PSMNet(2018):空间金字塔池化赋能立体匹配
导出时间:2025/11/24 09:09:22
1、研究背景与动机
(1)从单目到双目的过渡
你已经学过单目深度估计:
- 优点:只需要一张图像,应用广泛(相机、手机即可)。
- 缺点:本质上是一个 病态问题 ——单张图像没有几何约束,深度只能靠数据学习和先验,所以结果往往只有相对深度,缺乏精确度量能力。
👉 因此,研究者继续探索 双目立体视觉:利用两张图像的视差,直接提供几何约束,可以得到更精确的深度估计。
(2)GC-Net 的贡献与不足
你已经学习过 GC-Net,它是第一个真正意义上把深度学习引入到立体匹配的完整框架。
- 贡献:提出了“代价体 (Cost Volume)”的概念,并用 3D CNN 来做端到端的视差回归。
- 不足:
- 上下文信息不足:GC-Net 虽然能建模三维代价体,但依然偏“局部”,对于大范围的纹理缺失/重复区域,鲁棒性不够。
- 结构相对简单:缺少强大的多尺度上下文融合机制。
(3)PSMNet 出现的背景
针对 GC-Net 的不足,研究者发现:
- 在立体匹配中,仅靠局部纹理特征是不够的。例如:白墙、天空、栏杆这些区域,没有清晰的纹理信息,模型很容易预测错误。
- 需要 全局上下文信息 来辅助判断:
- 比如“这片大区域可能是天空 → 应该很远”;
- “这是道路表面 → 应该是连续的平面”。
因此,PSMNet 提出:
- 引入空间金字塔池化(SPP) ——获取多尺度的上下文信息,让网络既能“看细节”又能“看大局”。
- 堆叠沙漏(Stacked Hourglass)3D CNN ——对整个代价体进行反复的上下文整合和优化,而不是只做一次简单的卷积。
(4)通俗比喻(结合你学过的模型)
- 单目模型(MiDaS 等):像一个“凭直觉作画”的画家,靠经验画出物体的远近,但比例可能不准。
- GC-Net:像一个“工程师”,用尺子量,但只能就地量一小块,对全局环境理解不够。
- PSMNet:像一个“建筑设计师”,既用尺子(几何约束),又看整体蓝图(全局上下文),反复修改设计(堆叠沙漏优化),最后得到更稳健的深度图。
✅ 总结一句话:
PSMNet 的动机在于解决 GC-Net 只能局部匹配、对复杂场景鲁棒性差的问题,通过 多尺度全局上下文(SPP)+ 堆叠沙漏 3D CNN,让双目深度估计在纹理缺失、重复模式、遮挡等场景下更加稳定准确。
2、核心创新点
🔹 1. 引入空间金字塔池化(SPP, Spatial Pyramid Pooling)
- 问题(GC-Net 的不足):GC-Net 提取特征时,主要关注局部窗口,缺少全局上下文。
- 创新(PSMNet):在特征提取阶段加入 空间金字塔池化:
- 用不同大小的池化窗口(比如 64×64、32×32、16×16、8×8),提取多尺度的上下文信息。
- 既能捕捉到局部的细节特征,也能理解整体场景的全局结构。
- 效果:在纹理缺失(白墙、天空)、重复纹理(栅栏、地砖)等区域,模型仍能保持正确匹配。
👉 比喻:SPP 就像“放大镜 + 广角镜”,网络既能近距离看清局部,也能远距离理解整体。
🔹 2. 构建高维度的代价体 (Cost Volume)
- GC-Net:通过特征差异构建了 4D 代价体(Batch × Height × Width × Disparity)。
- PSMNet:改进特征拼接方式,把左右图像特征拼接后输入代价体,信息更丰富。
- 效果:代价体表达能力更强,能更好捕捉左右图的匹配关系。
🔹 3. 堆叠沙漏结构 (Stacked Hourglass 3D CNN)
- 问题(GC-Net 的不足):GC-Net 的 3D CNN 对代价体只做一次卷积正则化,优化能力有限。
- 创新(PSMNet):采用 多阶段“堆叠沙漏”结构:
- 每个沙漏网络都会先下采样(压缩特征,获取全局上下文),再上采样(恢复分辨率),并结合跳跃连接。
- 多个沙漏级联,反复 refine 代价体。
- 效果:对视差估计进行多轮优化,逐步修正误差,让预测结果更精细、更鲁棒。
👉 比喻:沙漏结构就像一个“反复审稿人”,先整体浏览,再逐步修改细节,最后的答案比第一次更可靠。
🔹 4. 端到端的回归机制
- PSMNet 使用 Soft Argmin 回归,把代价体转化为概率分布,然后求加权平均,得到连续视差值。
- 效果:相比传统的“硬匹配”(取最小代价对应的视差),这种方式更平滑,预测结果在边界和纹理模糊处更自然。
🔹 5. 在 KITTI、Scene Flow 上大幅领先
- PSMNet 在当时的主流双目数据集(KITTI 2015、Scene Flow)上超过 GC-Net,表现出显著优势。
- 特别是在复杂场景(重复纹理、无纹理、遮挡)上,PSMNet 的精度和鲁棒性远超前人。
👉 一句话:
PSMNet 在 GC-Net 的基础上,加入多尺度全局上下文(SPP)和多轮全局优化(堆叠沙漏),显著提升了双目深度估计的精度和鲁棒性。
3、模型的网络结构
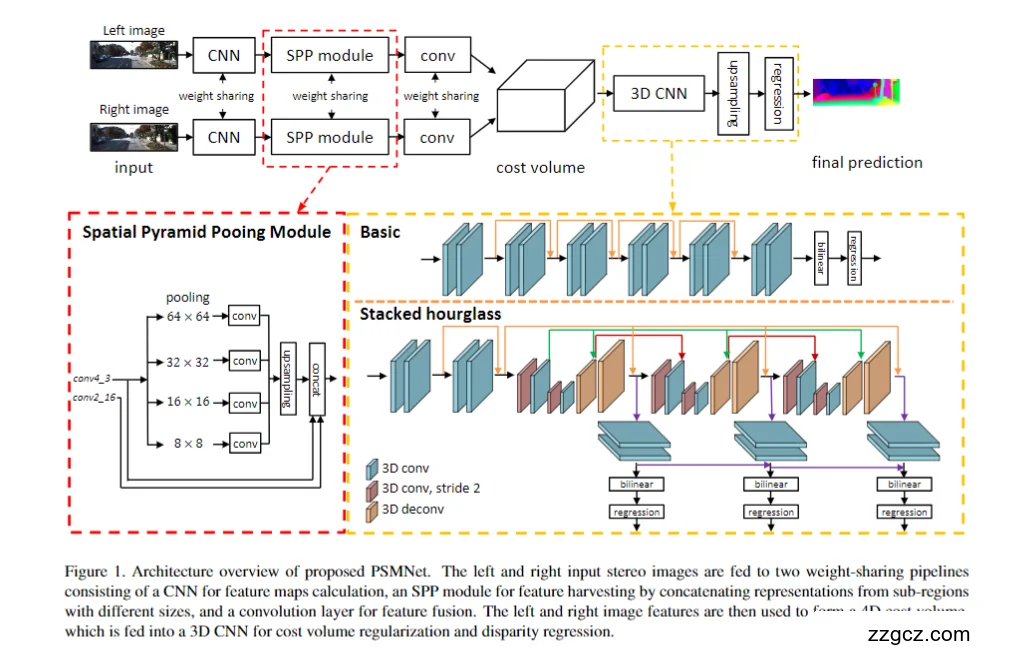
PSMNet 的整体框架可以分为四个主要部分:特征提取 → 空间金字塔池化(SPP) → 代价体构建 → 3D CNN 正则化与视差回归。
(1)特征提取网络 (CNN Feature Extractor)
- 输入:左右两张立体图像。
- 处理:通过一个共享权重的 2D CNN(通常基于 ResNet-50 改造),提取多层次特征图。
- 目的:得到对几何匹配有用的深层特征,而不仅仅是像素强度。
👉 直观理解:这一步就像“把图像翻译成特征语言”,让后续网络更容易判断哪个点和哪个点是对应的。
(2)空间金字塔池化模块 (SPP Module)
- 问题:单纯卷积只能看局部,容易在纹理缺失或重复纹理的区域出错。
- 方法:引入 SPP 模块,用多尺度池化(64×64、32×32、16×16、8×8)来捕捉不同尺度的上下文信息。
- 融合:池化特征经过卷积和上采样后,与原始特征拼接,形成更具全局理解力的特征图。
👉 比喻:像同时戴上了“放大镜”和“广角镜”,网络既能看清细节,又能理解整体布局。
(3)代价体构建 (Cost Volume Construction)
- 将左图特征与不同视差下的右图特征进行拼接,形成一个 4D 代价体(Batch × Height × Width × Disparity × FeatureDim)。
- 代价体记录了 “某个像素在不同视差下的匹配可能性”。
👉 直观理解:就像为每个像素建立一个“候选答案表”,里面记录它在不同视差下匹配的可能性。
(4)3D CNN 正则化与堆叠沙漏 (Stacked Hourglass)
- GC-Net 的做法:只用一个 3D CNN 对代价体卷积一次。
- PSMNet 的改进:采用 堆叠沙漏结构,反复对代价体进行上下文整合。
- 每个沙漏模块都会先下采样(聚合全局信息),再上采样(恢复空间分辨率),并通过跳跃连接融合细节。
- 多个沙漏级联,相当于多轮 refinement(逐步修正)。
- 效果:输出的代价体更光滑、细节更精细。
👉 比喻:就像反复审稿的编辑,每一轮都会发现并修改错误,最终得到更完美的稿件。
(5)视差回归 (Disparity Regression)
- 使用 Soft Argmin 操作,把代价体转化为概率分布,对视差进行加权平均。
- 优点:输出的视差是连续值,而不是离散的整数;预测边界更平滑、自然。
📌 总结
结合图片,PSMNet 的网络结构流程是:
- 特征提取:左右图通过共享 CNN 提取深层特征。
- SPP 模块:引入多尺度上下文,增强全局理解。
- 代价体构建:拼接左右图特征,生成候选匹配空间。
- 3D CNN + 堆叠沙漏:对代价体反复优化,提升鲁棒性和精度。
- Soft Argmin 回归:得到平滑、连续的视差图,最终转化为深度估计。
👉 一句话: PSMNet 在 GC-Net 的基础上,加入 SPP 和堆叠沙漏,使网络既能看到全局上下文,又能多次 refine 匹配,最终获得更精确、更鲁棒的深度结果。
4、存在的重大缺陷
虽然 PSMNet 在提出时性能很强,但它仍然存在一些明显的问题和不足:
(1)计算量和显存开销过大
- PSMNet 依赖 4D 代价体 (H×W×D×C) 和 堆叠沙漏 3D CNN,需要庞大的存储和计算。
- 在高分辨率图像和大视差范围时,显存消耗非常高(几 GB 起步),几乎无法在嵌入式设备或实时场景运行。
- 问题直观理解:代价体像一个“巨大的立体字典”,存储了每个像素所有可能匹配的结果,非常“笨重”。
(2)推理速度慢,不适合实时应用
- 由于网络包含多个沙漏结构,推理过程非常耗时。
- 在自动驾驶、无人机等需要实时深度估计的场景中,PSMNet 基本难以直接部署。
(3)对遮挡和边界的处理仍不足
- 虽然 PSMNet 能通过全局上下文缓解一些问题,但在 遮挡区域 或 物体边界,视差估计仍会出现错误。
- 这说明 PSMNet 的正则化主要是“几何+上下文”,对几何一致性建模和遮挡显式处理仍不足。
(4)泛化能力有限
- PSMNet 在 Scene Flow 和 KITTI 上表现很好,但换到新的数据集(比如室内场景或极端环境),效果会明显下降。
- 这暴露了它对训练数据分布的依赖性。
(5)无法灵活建模长距离依赖
- PSMNet 的堆叠沙漏虽然引入了全局信息,但依赖卷积堆叠,难以捕捉远距离区域之间的依赖关系。
- 例如,场景里两个相隔很远但相似的区域,模型依然可能被迷惑。
📌 总结一句话
PSMNet 的主要缺陷是“重、慢、显存大”,并且在遮挡、边界、长距离建模和泛化性上仍有不足。
5、后续基于此改进创新的模型
🔮 后续改进模型的方向
① GANet (2019)
- 核心思路:引导聚合 (Guided Aggregation)。
- 改进点:通过局部聚合和非局部聚合机制,对代价体进行更高效、更精细的正则化。
- 优势:提升在遮挡和边界区域的表现,减少伪匹配。
② AANet (2020)
- 核心思路:自适应聚合 (Adaptive Aggregation)。
- 改进点:通过轻量化模块动态选择聚合范围,避免使用庞大的 3D CNN。
- 优势:速度更快,显存消耗更小,更适合实时场景。
③ LEAStereo (2020, NAS 方法)
- 核心思路:神经网络架构搜索 (Neural Architecture Search, NAS)。
- 改进点:自动设计双目立体匹配网络的最佳结构,而不是人工手工搭建。
- 优势:在性能和效率之间找到更优平衡,在 KITTI 榜单上取得 SOTA。
④ ACVNet (2021)
- 核心思路:注意力机制 (Attention Concatenation Volume)。
- 改进点:用 Transformer 式的注意力替代部分卷积操作,捕捉长距离依赖关系。
- 优势:更高效地建模全局上下文,减少计算量同时保持精度。
⑤ RAFT-Stereo (2021)
- 核心思路:借鉴 RAFT 光流的迭代优化思想。
- 改进点:通过循环迭代方式不断 refine 视差预测,而不是一次性输出结果。
- 优势:更轻量,逐步优化,预测结果更稳健。
⑥ GwcNet (2019)
- 核心思路:组卷积特征 (Group-wise Correlation)。
- 改进点:在构建代价体时引入分组相关性,替代简单拼接方式。
- 优势:减少计算量,代价体更高效。
📌 总结
从 PSMNet 出发,后续模型的改进大方向可以归纳为:
- 更高效的代价体表示(GwcNet、AANet)。
- 更智能的代价体聚合(GANet、ACVNet)。
- 轻量化与自动化(LEAStereo、RAFT-Stereo)。
- 引入注意力/Transformer 思路(ACVNet,后续还有一些 Hybrid Transformer 模型)。
👉 一句话:
PSMNet 是双目深度估计的里程碑,但后续研究都在解决它“太大、太慢、不够聪明”的问题。