YOLOv7(2022):可训练的“免费午餐”策略为实时目标检测器树立了新的标杆,高性能检测
导出时间:2025/11/23 20:29:37
1、研究背景与动机
一、现实背景:实时目标检测的需求
目标检测是计算机视觉的“基础能力”,很多场景都离不开它,比如:
- 自动驾驶:识别路上的行人、车辆、交通灯。
- 机器人:感知周围环境、抓取物体。
- 医学影像:检测肿瘤、病灶区域。
- 安防监控:实时发现可疑行为。
这些场景有一个共同点:必须“又快又准”。
也就是说,模型要在有限的硬件(比如手机 CPU、边缘 GPU)上,既能高速运行,又能保证精度。这就是为什么 YOLO 系列一直主打 实时检测
二、技术背景:YOLO 系列的演进
回顾 YOLO 的发展:
- YOLOv1–YOLOv3:解决了“能跑起来”的问题,但精度还不够。
- YOLOv4:通过一堆技巧(CSPNet、Mosaic 数据增强等)提升了精度和速度的平衡。
- YOLOv5:更工程化,易用,支持不同大小的模型。
- YOLOX、YOLOR:探索了 动态标签分配、隐知识等新训练方法,进一步提升效果。
但这些方法大多 专注于改架构(模型设计) 或 推理性能优化。
一个明显的问题是:训练环节的优化没有被充分利用。比如一些能在训练中提高模型表现的小技巧(称为 bag-of-freebies,可训练的免费礼物),往往被忽视
三、YOLOv7 的动机
作者提出 YOLOv7 的主要出发点有三个:
- 不止优化架构,还要优化训练流程
以往的模型大多在“结构”上下功夫(加层、改 backbone),但 YOLOv7 认为:
训练阶段也能做很多优化,而且这些优化不会增加推理成本。
比如:
- 重新参数化(re-parameterization):训练时用复杂结构帮模型学习,推理时合并成简单结构。
- 动态标签分配:智能地把训练目标分给不同层的预测头。
这类方法相当于“训练时给模型戴上辅助轮,跑起来后把辅助轮卸掉”,最终既不增加速度负担,还能提升精度。
- 解决新问题
随着 YOLOX、YOLOR 的提出,一些新问题暴露出来:
- 重参数化怎么用在不同网络层? 有些层加了反而破坏结构。
- 动态标签分配如何处理多分支预测头? 不同层级的预测头该怎么分配训练目标?
YOLOv7 提出新的策略来解决这些训练难题,比如“粗到精的标签分配”
- 适配多种硬件,从边缘到云端
不同应用对速度和精度要求不同。YOLOv7 设计了 从轻量(tiny)到大规模(E6、D6) 的多个版本,覆盖手机、边缘设备到云端 GPU 的需求。这种扩展能力来源于它提出的 复合缩放方法(同时调整深度和宽度,让结构更均衡)
2、核心创新点总结
一、核心创新点总览
YOLOv7 的主要贡献可以概括为四大方面
- 可训练的“免费礼包” (bag-of-freebies)
- 在训练时加入一些特殊模块和方法,提升模型精度。
- 这些改进只增加训练成本,不会增加推理成本。
- 针对新问题提出新方案
- 重参数化模块替代问题:不同网络结构如何安全替换卷积层。
- 动态标签分配问题:多输出分支的标签该如何分配。
- 提出 计划式重参数化 和 粗到精引导式标签分配 两大新方法。
- 高效的模型扩展与复合缩放方法
- 提出了 E-ELAN 架构,保证梯度流稳定。
- 提出新的 复合缩放策略,能更高效地利用参数和算力,让模型在不同规模下都表现优异。
- 参数更少,速度更快,精度更高
- 相比同类最先进模型,参数量减少约 40%,计算量减少约 50%,但检测精度更高。
- 系统化设计,从边缘设备到云端 GPU 都有对应版本(tiny、W6、E6、D6 等)。
二、核心创新点通俗解释
- 免费礼包:训练时的“小外挂”
YOLOv7 就像在训练时给模型加了“外挂装备”:
- 辅助轮:训练时多加一些分支或辅助头,帮模型学得更稳,但推理时卸掉,不影响速度。
- 学习加速器:比如重参数化卷积,训练时是“多车道高速路”,推理时合并成“一条快速路”,模型跑得快还更聪明。
👉 效果:模型学得更多,但跑的时候依旧轻快。
- 针对难题的解决方案
- 重参数化问题 以往的方法有点“强行套件”,容易破坏网络原有结构。YOLOv7 提出 计划式重参数化,根据网络层级合理使用,不会乱改。
- 动态标签分配问题
以前多分支预测头各自分配训练目标,容易冲突。YOLOv7 提出 粗到精引导式标签分配:
- 辅助头学“粗粒度”目标,保证不漏掉目标。
- 主预测头学“细粒度”目标,保证精度。 👉 有点像“老师先给你大方向,再带你抠细节”。
- E-ELAN 与复合缩放
- E-ELAN 架构:改进的特征聚合方式,能稳定传递梯度,即使网络很深也不“塌掉”。
- 复合缩放:不是单独调宽度或深度,而是同时考虑,保证平衡。 👉 好比盖楼房,不仅要加层数(深度),还要加横梁(宽度),否则容易“头重脚轻”。
- 轻量化与高效性
- 相比 YOLOR、YOLOX,YOLOv7 用更少的计算就能达到更高精度。
- 从小到大都有版本,适配手机到超级计算卡,真正做到“一套框架,全面覆盖”。
三、简短总结
YOLOv7 的核心创新点可以一句话概括为: 👉 “通过训练时的巧妙设计(免费礼包),解决重参数化和标签分配难题,结合稳定高效的 E-ELAN 与复合缩放,让模型在各类硬件上都能达到又快又准的新高度。”
3、 VoVNet → CSPVoVNet → ELAN → E-ELAN
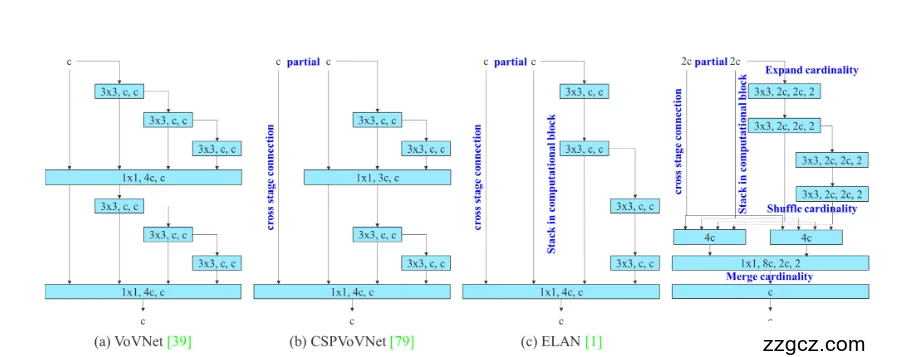
一、背景:为什么要设计 E-ELAN?
在 YOLOv7 之前,目标检测网络普遍使用 VoVNet、CSPVoVNet、ELAN 作为 backbone 的构建单元:
- VoVNet:堆叠卷积层,但层数加深时容易梯度消失/不稳定。
- CSPVoVNet:引入了 Cross Stage Partial (CSP),通过跨阶段连接,缓解梯度问题,同时减少冗余计算。
- ELAN:进一步改进,把卷积堆叠成一个“计算块”,保证梯度在深层网络中依旧能稳定传播。
但是,ELAN 仍然存在问题:
- 结构固定,难以灵活扩展。
- 当模型需要 扩大规模(更深更宽) 时,梯度流可能依然不稳定。
👉 E-ELAN 就是在 ELAN 的基础上,进一步改进以解决深层和大规模扩展时的稳定性问题。
二、E-ELAN 的核心思想
从图 (d) 可以看到 E-ELAN 引入了几组关键设计(蓝色字体标注):
- Expand cardinality(扩展基数)
- 在输入时,将特征通道数扩展,增加信息容量。
- 类比:把原来的一车道扩展成多车道,能同时并行传递更多信息。
- Shuffle cardinality(打乱基数)
- 在中间过程,把通道进行打乱和重新组合,避免某些通道学到的特征“过于孤立”。
- 类比:课堂上把学生重新分组,让他们互相交流,避免“信息孤岛”。
- Merge cardinality(合并基数)
- 在输出时,再把多车道的特征合并,保证信息重新汇聚。
- 类比:不同小组讨论完,再开全班大会,把结果合并。
- Stack in computational blocks(堆叠计算块)
- 每个分支继续使用堆叠卷积块,保持深度特征提取能力。
👉 通过 扩展—打乱—合并 的策略,E-ELAN 实现了 在网络深度和宽度扩展时,依然能保持梯度流动稳定。
三、与前面结构的对比
- VoVNet:单纯堆叠卷积,梯度容易阻塞。
- CSPVoVNet:部分跨阶段连接,缓解了梯度消失。
- ELAN:分组卷积 + 堆叠,保证了更深的梯度流。
- E-ELAN(YOLOv7 使用):
- 更进一步,引入 “扩展—打乱—合并” 三部曲。
- 在大规模扩展时,梯度依旧稳定。
- 特征融合更充分,参数和计算利用率更高。
四、直观类比
你可以把 E-ELAN 想象成一个 多人协作的学习系统:
- Expand:让更多学生进来上课(扩展信息容量)。
- Shuffle:把学生打乱分组,互相交流(避免信息冗余)。
- Merge:最后开大会,把大家的成果汇总(融合信息)。
这样,既保证了“班级规模扩展”时学习不会混乱,又能让知识点学得更全面、更高效。
五、总结
E-ELAN 是 YOLOv7 中的关键 backbone 模块,它的核心贡献是:
- 通过 扩展—打乱—合并 的结构设计,让网络在扩展时依然稳定。
- 在保证梯度流畅传递的同时,提高了特征表达的多样性和利用率。
- 支持 大规模网络扩展,为 YOLOv7 提供了更强的表达能力和更好的速度/精度平衡。
4、网络架构详解
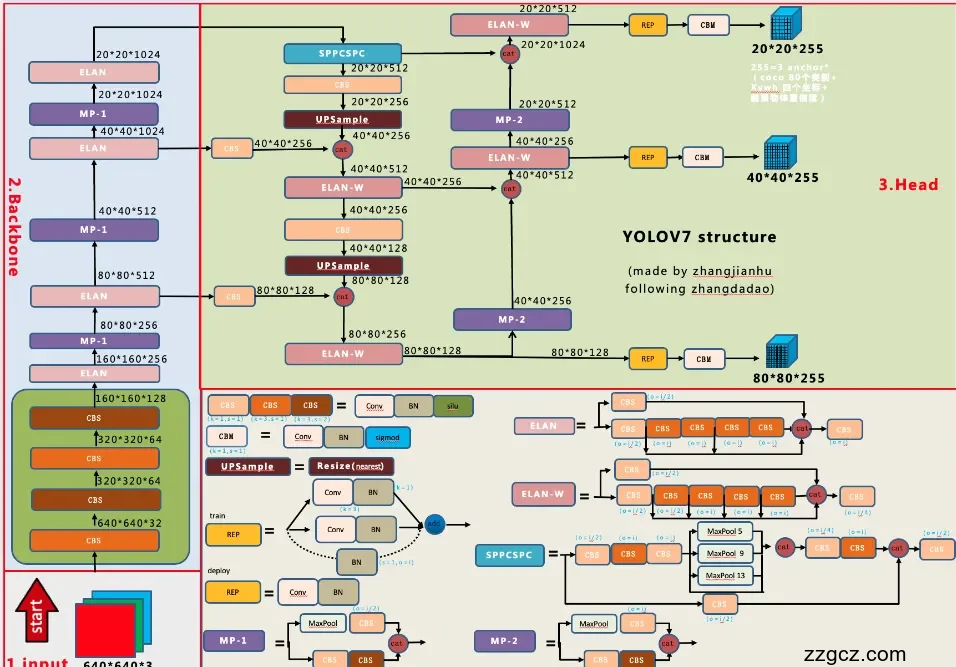
一眼看全图(分区)
- 左下角绿色框:Stem(输入 640×640×3,经几层卷积进入主干)
- 左侧紫色竖条:Backbone(多次“ELAN + MP-1”下采样)
- 中间红框:Neck(FPN/PAN 式的上下采样融合,含 SPPCSPC、ELAN-W、MP-2)
- 右侧黄框:Head(3 个尺度:80×80、40×40、20×20 的检测输出)
Stem(输入层)
- 输入是 640×640×3,Stem 用多层 CBS(Conv-BN-SiLU)逐步提取浅层特征并做第一次降采样,得到较厚的基础通道数,便于后续堆叠(图中绿色框“CBS×N”)。
- YOLOv7 主干/大模型默认使用 SiLU 激活,小模型(tiny)才用 Leaky ReLU
图例对齐: CBS = Conv + BN + SiLU;后文出现的 CBM 在不同复现中常仍表示 Conv+BN+激活(图例写法差异不影响理解)。
Backbone(主干)
Backbone 由若干个 ELAN 块 + MP-1 下采样串联而成,典型分辨率流(以 640 输入为例):
- Stage-1:ELAN → 特征图约 320×320
- Stage-2:MP-1 下采样(×1/2)→ ELAN → 160×160
- Stage-3:MP-1 → ELAN → 80×80(记作 P3)
- Stage-4:MP-1 → ELAN → 40×40(记作 P4)
- Stage-5:MP-1 → ELAN → 20×20(记作 P5)
3.1 ELAN / E-ELAN 是什么?
- ELAN 的核心是“控制最短梯度路径长度”,通过在一个“计算块”里把多条卷积分支并行堆叠再拼接,确保网络加深后梯度仍稳定,训练不塌陷。
- E-ELAN 是 ELAN 的升级版:在块内部做“扩展基数(Expand)→ 打乱基数(Shuffle)→ 合并基数(Merge)”,在不改变原始梯度路径的前提下提升学习能力与参数/算力利用率;这也是 YOLOv7 能安全变“大”的关键
- 你图上在 Neck 里用的 ELAN-W 就是 E-ELAN 思想的“更宽的”变体,专门用于多尺度融合(见下一节)。
3.2 MP-1(带信息保留的下采样)
- MP-1 不是只做 MaxPool,它通常走两条并行路径:
- MaxPool 通道
- 带步长的卷积通道 最后拼接,这样在降采样的同时保留更多上下文与梯度通路,比“只池化或只步长卷积”更稳更富信息。
小结:Backbone 以 ELAN/E-ELAN 的堆叠为主体,靠 MP-1 平滑地下采样,输出 P3/P4/P5 三层语义逐渐加深的特征。
Neck(特征金字塔融合)
YOLOv7 的颈部是 自顶向下 + 自底向上 的 PAN/FPN 结构,模块上由 SPPCSPC、ELAN-W、MP-2、Upsample、Concat 组成。
4.1 顶端大感受野:SPPCSPC(20×20)
- 在最顶层 P5(20×20) 上使用 SPPCSPC(YOLOv4 系的 SPP 变体):多尺度池化 + CSP 化的跨阶段连接,显著扩大感受野,利于检测大目标与整图上下文
4.2 自顶向下融合(FPN 路径)
- P5 → 上采样到 40×40,与 Backbone 的 P4(40×40) Concat,进入 ELAN-W 融合,得到新的 40×40 特征。
- 再 上采样到 80×80,与 P3(80×80) Concat,再过 ELAN-W 融合,得到新的 80×80 特征。
- ELAN-W:以“更宽的 E-ELAN”来做深/宽并行聚合,保证多尺度信息融合时仍有稳定的梯度路径与高效的参数利用。
4.3 自底向上增强(PAN 路径)
- 在 80×80 特征上用 MP-2 下采样到 40×40,与前一步的 40×40 特征 Concat → ELAN-W
- 再 MP-2 下到 20×20,与顶端分支的 20×20 Concat → ELAN-W
- MP-2 与 MP-1 思想相似,但更贴合 PAN 的“回流增强”,让低层(细粒度)信息回流补强高层(语义强)特征。
效果:这一套 FPN+PAN +(ELAN-W/MP-2)的组合,让 P3(80)、P4(40)、P5(20) 三层都兼具细节与语义,对小/中/大目标都更友好。
Head(检测头,三尺度输出)
- 三个输出分辨率:80×80(stride 8)/ 40×40(stride 16)/ 20×20(stride 32)。
- 每个尺度进入一个 REP → CB → Detect* 的小尾巴:
- REP:计划式重参数化卷积(RepConvN)——训练时是“多分支卷积”(更好学),推理时合并为单卷积(不增耗时);并且在有残差/拼接连接的层去掉恒等分支,避免破坏结构,这是 YOLOv7 的“计划式使用”要点
- Detect:默认 anchor-based,每尺度 3 个 anchor,输出通道为 (nc + 5) × 3(COCO 为 255,如你图中所标)。
为什么这样做? REP 让 训练更强、部署更快,是 YOLOv7 “可训练的免费礼包(bag-of-freebies)”之一;而三尺度检测继承 YOLO 家族的实时性与多尺度覆盖。
训练期的“辅助头”(只在训练用)
- 在颈部某些中间层(你图上「aux」位置)会接 辅助预测头 做 深度监督,训练更稳更快;
- 标签不是简单拷贝,而是用 “粗到精的引导式标签分配”:辅助头学粗粒度(高召回),主头学细粒度(高精度),并设置上界约束避免先验偏置;推理时这些辅助头被移除,因此不增加推理成本
图中模块速查表
- CBS:Conv + BN + SiLU(主力积木)
- ELAN / ELAN-W:E-ELAN 家族的块;W 表示“更宽”的融合块
- MP-1 / MP-2:带双分支并再拼接的下采样(保信息、稳梯度)
- SPPCSPC:多尺度池化 + CSP 的大感受野模块
- Upsample / Concat:金字塔上下流的常规操作
- REP:计划式重参数化卷积(训时多分支,测时合并)
- Head:三尺度输出(80/40/20),每尺度 3 anchors,输出维度 = (nc+5)×3(COCO=255)
这套架构为什么效果突出(直观总结)
- E-ELAN 保障“越深越稳、越宽越高效”的特征学习;
- SPPCSPC + ELAN-W + PAN/FPN 让三层特征既有细节又有语义;
- 计划式重参数化(REP)+ 辅助头深度监督 把“训练的强”和“推理的快”兼得(训练时强力、部署时零额外开销)。 这些设计共同把 YOLOv7 的速度/精度推到了新的平衡点
5、YOLOv7 的严重缺陷
虽然 YOLOv7 在 2022 年发布时达到了当时实时目标检测的 SOTA(速度与精度双优),但它依然存在一些明显的问题:
1. 结构复杂,难以复现与部署
- YOLOv7 使用了 E-ELAN、ELAN-W、SPPCSPC、REPConv、辅助头 等大量定制化模块。
- 对研究人员和工程应用来说,复现难度高,训练细节多(比如“计划式重参数化”的使用位置、粗到精的标签分配规则),容易出错。
- 对工业部署,过度复杂的结构在某些硬件(特别是移动端、嵌入式)上优化困难。
👉 缺陷点:工程友好度不高。
2. 依赖 Anchor,增加计算与调参成本
- YOLOv7 仍然是 anchor-based 的检测头(COCO 输出通道=255)。
- Anchor 的设计与匹配机制比较复杂,需要手工调参或额外自动 anchor 搜索。
- 在面对不同数据集时,泛化性较差,迁移麻烦。
👉 缺陷点:Anchor 成为瓶颈。
3. 小目标检测不足
- 虽然有三尺度检测,但 backbone/neck 主体仍然偏重中大目标。
- 对密集小目标(比如无人机航拍、交通监控场景),召回率不足。
👉 缺陷点:小目标表现不够优。
4. 训练资源消耗大
- YOLOv7 在大模型上需要非常高的显存和计算资源。
- 虽然训练时引入了“辅助头”和“bag-of-freebies”,但整体训练过程仍偏重资源,不适合轻量级设备端到端自训练。
👉 缺陷点:训练门槛高。
5. 缺少 Transformer / Attention 融合
- YOLOv7 完全基于 CNN,缺乏当时正在兴起的 Transformer(自注意力机制) 融合。
- 导致它在建模全局依赖、长距离上下文关系时不如混合架构(如 YOLOv6-NAS、DETR 系模型)。
👉 缺陷点:对全局建模不足。
6、后续模型如何基于 YOLOv7 改进
YOLOv7 的这些不足直接推动了后续 YOLO 家族的创新。核心改进方向主要有以下几点:
1. YOLOv8:Anchor-free 与轻量化
- 抛弃 Anchor:YOLOv8 改为 anchor-free,预测目标的中心点 + 宽高,不再依赖繁琐的 anchor 设计。
- 结构更简洁:放弃了 YOLOv7 的 ELAN 系列模块,采用更常规的 C2f(Cross Stage Partial + ELAN 融合)模块,更易用。
- 迁移更容易:Anchor-free 让迁移到新数据集几乎不用调参。
👉 解决了 YOLOv7 的 Anchor 依赖 与 工程复杂度高 问题。
2. YOLOv9:规划式梯度流优化 + 更好的训练稳定性
- 提出了 Programmable Gradient Information (PGI),比 YOLOv7 的 E-ELAN 更进一步地控制梯度流动,训练更稳。
- 提出 Generalized ELAN (GELAN),改进 E-ELAN 的扩展方式,让结构更简洁同时保持梯度优势。
👉 在 YOLOv7 的 E-ELAN 基础上继续优化,解决了 结构过于复杂、扩展受限 的问题。
3. YOLO-NAS / RT-DETR:融合 Transformer
- YOLO-NAS 引入 神经架构搜索 (NAS) 与 注意力机制,在保持速度的同时更好适配不同硬件。
- RT-DETR(实时版 DETR)用 Transformer 替代检测头,简化 pipeline,提高小目标与全局感知能力。
👉 弥补了 YOLOv7 缺乏 Transformer 融合 的不足。
4. 小目标优化(YOLOv5/YOLOv8 的分支 + 改进 FPN/PAN)
- 引入 更浅层特征 融入检测头(P2 层,160×160)。
- 通过改进 PAN/FPN 的路径聚合,使小目标检测更强。
👉 改进 YOLOv7 在 小目标检测不佳 的缺点。