YOLOv4(2020):目标检测的最佳速度与精度
导出时间:2025/11/23 20:27:26
1、研究背景和动机
在 YOLOv1、v2、v3 出现之后,大家已经知道 YOLO 系列的最大特点就是——快。它不像 Faster R-CNN 那样先生成候选框再分类,而是直接用一个卷积网络一次性完成检测,所以可以做到接近实时的速度。
但是问题来了:
- YOLOv3 的速度虽然快,但准确率不如一些最新的模型,比如 EfficientDet;
- EfficientDet 的准确率虽然高,但速度比 YOLOv3 慢两倍;
- 同时,很多最先进的检测器(比如 NAS-FPN、CenterNet)在实验室里表现很好,但在普通显卡(比如 GTX 1080Ti)上跑不动,需要昂贵的多卡 GPU 训练。
换句话说,当时的现状是:
- 速度快的模型不够准;
- 准确的模型跑不快;
- 一些很准的模型还需要多卡大规模训练,小公司、个人根本用不起。
这就导致一个现实问题:很多工业应用(如监控、无人驾驶、安防)需要实时检测,但却找不到一个既快又准、还能在普通 GPU 上训练的模型。
二、研究动机
YOLOv4 的作者提出了这样几个目标:
- 让目标检测器既快又准
- 在保持 YOLO 系列“快”的优势的同时,追赶甚至超过 EfficientDet 在准确率上的表现。
- 目标是:在 单卡 GPU 上也能跑到实时速度(30 FPS 以上),同时准确率提升一个档次。
- 让训练变得“人人可用”
- 不依赖昂贵的 TPU 或多卡 GPU。
- 任何人只要有一张普通显卡(1080Ti 或 2080Ti)就能自己训练并复现论文里的结果。
- 把研究界的“花里胡哨”的新技巧整合起来,筛选出真正有用的
- 深度学习里有很多被提出的“黑科技”:新的激活函数(Mish、Swish)、新的正则化方法(DropBlock)、新的损失函数(CIoU)、新的数据增强(CutMix、Mosaic)……
- 但这些方法有的只在分类里有效,有的只在小数据集里有效。
- YOLOv4 的目标是系统性地测试和筛选,把能稳定提升检测效果的“好东西”组合起来,形成一个既实用又强大的模型。
三、总结
一句话来说,YOLOv4 的研究背景和动机就是:
👉 解决“速度”和“精度”不可兼得的矛盾,同时让普通人也能在家用显卡上训练出一个工业级的目标检测器
2、YOLOv4 的核心创新点总结
YOLOv4 并不是从零开始设计的全新结构,而是一个 “集大成者”:它把过去几年在目标检测里提出的各种有效技巧(不论是骨干网络、数据增强、正则化还是损失函数)进行了 系统性实验、筛选和组合,最终形成一个既快又准、人人可用的模型
二、主要创新点
1. 骨干网络(Backbone)的改进
- 采用 CSPDarknet53 作为 backbone(比 YOLOv3 的 Darknet53 更强)。
- 引入 跨阶段部分连接(CSP),让网络在保证精度的同时减少计算量,提升推理速度。
- 使用 Mish 激活函数,在保持梯度流动方面更优于 Leaky ReLU。
👉 好处:骨干更强,检测更准,但速度没掉下来。
2. 颈部(Neck)的改进
- 在 YOLOv3 的 FPN 基础上,改为 PANet 路径聚合,增强多尺度特征融合能力。
- 增加 SPP(空间金字塔池化)模块,扩大感受野,帮助捕捉不同尺度的目标。
👉 好处:小目标检测更好,多尺度适应性更强。
3. 头部(Head)的优化
- 依然采用 YOLOv3 的 anchor-based 预测方式,但结合了改进的训练方法:
- CIoU 损失函数:比传统 IoU/GIoU 收敛更快,定位更准。
- DIoU-NMS:替代传统 NMS,更好处理重叠目标。
👉 好处:框的位置预测更准,遮挡物体也能区分开。
4. 训练技巧
- Mosaic 数据增强:把 4 张图片拼接在一起,极大提升数据多样性。
- CutMix、标签平滑、DropBlock 正则化:提升模型鲁棒性,减少过拟合。
- 自对抗训练(SAT):网络自己给自己制造“对抗样本”,增强抗干扰能力。
- CmBN(跨小批量归一化):单 GPU 也能模拟大 batch 的训练效果。
- 余弦退火学习率调度器、随机训练形状:让训练更稳定。
👉 好处:训练阶段做了很多“增强”,但推理速度完全不受影响。
5. 人人可用
- 单卡 GPU 就能训练(不需要 TPU 或多卡集群)。
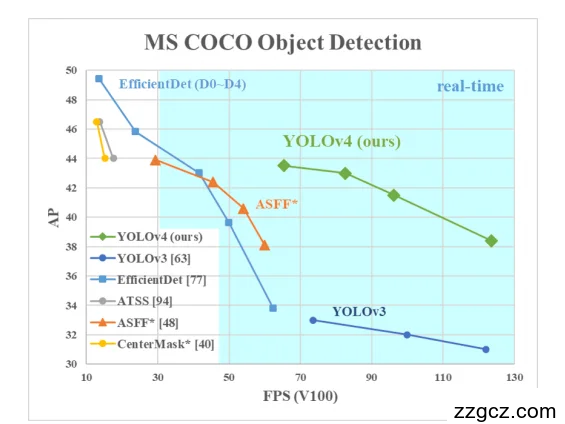
- 在 Tesla V100 上达到 65FPS 和 43.5% mAP,在速度和精度上同时超过 EfficientDet 和 YOLOv3。
👉 好处:不仅科研强,实际应用也能用。
三、总结一句话
YOLOv4 的核心创新点就是: 👉 把一堆分散的、零碎的“深度学习黑科技”筛选整合成一个完整系统,让 YOLO 既快又准,还能在普通显卡上跑得动。
3、模型网络结构
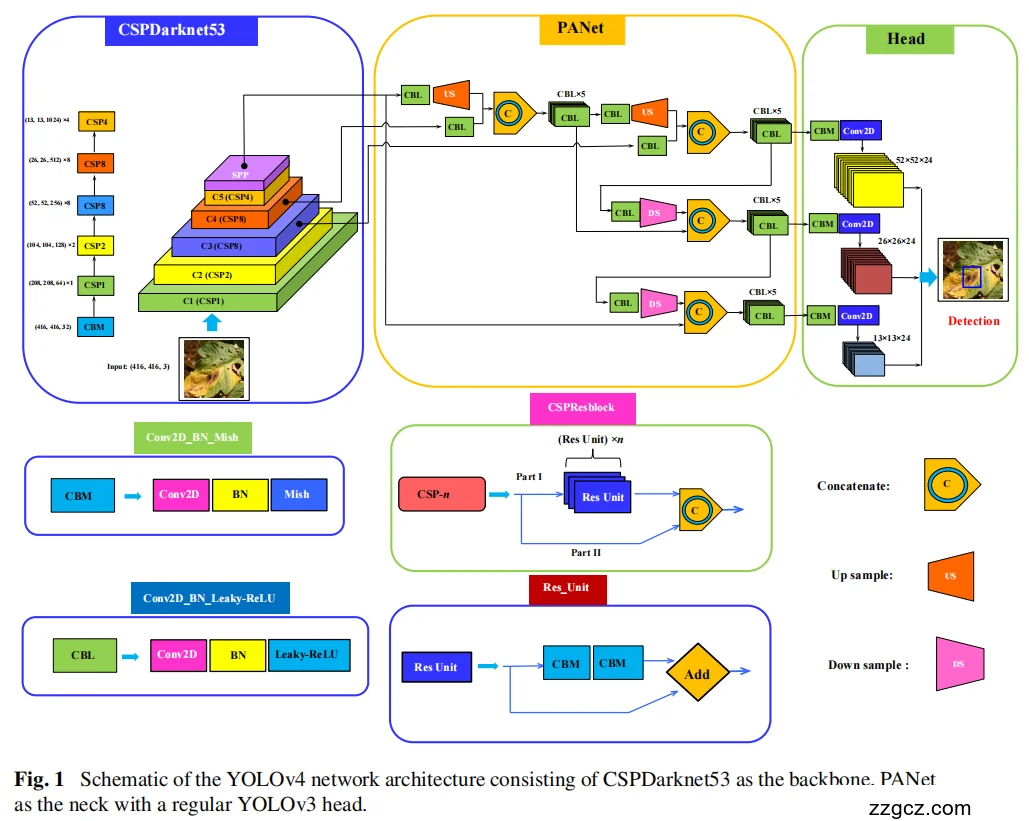
在网络架构中,将残差模块集成到ResNet网络结构中,获得DarkNet53。为了进一步提高网络性能,结合Cross Stage Partial Network(CSPNet),结合其优越的学习能力,形成CSPDarkNet53。将不同的特征层的信息输入到残差模块中,提供更高层次的特征映射作为输出。与ResNet网络相比,这显著降低了网络参数,同时提高了残差特征信息,提高了特征学习能力。
在最初的YOLOv4 Backbone中,SPP块与PANet以及CSPDarknet53集成,取代了YOLO其他变体中使用的特征金字塔网络(FPN)。这带来了感受野的显著增加。
SPP采用了一种有效的目标检测不同尺度的策略。
- 首先,在SPP中对输入的特征层进行卷积操作。
- 之后,可以通过4种不同kernel-size的池化操作来对前面所提特征进行池化操作。
- 然后,将从SPP中获得的合并特征信息连接起来并进一步进行卷积,这显著增加了检测网络的感受野。
从Backbone和SPP中获得的特征在PANet中通过卷积后进行了上采样,从而得到输入的特征层的2倍大小。为了提取额外的语义特征,特征层从CSPDarknet53经过卷积后被连接,然后上采样,然后下采样,与剩余的特征层堆叠,以增强特征融合过程,如图1所示。
因此,Neck被用来提取丰富的语义特征,并用于准确的预测。
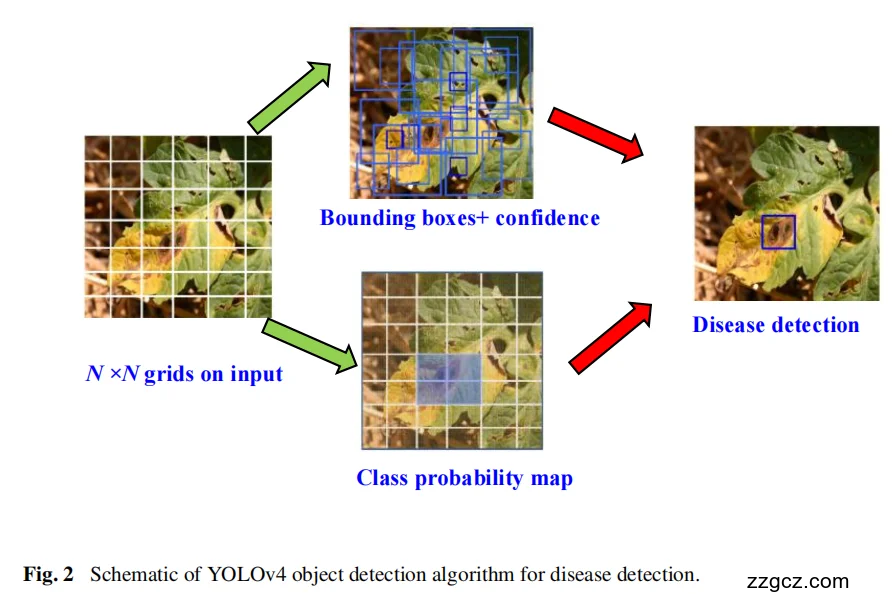
最后,对于特定输入的图像大小,YOLOv4模型可以在3个不同的尺度上预测检测头上得到边界框坐标。
在第一步,输入的图像离散成N×N等间距的网格。如果目标属于网格单元,该模型生成B预测边界框和相应的置信分数。采用非最大抑制(NMS)算法对其最佳边界框预测进行过滤,然后得到最终的边界框。预测过程如图2所示。
先认图例(右下角的小图标)
- CBM:Conv2D + BN + Mish 激活(绿色条)
- CBL:Conv2D + BN + Leaky-ReLU(蓝色条)
- Res Unit:两个卷积块后与输入**相加(Add)**的残差单元(紫/青+菱形)
- C(黄六边形):Concatenate,特征拼接
- US(橙三角):Upsample 上采样
- DS(粉三角):Downsample 下采样
- 右侧三叠彩色条:3 个检测分支(输出 52×52、26×26、13×13 三个尺度)
1)Backbone:CSPDarknet53(左边蓝框)
目的:提取强表征的多尺度特征,又快又稳。
- 输入:416×416×3 的图片(图中左下角)。
- 最底部的 CBM 把图像送进网络,之后进入一串标成 CSP1~CSP5 的阶段块(绿色到橙色的“台阶”)。
- CSP(Cross-Stage Partial)思想
- 做法:把输入特征一分为二,一支走一堆 Res Unit,另一支走捷径(更浅),最后 Concatenate 汇合(图中“CSPresblock”小框就是它的结构示意)。
- 直觉:只让部分通道走重计算,既保留信息、又减少重复梯度流,在不掉精度的前提下降算力/显存。
- 激活函数:Backbone 里默认用 Mish(所以叫 CBM),梯度更平滑,有助收敛与精度提升。
- 多尺度输出(常用的 3 个层级)
- C3:分辨率约 52×52(适合小目标)
- C4:约 26×26
- C5:约 13×13(更语义、更粗)
- SPP 模块(紫色小块,接在最高层 C5 之后):并行做多种核大小的最大池化并拼接,极大扩大感受野,几乎不影响速度。
一句话:CSPDarknet53=Darknet53 + CSP 设计 + Mish,既强化表达、又控制计算;SPP 再把“看得更全”的能力塞给最顶层特征。
2)Neck:PANet 路径聚合(中间黄框)
目的:把不同层级(大/中/小)的信息充分融合,让后面的检测头同时拿到“细节+语义”。
- 自顶向下(Top-Down)
- 把 SPP 后的 C5 先做几层卷积(图中一串 CBL),再 上采样 US,与来自 C4 的特征拼接 C。
- 再卷积几层(CBL),再 上采样,与 C3 的特征拼接。
- 自底向上(Bottom-Up)
- 从刚融合好的细粒度特征出发,做 下采样 DS 逐级往回走,每到一个尺度都与上一阶段的输出 拼接 C 再卷积。
- 为什么是 CBL(Leaky-ReLU)而不是 CBM?
- 颈部/检测头用 Leaky-ReLU 更省计算更快;把更“贵”的 Mish 主要放在 Backbone,速度与精度折中更好。
一句话:PANet 让信息上下“跑一圈”,先上采样聚合语义,再下采样补细节,三个尺度的特征都更“饱满”。
3)Head:YOLOv3 风格的三分支检测头(右边绿框)
目的:在三个尺度上做 anchor-based 预测,兼顾大小目标。
- 来自 Neck 的三路特征进入三套小头:每套
- 都是若干 卷积(CBL/CBM)→ 1×1 Conv2D 输出。
- 输出张量(每个网格×每个 anchor):
- 4 个框参数(tx, ty, tw, th,经变换得到 bbox)
- 1 个 obj 置信度
- N 类概率
- 三个输出尺度对应图里 3 堆彩色条:
- 52×52(小目标)
- 26×26(中目标)
- 13×13(大目标)
- 训练/后处理上的关键点(论文配置):
- CIoU 作为回归损失,提高收敛和定位精度;
- DIoU-NMS 在后处理时更好地区分重叠目标。
一句话:还是 YOLOv3 的“三头”,但因为 Backbone/Neck 和训练策略全面升级,同样的头能拿到更强的特征与更稳的学习信号。
4)把整条链串起来(图的一次过)
- 图片→CSPDarknet53(Mish) 提取 C3/C4/C5,多尺度强特征;顶层过 SPP。
- PANet(Leaky-ReLU) 先上采样一路一路拼接,再下采样回流,做足双向融合。
- 三路检测头 在 52/26/13 的特征图上分别输出框与类别,训练时配合 CIoU/DIoU-NMS 等策略。 ——结果:在单卡 GPU 也能得到 高精度 + 真·实时 的检测器(论文报告在 COCO 上 ~43.5% AP,V100 上 ~65 FPS 示例设置)。
4、后续改进与创新方向
起点(YOLOv4,2020)
采用 CSPDarknet + PANet、强数据增强与 CIoU 等训练技巧,奠定“速度/精度/易部署”的三要素模板。其后续工作大量沿用并改造这些组件与训练范式。
4.1 同一代的规模化与结构延展
- Scaled-YOLOv4(2020):把 YOLOv4 的“规模”当作一等公民来设计,同时缩放深度/宽度/分辨率甚至结构,形成 Tiny~Large 系列,确保不同计算预算下的最优速度/精度平衡。核心思想是把 v4 的 CSP 与 PAN 做“系统化扩展”。
4.2 训练与工程范式的现代化(v5 系列)
- YOLOv5(2020+):将 YOLOv4 的工程实践在 PyTorch 生态里“产品化”,并持续迭代自动锚框、Mosaic 等训练策略;近期的 YOLOv5u 甚至引入了来自 v8 的无锚、解耦式 Ultralytics Head,把后续一代的理念回迁到 v5,显著改善易用性与精度-速度折中。
4.3 “从锚到无锚、从耦合到解耦”的里程碑(YOLOX、YOLOv6)
- YOLOX(2021):在 YOLOv4 的单阶段框架上做三件大事:
- Anchor-free(免锚)预测;
- Decoupled Head(分类/回归解耦);
- SimOTA 动态标签分配。 直接把“YOLO 家族”带进免锚与解耦头时代。
- YOLOv6(2022):在 “v4/v5 的 PAN 拓扑” 上继续演化出 Rep-PAN 与 Efficient Decoupled Head,结合可重参数化的卷积骨干(EfficientRep/RepBlock),在工业部署上进一步压缩推理开销。说明 v6 仍紧扣 v4 的 PAN 思路,但以重参数化与解耦头把性能与部署友好性拉满。
4.4 大规模架构与可训练“免费包”(YOLOv7)
- YOLOv7(2022/2023):提出 E-ELAN 以提升参数利用率与梯度流,并系统性整合“可训练的 bag-of-freebies”(例如辅助头/重参数化训练等),在 5–160 FPS 范围内刷新实时 SOTA。它延续了 v4 的“工程 + 训练技巧并重”路线,但把训练期技巧做成“可训练组件”。
4.5 全面 Anchor-free 与头部升级(YOLOv8)
- YOLOv8(2023):默认 Anchor-free 与解耦式 Head,并在骨干/颈部做现代化轻量设计,减少锚框调参负担,提升泛化与易用性。可理解为:把 YOLOX 的核心理念产品化并完善到全任务栈。
4.6 关注信息瓶颈与梯度的“可编程化”(YOLOv9)
- YOLOv9(2024):从信息瓶颈与可逆函数视角出发,提出 PGI(Programmable Gradient Information) 与 GELAN 骨干,强调在训练目标处恢复更完整的信息以获得更可靠的梯度,进一步提升检测精度与轻量模型的参数效率。与 v4 的工程/数据增强取向不同,v9 把“梯度可用性”提升为一等公民。
4.7 走向“端到端、免 NMS”的训练闭环(YOLOv10)
- YOLOv10(2024):提出一致度量的双重标签分配,实现NMS-free 训练/推理,削减后处理延迟与冗余框,推动单阶段 YOLO 向真正端到端迈进;同时以“效率-精度协同设计”梳理各部件。可视作对 v4 时代“后处理 + NMS”范式的结构性替代。
4.8 其它重要分支:PP-YOLOE
- PP-YOLOE(2022):在 PP-YOLOv2 基础上引入可扩展骨干-颈部、高效 Task-Aligned Head 与动态标签分配等,整体为 Anchor-free,在产业化部署上对 v4 思路(单阶段 + 工程化)做了另一条路的强化。