + 工程落地性,并支持多种推理框架(ONNX、TensorRT、NCNN、OpenVINO),方便部署
YOLOX 的动机可以一句话概括: 👉 把近两年目标检测领域的新成果(无锚点、解耦头、先进标签分配)带入 YOLO 系列,让它在保持“快”的同时,更加“准”和“易用”。
2、YOLOX 的核心创新点总结
1. 无锚点检测 (Anchor-free)
- 传统 YOLO (v2–v5):基于锚点 (anchor-based),需要提前用 K-means 聚类得到一组固定尺寸的锚框,训练和推理时都依赖这些锚点。
- 问题:
- 依赖人工设置,缺乏泛化性。
- 每个格点要预测多个 anchor,增加了计算量和延迟。
- YOLOX 创新:改为 每个格点只预测一个框,直接回归目标的中心和宽高
- 优势:更简洁、更高效,减少超参数,推理速度更快,尤其适合移动端和边缘设备。
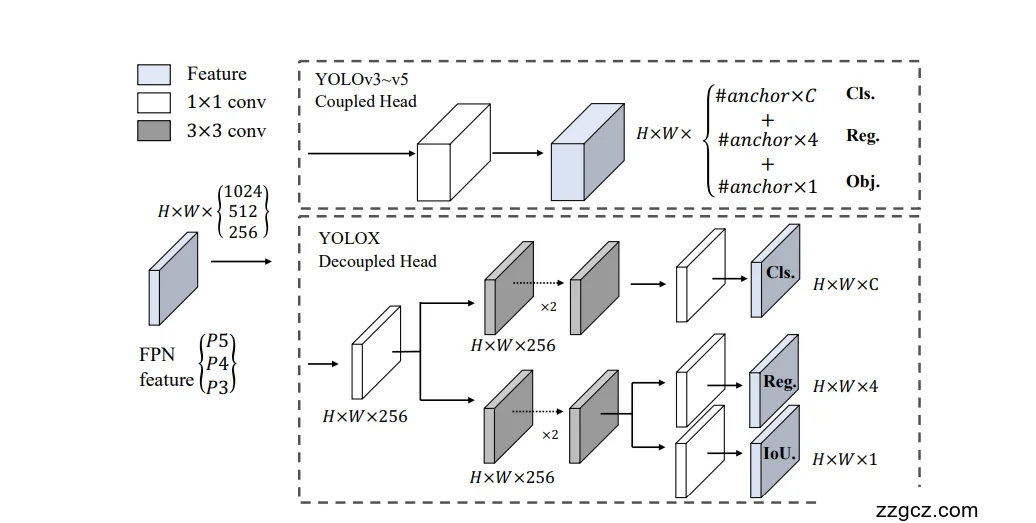
2. 解耦式检测头 (Decoupled Head)
- 传统 YOLO (v1–v5):分类和回归任务共享同一检测头(coupled head)。
- 问题:分类和回归是两种不同的学习目标,容易互相干扰,导致收敛慢、性能受限。
- YOLOX 创新:将检测头 分为两个独立分支:
- 一个分支专门做分类(是否是某个类别);
- 一个分支专门做回归(位置与大小),并额外加 IoU 分支。
- 效果:
- 收敛更快(训练更稳定);
- 在端到端版本中性能下降更小;
- 在 V100 上推理仅多 ~1.1ms,但换来更高 AP 值
3. SimOTA 动态标签分配
- 传统 YOLO:采用固定规则分配正负样本(比如“与 GT 最接近的 anchor 才是正样本”)。
- 问题:
- 正负样本划分僵硬,可能忽略一些优质预测;
- 容易出现正负样本比例严重不平衡。
- YOLOX 创新:提出 SimOTA (Simplified Optimal Transport Assignment)。
- 动态选择每个目标的 Top-k 个预测作为正样本,而不是只选一个中心点。
- 让模型利用更多有效样本,提升梯度质量。
- 效果:AP 从 45.0% 提升到 47.3%,比当时最优 YOLOv3 提高 ~3 个百分点
4. 更强的数据增强策略
- YOLOv4:引入了 Mosaic 数据增强,已经很有效。
- YOLOX:在此基础上进一步引入 MixUp,并针对不同规模模型调整增强强度。
- 大模型:强数据增强效果显著(如 MixUp、CopyPaste)。
- 小模型:弱化增强反而更好,避免过拟合。
- 效果:增强后 AP 提升明显(例如 YOLOX-L 提升 ~0.9%)。
6. 工程与部署优化
- 提供 ONNX、TensorRT、NCNN、OpenVINO 部署版本,方便落地工业场景。
- 在 CVPR 2021 自动驾驶流式感知挑战赛中凭借 YOLOX-L 拿下冠军,证明其实用性
3、YOLOX 模型架构详解
YOLOX 延续了 YOLOv4 / v5 的三段式结构:
👉 Backbone(特征提取) → Neck(特征融合) → Head(检测头)
但在 Head 和 训练流程 上做了重大革新。
1. Backbone:特征提取网络
YOLOX 在 Backbone 上 保持灵活,支持不同规模的网络:
- 小模型:YOLOX-Nano(MobileNet/Depthwise 卷积)、YOLOX-Tiny。
- 中大型模型:YOLOX-S/M/L/X,基于 CSPDarkNet(和 YOLOv5 类似)。
- 实验模型:YOLOX-DarkNet53,用于和 YOLOv3 做公平对比
关键点:
- 采用 CSPNet(Cross Stage Partial Network) 结构,提升梯度流动效率,减少冗余计算。
- 激活函数:SiLU(Swish 的变体),比 LeakyReLU 更平滑,有利于收敛。
👉 可以理解为:Backbone 基本和 YOLOv5 保持一致,但 YOLOX 的核心创新点主要在 Neck 和 Head。
Neck:特征融合网络
YOLOX 的 Neck 设计几乎和 YOLOv5 相同:
- FPN + PAN(Feature Pyramid Network + Path Aggregation Network)
- 作用:把高层特征(语义强但分辨率低)和底层特征(细节多但语义弱)融合,形成多尺度特征。
- 输出:三个尺度的特征图(通常是 80×80、40×40、20×20,对应小目标、中目标、大目标)。
👉 YOLOX 没有在 Neck 上大改,更多是沿用 YOLOv5 的成熟设计。
Head:解耦检测头 (核心创新)
这是 YOLOX 最与众不同的地方。
3.1 传统 YOLO Head(耦合式)
- YOLOv1–YOLOv5:分类、回归(位置)、置信度共享同一分支(coupled head)。
- 问题:分类和定位任务目标不同,耦合容易产生干扰,导致训练收敛慢。
3.2 YOLOX 解耦头 (Decoupled Head)
YOLOX 将检测头彻底 拆分为两个分支:
- 分类分支 (Cls branch):判断该格点是否属于某个类别。
- 回归分支 (Reg branch):预测边框的偏移量(中心坐标 + 宽高)+ IoU 分支。
结构上:
- 先用 1×1 卷积降维到 256 通道;
- 再分成两个并行分支:每个分支包含两个 3×3 卷积层;
- 分类分支输出类别概率,回归分支输出边框参数 + IoU 预测
👉 这样,分类更专注于“是什么”,回归更专注于“在哪里”,避免互相干扰。
Anchor-free 检测机制
YOLOX 把 YOLO 从 Anchor-based → Anchor-free:
- YOLOv2–YOLOv5:每个格点要预测多个 anchor 框(比如 3 个),增加了计算量。
- YOLOX:每个格点只预测 1 个框,直接输出边框的中心点偏移和宽高。
- 正负样本选择:中心区域 (center sampling) + 动态标签分配(SimOTA)。
👉 结果:更简洁,推理更快,超参数更少,泛化性更强
SimOTA 标签分配
YOLOX 的训练中,正负样本分配方式采用 SimOTA (Simplified Optimal Transport Assignment):
- 传统 YOLO:固定规则(IoU 最大的 anchor = 正样本)。
- YOLOX:动态选择多个正样本(Top-k),让每个目标可以匹配到更优的预测框。
- 效果:显著缓解正负样本失衡问题,提升收敛速度和最终精度
数据增强与训练策略
YOLOX 在训练时使用更强的数据增强:
- Mosaic(来自 YOLOv4)。
- MixUp(图片混合增强,提升模型泛化性)。
- 针对不同规模模型动态调整增强强度(小模型弱化增强,大模型强化增强)。
训练配置:
- 优化器:SGD,余弦学习率调度。
- 训练周期:300 epoch。
- 多尺度训练:随机调整输入分辨率(448–832)。
4、YOLOX 的严重缺陷与改进方向
1. 训练成本高,难以落地轻量化场景
- 问题:YOLOX 引入了 SimOTA 动态标签分配,虽然效果显著,但计算代价较高:
- 需要在训练过程中反复计算预测与 GT 的匹配代价。
- 相比传统 anchor-based YOLO,训练复杂度更大。
- 后果:在资源有限的硬件上(如嵌入式设备、移动端)训练门槛较高。
- 改进方向:后续的 YOLOv7 引入了 更高效的标签分配和梯度流优化,降低了训练开销,同时保持高精度。
仍依赖复杂的数据增强
- 问题:YOLOX 在训练时 heavily 依赖 Mosaic、MixUp 等数据增强。
- 对大模型有利,但对小模型(Tiny/Nano)会造成过拟合或欠拟合。
- 部分增强策略在小数据集或场景数据中并不适用。
- 后果:模型泛化性能依赖于增强设计,不够鲁棒。
- 改进方向:YOLOv8 开始引入 更智能的数据增强策略(自动增强、动态调整增强强度),弱化了人工调参。
未彻底解决 NMS(非极大值抑制)问题
- 问题:YOLOX 尝试过 端到端检测(NMS-free),但性能下降,最终并未默认采用。
- 后果:仍然需要额外的后处理(NMS),这在部署时可能成为延迟瓶颈。
- 改进方向:
- DETR 系列通过 Transformer 架构实现了真正的端到端检测。
- 一些后续 YOLO 系列尝试优化 NMS(如引入更快的 NMS 算法,或近似端到端的方法)。
Backbone 创新不足,仍以 CNN 为主
- 问题:YOLOX Backbone 主要依赖 CSPDarkNet,虽然高效,但属于卷积范式。
- 缺陷:在长距离依赖建模、全局上下文理解方面不如 Transformer 强大。
- 改进方向:
- YOLOv7/YOLOv8 引入了更优化的 CNN 结构(E-ELAN 等)。
- 一些 YOLOX 的改进版本(如 YOLOX-Transformer)尝试引入 Vision Transformer,提高全局建模能力。
模型对任务泛化不足
- 问题:YOLOX 主要针对 目标检测,在分割、关键点检测、多任务学习上缺乏原生支持。
- 后果:在实例分割/姿态估计等任务中,需要额外修改网络结构。
- 改进方向:
- YOLOv8 原生支持 检测 + 分割 + 分类 + 回归 多任务,扩展性更好。
- 其它 YOLOX 改进版(如 YOLOX-Seg)专门针对分割任务优化。
5、总结与后续演进
可以这样理解:
- YOLOX 的贡献:把 YOLO 系列带入 anchor-free + 解耦头 + 动态标签分配 的新纪元。
- YOLOX 的缺陷:
- 训练开销大;
- 依赖数据增强;
- 端到端检测不彻底;
- Backbone 停留在 CNN;
- 多任务扩展性不足。
- 后续改进路线:
- YOLOv7:优化标签分配和梯度路径,更快更准;引入 E-ELAN 增强特征学习能力。
- YOLOv8:彻底 anchor-free,更轻量级;内置多任务支持(检测、分割、分类)。
- YOLO-NAS 等新模型:自动化搜索结构(NAS),提升速度–精度权衡。
- Transformer 结合 YOLO:增强全局建模能力,缓解 CNN 在长依赖建模上的不足。