DSen2-CR(2020):利用深度残差神经网络和SAR光学数据融合技术实现Sentinel-2影像的云层消除
1、研究背景和动机
为什么要做 DSen2-CR?
- 云遮挡太常见,光学遥感“看不清”。 光学卫星图像广泛用于农情、气候、灾害评估等,但云层会严重破坏可用性,云去除一直是长期难题。深度学习时代到来,让这件事有了新机会。
- 仅靠光学图像不够,厚云下几乎没有地物信息。 遇到“光学上不透明”的厚云,单看光学多谱段很难“猜”出云下真实地表;作者因此引入 SAR(雷达)先验——雷达能穿云,提供几何/纹理线索,用来指导光学重建。
- 要一个稳健、可训练的大模型,而不是易崩的对抗式生成。 早前不少工作用 cGAN 做去云,但在大云量/劣质输入时容易不稳定;作者转而采用深度残差网络(ResNet),在大遮挡场景下更稳、更易优化。
- 跨时相训练会引入“地表真实变化”,需要损失函数管住伪影。 去云训练常用“不同日期”的无云图作监督,地物会有季节/作物等真实变化;如果只用常规 L1/L2,网络容易把不该改的地方也改了,于是作者提出云自适应正则化损失(CARL): 在云/云影区域,督促模型向目标无云图学习;在晴空区域,督促模型“别乱改”,贴近输入,降低伪影。
- 需要一个大而真实的数据集来验证泛化。 很多早期方法用“模拟云”或小规模数据;作者基于 SEN12MS-CR 做了大规模、全球采样的数据划分,用真实云与对应无云影像训练/测试,确保方法在不同地表类型上可泛化。
这套动机串起来就是:
- 云多 → 光学受阻 → 引入能穿云的 SAR 提供结构先验;
- cGAN 易不稳 → 用 ResNet 残差学习 提高训练稳定与重建质量;
- 跨时相监督会带来“误改” → 设计 CARL 损失,在云区学目标,在晴空区守住输入;
- 想证明可用、可泛化 → 用全球大数据集 系统验证。
一句话:DSen2-CR 的初心,是把“看得见云、看不见地”的光学成像,和“能穿云”的 SAR 拼起来,再配合“别乱改晴空区”的损失设计,让去云既可靠又稳健。
2、模型的核心创新点总结
🚀 一、总体概念回顾
🌈 “当眼睛(光学)看不见时,耳朵(雷达)能告诉我们下面是什么。”
🌟 二、模型的四大核心创新点
🧩 1️⃣ 异构数据融合架构(SAR + 光学)
✨ 创新点:
🧠 原理:
- 光学图像提供颜色、光谱信息;
- SAR 图像能穿透云层,提供地表几何和纹理结构;
- 网络通过多通道输入,将两者融合,获得“云下地物”的完整特征。
🎯 效果:
- 解决厚云遮挡下信息缺失问题;
- 避免模型凭空“猜测”;
- 提升地物边界和结构的恢复精度。
💬 类比: 光学图像像“彩色照片”,SAR 像“摸轮廓的盲文”, 模型学会把两种感觉合并成“既有颜色又有形状”的感知。
🧠 2️⃣ 深度残差网络 DSen2 架构(ResNet-based Cloud Removal)
✨ 创新点:
💡 原理:
- 输入是带云的多时相影像 + SAR;
- 输出是目标时刻的无云图像;
- 中间通过多个 残差模块(Residual Blocks) 提取多尺度特征;
- 模型学习残差(即“云造成的偏差”),从而更容易训练、收敛稳定。
🎯 效果:
- 比 GAN 稳定(不需判别器);
- 保持光谱一致性;
- 减少训练噪声和伪影。
🧩 类比: 模型不是“从零画图”,而是“在原图上擦掉云、补细节”,残差结构就像“精修师的橡皮擦”。
⚙️ 3️⃣ 云自适应正则化损失(Cloud-Adaptive Regularization Loss, CARL)
✨ 创新点:
💡 原理:
- 云区:用 L1/L2 强约束模型输出与无云目标一致;
- 晴空区:用弱约束或 identity loss,避免模型误修改;
- 全图:再用感知一致性损失保证全局视觉协调。
🎯 效果:
- 模型“重点修云,不乱动晴空”;
- 避免传统网络那种“云没去干净,晴空却变色”的问题。
🧠 类比: 就像 AI 修图师有指令:“只修云区,不许动蓝天”, 这让结果自然且可信。
🌍 4️⃣ 大规模真实云数据集 SEN12MS-CR
✨ 创新点:
- SAR 图像;
- 云覆盖光学图像;
- 对应的目标无云图像。
🎯 意义:
- 提供训练与验证标准;
- 弥补了以往“模拟云数据集”的局限;
- 为后续模型(如 SARFusionNet、CloudDiffusion)提供了 benchmark。
💬 类比: 以前大家都用“人造假云”做实验, DSen2-CR 提供了“全球真实云”的训练教材。
📊 三、创新点总结对比表
创新方向
| DSen2-CR 解决的问题
| 技术方案
| 改进效果
|
异构融合
| 光学无法穿透云
| 融合 SAR + 光学
| 云下结构更清晰
|
稳定架构
| GAN 不稳、发散
| 残差网络(DSen2)
| 训练稳,纹理自然
|
目标损失
| 云区/晴空混淆
| CARL 分区损失
| 修云区更精确,减少伪改
|
数据基础
| 模拟云不真实
| SEN12MS-CR
| 泛化更强,结果更可信
|
🧠 四、一句话总结
🌤️ DSen2-CR 的核心创新是: “把能穿云的雷达眼睛(SAR)与彩色光学眼睛(S2)结合, 用残差网络学习‘只修云区’的规律, 并用云自适应损失教模型区分哪里该修、哪里不该动。”
3、模型的网络结构
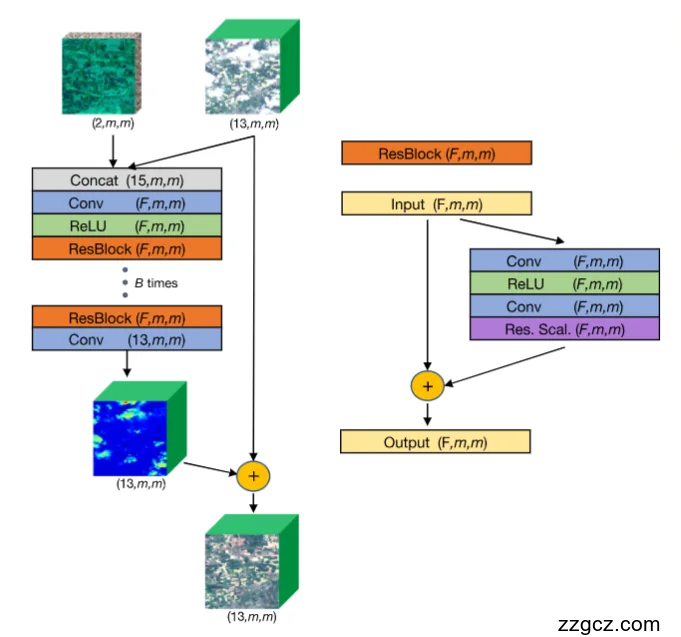
🌈 一、整体思路:
把“看得见云”的光学图像 和 “能穿云”的SAR雷达图像 合起来, 教神经网络学会“在云下复原地表”。
🧠 换个形象的比喻:
- 一只“眼睛”是光学相机(Sentinel-2),能看见颜色,但看不穿云;
- 另一只“眼睛”是雷达(Sentinel-1),能穿云,却只有黑白的纹理轮廓;
- 模型的任务,就是把这两种感知合成一张清晰的无云图像。
🧩 二、输入数据
输入类型
| 维度
| 作用
|
SAR 图像(Sentinel-1)
| (2, m, m)
| 提供云下结构、纹理信息
|
光学图像(Sentinel-2)
| (13, m, m)
| 提供颜色、光谱信息
|
- “2”表示 SAR 的两个极化通道(VV、VH);
- “13”表示光学的13个光谱波段(从可见光到近红外)。
🧠 可以理解为: SAR 像是“描线稿”,光学像是“上色参考”。
⚙️ 三、特征融合与编码部分(左侧灰蓝区域)
- 把两个输入直接拼在一起,形成一个“15通道”的输入块。
- 这一步实现了 光学+SAR 的早期融合(early fusion)。
- 输出尺寸:(15, m, m)。
类比: 就像把彩色图和雷达图摞在一起,交给模型统一处理。
- 用一个卷积层(Conv)提取融合特征;
- 激活函数 ReLU 引入非线性,使模型能识别复杂纹理。
🎨 类比: 就像修图师先观察颜色层与轮廓层的关系,找出云下可能的边界。
- 这里堆叠了 B 个残差块(通常 8 个);
- 每个块都包含:
- 两个卷积(Conv)层;
- 一个 ReLU;
- 以及残差跳连(shortcut)。
👉 功能:
- 学习“云区和无云区的差异”;
- 保持输入输出的整体一致;
- 减少梯度消失问题,让网络更深也能稳定训练。
💬 类比: 模型不是重新画图,而是“在原图上擦掉云、补上纹理”。
🧱 四、残差块内部结构(右侧橙紫模块)
输入特征 → 卷积 → ReLU → 卷积 → 残差缩放 → 加回输入 → 输出
🔧 类比: 修图师每次轻轻修一点,再与原图叠加,避免“修过头”。
🧩 五、输出层与重建部分
- 再经过一个残差块提炼特征;
- 最后一层卷积输出 13 个光谱通道;
- 对应无云的光学图像预测结果。
- 网络输出的是预测残差(即“云的差异”);
- 与原始带云图像相加,得到最终的无云图像。
🌤️ 类比: 网络输出的“修补层”叠加回原图,就像 PS 的“修复图层”。
📊 六、网络的三大特征总结
模块
| 功能
| 通俗理解
|
融合输入
| SAR + 光学拼接
| “听觉 + 视觉”双感知
|
深度残差块
| 提取局部与全局特征
| “多层修图、逐步精修”
|
残差输出
| 输出云区修正量
| “修云不动晴天”
|
🌍 七、整体工作流程(总结版)
💡 八、一句话总结
🧠 DSen2-CR 网络结构 就像一个“懂雷达的图像修复师”: 它一边用雷达摸出云下的地物轮廓, 一边用光学颜色填补细节, 通过残差学习轻柔地修正每一片云, 最终输出一张色彩真实、结构准确、云雾消失的地表图像。
4、模型的核心不足与后续改进方向
🧩 一、DSen2-CR 的核心不足与缺陷
⚠️ 1️⃣ 异构特征融合方式过于“简单粗暴”
- DSen2-CR 只是直接把 SAR 与光学影像“拼接(Concatenate)”后送进卷积网络。
- 这种“早期融合”虽然简单,却忽略了两种数据的本质差异:
- SAR:几何结构强,但噪声多、非线性高;
- 光学:光谱信息丰富,但受云干扰大。
- 模型难以充分对齐和理解两种模态之间的对应关系;
- 有时甚至出现“纹理错位”或“光谱不匹配”。
🧠 类比: 就像直接把“声波图”和“彩色照片”叠在一起训练, 模型能学到点规律,但始终“听不懂”SAR的语法。
⚠️ 2️⃣ 缺乏显式的空间配准与几何对齐机制
- 一旦两者存在位移或形变,融合卷积层会误配位置特征;
- 导致输出图像边缘模糊、建筑物错位。
💬 换句话说: 模型“假设”两张图重合,但现实中往往不是。
⚠️ 3️⃣ 仅使用卷积建模,感受野有限
- 网络核心仍是纯卷积(CNN)结构;
- 缺乏全局依赖建模能力;
- 对长距离空间关系或大范围云区处理效果差。
- 在大片厚云区域,模型容易“平均化”预测,输出模糊块;
- 无法像 Transformer 那样捕捉远处地物的上下文信息。
🌥️ 类比: CNN 只能看到局部的“局部图块”, 看不到“整张地图”的全貌。
⚠️ 4️⃣ 光谱一致性仍存在偏差
- 虽然使用残差学习稳定了训练,但不同波段间仍可能出现“色偏”;
- 尤其在近红外和短波红外通道,输出亮度与真实无云图存在差异。
🔍 结果: 地表结构对了,但颜色“不自然”或“不连贯”。
⚠️ 5️⃣ 时序信息完全缺失
- 模型只使用一张带云光学图和对应时刻的 SAR;
- 没有利用多时相(时间序列)的光学信息。
- 对临时云遮挡可以恢复;
- 但对“持续云覆盖”或“云下动态变化”无能为力。
🧠 类比: 模型只能“凭当前这一帧修图”, 没有时间维度的“前后参考帧”。
⚠️ 6️⃣ 数据驱动强,但物理约束弱
- 模型完全依赖学习数据映射;
- 没有融入物理散射规律或大气辐射模型。
- 生成结果虽逼真,但缺乏物理一致性;
- 在不同地区、季节、传感器组合下泛化能力有限。
🌍 这也是后续物理-引导模型(如 PhysCloudNet, 2023)改进的重点。
🔧 二、论文作者提出的改进方向
- 探索更高级的融合机制 —— 如基于注意力的跨模态特征交互;
- 引入时序信息 —— 结合多时相观测提高时空一致性;
- 物理与学习融合 —— 加入大气、雷达散射等物理约束;
- 优化配准与几何校正 —— 让网络自动对齐异源特征。
🌈 三、后续基于 DSen2-CR 改进的模型
改进模型
| 年份
| 改进核心
| 主要提升
|
DSen2-CR++
| 2021
| 增强残差连接 + 光谱一致性损失
| 减少波段色偏
|
CR-TransSAR
| 2023
| 引入 Transformer 跨模态注意力,学习 SAR↔Optical 映射
| 提升厚云区结构恢复
|
SARFusionNet
| 2023
| 多尺度融合 + 空间对齐模块
| 改善建筑错位问题
|
PhysCloudNet
| 2024
| 加入大气散射模型与光谱物理约束
| 增强辐射一致性
|
CloudFusionFormer
| 2024
| 基于 Transformer 的多模态长距离依赖建模
| 云区纹理更清晰、色彩自然
|
TempSAR-CR
| 2025
| 加入多时相序列(Temporal SAR + Optical)
| 支持持续云覆盖修复
|
🧭 四、演化总结:从 DSen2-CR 到新一代模型
世代
| 模型代表
| 核心机制
| 主要突破
|
第一代(2020)
| DSen2-CR
| CNN + SAR-Optical 融合
| 首次跨模态融合
|
第二代(2021-2023)
| DSen2-CR++、SARFusionNet
| 多尺度与几何对齐
| 改善结构错位
|
第三代(2023-2024)
| CR-TransSAR、CloudFusionFormer
| Transformer 注意力
| 融合特征更精准
|
第四代(2024-2025)
| TempSAR-CR、PhysCloudNet
| 加入时序与物理约束
| 提升长期稳定性与物理一致性
|
🧠 五、一句话总结
🌍 DSen2-CR 的意义在于“开了头”: 它首次让“光学 + SAR”协作解决云去除问题, 但仍是一个“早期融合 + 卷积修复”的方案。 后续研究逐步在它的基础上:
- 加入注意力机制 → 让两种模态真正对话;
- 加入时序信息 → 让模型理解时间变化;
- 加入物理约束 → 让输出更符合大气与辐射规律。