GCNet(2017):用于深度立体回归的几何与上下文端到端学习,双目深度估计起点
导出时间:2025/11/24 09:09:08
1、GCNet 的背景和动机
1.1、背景:从单目到双目
- 你已经学过的 Monodepth v1/v2 和 DPT 都是 单目深度估计 方法。它们通过学习数据分布和语义上下文,从一张单目图像预测深度图。
- 优点:只需要一台相机,应用场景更灵活。
- 缺点:缺少真实几何约束,预测结果依赖网络学到的先验(比如“车一般有多大、道路一般多平”)。一旦遇到新环境或者不常见物体,深度预测容易偏差。
- 与之相比,双目深度估计(Stereo Matching) 是通过 一对校正好的双目图像 来估计深度。这里的关键是找到两张图中同一个点的匹配关系(视差)。视差越大,目标越近。
- 优点:几何关系真实、明确,不需要纯粹靠“猜”。
- 难点:实际场景复杂(无纹理区域、反光、遮挡、重复图案),很难保证像素级匹配的鲁棒性
1.2、传统立体匹配的局限
在深度学习之前,立体视觉通常分为几个步骤:
- 匹配代价计算(比如像素差、Census、SAD)。
- 代价聚合(平滑、窗口卷积)。
- 视差优化(图割、置信传播、半全局匹配 SGM)。
- 后处理(左右一致性检测、填补空洞)。
这些方法的局限性:
- 手工设计的代价函数和正则化方法比较“死板”。
- 在大面积无纹理区域(比如蓝天)、反光(玻璃)、细小结构(电线)等场景下很容易失败
- 为了平滑和细节常常需要权衡,结果要么过度模糊,要么过于噪声。
1.3、深度学习的启发
深度卷积网络(CNN)在分类、检测、分割上已经证明了强大的“上下文理解”能力。
→ 研究者们想到:能不能用 CNN 来“替代”传统立体匹配中的每一步?
- 不只是算局部匹配,而是直接学习全局上下文;
- 不只是后处理平滑,而是通过网络自己学会正则化。
之前有一些深度方法尝试:
- MC-CNN(孪生网络匹配图像块),但还需要传统后处理。
- DispNetC(端到端网络),引入相关层来近似代价体积,但没能充分利用几何信息。
这些方法还没彻底摆脱“拼接手工模块 + 学习特征”的模式
1.4、GCNet 的核心动机
GCNet 提出一个关键问题:
能不能构建一个 端到端网络,既利用立体几何的明确约束,又能从数据中学习上下文语义,从而一步到位得到高精度深度图?
于是他们设计了:
- 几何约束:通过构建 代价体积 (cost volume),保留每个像素在不同视差下的匹配可能性,这是立体几何的天然表示。
- 上下文建模:在代价体积上用 3D 卷积,在空间(H×W)和视差(D)三个维度同时学习正则化,捕捉局部+全局上下文。
- 端到端回归:通过可微分的 soft-argmin 层直接回归视差,而不是分类或后处理。这样可以达到 亚像素级别精度,并且训练时能端到端反向传播。
换句话说:
- 传统方法 = 手工 + 分阶段 → 易碎。
- Monodepth/DPT = 全学习,但缺少几何 → 有先验偏差。
- GCNet = 几何 + 学习上下文 + 端到端 → 在 KITTI 上刷新 SOTA,运行速度也快
✅ 总结一句话: GCNet 的动机就是要解决“传统立体方法缺乏语义理解”和“早期深度方法没充分利用几何约束”的矛盾,提出一个 端到端几何+上下文网络,让深度学习真正学会立体视觉。
2、GCNet 的核心创新点
1. 代价体积 (Cost Volume) 构建
专业讲解:
GCNet 把左、右图像经过 2D CNN 提取的特征,在所有可能的视差位置上进行对齐,并在每个视差处拼接特征,形成一个三维空间 (H×W×D) 的 代价体积。相比于早期方法只用点积或相似度,这样能完整保留匹配的丰富信息。
形象化比喻:
想象你要对齐两张错位的半透明图纸。传统方法只看“重叠部分像不像”;GCNet 的做法是——不管像不像,都把它们整页贴进一本“候选相册”,让后面的大脑慢慢挑。这就像把所有可能的拼图碎片先收集起来,而不是立刻丢掉那些“看起来不对”的。
2. 3D 卷积正则化
专业讲解:
GCNet 在代价体积上使用 3D CNN 编解码结构(类似 U-Net),在高 (H)、宽 (W)、视差 (D) 三个维度上同时卷积。这不仅利用了像素之间的空间邻域关系,还能建模不同视差假设之间的关联,最终得到更光滑、语义合理的代价分布。
形象化比喻:
把代价体积想象成一本“厚书”,每一页对应一个视差假设。传统方法是逐页翻;GCNet 的 3D CNN 像一个扫地机器人,不光横着扫每页的内容,还能上下贯通,把多页之间的矛盾和空白都清理掉,让整本书逻辑通顺。
3. Soft-Argmin 回归
专业讲解:
传统立体匹配最后会用 argmin 选择代价最小的视差,但 argmin 不可微分,且只能得到像素级结果。GCNet 提出了 Soft-Argmin:
- 先对代价沿视差维度做 softmax,得到概率分布;
- 再对所有视差做加权平均,得到期望值作为预测视差。 这样不仅可端到端训练,还能实现亚像素级精度。
形象化比喻:
传统方法像是“只挑最低的山谷”作为答案,而 Soft-Argmin 更像“看整个山谷群的形状,算出重心在哪里”。这样即便有多个小谷地,它也能算出一个平滑、合理的“中心”,而不是死板地只认某一个点。
4. 端到端设计
专业讲解:
早期方法往往把“特征学习”和“视差优化”分开,需要额外的人工规则(如 SGM 后处理)。GCNet 把特征提取、代价体积、正则化、视差回归全放在一个可微框架里,实现真正的端到端学习。
形象化比喻:
以前做立体匹配像流水线:一人切菜、一人炒、一人加盐,各司其职但容易出错。GCNet 则像一个智能厨师机器人,从洗菜到端盘全包揽,一气呵成,味道稳定还省事。
✅ 总结
- 专业角度:GCNet 创新点在于 (1) 拼接特征代价体积,(2) 用 3D CNN 做正则化,(3) Soft-Argmin 回归可微+亚像素,(4) 真正端到端。
- 形象角度:一本“厚书”+“扫地机器人”+“找重心”+“智能厨师” → 帮助我们记住它的核心亮点。
3、GCNet 模型网络结构(结合图解)
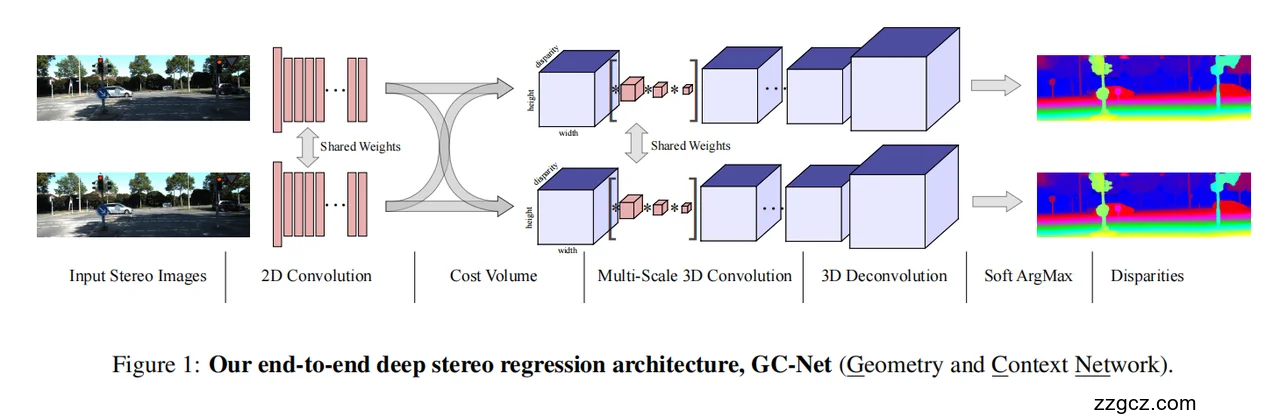
1. 输入双目图像 (Input Stereo Images)
- 专业讲解:输入是左右相机拍摄的两张校正后的图片(左图、右图)。目标是预测每个像素的视差(即深度)。
- 形象比喻:就像我们人类的双眼同时看到同一场景,只是视角有一点偏差。
2. 2D 卷积特征提取 (2D Convolution with Shared Weights)
- 专业讲解:左右两张图先分别通过 共享权重的 2D CNN 提取特征。这保证了左右图得到的特征在同一空间里,可以对齐比较。提取到的是更鲁棒的表示(边缘、纹理、语义信息)。
- 形象比喻:好比在两张相似的地图上都用荧光笔标记了关键地标(树、车、建筑),而且两张地图用的标记方法完全一致。
3. 代价体积 (Cost Volume)
- 专业讲解: 将右图的特征在不同视差 d 下逐像素平移,与左图特征拼接,形成一个 4D 张量:
- H×W×D×F
- 这里 H、W 是图像高宽,D 是最大视差范围,F 是特征维度。 这样每个像素在每个视差假设下的匹配可能性都被保留下来。
- 形象比喻:像是制作一本“厚书”,每一页都对应一个可能的视差,把所有可能的对齐情况都记录下来,而不是只挑一个“最可能的”。
4. 多尺度 3D 卷积 (Multi-Scale 3D Convolution)
- 专业讲解:
在代价体积上使用 3D CNN 编解码结构:
- 下采样 → 提取更大范围上下文(全局一致性)。
- 上采样 → 恢复细节,并通过跳跃连接保留局部信息。 这样可以同时利用空间 (H×W) 和视差 (D) 维度的信息,对代价体积进行正则化,增强语义一致性。
- 形象比喻:想象一个“扫地机器人”,不仅横着扫整张书页,还会上下贯通所有书页,把错误的候选抹掉,让整个书卷逻辑清晰,避免杂乱。
5. 3D 反卷积 (3D Deconvolution)
- 专业讲解: 经过多尺度 3D 卷积后,特征分辨率变低。通过 3D Deconvolution(上采样),逐渐恢复到原始的空间和视差分辨率。 这样最后输出的代价体积与原始图像大小一致,可以逐像素预测视差。
- 形象比喻:就像放大一张压缩的照片,但同时利用“记忆中的细节”把边缘补回来,不至于模糊。
6. Soft ArgMax
- 专业讲解:
- 传统 argmin:选择代价最低的视差 → 不可微分,只能得到整数像素。
- GCNet:通过 softmax 把代价转化为概率分布,再加权平均求期望 → 可微分 & 支持亚像素精度。
- 形象比喻:
- Argmin 像“只选最低的山谷”;
- Soft-Argmin 像“看整片山谷的形状,找出重心位置”,更精细也更平滑。
7. 输出视差图 (Disparities)
- 专业讲解:最终输出是一张与输入图像大小相同的视差图,每个像素的值代表预测的视差(间接就是深度)。
- 形象比喻:就像给整个场景画了一张“立体地图”,告诉我们每个物体离相机有多远。
✅ 总结(顺着图的流程)
- 左右图像 → 共享 2D CNN 提特征(做标记)。
- 构造 代价体积(装订成厚书)。
- 用 3D CNN 在空间 & 视差维度一起清理、整合信息(扫地机器人)。
- 3D Deconvolution 恢复分辨率(还原细节)。
- Soft-Argmin 求重心(平滑、亚像素、可微)。
- 输出 视差图(场景深度)。
4、GCNet 的主要缺陷
- 计算和显存开销大
- 代价体积是 4D 张量 (H×W×D×F),再用多层 3D 卷积处理 → 显存和计算量非常大。
- 在高分辨率图像和大视差范围下,几乎难以部署到实时应用(如自动驾驶、AR/VR)。
- 🔎 类比:像写一本“超厚的字典”,每次查一个词都得把厚书翻来翻去,非常耗时。
- 对纹理缺失区域仍有挑战
- GCNet 引入了 3D CNN 上下文,但在 大面积无纹理(天空、墙面)或重复纹理(栅栏、道路标线) 区域,代价体积的匹配仍然会产生歧义。
- 没有引入额外的语义监督或全局约束。
- 🔎 类比:就算厚书里写得很详细,但如果几页内容都长得差不多,读者还是容易“认错页码”。
- 长距离依赖建模不足
- 3D CNN 的感受野有限,要捕捉更大范围的全局几何结构,网络需要堆叠更多卷积层,进一步增加开销。
- 对于跨大范围的遮挡区域,GCNet 很难利用远处的语义联系来推理。
- 🔎 类比:扫地机器人虽然能扫一片区域,但它“记不住整栋楼的格局”,全局推理能力有限。
- 缺少显式几何/语义先验
- GCNet 是纯粹的数据驱动,没有结合显式的几何一致性损失或语义信息。
- 在稀疏 GT(如 KITTI)上效果好,但泛化到新场景或噪声图像时表现不够稳健。
- 🔎 类比:靠“背书”学会了很多套路,但没有真正理解物理规则,一旦遇到“新题型”就容易出错。
5、后续基于 GCNet 的改进模型
1. PSMNet (Pyramid Stereo Matching Network, CVPR 2018)
- 引入 空间金字塔池化 (SPP) 捕捉多尺度上下文信息。
- 使用 3D CNN + hourglass 结构 进一步增强全局正则化能力。
- 相比 GCNet,在 KITTI 等基准上显著提升。 🔎 类比:PSMNet 给“扫地机器人”配了多层地图(大视野+细节),能既看全局又看细节。
2. GANet (Guided Aggregation Network, CVPR 2019)
- 提出 局部引导聚合 (LGA) 和 非局部引导聚合 (NGA),增强在无纹理区域和边界处的表现。
- 在代价体积正则化时更注重几何边界和结构感知。 🔎 类比:GANet 相当于给扫地机器人配了“激光测距仪”,在平滑大面积地板和复杂边角处都更聪明。
3. 轻量化网络
(为了解决 GCNet 太重、太慢的问题)
- StereoNet (ECCV 2018):减少代价体积维度,用少量 3D CNN。
- AnyNet, AANet:引入 逐级 refinement(逐层细化),先粗后细,逐步预测视差。 🔎 类比:先画一张粗略地图,再逐步加细节,而不是一开始就写满“百科全书”。
4. 基于 Transformer 的模型
(解决 GCNet 全局建模不足)
- STTR (CVPR 2021):用 Transformer 做序列匹配,直接在行上做 attention,捕捉长程依赖。
- RAFT-Stereo (NeurIPS 2021):借鉴光流 RAFT,用 recurrent update 模块迭代优化匹配。 🔎 类比:这些方法让“扫地机器人”变成“无人机”,可以从全局鸟瞰整个场景,理解远处的关系。
5. 语义增强的模型
- 一些后续工作结合 语义分割特征,增强在无纹理/反射区域的推理能力。
- 例如 SegStereo (ECCV 2018) 在代价体积上引入语义特征作为辅助。 🔎 类比:如果机器人知道“这块是车,那块是路”,就能更聪明地判断谁离得更远。
✅ 总结
- GCNet 的主要缺陷:显存/算力开销大、对无纹理/重复区域依然薄弱、全局建模不足、缺乏显式先验。
- 后续改进方向:
- 更强上下文建模 → PSMNet (SPP + Hourglass)
- 几何感知正则化 → GANet (LGA/NGA)
- 轻量化和速度优化 → StereoNet, AANet
- 全局依赖建模 → STTR, RAFT-Stereo
- 结合语义信息 → SegStereo