Cloudformer(2022):一种结合自注意力机制和卷积的云消除网络
导出时间:2025/11/24 08:46:21
1、研究背景和动机
背景:遥感影像“先去云,后分析”
- 光学遥感用得很广(测绘、环境、侦察…),但地表大约一半时间被云遮,成像会降质(分辨率/对比度下降、云影干扰),因此“去云”是许多任务(检测/分割/变化监测)前的必备预处理。
- “厚云”往往把地物信息完全盖住,单幅图像很难恢复,常需多时相/多源辅助;“薄云”仍保留一些信息,单幅也有希望处理。
既有方法的痛点
- 传统方法依赖人为先验或简化物理模型,泛化弱、对复杂场景适应性差。
- CNN 方法虽然提升了效果,但先天局限明显:
- 卷积感受野偏局部,难以利用远距离上下文来补全大块云遮区域;
- 卷积核权重在推理时固定,难以随输入自适应调整。
- Transformer 的机会与挑战:自注意力能建模大范围依赖、按输入动态分配权重,理论上更适合“看远处拿信息来补云”;但纯 Transformer 往往需要大数据避免过拟合,遥感去云配对数据采集昂贵、难做大规模,这限制了直接上纯 Transformer 的可行性
动机:把“看近处的卷积”和“看远处的自注意力”拼好用
- 论文观察到:Transformer 在浅层实际也主要学“局部”,这时用自注意力会产生冗余计算;而到深层才真正受益于大范围依赖。于是作者提出: 浅层用卷积(高效抽局部简单特征)+ 深层用窗口化多头自注意力(高效抽全局/长程依赖),两者优势互补,既省算力、又提效果,还能降低小数据下的过拟合风险。
- 为了让窗口自注意力拥有更强的位置感与局部先验,作者引入LePE(局部增强位置编码):用深度卷积为不同输入自适应地产生位置编码,把局部信息注入注意力,增强恢复质量。
- 目标很直接:做一个单幅去云的新基线,同时兼顾薄云与厚云场景,相比以往 cGAN/McGAN/SpaGAN 等方法,在画面色彩一致性、纹理保真、云影处理和整体连贯性上更稳、更强。
一句话总结
数据不易、云很难:纯 CNN 看不远,纯 Transformer 又吃数据。Cloudformer 的动机就是浅层卷积 + 深层 Transformer + LePE,在有限数据下把“局部先验”和“全局依赖”结合起来,成为单幅去云的更强基线。
2、模型的核心创新点总结
“浅卷积 + 深注意力”的混合式骨干
- 做法:把 U-shaped Transformer(Uformer)改造为**浅层用卷积、深层用窗口多头自注意力(W-MSA)**的混合架构;浅层卷积高效抓局部、避免自注意力的冗余计算,深层注意力负责建模长程依赖。
LePE:局部增强位置编码,给注意力“加上方位感”
- 做法:在窗口注意力里引入 LePE(Locally-enhanced Positional Encoding)——用卷积产生数据自适应的位置编码,把可靠的局部先验注入到注意力里,增强纹理与结构恢复。
端到端的 U 型 Transformer 编解码器 + 跳跃连接
- 做法:延续 U 形对称的编码器–解码器,并用跳跃连接传递多尺度特征,保证细节与全局一致性;输入/输出均为 RGB 图像,适合单幅去云的端到端学习。
针对“遥感去云小数据”场景的设计取舍
- 动机 & 创新点:作者明确指出 Transformer 往往需要大规模数据,而去云很难获得大量成对样本;因此提出与卷积有效融合的设计,缓解过拟合与算力开销,使 Transformer 在小数据下也好用。
- 实证证明:混合式 > 纯卷积 / 纯注意力
- 证据:消融实验把浅层改为纯注意力或全卷积作对比,**Cloudformer(浅卷积 + 深注意力 + LePE)**最优;证明混合策略与 LePE 的增益。
- 跨数据泛化:在巴黎城市数据集等异质场景,Cloudformer 的 PSNR/SSIM 明显优于 cGAN/McGAN/SpA-GAN 等方法,纹理与色彩更接近真实。
- 可接受的效率–质量权衡
- 观察:由于 Transformer 计算重,推理速度略慢,但作者给出 FPS 对比并认为去云任务对实时性要求不高,为画质牺牲适度速度是值得的(作为SOTA 基线更强调画质)。
一句话
Cloudformer 的核心在于:用浅层卷积稳抓局部+省算力,深层窗口注意力建模长程依赖,再用 LePE 给注意力加“本地方位感”;配上 U 型编解码器与跳跃连接,在小数据的遥感单幅去云场景里,达到更好的细节与全局一致性。
3、模型的网络结构
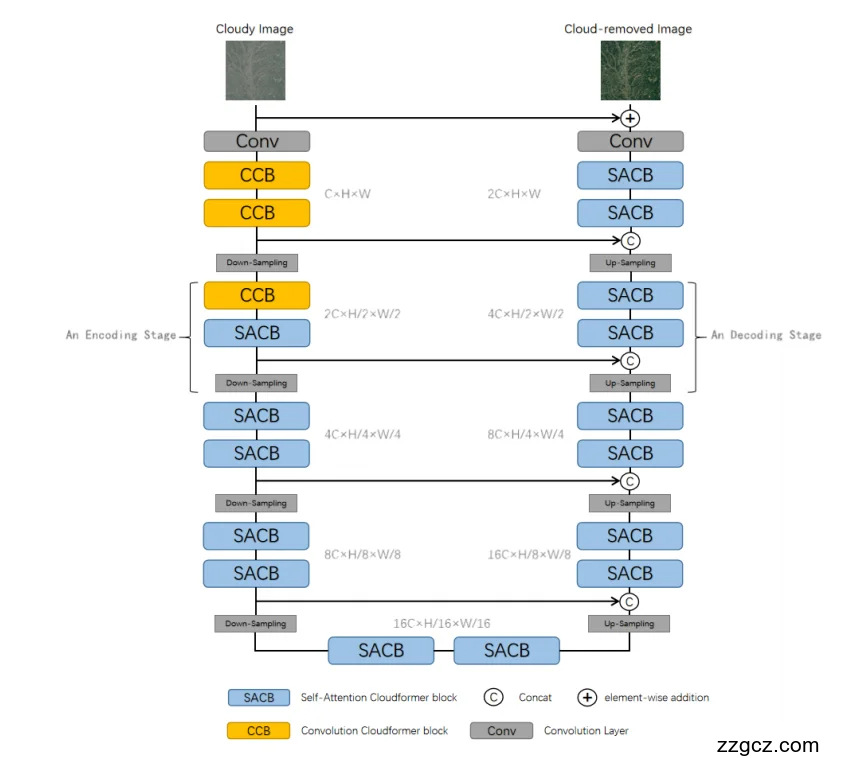
整体结构:一个“U 型”的去云机器
这张图展示的是 Cloudformer 的核心网络架构,它是一个U 型编码器–解码器结构(U-Net 风格)。
U 型结构的特点是:
- 左边是编码器(Encoder),负责“看懂”云图、提取多层次特征;
- 右边是解码器(Decoder),负责“还原”无云图像;
- 中间底部是“最深层特征”,代表对图像内容的高层语义理解;
- 中间的“横线连接”(跳跃连接)让浅层细节直接传到解码端,保证图像恢复的细节保真度。
通俗比喻:
编码器像医生“看CT扫描”,逐层看得更深;解码器像医生“还原健康组织”,逐层重建原图;跳跃连接就是医生一边看扫描、一边参照原始图像细节,防止修复走样。
模块组成:CCB 与 SACB 两大主角
1️⃣ CCB(Convolution Cloudformer Block)——卷积块,负责“看近处”
- 这是浅层使用的模块,黄色部分。
- CCB 用卷积层提取局部特征,捕捉云纹理、边缘、地物细节。
- 它结构轻、效率高、抗噪好,非常适合网络前几层处理。
想象 CCB 像是“放大镜”——在图像表面仔细观察局部特征。
2️⃣ SACB(Self-Attention Cloudformer Block)——注意力块,负责“看远处”
- 蓝色部分,是网络的“深层模块”。
- SACB 内部使用多头自注意力机制(Transformer 模块),可以同时看到整幅图像的不同区域。
- 它能理解:比如右上角的田地和左下角的山脊在纹理上可能相似,从而在被云遮住时“借别处信息”来修复。
想象 SACB 像“无人机视角”,可以从高处看全局,帮助判断哪里是云、哪里该补。
编码器(左半部分)——分层理解“云”
- 输入是带云的卫星图像。
- 经过一个卷积层(Conv)做初步特征提取。
- 前两层是两个 CCB:用卷积处理,提取局部结构信息。
- 然后通过下采样(Down-Sampling),图像尺寸减半、通道数加倍,进入更深层。
- 从第二层开始,引入 SACB:让网络能看远一点,理解云的形状与全局分布。
- 编码端最后几层几乎全是 SACB——表示网络在高层已经完全靠“自注意力”建模。
通俗解释: 编码器这边相当于“从像素级看到场景级”, 前面 CCB 看清云边缘、云影,后面 SACB 理解“这片白云下可能是农田还是山地”。
解码器(右半部分)——分层重建“无云图像”
- 从底层深层特征开始,用上采样(Up-Sampling)逐步放大图像分辨率。
- 每个上采样阶段都包含两个 SACB 模块,用自注意力恢复全局结构。
- 与编码器对应层通过“跳跃连接(Concat)”融合,确保细节恢复。
- 最后一个卷积层(Conv)把特征图转换成最终输出图像(Cloud-removed Image)。
直观理解: 解码器就像是“图像修复工”,在全局上下文指导下,一边放大分辨率,一边用局部信息补全云区细节。
跳跃连接(Skip Connections)
- 图中每个“C”符号表示“Concat(拼接)”:把编码器相同层的特征复制给解码器。
- 这样做能让浅层(纹理细节)与深层(语义理解)结合,防止图像变糊。
这相当于医生在修复CT图时,会参考最原始的照片,保证修复后的皮肤纹理、边界都真实。
特征流动与输出过程(总结)
- 输入: 带云图像。
- 编码阶段:
- 浅层 CCB 捕捉局部云纹理;
- 深层 SACB 通过自注意力看全局关系;
- 下采样逐层压缩空间、增加语义理解。
- 解码阶段:
- SACB 逐层上采样恢复清晰地物;
- 跳跃连接融合细节;
- 最终卷积生成无云输出。
- 输出: 云被清除、地物纹理自然的“Cloud-removed Image”。
一句话总结
Cloudformer 的网络结构是一个“浅层看近、深层看远”的 U 型架构:
- 前半段(CCB)用卷积快速抓局部云纹理;
- 后半段(SACB)用 Transformer 理解全局关系;
- 中间通过多层跳跃连接,让全局理解与细节修复兼得;
- 最终输出一张结构自然、细节丰富的无云遥感影像。
4、模型的核心不足与缺陷,已经后续的哪些模型,是基于此进行改进,如何改进?
1. Cloudformer 的主要不足 / 缺陷
虽然 Cloudformer 在单幅去云任务中取得了不错的效果,但从学术角度和工程应用角度看,它依然有一些局限和不足:
不足 / 局限
| 原因 / 机制分析
| 对实际效果或应用的影响
|
对厚云 / 强遮挡区域恢复能力不足
| 即便使用 Transformer,单幅图像中若云层完全遮挡下面地物信息,模型也几乎没有可靠线索可推断。Cloudformer 虽设计为处理薄云 + 部分厚云,但本质上仍受单幅信息限制。
| 在云很厚、云影严重的区域,输出可能是模糊、伪造或失真。
|
数据依赖 / 小样本过拟合风险
| Transformer 模型倾向于需要大量样本训练才能稳定和泛化,而遥感云去除领域可用的配对训练数据较少。Cloudformer 通过浅层卷积缓解部分问题,但仍可能在异域数据或不同传感器上过拟合。
| 在未见过卫星、地物类型、云型等场景,其性能可能下降。
|
计算复杂度 / 推理成本
| Transformer 部分(尤其窗口自注意力、多头操作)在高分辨率图像上仍开销较大。对于大幅遥感图像(几十万像素尺度),模型的计算、内存需求可能成为瓶颈。
| 在实际部署(尤其在卫星端、移动端或实时系统)可能难以直接使用,需做裁剪、降采样、分块等处理。
|
局部 + 全局平衡仍有矛盾
| 虽然 Cloudformer 混合卷积与注意力,但在浅层卷积与深层注意力的切换处,可能存在“信息融合 / 衔接”不够顺滑的问题,使得有些特征在层次交互时“断层”或不一致。
| 在云边界、纹理细节区域可能出现边界不连续、色彩失真或伪影。
|
位置编码 / 局部结构注入可能不完全
| LePE(局部增强位置编码)确实引入了输入自适应的位置编码,但它仍依赖深度卷积生成,可能在极复杂纹理或不规则云形中不能完全捕捉所有空间结构信息。
| 在某些复杂云形、极端纹理或几何结构丰富场景下,可能出现细节错误、边界不一致、纹理模糊等问题。
|
缺少辅助模态 / 多源信息利用
| Cloudformer 是纯单幅光学图像输入模型,不利用如 SAR、红外、历史图像等辅助信息。
| 在云遮挡严重或图像区域几乎无地物曝光的区域,其恢复能力受限;若能融合其他模态,恢复可能更稳健。
|
现实遥感场景差异适应性弱
| 不同卫星、不同分辨率、不同成像条件(光照、成像几何、气溶胶)下特性差异大。一个在某个数据集上训练好的模型,在现实场景中可能出现偏差或性能退化。
| 模型可能需要迁移 / 适配 /微调,在跨域应用中可能表现不如预期。
|
这些缺点在 Cloudformer 的论文中或在云去除领域的后续文献中都被或明或暗地提及(如对数据集限制、对厚云恢复能力的担忧)MDPI。
后续基于 Cloudformer 思路做改进 / 替代的模型 / 方法,以及它们的改进策略
近年来,云去除 / 云恢复任务上的研究越来越多,不少方法是在 Transformer 或混合模型方向对 Cloudformer 或类似思路做增强或替代。下面列举几个代表性方法,以及它们如何改进或克服 Cloudformer 的不足。
方法 / 模型
| 改进点 / 创新方向
| 与 Cloudformer 的对比 & 增强之处
|
DiffCR: A Fast Conditional Diffusion Framework
| 引入扩散模型(Diffusion Model)用于云去除,以逐步细化恢复细节,提升图像真实感与结构一致性。它还设计高效的时间-条件融合模块,保持性能高但复杂度低。arXiv
| 相比 Cloudformer 靠 Transformer 重建,DiffCR 在生成细节、纹理连贯性上潜力更强,且扩散模型具有“逐步到精细”的优点。它可视为一种新的方向替代 Transformer 架构。
|
“When Cloud Removal Meets Diffusion Model in Remote Sensing” (DC4CR)
| 提出在云去除任务中使用多模态引导、Prompt 驱动控制、低秩适配等技巧,把云去除作为条件扩散生成问题。该模型可以较灵活地控制去云过程、增强模型泛化性。arXiv
| 相对于 Cloudformer 的单一结构,DC4CR 在可控性、适应性、条件引导上更灵活,也更易于扩展到不同云强度 / 模态融合场景。
|
Patch-GAN Transfer Learning with Reconstructive Models
| 结合 重构网络(Reconstructive Models, 比如 MAE) 与 GAN,采用 Patch-wise 判别器做局部真伪判断,并用迁移学习降低数据需求。arXiv
| 与 Cloudformer 单纯端到端 Transformer 架构不同,该方法通过预训练 + patch 判别策略增强局部一致性,提升细节修复能力,同时减缓对大数据需求的压力。
|
SFCRFormer: Spatial–Frequency Combined Transformer
| 在 Transformer 模型中同时融合空间域注意力与频域自注意力,即处理图像在频域与空间域上的特征交互,从而更精准区分云区与地物、保护纹理结构。MDPI
| 这种双域注意力补足了 Cloudformer 可能在某些纹理 / 频率特征上处理不佳的问题;特别在边缘 / 纹理细节上能获得更好的保持。
|
Radiative Transfer Model–coupled Transformer (RTFormer)
| 在网络中融入**物理云模型(辐射传输模型)**的先验,增强真实云 / 大气规律建模,减少模型盲学习风险,同时扩展感知场。SSRN
| Cloudformer 是纯数据驱动的,缺少物理模型约束;RTFormer 引入物理先验,有助于在真实遥感场景下表现更稳健,尤其在极端云 / 大气条件下更具鲁棒性。
|
Rule-based Transformer for Cloud Removal (CloudRuler)
| 在深特征空间中加入规则(rule-based)模块,用显式规则补充 Transformer 学习,以减少错误修复或误修干净区。科学直通车
| 这种方法针对 Cloudformer 在边界或细节区域可能的误修问题,用规则辅助来提高稳定性与准确性。
|
这些模型或方法一般沿着以下几个方向对 Cloudformer 的不足做补充或改进:
- 引入扩散 / 生成功能模型 扩散模型擅长逐步生成与细化,能更好处理细节与纹理连贯性,是对 Transformer 架构的一种补充或替代。
- 融合物理模型 / 先验知识 将大气散射、辐射传输等物理模型融入网络,给模型更多结构化约束,降低盲学风险,提高在真实场景下的泛化性。
- 频域 / 变换域融合 通过把图像从空间域变换到频率域(傅里叶、小波等),在频域上识别云与地物纹理差异,从而增强云检测与去除能力(如 SFCRFormer 的频域注意力模块)。
- 局部 + 全局混合 / 多尺度机制 在 Transformer 或注意力模块中更精细地设计多尺度融合、局部–全局平衡机制,以减轻层次交互断层、细节丢失的问题。
- 迁移学习 / 预训练 / 重构模块 利用 MAE / 自监督 /预训练模型先学图像结构,再做云去除,以缓解监督样本匮乏问题(如 Patch-GAN Transfer Learning 方法)。
- 规则 / 先验辅助 / 辅助模块 加入规则模块、边界引导、云掩膜辅助监督、云/地物先验等,约束模型避免误修或伪影。