STGAN(2020):利用时空生成网络去除卫星图像中的云
1、研究背景和动机
1.1、研究背景:云层是遥感影像的“天敌”
- 全球约 2/3 的区域 在任意时刻都被云层覆盖;
- 厚云几乎完全挡住地物;
- 即便是薄云、半透明云,也会让图像模糊、亮度偏移。
🌫 “如果卫星看不清地面,我们就无法准确监测地球。”
1.2、传统方法的困境:靠“拼接”和“滤波”不够聪明
- 合成图像法(图像拼接)
把不同时间拍的图像叠加,用算法拼出无云区域。
- 缺点:需要很多张干净的图;
- 要求场景不能变(农田不能长高、城市不能建楼);
- 一旦长期多云或地表变化,就失效。
- 滤波 / 修复法(如均值、中值滤波)
用周围像素平均值或插值去“补洞”。
- 缺点:云下区域信息完全丢失;
- 容易生成模糊或错误的纹理。
🔍 通俗理解: 传统方法就像“擦照片”的笨办法——看不到的地方只能猜、平均、模糊补。
1.3、早期深度学习方法的不足:假数据训练、忽视时序信息
- MCGAN(Multispectral cGAN);
- CycleGAN(无配对图像翻译)。
(1)靠“合成云”训练,太假
- 模型学到的是“人工云”特征;
- 到真实场景时就“翻车”了;
- 泛化能力差,细节不真实。
比喻:像教AI擦掉“画上去的白雾”,但现实的云更复杂、透明、有阴影,它就认不出来。
(2)只看一张图,信息太少
所以如果我们能利用这些“时间序列”图像,就能像拼图一样补全被云遮的地方。
1.4、研究动机:让模型“看时间”,整合多时相信息
☀️ “卫星不是只拍一次,而是每隔几天就拍一张, 云虽然变,但地面是同一个。”
- 收集全球最大规模的真实有云-无云配对数据集(97,640对);
- 进一步构建 时序数据集: 每个样本由一张无云图 + 多张不同时刻的有云图组成;
- 让模型从“时间”中学习,还原真实地表。
🔧 核心想法:“人眼能通过几天内的多张照片拼出全貌,那AI也能。”
1.5、STGAN 的诞生逻辑
- 把“去云”转化为一个时空条件生成问题;
- 输入:同一区域不同时间的几张有云图;
- 输出:一张干净、真实的无云图;
- 网络设计结合了 U-Net 和 ResNet;
- 判别器采用 PatchGAN 来判断生成图是否逼真。
✅ “突破合成数据的局限,真正利用卫星的时序观测信息,在浓云、复杂地形下也能生成真实可信的无云图像。”
1.6、总结一句话
STGAN 的研究动机是: 传统去云方法太笨,GAN 太假, 所以要让AI同时“看空间”和“看时间”, 利用卫星的多时相观测去重建云下的真实地表。这就是它被称为“时空生成网络”的原因。
2、模型的核心创新点总结
2.1、把“去云”重新表述为多时相 → 单张的时空条件生成问题
- 不是只看一张云图硬猜无云图,而是同时喂入同一地点不同时间的多张云图,由生成器“综合”出一张干净的无云结果(multi-to-one)。这样只要某一帧露出一点地物,模型就能利用它来补其它帧被云遮的地方。
2.2、首次提供两类真实配对数据集,规模大、覆盖广
- 单幅配对集(cloud ↔ clear)与时序配对集(多帧 cloud ↔ clear),基于 Sentinel-2 真数据构建,总计约 97,640 对样本,且包含 RGB 与 IR(近红外)两种版本;时序配对集是同类工作的首创,为训练/评测“时空生成”提供了基础。
2.3、设计**时空生成网络(STGAN)**两种骨干,专为“多帧融合”
- 提出两种生成器:
- 分支式 ResNet:每帧各自编码–解码,分阶段成对/逐级融合(增强跨帧信息对齐与补全),可选“分支共享权重”。
- 分支式 U-Net:三路独立编码,在深层做联合解码,并通过跳跃连接把浅层细节带到重建端。
- 两者都面向“多对一”的时空特征融合,判别器采用 PatchGAN。
2.4、明确的训练目标与时空条件化
- 损失为 cGAN 对抗损失 + L1 重建损失;判别器同时看“候选无云图 + 该样本的多帧云图”,迫使生成器在时序上下文中产出更可信的无云结果。
2.5、充分利用**多模态(RGB+IR)**信息
- 提供和验证 RGB / RGB+IR 两套模型;实验显示加入 IR 显著提高 SSIM/细节连贯性,有助于减少伪影、稳住纹理。
2.6、系统级实证:对比单帧方法与传统合成/滤波显著更强
- 在真实时序数据上,STGAN(尤其 ResNet 版)PSNR/SSIM 明显超过单帧 Pix2Pix、MCGAN 与常见均值/中值/复合法;
- 作为外部效用验证,生成无云图用于土地覆盖分类,准确率接近真实无云图,证明“可用性”而非只看像素指标
3、模型的网络结构
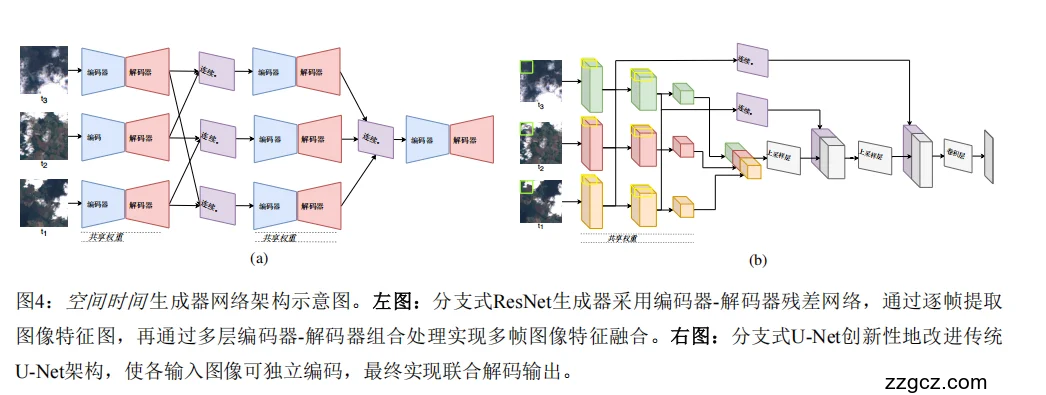
3.1、总体思路:让AI“看时间”,再拼出无云图
- 在某一天,云挡住了山;
- 第二天,云挪了点,露出一点田地;
- 第三天,山又清楚了但田地模糊。
两种结构思路(图 a 和图 b)
🔹 (a) 分支式 ResNet 结构 ——「逐层融合」思路
- 编码阶段(左侧) 每一帧图像都通过各自的编码器提取特征(颜色、纹理、云影信息)。
- 跨帧特征融合(中间)
不同帧的特征在多个“融合层”逐级合并。
- 比如第 1 层先对齐大致的地貌;
- 第 2 层再细化局部纹理;
- 最后层整合整体语义。
- 解码阶段(右侧) 把融合后的特征逐层还原成一张完整的无云图。
🔹 (b) 分支式 U-Net 结构 ——「独立编码,联合解码」思路
- 独立编码(左半部分) 每一时相(t₁、t₂、t₃)都有自己的“特征提取管道”,各自提取云下地物的局部细节。
- 中间特征联合(中间绿色部分) 这些多帧的编码结果在深层统一融合(Concat 或 加权融合),得到一个时序一致的特征图。
- 联合解码(右半部分) 解码器再利用 U-Net 式的跳跃连接(Skip Connections),把浅层的细节信息带回来,逐步生成高分辨率的无云输出。
3.2、关键设计亮点
模块
| 作用
| 形象解释
|
编码器(Encoder)
| 从每张有云图中提取特征,识别哪些区域是云、哪些是地物。
| 相机的“感光芯片”,提取不同图像特征。
|
融合层(Feature Fusion)
| 在多帧之间对齐、比较、融合特征信息,整合“时间维度”的差异。
| 比对不同时间的照片,看看哪里云变、哪里地物没变。
|
解码器(Decoder)
| 将融合后的高维特征重新还原成无云图像。
| 把“线索”组合成清晰的成品图。
|
跳跃连接(Skip Connections)
| 把浅层细节信息(纹理、边缘)直接传递到解码端。
| 保留原图细节,防止输出模糊。
|
PatchGAN 判别器
| 判断生成的无云图是否真实、自然。
| 像“鉴定师”,挑出假纹理、假边界。
|
3.3、数据流动小结(一步步的过程)
- 输入:同一地区 3 个时刻 t₁、t₂、t₃ 的有云图;
- 各自进入独立的编码网络;
- 多层次地融合时序特征;
- 经过解码器恢复出空间分辨率;
- 输出:一张干净、细节保留的无云图像;
- 判别器再对输出进行真伪判别,反向优化生成器。
3.4、整体理解
STGAN 的网络结构就像一个“时空拼图机器”:
- 左边多条分支看“时间变化”;
- 中间模块融合“多帧信息”;
- 右边再重建“地球本来的样子”。
它既能看到不同时间的变化,又能理解空间结构, 从而在云很厚、区域复杂的情况下依然生成自然、可信的无云图像。
4、模型的核心不足与缺陷
4.1、模型的核心不足与缺陷
- 对密集云层区域的重建仍不理想
✦ 说明:即使在多时相输入下,如果所有帧中都被厚云完全遮挡,模型也无法恢复真实地物,只能生成“逼真但错误”的地表纹理。
- 生成器缺少物理约束,只能凭上下文纹理推测;
- 时空信息融合层仅在像素特征层面运算,缺乏显式的几何或光谱一致性约束;
- 数据集中此类样本稀少,导致模型对厚云样本泛化差。
- 时序假设过强(地表缓变假设)
✦ 问题:若地物随季节、耕作或建设变化明显(例如城市扩张、农作物生长),模型会误将真实变化识别为云遮差异,从而产生错误重建。
- 时序输入数量与融合方式受限
✦ 问题:这种手工设定的融合结构在更长序列(>3 帧)或不规则采样时难以扩展,也不能自适应权衡不同帧的重要性。
- 跨帧特征对齐不足
✦ 导致:不同时间的视角、云移动、几何误差可能造成边界错位或重影,从而降低 SSIM 和 PSNR 的稳定性。
- 模态利用不足与物理先验缺失
✦ 说明:加入 IR 确实提升性能,但模型并未充分挖掘光谱间互补信息。
4.2、论文外延与作者暗示的后续改进方向
- 多模态融合 → 引入红外(IR)信道显著提升 SSIM 至 0.734
后续研究据此发展出 SAR + Optical 融合模型,用雷达信号穿透厚云补充光学盲区。
- 网络结构层面 → STGAN 通过 ResNet 结构已优于 U-Net,但作者承认模型仍依赖局部卷积特征,缺乏长距离依赖建模;这为后续引入注意力机制 / Transformer 模块奠定了方向。
5、后续基于 STGAN 的改进模型与思路
(1)SpA GAN(空间注意力生成对抗网络)
✦ 改进机制:利用 SARB (Spatial Attention Residual Block) 在云区聚焦重要特征,从而改进 STGAN 对厚云与纹理恢复不佳的问题。
(2)SACTNet(Spatial Attention Context Transformer Network, 2021)
(3)ViT / Hybrid Transformer 改进方向(2022 以后)
(4)多源数据融合(SAR-Optical CR Network)
阶段
| 代表模型
| 关键创新
| 改进 STGAN 的不足
|
2020
| STGAN
| 多时相→单帧 cGAN; RGB+IR 双模态
| 首次提出时空生成思路
|
2020 – 2021
| SpA GAN
| 空间注意力模块 (SAM/SARB) 定位云区
| 减少伪影、提升细节
|
2021 – 2022
| SACTNet / CvT 混合结构
| 引入 Transformer 长程依赖 + 局部上下文
| 改善融合与泛化
|
2022 以后
| SAR-Optical / Hybrid ViT
| 多源、多模态融合 + 窗口注意力
| 克服厚云重建与跨模态差异
|
STGAN 的主要不足在于:厚云区重建能力弱、时序假设过强、帧间融合与对齐有限、光谱利用不足。 后续改进方向沿着两条主线发展: 1️⃣ 结构层面 → 引入注意力 / Transformer 机制增强特征融合与全局建模; 2️⃣ 数据层面 → 引入 IR 和 SAR 等多模态数据提升物理一致性与穿云能力。