DeepDA(2019):基于LSTM的多目标杂波跟踪深度数据关联网络
1、研究背景和动机
多目标跟踪(MTT)的关键挑战
- 在自动驾驶、雷达监控、机器人导航等应用中,传感器需要从大量原始测量数据中识别和追踪多个目标(如车辆、行人、无人机等)。
- 这一过程的核心难题是 数据关联(Data Association, DA):要判断每一个传感器测量值到底是属于某个已存在的目标、一个新出现的目标,还是仅仅是环境噪声(杂波)。
- 真实环境中存在三类困难:
- 杂波(clutter)和虚警:许多测量值可能是环境干扰产生的虚假目标。
- 漏检(miss-detection):传感器有时会错过真实目标的观测。
- 目标交叉和密集场景:多个目标轨迹可能交错重叠,难以区分。
传统方法的局限性
- 常见的数据关联方法如:
- 匈牙利算法 (Hungarian Algorithm, HA):将问题建模为加权二分匹配,但假设数据干净,计算复杂度较高且在杂乱场景中精度下降。
- 概率数据关联 (PDA) / 联合概率数据关联 (JPDA):通过概率权重建模测量与目标的对应关系,但需要先验信息(如杂波密度、检测概率),并且在目标多、场景复杂时会出现组合爆炸,计算量急剧上升。
- 多假设跟踪 (MHT):延迟决策以获得更准的关联结果,但实时性差。
- 总体来看,传统算法依赖复杂的数学模型和先验统计参数(如杂波密度、滤波器协方差、门控阈值等),在真实复杂环境中难以高效和准确地工作。
深度学习的引入
- 近年来,研究者开始用神经网络来解决组合优化和数据关联问题,例如用循环神经网络(RNN)或强化学习近似解决分配问题。
- 但已有方法往往存在两大限制:
- 假设环境干净,不适应杂波和漏检。
- 只满足 1-1 匹配约束,无法自然处理“目标缺失”或“虚警”情况。
研究动机
- 摆脱传统算法对先验信息的依赖 传统 JPDA、PDA 需要精确的杂波密度和检测概率等先验统计信息,而这些参数在真实环境下很难准确估计。DeepDA 希望用端到端学习的方法,让网络直接从数据中学会如何进行数据关联。
- 处理杂波和漏检的复杂场景
现实中的多目标跟踪不仅存在 1 对 1 的测量-目标匹配,还需要考虑:
- 1-0 情况(目标被漏检,测量缺失);
- 0-1 情况(杂波或虚警测量无对应目标)。 DeepDA 将传统的“纯 1-1 分配”扩展为可同时支持 1-1、1-0 和 0-1 的灵活关联形式,更贴合真实场景。
- 利用 LSTM 的时序记忆能力解决 NP 难问题 数据关联本质上是一个 NP 难的组合优化问题。LSTM 拥有强大的时序信息记忆和非线性建模能力,可以将多次扫描的测量信息串联处理,从而在复杂动态场景中学会更优的关联策略,避免组合爆炸式的枚举计算。
总结(用通俗类比)
- 传统算法就像手工比对航班和人群,需要知道所有航班时刻表(先验参数),一旦人很多、有人缺席或混入假消息,就很难快速做出正确匹配。
- DeepDA 像一个有经验的“人脸识别+跟踪系统”,它不需要提前知道人流的精确统计信息,通过学习大量真实场景,直接学会如何在混乱中判断谁是目标、谁是干扰,还能处理有人暂时没出现或冒出假消息的情况。
2、总体创新概述
创新点 1:将 1-1 分配扩展到支持 1-0 与 0-1 的灵活关联
- 传统方法局限:
大部分经典算法(如匈牙利算法、RNN-based assignment)默认每一个测量值必须与一个目标严格一一对应(1-1),无法自然处理:
- 1-0 情况:目标在某一时刻未被检测到(漏检)。
- 0-1 情况:测量值是杂波或虚警,没有对应目标。
- DeepDA 改进: 作者把数据关联问题重新形式化,将约束条件从只支持 1-1 扩展到 1-1、1-0、0-1 三种情况。 网络输出的关联概率矩阵中,专门增加一列表示“没有匹配的测量值”,从而自然表示漏检;同时网络也能判断某些测量可能是杂波。
🔍 直观理解: 传统算法像强制每个人都得配对跳舞(每个测量必须找个目标),DeepDA 允许“空舞伴”或“假人”,因此更符合现实场景。
创新点 2:把 NP 难的组合优化转化为可学习的序列到序列预测
- 背景: 多目标数据关联可以被建模为一个 多维指派问题(MDAP),其复杂度随目标和测量数量呈阶乘增长,是 NP 难问题。传统解法需要搜索、松弛、动态规划等,计算代价高。
- DeepDA 做法:
- 用 LSTM(长短期记忆网络) 处理传感器每次扫描到的测量数据,将关联过程建模为序列到序列(Seq2Seq)预测:
- 输入:每一时刻的目标预测状态与所有测量值构成的距离矩阵。
- 输出:每个目标与各测量值的关联概率分布。
- 利用 LSTM 的 记忆能力,在时间序列上捕捉目标轨迹的动态信息,逐步预测关联结果,而不是一次性穷举所有可能组合。
- 用 LSTM(长短期记忆网络) 处理传感器每次扫描到的测量数据,将关联过程建模为序列到序列(Seq2Seq)预测:
🔍 直观理解: 以前要暴力搜索所有可能的匹配组合(像全排列找最优解),DeepDA 用 LSTM 来“学会经验法则”,直接输出每个目标最可能的匹配关系,大大降低计算复杂度。
创新点 3:端到端数据驱动,不依赖先验杂波模型
- 传统方法问题:
- JPDA、PDA 等需要准确的 杂波密度、检测概率、门控阈值、滤波器协方差 等先验参数。
- 这些参数在真实复杂环境中很难获取或会随着场景变化。
- DeepDA 改进:
- 模型训练时只需要 历史的测量数据与真实目标轨迹,不需要显式提供杂波统计或噪声分布模型。
- 通过 BPTT(反向传播)+ RMSprop 优化进行监督学习,网络自动学习如何在各种噪声、虚警和漏检条件下进行最优关联。
🔍 直观理解: 以前像是做推理要知道“噪声的分布”或“杂波的概率”,DeepDA 不用提前假设这些,直接用数据学会应对各种复杂环境。
其他技术细节亮点
- 距离矩阵特征化输入: 将目标状态预测与测量值之间的欧氏距离构造成矩阵,再进行重塑与特征扩展,可直接输入到 LSTM 中,灵活支持其他外观或相似度特征。
- Softmax 概率输出: 对每个目标输出一个长度为 (M+1) 的概率向量,前 M 个维度对应各个测量值,最后一个维度对应“未检测/杂波”。
- 高效训练与实时性: 实验表明 DeepDA 在训练后推理时计算耗时极低(平均仅 0.011 秒),比 JPDA 和 HA 在高杂波条件下快得多。
DeepDA 的核心创新在于:用 LSTM 序列到序列学习,将复杂的 NP 难数据关联问题转化为端到端概率预测,并扩展支持 1-1、1-0、0-1 匹配,无需先验杂波模型,在复杂多目标跟踪场景中实现更鲁棒、更高效的实时数据关联
3、DeepDA 模型的整体结构与工作流程
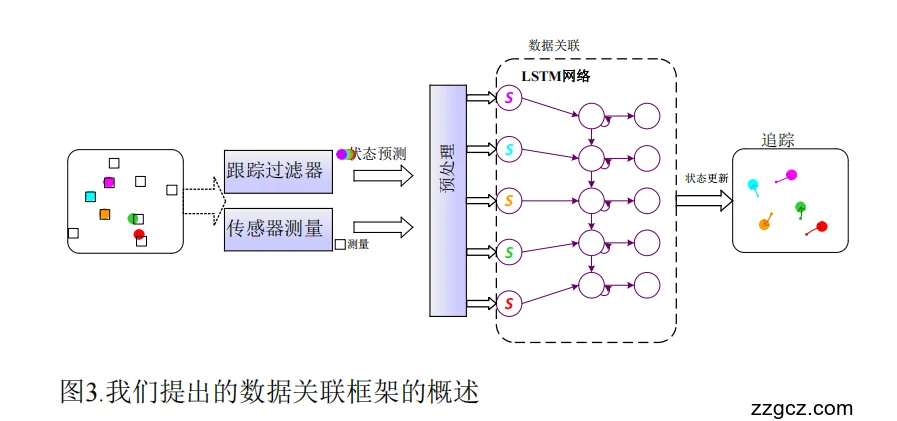
整体视角
- 前端感知与预测(左边)
- 输入特征构建(中间灰色“预处理”区域)
- LSTM 数据关联网络(右边虚线框内)
- 轨迹更新(最右侧)
各部分详细解释
(1) 跟踪滤波器 + 传感器测量
- 左边方框表示传感器检测到的目标点(彩色小点)和周围的背景杂波(灰色方块)。
- 跟踪滤波器(如卡尔曼滤波)会根据上一次的目标状态预测当前时刻目标可能的位置。
- 图中彩色圆圈就是预测的目标状态。
- 传感器测量量就是实际观测到的点,可能有真实目标,也可能有噪声或虚警。
🔍 类比: 你上一秒看到几个人(目标),大概知道他们往哪个方向走(状态预测);现在相机拍下来的所有点里,有真有人,也有误报。
(2) 预处理:生成“配对成本”特征
- 这一部分负责把“预测的目标状态”和“当前测量”进行两两比较,计算距离或相似度。
- 结果是一个 距离矩阵,描述每个预测目标与每个测量值之间的匹配成本。
- 这里还会扩展一个“没有匹配的测量”列,表示漏检或杂波的可能性。
🔍 类比: 把所有“预测的目标”排在一边,“实际检测到的点”排在另一边,做一张表格写下每对的匹配难易度。
(3) LSTM 网络 —— DeepDA 的核心
- 图中虚线框表示一个 多层 LSTM 网络,每一行对应一个预测目标。
- 输入:每个目标对应的特征序列(它与每个测量点的距离、历史轨迹信息等)。
- LSTM 的作用:
- 记住目标之前的运动轨迹和匹配历史;
- 学习在复杂背景(杂波、漏检)下,如何从多个测量值中挑选最合适的一个;
- 不用暴力搜索所有组合,而是“经验化”地给出概率预测。
- 输出:每个目标的匹配概率分布(Softmax)。
- 每一行是一个目标,列是所有测量值 + 一个“未匹配”选项。
🔍 类比: LSTM 像一个有记忆的“匹配专家”,它看着每个目标之前怎么移动、现在距离谁最近,给出“这个目标最可能匹配哪个测量点”的概率表。
(4) 状态更新与轨迹维护
- 最右边的“追踪”部分表示,当概率矩阵生成后:
- 为每个目标选择最可能的测量值来更新其位置和速度;
- 如果有目标没有匹配到测量值,认为它暂时被漏检但仍保留轨迹;
- 如果有测量值没有匹配到现有目标,可能初始化一个新的目标轨迹。
- 这样就实现了多目标轨迹的持续更新。
🔍 类比: 系统看完概率表后决定:谁和谁是一对儿(目标和观测),没匹配到的目标就先等一等,新冒出来的点可能新建一个目标。
模型特点(从结构上看)
- 端到端学习 不需要人工设置杂波概率、检测率等参数;输入距离矩阵,输出直接是匹配概率。
- 时序记忆 LSTM 能理解目标的轨迹连续性,不是单帧决策,鲁棒性更强。
- 灵活匹配 输出矩阵支持 1-1、1-0(漏检)、0-1(虚警),比传统方法更贴近实际。
- 计算高效 训练好之后,推理阶段只需一次前向传播,速度比 JPDA、匈牙利算法更快。
一句话通俗总结
这张图可以理解为: 传感器和滤波器先给出“目标预测”和“实际检测点”,预处理模块算出它们的距离表,再交给一个会记忆轨迹的 LSTM 网络去学习如何匹配,并输出每个目标和测量点的匹配概率;最后根据概率更新轨迹,新增目标或处理丢失目标。 它就像一个学会经验的“自动分配员”,在嘈杂环境中帮我们自动判断谁是谁。
4、DeepDA 模型的核心不足与局限
1. 对训练数据依赖较强,泛化性受限
- 问题:DeepDA 完全依赖数据驱动,需要大量带真实标签的轨迹和测量数据来训练。如果训练数据的场景与真实环境差异较大(如杂波密度、目标运动模式、传感器噪声特性不同),模型可能失效。
- 原因:LSTM 学到的是“经验”,并没有物理解释或显式概率模型。面对从未见过的极端场景(如超高目标密度或新型传感器特性),鲁棒性可能下降。
- 对比:传统 JPDA、PDA 有明确的概率建模,虽然需要参数,但在场景变化时可通过调参适应。
🔍 通俗理解:就像一个只在熟悉的机场学会找朋友的“导游”,如果换到一个全新的车站,他可能会迷路。
目标数量变化和大规模场景下计算挑战
- 问题:DeepDA 的输入是目标与测量的距离矩阵,大小是 N×(M+1)N \times (M+1)N×(M+1)。当目标或测量数量很多时,矩阵会急剧膨胀,LSTM 的计算和内存需求上升。
- 现象:虽然比组合搜索快,但在数百甚至上千目标的大规模场景中,仍可能遇到效率瓶颈。
- 对比:某些传统方法(如门控+匈牙利算法)在简单场景下计算开销更可控。
🔍 通俗理解:一开始只要在小人群中找朋友很快,但如果是几千人规模的演唱会,LSTM 的工作量也会变大。
缺少显式的不确定性建模
- 问题:DeepDA 用 Softmax 给出匹配概率,但没有显式考虑传感器噪声、目标检测置信度等统计不确定性。
- 影响:如果观测噪声较大或目标状态预测误差很大,概率输出可能过于自信或误导后续轨迹更新。
- 对比:PDA/JPDA 等方法会显式利用检测概率、噪声协方差,对异常情况更稳健。
🔍 通俗理解:DeepDA 只是学会“经验概率”,但不知道自己何时不确定;有时会错误地非常“自信”地匹配错对象。
缺乏物理可解释性与调试难度大
- 问题:网络是黑箱,虽然能输出匹配概率,但难以解释其决策依据。调试和验证困难,尤其在安全关键的应用(如自动驾驶)中不利。
- 对比:基于概率图模型的方法可明确分析失败原因(如门控条件、先验参数设定问题),调试更方便。
🔍 通俗理解:DeepDA 就像一个经验丰富但“不解释为什么”的专家,出错时很难知道原因在哪。
对实时变化场景的自适应能力有限
- 问题:训练好的模型参数在部署后是固定的,当杂波密度、检测概率或传感器性能实时变化时,模型无法快速自适应,需重新训练或微调。
- 对比:传统方法通过在线估计参数(如检测概率)可一定程度上适应场景变化。
🔍 通俗理解:DeepDA 像一个只学过一门课的司机,路线变化后需要重新上课才能开。
目标外观信息未充分利用
- 问题:DeepDA 主要依赖几何距离(位置关系),对目标的视觉/外观特征利用有限。
- 影响:在目标密集且相互交叉的场景(如车辆或行人密集区域),仅靠位置距离可能难以区分相似轨迹。
- 改进方向:可将视觉特征或外观嵌入结合进输入,提升分辨能力。
5、后续改进方向
论文 / 方法
| 主要改进 / 技术思路
| 适用场景 /优点
| 局限或挑战
|
Modular Multi Target Tracking Using LSTM Networks (Verma et al., 2020) (arXiv)
| 将关联 (association)、预测 (prediction)、滤波 (filter/update) 拆分为模块,用不同的 LSTM(或 Bi-LSTM)处理
| 较好的模块化设计、可解释性更强
| 各模块间误差传递、整体联合优化困难,对极端场景适应性待提升
|
DeepAF: Transformer-Based Deep Data Association and Track Filtering (最近) (MDPI)
| 用 Transformer 替代 LSTM,融合关联与轨迹滤波功能,实现端到端 “Data Association + Track Filtering”
| 在雷达多目标跟踪任务中位置估计精度更高,且速度更快 (MDPI)
| 在大目标数量、强干扰环境下 Transformer 计算开销高;训练数据需求大
|
Online Multi-Target Intelligent Tracking (MTIT-DLSTM) (2023) (科学直通车)
| 把预测/更新也通过 DLSTM 网络建模,结合匈牙利算法做关联;更“模型自由”
| 在复杂跟踪场景中,对状态噪声与目标运动特性具备更强的适应性 (科学直通车)
| 仍依赖匈牙利算法做最终关联;网络设计对于目标数量、噪声幅度变化仍敏感
|
Transformer Based Multi-Target Bernoulli Tracking (Maritime Radar, 2025) (arXiv)
| 在海面雷达中结合 Transformer 做目标检测 + 使用 LMB(Labeled Multi-Bernoulli)滤波器做轨迹跟踪
| 针对海杂波、雷达虚警率高环境有更好表现 (arXiv)
| 目前只在海面 / 较专门场景验证;Transformer 计算开销是瓶颈
|
SIRA: Scalable Inter-frame Relation and Association for Radar Perception (2024) (arXiv)
| 结合多帧间关系(用类似 Transformer 的时间窗口注意力机制) + 伪轨迹一致性跟踪
| 在雷达环境(低空间分辨、杂波强)下提升跨帧关联性能
| 计算复杂度、对历史帧长期依赖的稳定性是挑战
|
MeMOTR: Long-Term Memory-Augmented Transformer for MOT (2023) (arXiv)
| 用 Transformer 加 长期记忆模块(memory-attention)增强跨帧关联能力
| 在视频 MOT 任务中表现优异,关联稳定性好
| 主要在视觉 MOT 上验证,对雷达多目标追踪还需移植和适配
|
基于 Transformer 的雷达追踪模型(2023) (科学直通车)
| 将 Transformer 架构引入雷达目标跟踪,用 attention 机制建模测量-轨迹间交互
| 初步验证 Transformer 在雷达跟踪中的可行性
| 应用场景偏窄,尚未大规模实证
|
5.1 从 LSTM 到 Transformer / 自注意力结构
- 例子:最近有工作提出 DeepAF(Deep Association & Filtering),采用 Transformer 架构,同时融合数据关联(data association)与轨迹滤波(track filtering)功能。相比 LSTM-based 的方法,DeepAF 在目标位置估计上精度更高,且计算效率更佳。MDPI
- 优势预期:
- 能更好地建模目标间的交互(谁更可能与谁匹配);
- 支持并行计算,加速推理;
- 能跨帧自适应注意力模式,对长时上下文做更灵活的匹配。
5.2 多雷达 / 传感器融合 + 跨模态特征融合
- 参考:有些最新方法融合 mmWave 雷达和相机,用 Bi-LSTM 结合视觉外观特征(emphasis on appearance embedding)来建立跨帧关联。arXiv+1
- 在多雷达场景中,可以构建跨雷达测量对齐、时间基准同步、视角对齐误差补偿等模块,使得不同雷达的测量能够更直接地被输入统一的关联网络。
- 特征融合可以引入:雷达反射强度谱、回波形状特征、时间频域特征、目标微多普勒特征、外观相机贴片特征等。
5.3 联合关联+滤波 / 端到端轨迹估计
- DeepAF 就是朝这个方向尝试:将 关联模块 + 滤波模块 集成在一个网络里,使网络能够在同一架构下同时判断匹配与估计目标状态。MDPI
- 另一个例子是 Modular Multi Target Tracking using LSTM,将关联、预测和滤波模块拆分但能联合训练或协作。arXiv
- 未来可进一步扩展:把轨迹出生/消亡(track initiation / termination)也纳入网络,让整个 MTT 流水线端到端可学习。
5.4 不确定性建模与概率输出增强
- 引入 贝叶斯神经网络(Bayesian Neural Networks) 或 深度生成模型(如变分自编码器 VAEs, 正态化流)来对关联概率的置信度建模;
- 用 概率图网络 / 图神经网络 + 潜变量模型,使得匹配决策可以附带不确定度(置信区间、分布);
- 在损失函数中引入不确定性正则化、对抗性训练等,使模型在高噪声条件下更加保守或稳健。
5.5 自适应在线学习与模型自更新
- 在线微调(fine-tune):在运行过程中,让模型接收带标签的小批量数据或人工校正结果进行微调;
- 增量学习或持续学习:使模型能不断从新数据中更新,而不遗忘旧知识;
- 自监督 / 无监督辅助损失:在没有标签的情况下,用轨迹一致性、轨迹平滑性、前向/后向预测误差等信号给模型提供反馈,作为辅助训练。
5.6 处理极端情况与稀疏目标场景
- 作针对性增强方法(数据增强、难例采样)让模型见识极端场景;
- 多级关联策略:在稀疏场景可用简化匹配,在密集场景启用精细模型或局部子模块;
- 合并启发式算法与深度学习方法(hybrid 方法),在极端边界情况下 fallback 回传统方法。
5.7 计算效率与资源优化
- 轻量级模型设计:压缩模型、剪枝、知识蒸馏、量化等;
- 局部注意力 / 局部子网结构:只对某些可能关联区域做深度计算;
- 异步处理 / 分层推理:对低速目标使用低频更新,对高速目标用高频网络。
5.8 跨域与迁移学习
- 迁移学习 / 少样本学习:让模型能快速适应新环境;
- 域自适应 / 域对抗训练:使模型在不同雷达 / 不同噪声条件下具有鲁棒性;
- 模型组合策略:在多个子模型中自适应选择最适合当前环境的子模型。