Former-CR(2023)首次将基于Uformer架构用于SAR-光学厚云去除
1、研究背景和动机
🌦 一、问题背景:地球“看不清”的老难题
想象一下:你拍一张全球地图,结果上面大半都是白茫茫的云, 想看农田、城市、灾情?——全被挡住了。
- 农作物监测(因为看不清作物长势);
- 灾害评估(洪水或山火后云太厚,看不出地表);
- 环境监控(空气、水体、城市扩张……全模糊)。
🌍 二、旧方法的三种套路 —— 各有毛病
方法类型
| 核心思路
| 问题
|
单幅图像修复法
| 用图像本身晴空区去“补云区”
| 云太厚时根本没信息可补
|
多时相法
| 用不同时刻的无云图作参考
| 云多地区经常等不到“无云时刻”
|
多光学源融合
| 把多颗卫星的光学数据融合
| 光学都怕云,换汤不换药
|
🎨 就像你修一张照片:
- 第一种是“自己涂涂改改”;
- 第二种是“拿另一张没云的照片来对照”;
- 第三种是“几台相机拼在一起拍”—— 但如果天天阴天,那几乎都白搭。
📡 三、新思路:用“能穿云”的雷达来帮忙
“既然光学看不见,那我们用**雷达(SAR)**来当透视眼!”
- **SAR(合成孔径雷达)**能穿透云层、雾气、甚至轻微降雨;
- 它提供的是地物的结构、形状和粗糙度信息;
- 虽然是黑白的、带噪声,但能“摸到”地表纹理。
“如何把 SAR 的‘骨架图’ 和 光学的‘彩色图’ 融合成一张既真实又清晰的无云图?”
🧠 四、为什么要用 Transformer?
CNN 就像“近视修图师”: 它修得了小块区域,却看不到整张图的全貌。
- 它能通过**自注意力机制(Self-Attention)**看全局;
- 让模型理解: “这一块云,可能对应远处那片地物的延续”;
- 还能跨模态(SAR ↔ 光学)地对齐对应区域。
🌈 就像一个“聪明的修图师”, 既能看全局,又能专注到局部细节。
🧩 五、UFormer:让 Transformer 更像“修图匠”
- 结构上像一个“U”字(编码 + 解码),
- 在中间用 局部增强窗口注意力(LeWin Attention):
- 小窗口内看细节;
- 大范围上看整体;
- 最终实现:既能“看远”,又能“修细”。
💬 类比: 它就像一个美术老师,一边退后看整张画的构图,一边低头修每一笔的阴影。
🧮 六、损失设计:让模型“像人一样看图”
- 让模型不只是“像素对像素地还原”,
- 而是“从视觉感觉上看起来像真实的无云图”。
🌤️ 换句话说, 模型学会了“修图的审美”,不是死记硬背颜色。
🎯 七、研究动机总结(形象版)
研究动机
| 通俗解释
|
☁️ 云多、光学失效
| “天老是阴,照片都糊”
|
📡 融合 SAR 的穿云能力
| “雷达能摸出云下的轮廓”
|
🧠 用 Transformer 取代 CNN
| “修图师换成更聪明的 AI”
|
🧩 引入 UFormer 结构
| “既看全局又修细节”
|
🎨 加入感知损失
| “修得自然,不死板”
|
🧭 八、一句话总结
🌍 Former-CR 的研究动机:是要打造一个能“透云看地”的聪明修图师,把雷达的结构线索与光学的颜色细节融合,用 U型 Transformer 架构 既“看全局”又“修细节”,实现真正意义上的 厚云可修、细节不糊、色彩自然 的多模态去云。
第2部分:模型的核心创新点总结
- 真正把 Transformer 引进“厚云去除”,且面向 SAR+光学 的多模态场景
- 以 U-shaped Transformer(UFormer) 做骨干:输入用 SAR + 多云 RGB,输出直接预测 无云 RGB,把全局关系建模带进云去除任务里。
2) 两分支设计:残差分支 + 重建分支,既稳又好用
- 网络分两路:
- 重建分支负责“看懂并重绘”——包含**预处理(IPP) → 编码-解码 → 图像还原(Decloud-IR)**三步;
- 残差分支把原始多云 RGB 一直“原样保留”,最后与重建结果相加,生成更自然的无云图。 这样既能修云,又不轻易改动不该改的区域。
3) UFormer / LeWin 模块:窗口注意力 + 卷积,兼顾“看远”和“抠细节”
- 选用 LeWin-Transformer(局部增强窗口注意力),在注意力里融合卷积以增强局部特征提取;因此同时保证全局一致性与细节/纹理复原,而且参数量可控,适合影像修复类任务。
4) IPP 与 Decloud-IR:把多源特征“喂得进、还得出”
- IPP 把 SAR 与 RGB 的浅层特征对齐到编码器所需的形状/通道数;
- Decloud-IR 负责把解码得到的特征图正确映射回 RGB 图像空间,确保输出颜色/格式与目标一致。
5) 端到端的多模态融合:显式用 SAR 辅助重建厚云区
- 整体管线从“多云 RGB + SAR”到“无云 RGB”端到端训练,充分利用 SAR 的结构线索与 RGB 的色彩语义,并通过残差合成抑制过度修复。
6) 效果验证:全局结构与细节更稳、更清晰
- 在多种场景(山地、城市、农田)和不同云量下,Former-CR 的细节与结构一致性更好;定量上 SSIM/PSNR/MAE 综合领先,尤其 SSIM 反映的全局结构恢复优势明显。
一句话版
Former-CR 的“新”在于:用 U-shaped Transformer(LeWin) 把 SAR 的“穿云骨架” 和 光学的“颜色语义” 做成一体化的端到端重建; 通过 两分支(重建+残差) 与 IPP/Decloud-IR,既修得动真格,又不乱改干净区,最终在厚云场景拿到更好的全局一致性与细节质量。
3、模型的网络结构
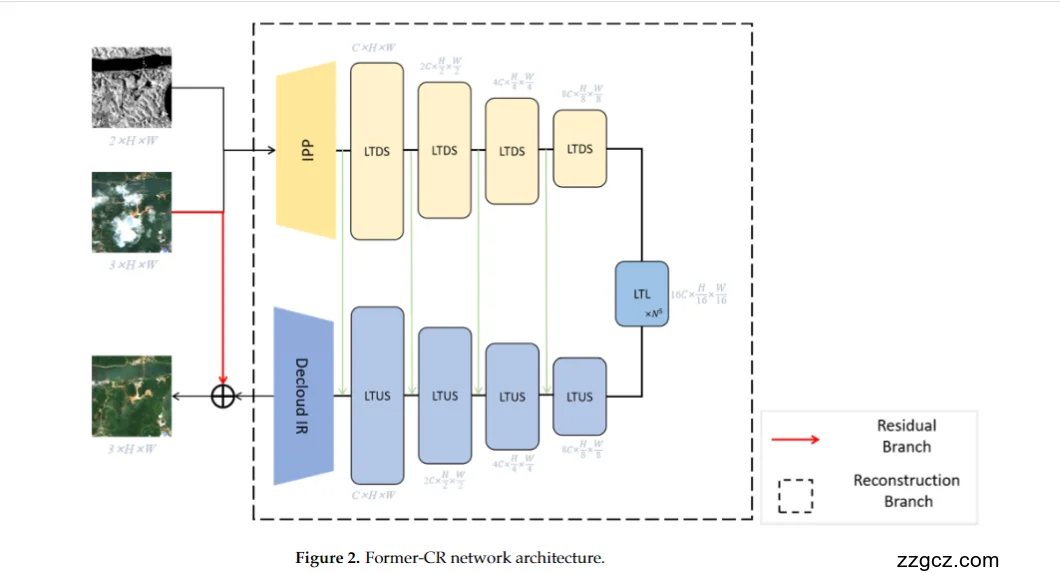
🧠 一、整体结构:两条路的“聪明修图师”
- 主修复分支(蓝黄相间的 Reconstruction Branch) ——负责真正“看懂云下的地物”并重建无云图像;
- 残差分支(红线标的 Residual Branch) ——负责保留原图中那些没被云遮住的区域,防止“修过头”。
💬 类比: 就像一个修图师:
- 主分支负责把被云挡住的地方重新画出来;
- 副分支保存原来的蓝天和地物,
- 最后两者融合,得到自然又真实的结果。
🌦 二、输入部分:双模态输入
- SAR 图像(上):两通道(VV、VH极化) → 提供“云下结构、纹理、边缘”;
- 带云光学图像(中):三通道(RGB) → 提供“颜色与光谱信息”;
- 目标输出(下):无云的RGB图像(模型要学着去复原它)。
🧩 三、IPP(输入预处理模块)
- 它先用卷积将SAR与光学特征映射到相同的维度;
- 然后把两者拼接成一个联合特征图 C×H×WC \times H \times WC×H×W。
🧠 类比: 就像你把红外照片和普通照片统一成相同大小、同样的色彩空间, 方便AI后面一起处理。
🔷 四、主干部分:U-shaped Transformer
🟨 编码器(上半部分,黄色 LTDS 模块)
- 模块名称:LTDS(Locally-enhanced Transformer Down-Sampling);
- 功能:逐层下采样、提取多尺度特征;
- 每层同时使用局部窗口注意力(LeWin Attention)和卷积增强, 既能“看远”又能“抠细节”。
- 通道数不断增加(C → 2C → 4C → 8C),空间尺寸逐步减半。
💬 类比: 模型像拿着放大镜,一层层缩小图像看全局的布局。
🟦 解码器(下半部分,蓝色 LTUS 模块)
- 模块名称:LTUS(Locally-enhanced Transformer Up-Sampling);
- 功能:一步步恢复空间分辨率;
- 每层会把上采样结果与对应编码层特征拼接(绿色竖线所示)形成“跳跃连接”;
- 这样能把全局语义与局部细节结合。
💬 类比: 修图师在放大局部上色时,仍记得整张画的整体构图。
🔵 中间瓶颈层(LTL 模块)
- 名称:LTL(Locally-enhanced Transformer Layer);
- 位于U形的底部,是网络“最深的思考层”;
- 它拥有最广的感受野、最强的全局注意力;
- 相当于在“全图范围”里理解: 哪些地方被云遮、哪些地方可从SAR推测出结构。
🧠 类比: 这是修图师“退远一步”看整张照片,确定修复策略的阶段。
🧱 五、Decloud-IR(输出还原模块)
- 它把多通道特征通过卷积映射为 3 通道 RGB 输出;
- 确保颜色、亮度、细节都符合光学影像的风格;
- 最终输出的是**“修复分支结果”**(Reconstruction branch output)。
🌈 类比: 就像AI修图完,把内部的“特征草图”重新渲染成一张彩色照片。
🔴 六、Residual Branch(残差分支)
- 直接将输入的“带云光学图像”绕过主干网络,
- 与修复分支的输出结果在最后相加(⊕)。
- 保留原图中晴空区域的真实像素;
- 避免模型过度修复;
- 让输出更自然、过渡更平滑。
💬 类比: 就像修图时只修被云盖住的地方,而其他区域保持原样。
🎯 七、输出结果
原始多云图像 + 修复分支预测的“云层差异”
- 晴空区保持原样;
- 云区被补充出地物结构与颜色;
- 结果更干净、更自然。
🧩 八、模块总结对照表
模块
| 名称全称
| 功能
| 通俗解释
|
IPP
| Input Pre-Processor
| 融合SAR+光学输入
| “统一语言”
|
LTDS
| Locally-enhanced Transformer Down-Sampling
| 提取多尺度全局特征
| “远看全局”
|
LTL
| Locally-enhanced Transformer Layer
| 捕捉全局上下文
| “整体规划”
|
LTUS
| Locally-enhanced Transformer Up-Sampling
| 恢复空间细节
| “近看修补”
|
Decloud-IR
| Image Restoration
| 输出RGB图像
| “上色成图”
|
Residual Branch
| 残差分支
| 保留原图晴区,防止过修
| “只修云,不动晴”
|
💡 九、一句话总结
🌍 Former-CR 的网络结构就像一个“双手并用的AI修图师”:
- 一只手(SAR)摸出云下的轮廓;
- 一只手(光学)看颜色与细节;
- 通过 U形 Transformer 同时“看远+修细”;
- 最后只修该修的地方,不乱动晴空; 于是生成一张既结构准确又视觉自然的无云卫星图。
4、模型的核心不足与后续改进方向?
🌧 一、模型的核心不足
1️⃣ 计算量大、模型复杂度高
- 参数量大,显存占用高;
- 推理速度慢,不适合大规模遥感数据处理;
- 训练时对 GPU 资源要求非常高。
💬 类比:它就像一个“手工修图的超级AI”,修得精细,但太慢、太贵。
- 引入轻量化 Transformer(如 Swin-Lite、MobileViT);
- 使用 混合卷积-注意力结构(ConvFormer类)减少计算;
- 或采用 低分辨率编码 + 高分辨率细化 的两阶段策略。
2️⃣ SAR 与光学的跨模态对齐仍不完美
🧠 类比:就像用黑白线稿去推测彩照颜色,AI能猜个大概,但有时“猜错色调”。
- 在输入前增加 跨模态对齐模块(Cross-modal Alignment Block, CMAB);
- 使用 互信息约束 或 对比学习(contrastive learning) 提升对齐鲁棒性;
- 加入 可学习配准模块(Learnable Registration),自动纠正几何偏差。
3️⃣ 细节还原存在“过平滑”问题
- 边缘模糊(特别是在建筑、道路区域);
- 细节“抹掉”现象(因为模型追求全局一致性而牺牲局部锐度)。
- 加入 多尺度细节增强模块(Multi-scale Detail Refinement, MDR);
- 使用 感知+结构混合损失(如 Perceptual + SSIM + Edge Loss);
- 引入 对抗判别器(GAN-style Refiner) 增强真实感。
4️⃣ 缺乏时序信息利用(只用单时刻 SAR + 光学)
🌍 类比:只看一张云图,你分不清是云还是湖面反光; 但看多张时间序列,就能知道哪部分总在变化(云),哪部分固定(地物)。
- 引入 时序Transformer模块(Temporal Attention);
- 与 CloudTran++ 等多时相模型融合(“多模态 + 多时相”);
- 建立 3D Transformer 时空块结构(Spatial-Temporal Hybrid)。
5️⃣ 泛化能力有限、依赖训练域
- SAR信号受成像角度、极化方式影响;
- 光学数据受光照、季节变化干扰;
- Transformer 对数据分布漂移较敏感。
- 增加 多地区、多季节、多卫星混合训练集;
- 引入 领域自适应(Domain Adaptation) 技术;
- 结合 少样本微调(Few-shot Fine-tuning) 提升跨域泛化。
🧭 二、后续改进模型与趋势
年份
| 改进模型
| 核心创新
| 针对的问题
|
2023下半年 – CloudFusionFormer
| 三模态融合(SAR + 光学 + 高光谱)
| 加强多源互补性与颜色一致性
| 解决跨模态信息丢失
|
2024 – TempSAR-CR
| 引入时序Transformer + SAR序列
| 利用时间维度区分云与地物变化
| 克服单时刻局限
|
2024 – CloudDiff
| 基于扩散模型的去云
| 学习真实分布、减少伪影
| 改善纹理自然度
|
2025趋势 – CloudTran++ / CloudFusionFormer 2.0
| 时空多模态联合Transformer
| 同时处理时序、SAR、光学三源输入
| 实现稳健跨时空去云
|
🧩 三、一句话总结
Former-CR 的不足在于: 它修得准,但“算得重”; 它看得远,但“猜颜色不稳”; 它修得细,但“缺少时间记忆”。
后续改进方向: 让模型更“轻”、更“稳”、更“聪明”—— 通过轻量化结构、跨模态对齐、时序增强与对抗细化, 让AI不只是“修云图”,而是真正理解云下地球的多源时空变化。