DMDiff(2025):一种基于SAR光学数据融合的双分支多模态条件引导扩散模型
导出时间:2025/11/24 08:47:32
1、研究背景和动机
1.1、为什么又需要一套新方法?
- 云把光学卫星“眼睛”遮住了——这是老大难。 多地长期云多,光学影像经常大片缺失;如果只挑无云影像来做分析,会浪费大量数据。于是“把云去掉、还原云下地物”成了刚需。
- SAR 能穿云,但和光学完全是两种“语言”。 SAR(雷达)能在任何天气看到地表结构;光学影像提供颜色与材质。两者成像机理差异大,直接拼在一起用,很容易信息失真或对不齐。
- CNN / GAN 已有进展,但还不够:
- CNN 擅长局部,遇到大面积厚云容易“糊成一片”;
- GAN 画面感强,但训练不稳定、容易“模式崩溃”,调参很费力。
- 扩散模型生成更稳,但照搬“噪声预测”(NP)策略在遥感上不理想。 很多扩散方法让网络在每一步“预测高斯噪声”,在自然图像上很好用;可遥感图像光谱复杂、区域异质性强(同一张里既有水体、农田、城市),仅用 NP 往往学不稳、容易光谱失真、细节丢失。
1.2、DMDiff 想解决什么痛点?
用扩散模型做“云下重建”,但专门针对 SAR+光学 的多模态场景做了两件事:
① 让两种传感器“分头提取,各显其能”,再用注意力深度对话
- 设计双分支编码器:SAR 支路专抓结构纹理,光学支路专抓无云区的空间-光谱信息;
- 再用跨模态交叉注意力进行特征融合,并配去冗余模块,避免信息重复与噪声。 → 目标:把“能穿云的骨架”与“真实的颜色语义”对上号,给扩散过程提供更准的条件引导。
② 把扩散的学习目标从“猜噪声”改成“直接猜无云图”(IAP 策略)
- 提出 Image-Adaptive Prediction (IAP):每个扩散步直接预测目标无云影像,而不是预测噪声;
- 更贴合遥感图像“多类地物+多波段”的本质,细节与光谱更稳,论文报告在 PSNR 等指标上显著优于 NP。
一句话动机总结
DMDiff 的动机:把SAR 的全天候结构线索和光学的颜色语义,通过双分支+跨模态注意力喂给扩散模型;同时用IAP替代传统“噪声预测”,让扩散过程更适配遥感的复杂场景,最终在厚云下也能生成细节真实、光谱靠谱的无云图像。
2、模型的核心创新点总结
2.1、一句话先懂
DMDiff把扩散模型用于“SAR + 光学”多模态去云:
让SAR 的骨架和光学的颜色先在特征层“对上话”,再用更贴合遥感的扩散训练目标一步步把云下影像“还原出来”。
2.2、核心创新点
- 双分支特征提取:各司其职,先分后合
- 两条编码器分别处理 SAR 与带云光学: SAR 支路专抓结构/纹理,光学支路专抓颜色/语义;避免“一锅炖”带来的互相干扰。
- 目的:为云区重建提供“结构+颜色”的可靠先验。 (作者明确设计“双分支特征提取架构”,适应两种数据的本质差异。)
- MFFDE:多模态特征融合与去冗余的一体化编码器
- MFFDE 由两步组成: (a) MCFIM 跨模态交叉注意力——把 SAR 的空间结构与光学晴空区特征建立互补映射关系, 学会“如何把骨架涂上正确的颜色”; (b) FDM 去冗余——用 SCConv 抑制空间/通道冗余,保证融合后信息干净、有效。
- 作用:让多模态融合“有的放矢”、不过度重复。
- IAP(Image-Adaptive Prediction)训练目标:不再“猜噪声”,而是直接猜无云图
- 传统扩散学噪声(NP),在多波段、强异质的遥感图像上易出现颜色漂移、细节流失;
- DMDiff改为每一步直接预测目标无云影像(IAP),训练信号更贴近任务本质;
- 结果:相对 NP,PSNR 提升近 20 dB,同时 SSIM/FID/LPIPS 全面更好。
- 扩散过程由“多模态条件”显式引导
- 经过 MFFDE 的“结构+颜色”条件特征持续注入扩散采样过程, 让模型在云区按真实结构填细节、按合理光谱上色,避免“凭空想象”。
- 光谱一致性验证:不仅像,更“像真的”
- 作者给出植被/裸土/人工地表的光谱曲线对比:DMDiff 与无云真值高度一致, 明显优于多种对比方法(含条件扩散、cGAN、DSen2-CR 等)。
- 端到端、跨数据集有效
- 在航空、WHU-Opt-SAR、LuojiaSET-OSFCR 等多数据集上, DMDiff在信号保真度(PSNR/SSIM)与感知质量(FID/LPIPS)均达到或超过SOTA。
通俗对照表
创新
| 做了什么
| 直观理解
|
双分支编码
| SAR管结构、光学管颜色
| “骨架 + 上色”分工明确
|
MCFIM
| 跨模态交叉注意力
| 让骨架和颜色对上号
|
FDM(SCConv)
| 空间/通道去冗余
| 删重复、降噪声
|
IAP
| 直接预测无云图
| 不猜噪声,直奔目标
|
条件引导扩散
| 条件特征贯穿采样
| 按“真实结构+颜色”生图
|
光谱一致性
| 曲线与真值对齐
| 不仅像、还“物理像”
|
总结
**DMDiff 的“新”**在于:
- 先分后合的双分支 + 交叉注意力,把 SAR 的结构与光学的颜色对齐融合;
- 用 IAP 取代 NP,让扩散直学目标图像,在遥感这种多模态、多波段场景里更稳更准;
- 在厚云与多地类上做到细节与光谱双重可信。
3、网络结构
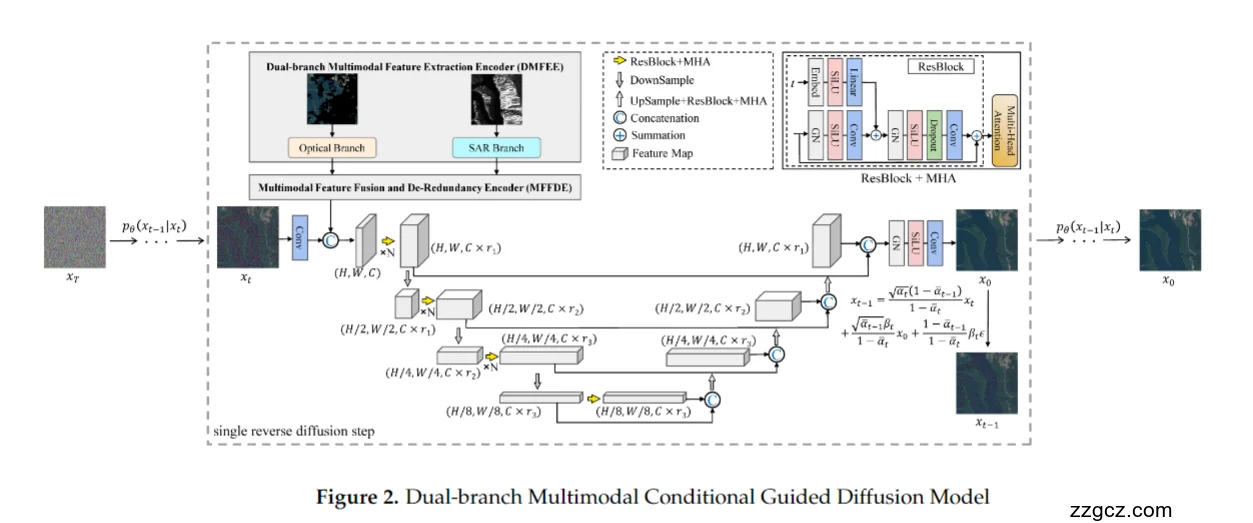
🧭 一、整体结构:一个“懂两种语言”的智能修图师
整个模型由三大部分组成:
- 双分支特征提取器(DMFEE)——让 SAR 和光学图像各自提取特征;
- 多模态融合与去冗余编码器(MFFDE)——把两路信息对齐、融合、去噪;
- 扩散生成器(Diffusion U-Net)——在融合特征的条件引导下,从“噪声”一步步还原出无云图像。
可以把它理解成一个智能修图团队:
- SAR 是“结构顾问”,告诉你地面轮廓;
- 光学图像是“色彩顾问”,提供颜色参考;
- 扩散模块是“画师”,在两位顾问的指导下从模糊噪声中画出清晰无云照片。
☁️ 二、双分支多模态特征提取(DMFEE)
上方蓝黄框部分:
🔹 SAR Branch
- 负责提取结构、形状、边缘等几何信息;
- 输出空间特征图,包含地表高程、建筑、地物轮廓等线索。
🔸 Optical Branch
- 提取颜色、纹理、光谱信息;
- 重点学习晴空区域的色彩关系和地物语义。
两路输出都会被送入下一层融合模块。
💬 类比:就像一张黑白线稿(SAR)和一张被云遮住的彩色照片(光学)——模型要让它们“合成”出完整、正确的彩色图。
🔀 三、多模态融合与去冗余编码器(MFFDE)
这一块是 DMDiff 的核心创新点。
它包含两个主要机制:
- 跨模态特征交叉注意力(MCFIM)
- 光学与 SAR 特征相互“对话”;
- 模型学会:“哪个结构对应哪个颜色”,从而在云区能精准还原地物。
- 特征去冗余模块(FDM)
- 采用 SCConv 结构,清除重复或噪声特征;
- 让融合后的特征既丰富又干净。
💬 类比:SAR 给出“轮廓”,光学提供“色彩”;MFFDE 就是让它们对齐+合并成“可上色的素描草图”。
🔄 四、扩散生成部分(条件引导扩散 U-Net)
中间的大灰色框部分展示了扩散模型的反向生成过程(Reverse Diffusion)。
🧩 1. 扩散的含义
扩散模型通过“加噪声→逐步去噪”的方式生成图像。
在推理时,它从纯噪声开始,一步步恢复出目标影像。
在 DMDiff 中,每一步去噪都由SAR+光学融合特征指导:

🧱 2. 模型结构
主干网络是一种 U-Net 结构的扩散预测网络:
- 下采样路径(左下部分):逐步降低分辨率,提取多尺度全局特征;
- 上采样路径(右下部分):恢复空间分辨率,重建局部细节;
- 中间通过**跳跃连接(Skip Connections)**保持不同尺度的信息流动;
- 每层都包含 ResBlock + MHA(多头注意力), 既能处理局部纹理,又能看全局依赖关系。
🎨 五、IAP(Image-Adaptive Prediction)策略
传统扩散模型预测的是“噪声”;
而 DMDiff 改为直接预测“目标无云图像”:
- 这样模型每次反推时更贴合遥感任务本质;
- 输出稳定、光谱一致,不会“颜色漂移”。
💬 类比: 以前模型只学会“怎么去掉噪声”; 现在它学的是“去掉云之后,图像应该长什么样”。
🧾 六、一步反向扩散流程(图中公式区域解释)
在图下方有一行公式:
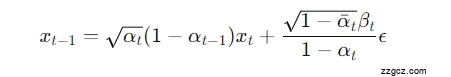
简化理解为:
- 模型用上一步图像 xt和条件特征 z 推出下一步 xt−1;
- 不断循环,直到生成最终无云图像 x0。
🌈 七、输出阶段
当反向扩散完成:
- 模型输出 x0,即预测的无云光学图像;
- 与真实无云图像进行对比计算 IAP 损失(图像层面损失)。
🧩 八、结构层级总结
模块
| 名称全称
| 主要作用
| 类比
|
DMFEE
| Dual-branch Multimodal Feature Extraction Encoder
| SAR+光学特征提取
| “两个顾问各自观察”
|
MFFDE
| Multimodal Feature Fusion & De-redundancy Encoder
| 融合 + 去噪
| “对齐、融合、清理”
|
ResBlock+MHA
| 残差+多头注意力单元
| 多尺度特征提取
| “既看细节又顾全局”
|
IAP
| Image-Adaptive Prediction
| 直接预测无云图
| “直接画目标图”
|
Reverse Diffusion
| 反向扩散过程
| 从噪声逐步生成无云图
| “画师一步步修出来”
|
💬 九、一句话总结
DMDiff 的网络结构就像一个“多模态引导的扩散画师”:
- 先让 SAR 和光学各自学习自己的强项;
- 再通过 MFFDE 把两者的优点融合;
- 然后在扩散的每一步中,用这些条件特征指导“去噪”生成;
- 最终一步步“从噪声中画出”一张结构真实、色彩可信的无云卫星图像。
4、核心不足与后续改进方向。
☁️ 一、核心不足(模型的“短板”)
尽管 DMDiff 代表了 SAR + 光学多模态扩散去云的前沿方向,
但它依然有几个明显的局限性:
1️⃣ 模型计算量极大,生成速度慢
- 扩散模型的本质是“多步反向采样”, 每张图像都要经过几十甚至上百次的去噪迭代;
- 再加上 DMDiff 同时处理 SAR 与光学两路输入,还带多层交叉注意力, 计算量非常大。
🔹 表现为:
- 训练时间长、推理速度慢(GPU 显存占用高);
- 不适合卫星大规模批量生产(尤其在区域或全球尺度下)。
🔹 改进方向:
- 使用 加速采样策略(Fast-DDPM、DDIM、Consistency Models);
- 尝试 Latent Diffusion(潜空间扩散) 或 条件轻量化 Transformer;
- 采用 蒸馏/压缩扩散(Diffusion Distillation) 降低采样步数。
💬 类比:现在的 DMDiff 像一个手工修图大师,修得漂亮,但太慢。后续需要让它“AI加速”,既修得好又快。
2️⃣ 双模态对齐仍然依赖深度学习的“黑箱”
- 虽然 DMDiff 引入了跨模态注意力机制(MCFIM), 但 SAR 与光学在几何、尺度和语义上的差异非常大;
- 模型仍然是隐式地“学会对齐”, 缺乏显式的几何/物理约束,因此在地形复杂或配准误差较大区域, 容易出现伪影或纹理漂移。
🔹 改进方向:
- 引入 几何一致性约束(Geo-Consistency Loss) 或 物理辐射校正模块;
- 采用 可学习配准模块(Learnable Registration Network);
- 与 SAR干涉相位/地形模型(DEM) 联合优化对齐精度。
💬 类比:现在模型只是“靠感觉”把两张图对齐,未来要“靠标尺和物理公式”精准对齐。
3️⃣ 扩散模型生成的图像“过平滑”,纹理细节仍有损失
- 尽管比 GAN 稳定,但 DMDiff 输出的图像有时过于平滑;
- 这是因为扩散过程在去噪时倾向于生成均值图像(最可能的结果), 会抹掉微弱的高频细节(如建筑纹理、农田边界)。
🔹 改进方向:
- 引入 混合生成架构(如 Diffusion + GAN 混合判别器);
- 或采用 多阶段细化(Refinement Stage), 在扩散输出后再加一层细节增强网络;
- 在损失中加入 高频/梯度一致性约束(Gradient Consistency Loss)。
💬 类比:DMDiff现在像是修得“太干净”,后续要让它学会“保留真实纹理的毛边”。
4️⃣ 时序信息未利用
- DMDiff 仍然是单时相多模态(SAR + 光学), 没有引入时间序列信息;
- 在遥感任务中,多时相序列(T1、T2、T3)能帮助模型区分 “短暂的云遮挡”和“真实地表变化”。
🔹 改进方向:
- 融合 时序Transformer(Temporal Attention Block);
- 设计 时空扩散模型(Spatio-Temporal Diffusion);
- 与 CloudTran++ 等模型融合形成“多模态+多时相联合扩散”。
💬 类比:只看一张照片容易误判,但看几天的连续卫星图就能更准确地“识云辨地”。
5️⃣ 物理一致性与光谱可解释性不足
- DMDiff 更偏向“视觉复原”, 并未严格保证输出的光谱反射率与真实地物一致;
- 在高精度科学应用(如农业监测、植被反演)中, 这会影响数据可信度。
🔹 改进方向:
- 引入 物理辐射约束损失(Radiometric Constraint Loss);
- 结合 大气校正模型(例如 6S / MODTRAN);
- 发展 物理引导扩散模型(Physics-Guided Diffusion Model, PGDM), 在生成过程中显式约束光谱分布。
💬 类比:现在模型会“画得真”,但不一定“测得准”;后续要让它既好看又科学可信。
🚀 二、后续研究方向与趋势(2025→2026)
改进方向
| 关键思路
| 对应趋势模型
|
轻量化与加速
| 减少采样步、蒸馏压缩
| Fast-DMDiff, LatentDiff-SAR
|
显式几何对齐
| 联合配准 + 几何约束
| GeoDiff, AlignFormer-CR
|
细节增强
| 融合GAN或RefineNet
| DiffRef-CR, TextureFusionDiff
|
时空融合
| 多时相+跨模态Transformer
| TempDMDiff, CloudTran++2.0
|
物理约束扩散
| 光谱一致性+辐射校正
| PhysDiff-CR, SpecAlignDiff
|
🌍 三、一句话总结
DMDiff 的强项在于多模态融合 + 稳定扩散生成,能在厚云条件下生成高保真无云图像; 但短板在于计算慢、跨模态隐式对齐、细节略平、缺乏时序与物理约束; 未来的方向将是让它更“轻、更准、更懂地球物理”—— 走向 轻量化、显式对齐、时空融合与物理一致性引导的扩散模型。