SpA-GAN(2020):遥感影像云移除与空间注意力生成对抗网络
导出时间:2025/11/24 08:46:10
1、研究背景和动机
研究背景(问题场景 & 现状)
- 光学遥感影像应用广泛(国防、环境、气象等),但成像极易受气候影响,尤其是“云”。在做任何下游分析前,“去云”是必不可少的预处理步骤。
- 云的类型与难度不同:
- 薄云(thin cloud):地物信息仍保留,有可能从单张图像中恢复;
- 厚云(thick cloud):地物信息基本被遮挡,仅凭单时相/单幅很难恢复,通常需要多时相数据;
- 云影常与厚云同时出现。论文聚焦“单张光学遥感影像的薄云去除”。
- 本质上,“去云”可视作图像去噪问题(云≈背景噪声)。既有方法分为传统图像处理与深度学习两类;视觉社区在去雾、去雨、水印/阴影去除上已有进展,为“去云”提供了启发。
- 传统方法(如 HOT、DCP、同态滤波)多依赖低级特征,容易出现过校正、色偏或能力受限的问题。
- 深度学习开始被引入:有利用条件GAN的多光谱方法(需额外近红外/多光谱数据),也有基于CycleGAN的无配对学习。但这些方案在高分辨率遥感去云上仍存在不足(例如细节模糊或空间连续性破坏)。
- 应用深度学习的一个现实瓶颈是数据集匮乏。为此,有人构建了开源 RICE 数据集(含 RICE1/RICE2),为有监督训练与评测提供基础。
研究动机(为何提出 SpA-GAN)
- 现实需求:单时相、单幅图像去除“薄云”,以便在没有多时相/多传感器数据时也能恢复可用的无云影像,用于后续解译与分析。
- 现有深度学习方案的痛点:
- 纯 cGAN 往往保连续但偏模糊;
- 纯 CycleGAN 虽能去除高亮云,但可能破坏空间连续性/细节。需要一种既能精准定位云区、又能尽量保持结构与细节的机制。论文中的对比与讨论体现了这一点。
- 关键思想:人眼在观察时会把注意力集中到受遮挡/异常区域。若能在网络里显式建模“空间注意力”,就可以在生成过程中更聚焦云区,引导网络投入更多表征能力到“该修复的地方”,从而提升重建质量与细节一致性。
- 技术路线选择:
- 采用 GAN 作为生成框架,利用其强大的图像分布建模与重建能力;
- 将空间注意力机制融入生成器,做“由局部到全局”的注意力聚焦,引导云区修复,并在损失中加入注意力约束,形成端到端可训练的方案。
- 可验证性与可比性:基于开源 RICE 数据集进行对比实验,结果显示 SpA-GAN 在 PSNR/SSIM 上优于 cGAN 与 CycleGAN,验证了在去云任务中显式空间注意的有效性,这也进一步支撑了该研究路线的合理性。
一句话总结: 遥感图像普遍受云影响,而单时相单幅去“薄云”是常见且现实的需求。传统方法与早期深度学习方案要么过度校正、要么牺牲细节或连续性。SpA-GAN 的动机就是把“空间注意力”引入 GAN 的生成过程中,精准聚焦云区、提升修复质量,并在公开数据上证明其优势。
2、SpA-GAN(2020)论文的核心创新点总结
SpA-GAN(Spatial Attention Generative Adversarial Network)是首个将空间注意力机制引入遥感影像云层消除任务的生成对抗网络方法。其核心创新点可从网络结构设计、注意力机制、损失函数设计与性能表现四个方面来理解:
一、网络结构创新:生成器中的“空间注意力块”设计
论文提出的生成器在传统 cGAN 框架上进行了结构性改进,引入了多阶段空间注意力块(SAB):
- 生成器由三个阶段组成:
- 特征提取阶段:使用标准残差块提取低层语义特征;
- 云层识别阶段:引入四个 空间注意力块(SAB),逐步聚焦于云层区域,区分云区与非云区;
- 重建阶段:使用两个残差块生成清晰的无云背景。
- 每个 SAB 内含 空间注意力残差块(SARB) 与 空间注意力模块(SAM)。
- SAM 模块通过**四向循环神经网络(IRNN)**建模上下左右方向的全局依赖,生成注意力图,从而精准识别云层分布。
- SARB 则利用该注意力图“引导残差”进行定向修复,使网络“更关注云区”,减少无关区域的干扰
通俗解释:模型像人眼一样“学会看重点”——它不再平均处理整张图像,而是自动找到被云遮住的区域,把计算资源集中在这些地方去修复。
二、判别器与整体框架:对抗性学习提升图像真实性
判别器采用标准卷积网络结构(含卷积层、BN、LeakyReLU),用于区分输入图像是真实无云图像还是生成器输出图像。
这种对抗性训练确保输出结果不仅去云彻底,还视觉上更自然、结构上更连贯
三、损失函数创新:引入“注意力约束”
SpA-GAN 的总损失由三部分组成:
- 条件GAN损失(LcGAN):保持生成结果与真实分布一致;
- 像素级L1损失:确保每个像素重建精度;
- 注意力损失(LAtt):这是关键创新。
- 通过比较模型生成的注意力图A与真实云区二值图M(由阴天与晴天图像差异计算得出),
- 引导网络学习“哪里是云”,使注意力分布与真实云区匹配,从而提高云层识别准确度和去除效果
通俗解释:这就像老师在批改作业时指出“重点错在哪”,帮助模型在下一次生成时更加聚焦真正的云区,而不是乱猜。
四、实验验证与性能提升
- 在 RICE 数据集上的实验表明:
- SpA-GAN 的 PSNR 达到 30.232 dB、SSIM 达 0.954,
- 相比条件GAN提升约 3 dB、相比CycleGAN提升约 4.5 dB。
- 生成结果显示,SpA-GAN 输出的图像细节更丰富、边缘更清晰、空间连续性更好,与真实场景视觉一致性最高。
- 注意力热图进一步证明模型确实学会了“关注云层区域”,红色高注意区域精准覆盖云层分布
五、总结:论文的三大创新点概括
- 结构创新:在生成器中首次引入空间注意力机制(SAB+SAM+SARB),分阶段识别云层并重建背景;
- 损失创新:提出注意力约束损失,使网络在训练中“学会找云”;
- 性能验证:在公开数据集上显著超越 cGAN、CycleGAN,证明注意力机制对云层识别与去除的有效性。
一句话总结: SpA-GAN 的核心创新在于让生成对抗网络“会看、会想、会改”——通过空间注意力机制引导网络专注于云区,从而实现了更精准的识别、更自然的修复,是遥感图像去云任务的重要进步。
3、模型的网络结构
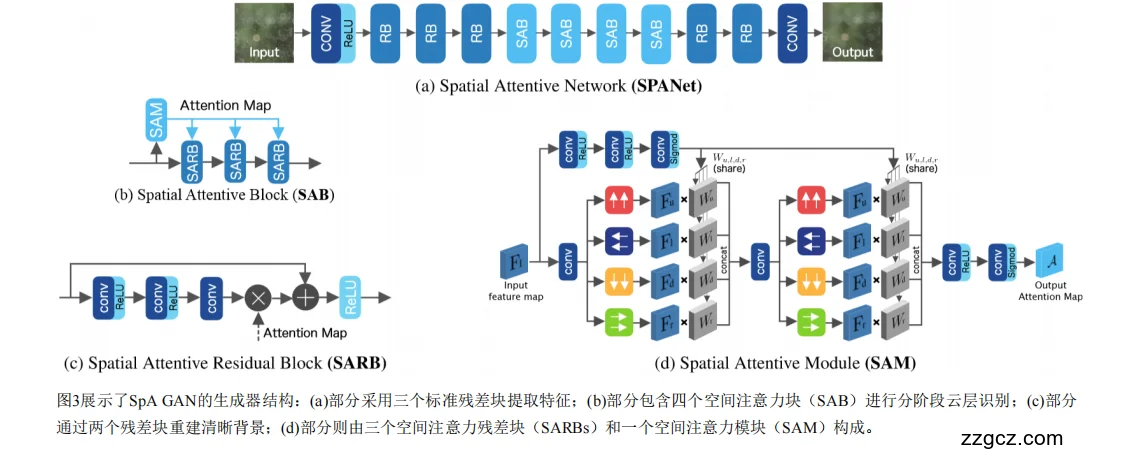
一、整体结构:像“医生看片”一样的三阶段分析
图(a) 是整个生成器的主干结构,叫做 Spatial Attentive Network (SPANet)。
它可以理解为一个“分阶段去云”的流程,主要分为三步:
- 看整体——提取图像特征(CONV + RB)
- 网络先用卷积层和若干个残差块(RB)提取整张云图的底层特征,
- 就像医生先扫一眼整张CT图,看整体轮廓。
- 找重点——定位云区(SAB 块 ×4)
- 接下来进入4个“空间注意力块”(SAB),
- 每个 SAB 负责识别不同层级的云分布,生成“注意力图(Attention Map)”,
- 告诉网络:“云大概在这儿,这儿需要更多关注。”
- 修细节——重建清晰背景(RB + CONV)
- 最后两个残差块负责修复被云遮住的地方,
- 输出一张干净、自然的“无云图像”。
👉 总体上就是一个**“先看全图 → 找出云 → 修复背景”**的过程。
二、核心模块①:SAB(Spatial Attentive Block)——教网络“看重点”
看图(b)。每个 SAB 模块由两个子部件组成:
- SARBs(Spatial Attentive Residual Blocks) 帮助网络根据注意力图来“修复重点区域”;
- SAM(Spatial Attentive Module) 负责生成注意力图,即告诉网络哪些地方是云、该看哪儿。
SAB 的工作机制:
输入一张特征图 → SAM 计算出“注意力图” → 这个图就像一张热力图,红的地方是“多看”,蓝的地方是“少看” → 然后 SARBs 依据这个图去重点修复红色区域(云区)。
通俗比喻:
SAB 就像给画家戴上“云检测眼镜”,让他知道该在哪些地方涂改、哪些地方保持原样。
三、核心模块②:SARB(Spatial Attentive Residual Block)——专注修补的“小工人”
看图(c)。
SARB 结构上类似普通的残差块(有卷积层、ReLU激活等),
但它多了一个“注意力引导”的输入——也就是那张 Attention Map。
- 它让残差块学会“只修复被云挡的部分”。
- 比如在注意力图红的区域,SARB会投入更多计算去还原细节; 蓝色区域(晴朗的地方)则尽量保持不变。
👉 这样模型就能做到“有选择地修补”,不破坏原本干净的地面细节。
四、核心模块③:SAM(Spatial Attentive Module)——网络的“云感知雷达”
看图(d)。这是最关键的“注意力生成器”。
- 它的输入是图像的特征图(Feature Map);
- 内部用了一个 四向循环神经网络(IRNN): 分别从上、下、左、右四个方向扫描整张图;
- 这样网络能同时“看到局部云”和“全局分布”,得到一张全面的注意力图;
- 最后输出的 Attention Map 就告诉后续模块“云在哪、该怎么修”。
通俗理解:
SAM 就像一台云检测雷达,从四个方向扫描图像,识别出“云的形状和分布”,并生成一张指导图, 帮助网络把注意力聚焦在真正需要修复的区域。
五、总结:SpA-GAN 生成器的逻辑就像人类修图过程
阶段
| 模块
| 功能
| 通俗比喻
|
① 特征提取
| CONV + RB
| 提取图像基础信息
| 看整张图,找出云的大概位置
|
② 云区识别
| SAB(含SARBs + SAM)
| 找出重点区域、生成注意力图
| 戴上“云检测眼镜”,专注修云
|
③ 背景修复
| RB + CONV
| 重建细节、恢复清晰图像
| 精细修补、上色还原
|
一句话总结: SpA-GAN 的网络结构让模型“先看全图、再聚焦重点、最后修细节”,通过注意力机制像人眼一样有选择地处理信息,这正是它能比 cGAN、CycleGAN 去云更干净、细节更自然的关键。
4、SpA-GAN 的主要不足或局限
虽然 SpA-GAN 在单时相薄云去除任务上表现出了不错的效果,但它也存在一些固有的限制和潜在缺陷。下面分几点说明:
缺陷 / 限制
| 原因 / 机制分析
| 潜在影响 /场景弱点
|
对厚云或严重遮挡区域恢复能力弱
| SpA-GAN 主要设计目标是“薄云”去除,注意力机制作用于云层可见区域,对那些被完全遮挡、地物信息消失严重的云区,单张图像内部信息不足,模型难以推断真实地物。
| 如果云层过厚、云影非常强、底层地物几乎不可见,这种场景下 SpA-GAN 的恢复可能出现模糊、假象、位移错误。
|
注意力误导 / 虚假注意力分布
| 注意力模块(SAM / SAB)会根据特征预测云区,如果预测出错(将晴区误当作云、或将云边界判断不准确),就可能导致在错误区域做修补,从而“破坏”原本干净区域。
| 会引起色彩漂移、纹理丢失、伪影、边界不连续等错误。
|
缺乏长程依赖建模
| 虽然 SAM 通过四向 IRNN 扫描上下左右,但这种方式对极远距离或非轴向的空间依赖建模仍然有限。云层与地物之间可能存在复杂的跨区域关系,这类关系未必能被仅上下左右扫描捕捉。
| 在大尺度图像,云块很大、形状复杂时,模型可能无法有效利用远处信息做一致性修复。
|
对晴区细节保持能力不足
| 在追求云区修复能力时,可能忽略了对原本无云区域的“保真性”约束,使得晴区细节有可能被过度平滑或修改。即模型可能“过度修正”无云区域。
| |
训练稳定性 / 参数敏感性
| 作为 GAN 模型,训练本身就有不稳定、模式崩溃 (mode collapse)、对抗网络不收敛等风险。加上注意力损失、多个子模块、多个损失加权,训练超参数很敏感。
| 若训练不稳定或超参数调不好,可能导致结果发散、伪影严重、注意力地图无法收敛。
|
泛化能力 / 数据集依赖弱
| SpA-GAN 在公开的 RICE 数据集上验证效果不错,但可能在其他卫星影像、不同分辨率、云类型、地物类型上泛化性不足。模型可能对训练集分布敏感。
| 在现实应用中,遇到不同光谱通道、不同传感器、不一样云状况时,效果可能退化。
|
未充分利用多源 / 多时相信息
| SpA-GAN 是单时相、单幅图像模型,设计上没有利用多时相、SAR、红外、多光谱等辅助信号。
| 多时相 / 多源数据(如前后时刻、SAR 无云图像)在云恢复任务里通常能带来更强的恢复能力,SpA-GAN 在这方面潜力未被充分挖掘。
|
这些局限性在不同论文 / 实验讨论中也被提及。比如在遥感云去除的综述或后续文章中,有指出 SpA-GAN 在极端云、泛化、对无云区域细节保护上的不足。
例如,有文献指出 SpA-GAN 在某些大型地图 / 建筑重建 /影像映射任务上,会出现“生成不合理”或“失真”的问题(如在图像映射领域的 SPA-GAN 研究)。
5、后续哪些模型基于 SpA-GAN 或在其方向上做改进 / 扩展,以及主要改进方式
近年来,在遥感图像云去除(尤其薄云去除 / 单幅方法)方向,有不少研究在注意力机制、Transformer、图像重建策略、多源融合等方面做了改进。以下是几个典型代表,以及它们是如何在 SpA-GAN 的基础上改进或借鉴其思想的。
模型 / 方法
| 改进方向 /机制
| 与 SpA-GAN 的联系 /区别
|
MLA-GAN(Multi-Head Linear Attention GAN)
| 将注意力机制升级为多头线性注意力机制,以更好地捕捉像素之间的依赖关系。arXiv
| SpA-GAN 使用的是局部 + 四向扫描生成注意力图,MLA-GAN 则尝试用更强的注意力机制捕捉更丰富的依赖。这样能帮助在云区更加精准的修复。
|
SpT-GAN(Sparse Transformer GAN)
| 在 2024 年,有文章提出用 Transformer 模块(稀疏 Transformer)替代或辅助传统卷积 + 注意力结构,以更好地建模全局关系。MDPI
| 相比 SpA-GAN 的 IRNN + 卷积注意力机制,Transformer 擅长捕捉远距离依赖,并更灵活。SpT-GAN 增加了“全局增强特征提取模块”、稀疏注意力、反残差傅里叶转换块等,尽可能在保留云区修复能力的同时,也更好保护无云区细节。
|
DC-GAN-CL(Distortion Coding GAN + Compound Loss)
| 引入 失真编码模块 (Distortion Coding Module, DCM) 和 特征重构 / 细节增强机制,以及复合损失函数(结合语义一致性、本地自适应重建等约束)MDPI
| 这个模型借鉴 SpA-GAN 的“重点区域关注 + 特征重建”思路,但更细化地把“云区失真编码”作为一个显式模块,并在损失上对语义、像素、本地自适应重构做联合约束,以缓解 SpA-GAN 在细节修复与无云区保护上的缺陷。
|
Attentive Contextual Attention (AC-Attention)
| 在 2024 年新提出,将注意力机制做得更“上下文敏感”,动态学习注意力选择权重,以滤除噪声 / 无关信息,从而减少伪影和不一致性arXiv
| 这个模块可以看作是对基于注意力方法(如 SpA-GAN)的补充:不是简单地对所有特征做加权,而是学会“选对上下文”做注意力,从而在云去除任务中减少误修、虚假细节等问题。
|
Patch-GAN Transfer Learning with Reconstructive Models
| 最近(2025 年)有研究将 重构任务 + 转移学习 的思想引入云去除,使用 MAE(Masked Autoencoder)等重构模型预训练、然后用 Patch-wise 判别器判断局部真伪。arXiv
| 这类工作借鉴了 GAN 应用于云去除的思路(SpA-GAN 属于此类),但在预训练 / 重构 / 局部判别等方面做了扩展。这样的设计有助于提升局部细节重建能力和泛化能力。
|
改进型扩散模型 / 混合模型
| 最近也有将 扩散模型(Diffusion Models, DM) 引入 cloud removal 任务,例如 EMRDM。CVF开放获取
| 虽然不直接基于 SpA-GAN,但这些方法常常作为对 GAN 方法的“下一代”替代或补充,对比中可以看出 SpA-GAN 的局限性(如模式覆盖、稳定性、生成能力)在扩散模型中被更好地处理。
|
这些工作大致遵循以下改进思路:
- 加强长程依赖 / 全局上下文能力
- 用 Transformer / 多头注意力替代或增强传统卷积 + 注意力结构。
- 引入多尺度、全局增强模块,补充 SpA-GAN 在远距离信息捕获方面的不足。
- 更灵活 / 更智能的注意力机制
- 动态注意力选择(如 AC-Attention),而不是简单按特征加权。
- 注意力正则化 / 策略约束,防止误导量化错误。
- 专门模块处理“云区失真 / 噪声”
- 如 DC-GAN-CL 的失真编码模块,把云区的扰动当成一种“可编码失真”来处理。
- 这样的模块化设计可以减缓注意力模块单独修复带来的副作用。
- 联合损失 / 多任务监督
- 加入语义一致性损失、本地适应损失、边缘 / 纹理损失等,以加强无云区细节保真。
- 辅助监督(如云掩膜、边界图)提供额外引导。
- 融合多源 / 多时相 / 多模态数据
- 虽然 SpA-GAN 本身是单幅单时相设计,但后续很多云去除模型都尝试用 SAR、红外、历史图像、时间序列图像作为辅助输入,以提供更多信息。
- 这些融合方法通常能显著改进在厚云或复杂云层场景下的恢复性能。
基于以上分析,如果要在 SpA-GAN 基础上做改进,有以下几个有希望的方向:
- 引入 Transformer / 自注意力机制 用更强的全局注意力机制补充 IRNN 扫描的局限,增强模型对远距离像素关联的理解。
- 注意力选择机制 / 注意力正则化 在注意力图生成中加入噪声滤波、上下文一致性、动态门控机制,以防止误修。比如 AC-Attention 的思路。
- 模块化处理云区扰动 像失真编码模块那样,把云层带来的扰动成分单独提取或编码,再用于修复重建,这样可以减弱“直接基于注意力修补”的风险。
- 多尺度 / 多分辨率融合 在网络中引入多尺度特征提取(如金字塔结构、空洞卷积、ASPP 等),使网络能兼顾云块大小、形态各异的场景。
- 多源 / 多模态输入 若可能的话,引入至少一个辅助通道(如历史无云图像、SAR、红外等),以便在云遮挡严重时有补充信息。
- 改进损失设计 / 多重监督 引入边缘损失、纹理损失、云边界损失、感知损失等,让模型在修复云区时,同时保持无云区的细节一致性。
- 训练稳定性增强 使用更先进的 GAN 训练技巧,如谱归一化 (spectral normalization)、渐进训练 (progressive training)、判别器正则化、对比损失等,以缓解 GAN 本身的训练不稳定问题。