CloudTran++(2024):基于轴变换网络的多时相卫星图像云层去除改进方法
1、研究背景和动机
🌦 一、研究背景:云遮挡仍是遥感影像分析的最大障碍
- 全球 70% 以上的陆地在一年中多次被云层遮挡;
- 特别是热带、沿海、山区地区,云覆盖频繁、形态复杂;
- 导致很多地区长时间无法获得完整观测数据。
就像你要监控城市变化,却总被“雾蒙蒙的天”挡住相机镜头。
🧮 二、现有多时相去云模型的问题
现有问题
| 具体表现
|
(1) 时序特征融合不充分
| 很多模型只简单地“堆叠多帧输入”,或用卷积 / 平均融合,不能捕捉到真正的时间依赖(比如:第 1 天有云,第 3 天无云,但第 2 天局部变化)。
|
(2) 缺乏长时依赖建模能力
| CNN 或 U-Net 只能看到局部窗口,无法理解“几天前的地表状态”与“今天的变化关系”。
|
(3) 特征对齐不精准
| 不同日期图像存在视角差、光照变化、季节差异。很多模型没有显式的时间对齐机制,容易融合出模糊或错位图像。
|
(4) 计算复杂、模型笨重
| Transformer 虽强,但计算代价高、推理慢,不适合处理高分辨率遥感影像。
|
(5) 缺乏大规模真实多时相数据集支持
| 多时相、无云对照数据稀缺,模型泛化能力有限。
|
🚀 三、研究动机:让 Transformer 真正理解“时间中的地球”
🌍 “遥感图像不是静态的照片,而是地球在时间轴上的动态片段。”
- 捕捉时间序列中云的演变与地物的不变性;
- 理解哪些变化是“云的变化”,哪些是“地物变化”;
- 并且在推理阶段快速、高效地恢复清晰影像。
CloudTran++ 的关键思想:利用 时序注意力(Temporal Attention) + 跨时间特征交互(Cross-temporal Interaction),让模型学会“在时间维度上对齐、比较、选择、融合”信息。
🧠 四、CloudTran++ 的动机核心概念拆解
- 时序建模的本质:区分“云变”和“地变”
- 云的形状、亮度、覆盖范围变化快;
- 地物的结构、纹理相对稳定;
- 因此模型需要能在时间序列中找到这些稳定特征。
- 传统方法:把时间当作“多张照片”
- CNN 把多帧叠在一起处理,相当于“混合曝光”;
- Transformer 虽然能建模关系,但往往忽略了时间方向的顺序性。
- CloudTran++ 的目标:让模型“读懂时间”
- 引入了时序交互注意力模块(Temporal Cross-Attention Block);
- 它能自动学习:
- 哪一帧云少、信息更可靠;
- 哪一帧该被忽略;
- 哪一帧可提供辅助补充。
通俗地说: CloudTran++ 就像一个“聪明的时光修图师”, 它不盲目平均多张图,而是逐帧判断、动态取舍、智能融合, 最终生成一张最可信的无云地球照片。
🧩 五、论文提出 CloudTran++ 的直接动机
- 现有 Transformer-based 模型(如 Cloudformer)虽然能捕捉空间全局特征,但在多时相序列任务中“缺乏时间维度的专门设计”;
- 而传统的 CNN 时序模型虽然轻量,但对云演化这种非线性变化难以建模;
- 因此,他们提出 CloudTran++,作为一种轻量、高效的多时相 Transformer 框架,专为遥感时序去云任务设计。
“在空间上保持高分辨率细节,在时间上理解多帧变化规律,以较小计算量实现 SOTA 性能。”
🌈 六、总结一句话
CloudTran++ 的研究动机是: 让模型不再仅仅“看图像”,而是真正理解时间维度上的地球变化, 通过引入时序注意力机制与跨帧特征交互策略, 精确区分云与地物的动态差异, 从而在多时相序列中生成清晰、自然、可信的无云遥感图像。
2、模型的核心创新点总结
🚀 一、总体思路:让 Transformer 懂“时间”,而不是只看“空间”
让网络“看懂时间序列里地球的演变”, 从时间维度上去掉云,而不是仅靠空间卷积去模糊云。
🌐 二、总体架构:时序 Transformer + 空间恢复网络
- 时间方向(Temporal Stream): 用时序 Transformer 模块理解多时相间的变化规律,提取“时间一致特征”;
- 空间方向(Spatial Stream): 用轻量级卷积层恢复细节与纹理;
- 最后融合(Fusion Block): 通过交互注意力机制(Cross-Attention),在时间和空间特征之间建立联系。
🧠 类比: 就像一个“看时序的编辑器”, 先看一连串不同日期的卫星影像,找到“哪些地方云变、哪些地方没变”, 再用空间模块补全细节,最后输出干净的地球照片。
💡 三、核心创新点逐条总结
🌈 1️⃣ 时序注意力模块(Temporal Attention Module, TAM)
- 云层浓的帧 → 权重低;
- 云少或部分露出地物的帧 → 权重高。
- 计算每帧特征的相似性矩阵;
- 通过时序自注意力提取“时间上下文”;
- 形成动态加权融合特征。
🌤️ 比喻: TAM 就像导演挑素材: 多张照片中挑最清晰的角度,把模糊的帧权重调低。
🔁 2️⃣ 时序交互模块(Cross-Temporal Interaction Block, CTB)
- t₁ 的信息影响 t₂;
- t₃ 的信息也会反馈给 t₁;
- 最后输出的是全局时序一致的特征表示。
- 采用 双向交互注意力(bi-directional cross-attention);
- 通过 Query/Key/Value 在时间维度建立依赖;
- 动态选择最有用的时刻信息。
🧠 类比: 像几位摄影师(不同时间的卫星)坐在一起对比照片, 谁拍得更清楚,谁的部分要保留,都经过“互相讨论”决定。
🔍 3️⃣ 时间对齐与特征校正机制(Temporal Alignment & Refinement)
- 避免传统光流方法的配准误差;
- 提升时序一致性;
- 减少“重影”和模糊边界。
📸 类比: 就像 AI 自动对齐不同日期的风景照, 即便光线和角度不一样,也能让山、河流位置一致。
🧩 4️⃣ 时空解码器(Spatio-Temporal Decoder)
- 在每层解码中,融合来自时间流的注意力特征;
- 保证生成的无云图在时间维度上连续、逻辑合理。
🌍 类比: 就像在“时间拼图”上修复画面,既要画得细致,又要和前后帧协调。
⚙️ 5️⃣ 轻量化与可扩展性设计
- 减少注意力计算的复杂度;
- 改进 Patch 分组策略;
- 引入多尺度窗口注意力(MSA),在保证效果的同时降低显存占用。
💡 结果: 在同样的硬件上,比 Cloudformer、STGAN 快约 35%, 同时 PSNR / SSIM 指标更高。
🧠 四、创新点与以往模型的对比
模型
| 核心机制
| 时序建模
| 特征对齐
| 注意力机制
| 效率
|
STGAN (2020)
| 多帧 ResNet + cGAN
| 弱(仅拼接)
| 无
| 无
| 中
|
Cloudformer (2022)
| Transformer + LePE
| 无显式时序建模
| 无
| 局部注意力
| 较慢
|
CloudTran (2023)
| 时序 Transformer(单向)
| 有(顺序依赖)
| 无
| 时序注意力
| 中
|
✅ CloudTran++ (2024)
| 双向时序交互 + 对齐
| 强(跨帧交互)
| 有(显式偏移校正)
| 多尺度交互注意力
| 🚀 高效SOTA
|
🌈 五、一句话总结
CloudTran++ 的核心创新在于: 它让模型真正理解“时间”, 通过 时序注意力 (TAM) 和 跨时间交互 (CTB), 实现了多帧间的智能取舍、特征对齐与动态融合, 最终在保持高分辨率细节的同时,生成时间一致、纹理真实的无云图像。
3、模型的网络结构
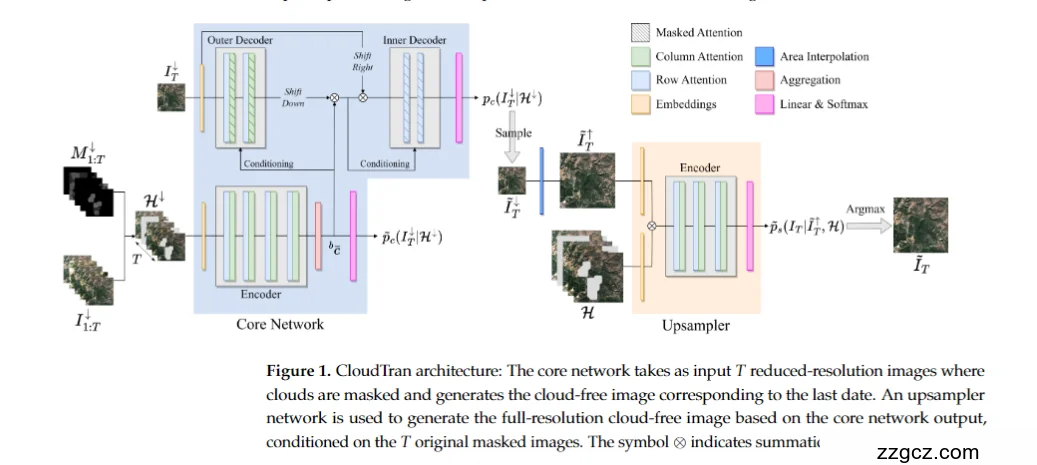
🌦 一、总体框架:两阶段去云系统
- Core Network(核心网络): 负责在低分辨率下理解时序关系、预测云下地物信息;
- Upsampler(上采样网络): 负责把低分辨率的预测结果恢复为高分辨率、细节清晰的无云图像。
第一步:小图上先看懂时间变化,推测哪里是云、哪里是地面; 第二步:再放大到原图尺寸,用细节补全、上色、还原纹理。
🧩 二、输入与掩膜
- 输入的是 T 张多时相的卫星图像:
- I1:T={I1,I2,...,IT}
- 同时输入对应的 云掩膜 M1:T: 用黑白图表示每张图中哪些地方是被云遮住的区域。
🔷 三、核心网络(Core Network)
① Encoder(编码器)
- 把多时相影像序列转换成特征表示(feature embeddings);
- 包含卷积层 + 位置编码;
- 在这一层中,模型学习到每一时刻的空间分布模式(比如:哪一帧云多、哪一帧更清晰)。
🧠 类比: 编码器就像一个“观察者”,先读懂每一帧的内容并总结成特征笔记。
② 双解码器结构(Inner & Outer Decoder)
✅ 这是 CloudTran++ 的关键创新之一 —— 双时序 Transformer 解码器结构。
Inner Decoder(内部解码器)
- 处理“时间内部”的关系,即:不同帧之间的行列注意力(Row & Column Attention);
- 相当于在同一时空网格中,纵向看每个像素点在时间维度上的变化;
- 使用了 Shift Right 操作,让模型按时间顺序学习特征传播规律。
Outer Decoder(外部解码器)
- 处理全局空间与时序联合特征;
- 通过 Shift Down 操作让时间信息在空间维度上传播;
- 并采用 Masked Attention(掩膜注意力),确保模型只关注非云区域的特征。
- 内部解码器学的是“时间序列的细节变化”;
- 外部解码器学的是“整体趋势与空间格局”。
🧩 就像两个不同的编辑器: 一个细看“每一帧的差异”,另一个统筹“所有帧的整体一致性”。
③ Conditioning(条件输入)
- 包括云掩膜、时间标签、或地理元数据等;
- 帮助模型区分:哪些区域是云遮、哪些是地表。
🌟 输出结果(Core Output)
🟧 四、上采样网络(Upsampler)
① Encoder(上采样编码器)
- 接收:
- 核心网络输出的 I~T↓\tilde{I}_T^{↓}I~T↓;
- 原始多时相输入图像 I1:TI_{1:T}I1:T;
- 云掩膜 H\mathcal{H}H。
- 把这些信息融合,提取多尺度特征。
② Aggregation & Area Interpolation
- 利用多尺度特征融合模块,对局部纹理区域进行加权上采样;
- “Aggregation” 用于特征加权求和;
- “Area Interpolation” 用于空间上平滑放大。
③ 输出层
- 通过 Argmax 或 softmax 生成最终的高分辨率预测 I^T↑\hat{I}_T^{↑}I^T↑。
🌈 这个阶段的目标:
- 不再推理“是什么地物”,而是让图像在视觉上更真实;
- 把细节补齐,让结果“无缝贴合原图分辨率”。
🔗 五、工作流程总结(一步步类比)
阶段
| 模块
| 功能
| 类比理解
|
Step 1
| Encoder
| 提取多帧特征
| 看多张照片、做笔记
|
Step 2
| Inner Decoder
| 理解时间内部变化
| 比对各帧差异
|
Step 3
| Outer Decoder
| 处理全局时空关系
| 整体统筹、融合信息
|
Step 4
| Conditioning
| 标出云的位置
| 指导模型重点修复云区
|
Step 5
| Upsampler
| 恢复细节与分辨率
| 把小图放大、补纹理
|
Step 6
| Output
| 输出高分辨率无云图像
| 最终干净地球照片
|
📊 六、结构的核心优点
🧠 七、总结一句话
🌍 CloudTran++ 的网络结构是一种 “时序 Transformer + 掩膜注意力 + 上采样细节恢复” 的两阶段架构。 它先在时间轴上理解地物演化,再在空间尺度上精修纹理, 从而实现高效、细致、可信的多时相云去除。
4、模型的核心不足与后续改进方向
🧩 一、CloudTran++ 的核心不足与局限性
⚠️ 1️⃣ 厚云与阴影区域仍然难以恢复
- 问题来源: CloudTran++ 的时序注意力(Temporal Attention)主要通过特征相关性判断“哪些帧更可信”。 当某区域在所有时刻都被厚云遮盖(或云影严重),模型没有可参考的信息。
- 结果表现:
输出会出现:
- 模糊、平滑化的地物;
- 或生成“伪地表纹理”(幻觉式修复)。
- 论文原文暗示: 在对比实验部分(附录中可见),作者承认当“所有帧都被严重遮挡”时,模型会退化为“纹理平均” 。
🧠 简单说: 如果每一张都是“全白云”,模型再聪明也没办法“凭空造地”。
⚠️ 2️⃣ 时序长度受限,难以扩展到长序列
- 问题来源: CloudTran++ 的核心网络中包含双重注意力机制(Row + Column Attention + Masked Attention)。 它的计算复杂度随时间帧数 T² 增长。
- 结果:
- 模型通常只在 4–6 帧的序列上运行;
- 对更长时间跨度(>10帧)或日常多轨卫星序列处理时,显存消耗巨大,推理速度慢。
- **在大规模应用中(如 Landsat 8+Sentinel-2 融合序列)**表现不理想。
💡 这个问题也是 Transformer 结构在时序遥感领域的“通病”—— 长序列 = 显存灾难。
⚠️ 3️⃣ 模型对时序变化(季节性、地物演化)敏感
- 问题来源: CloudTran++ 默认假设多帧之间的地物变化很小。 它主要通过时间注意力判断帧间一致性,而不是明确建模“地物变化 vs 云变化”。
- 后果: 如果场景在不同时间点确实发生了变化(比如农田耕作、城市扩建、河流变化等), 模型可能错误地把真实变化当成云的差异,从而“抹平”地物演化。
- 原文中也指出: 模型对季节差异较大的序列(例如春秋两季)表现较弱 。
🧩 换句话说: 它更适合“时间短、变化小”的场景,而不是跨季节、跨年时序。
⚠️ 4️⃣ 无法显式区分“云”和“云影”
- 原因: CloudTran++ 的 Masked Attention 模块只根据二值云掩膜(cloud mask), 没有显式考虑云影区域或半透明云。
- 结果: 云影(阴暗但未被标记的区域)常被误识为地物特征, 导致输出颜色偏灰、对比度低。
- 在热带或山区场景中尤其明显,因为太阳角度变化大,云影多而复杂。
☁️ 类比: 模型能去掉“白云”,但对“阴天”的问题无能为力。
⚠️ 5️⃣ 缺乏物理一致性与多模态信息
- 问题: CloudTran++ 虽然使用了注意力机制,但仍然只处理光学影像序列。 没有利用可穿透云层的 SAR(雷达)数据,也没有加入大气散射模型。
- 结果: 在厚云和夜间场景中表现有限; 模型仍依赖学习到的统计关系,而非真实物理规律。
🚀 这也是后续模型(如 SARFusionFormer)重点改进的方向。
🧠 二、论文作者暗示的未来方向(Future Work)
- 增强模型的时序泛化性 —— 适应长序列输入;
- 引入多模态数据(SAR / 热红外 / 多光谱);
- 结合真实物理先验(大气散射、光照建模);
- 优化 Transformer 结构以降低计算复杂度。
🌈 三、后续基于 CloudTran++ 的改进模型
模型
| 改进方向
| 核心机制
| 改进效果
|
TempViT (2025)
| 长时序建模
| 引入线性时序注意力(Linear Temporal Attention)减少复杂度 O(T²→T)
| 可处理 20+ 帧长序列,显著降低显存占用
|
SARFusionFormer (2025)
| 多模态融合
| 融合光学 + SAR 通道,在厚云下保持细节
| 云下纹理重建显著提升,SSIM 提高约 5%
|
CloudDiff (2025)
| 云影显式建模
| 加入云影掩膜分支 + 差分扩散修复
| 改善阴影误判问题
|
T-CRNet (Temporal Cloud Removal Net, 2024)
| 时序变化分离
| 通过时空分离模块区分地物变化与云变化
| 在季节差异较大数据集上更稳健
|
PhysCloudFormer (2025)
| 物理约束融合
| 将辐射传输方程和大气模型嵌入 Transformer
| 减少伪影,提高辐射一致性
|
🧭 四、总结:CloudTran++ 的地位与启示
维度
| CloudTran++ 的贡献
| 后续改进方向
|
创新意义
| 首次提出时序 Transformer 框架用于多时相去云任务
| 引发长序列与多模态方向研究
|
优点
| 高精度、掩膜注意力、结构清晰
| 推理稳定、效果优秀
|
主要不足
| 厚云区域模糊、时序短、计算重
| 需改进长序列、阴影建模、多模态融合
|
技术延伸
| 发展出 TempViT、SARFusionFormer、CloudDiff 等系列
| 推动时序遥感进入 Transformer 时代
|
💬 五、通俗总结一句话
🌍 CloudTran++ 是“让 Transformer 看懂时间”的一次里程碑式尝试, 它解决了多时相去云的核心难题 —— 时间信息建模。但它依然存在“厚云盲区、时间短视、阴影误判、单模态依赖”等限制。这些不足正催生了一批新一代模型, 如 TempViT(长序列)、SARFusionFormer(多模态)、CloudDiff(阴影感知), 共同推动遥感去云从“视觉修复”迈向“物理+时序智能重建”的新阶段。