Transformer-DA(2022):基于Transformer网络的机载雷达多目标跟踪方法
1、研究背景和动机
1.1、研究背景
- 当目标数量较少、环境简单时,传统算法(如 匈牙利算法、JPDA)还能工作。
- 但在实际空中场景中,杂波密集、检测概率不稳定、目标机动多变且数量未知,传统算法容易出现计算复杂度高、关联错误率高的问题
- 基于极大似然的算法(如 HA):需要穷举匹配组合,容易在目标交叉或杂波多时失效,且复杂度随目标数快速上升。
- 贝叶斯类算法(MHT/JPDA):虽然能处理一定的不确定性,但需要假设先验(如目标运动模型、杂波密度),在真实任务中很难准确获取;此外,组合爆炸导致计算量巨大
- 基于深度学习的早期尝试(如 LSTM/Bi-LSTM/DeepDA):能够自动学习部分运动特征并做关联,比传统方法更鲁棒,但仍有明显限制:
- 需要假设检测概率较高、漏检少;
- 处理多量测、虚警的能力不足;
- 序列建模受 LSTM 结构限制,难以捕获长时间依赖和全局特征
是否可以用 Transformer 替代 RNN/LSTM 来建模目标运动与量测之间的复杂关系,从而实现更精准、更鲁棒的数据关联?
1.2、研究动机
- 摆脱对先验信息的依赖 传统 JPDA/MHT 在应用前需要准确的目标运动模型、杂波密度等先验参数,但在实际机载雷达任务中,这些信息往往难以及时、准确地获得。Transformer-DA 希望通过端到端训练,直接从数据中学习目标与量测的关联模式,无需人工设定先验
- 更好地处理漏检和虚警 真实雷达经常出现检测不到目标(漏检)或检测到杂波(虚警)的情况。为此,Transformer-DA 引入 虚拟量测 (virtual measurement) 的概念,将漏检情形显式纳入关联模型,使网络在训练和推理时都能自然处理这些异常
- 缓解类别不平衡与复杂关联带来的训练困难 多目标跟踪中,真实匹配样本稀少,杂波样本数量庞大,导致训练偏向于“预测杂波”。为此,Transformer-DA 设计了 MCD(掩蔽交叉熵 + Dice)损失函数,在损失层面让模型更加关注真实的目标匹配,从而提升对真实轨迹的学习效果
简单总结(通俗解释)
以前的算法像是要先写好一堆规则:目标怎么飞、环境多吵杂,然后再去做数学推理。而 DeepDA 开始尝试用神经网络学习这些规则,但它像记忆力有限的学生——只能看见短期的信息,对漏检和杂波处理得不好。 这篇工作用 Transformer,就像换了一个有“全局视野”的大脑,可以同时看到所有历史状态和当前所有量测;再加上“虚拟量测”去处理漏检,和特别设计的损失函数来关注真实匹配,使得在复杂的雷达场景中也能更好地完成多目标跟踪。
2、总体创新概述
用 Transformer 网络替代传统 LSTM/概率模型来做雷达多目标数据关联,并在网络设计上针对雷达场景中最关键的问题——杂波、漏检、数据不平衡——进行了系统性改进,使得模型能端到端学习复杂的目标-量测匹配关系。
创新点 1:引入 Transformer 自注意力机制进行全局数据关联
- 问题:LSTM 只能顺序地处理历史信息,长时间依赖衰减严重;目标数量多、交叉频繁时难以捕获全局关系。
- 改进:模型采用 Transformer 编码器,用 自注意力 (Self-Attention) 同时分析所有目标历史状态与当前量测之间的关系。
- 可以一次性考虑目标间、测量点间的全局交互,尤其在目标接近或轨迹交叉时保持高关联精度。
- 注意力机制可自动聚焦与每个目标最相关的量测,而不必穷举组合。
🔍 直观理解: 以前的 LSTM 像一个按顺序读历史的“记事本”,而 Transformer 像一个可以同时看全局的“指挥官”,能并行关注所有目标和测量之间的关系。
创新点 2:显式建模漏检与杂波 —— 引入虚拟量测 (Virtual Measurement)
- 问题:实际雷达常有漏检(目标没被检测到)和杂波(检测到的点无对应目标),传统一一匹配模型处理困难。
- 改进:在输入关联矩阵时,专门加入一类“虚拟量测”,表示目标可以没有对应量测。
- 这样网络训练时就能学习到 1-0(目标无匹配) 和 0-1(杂波) 的真实场景。
- 推理时也能自然输出“这个目标当前没有检测到”的判断。
🔍 直观理解: 以前匹配必须“强行配对”,现在允许目标“暂时没舞伴”或量测是“路人甲”,更符合雷达实际工作情况。
创新点 3:设计专门适合数据不平衡的损失函数(MCD Loss)
- 问题:在多目标跟踪中,真实匹配样本稀少,而虚警/杂波样本大量存在,导致网络训练时容易偏向预测“没有匹配”,从而关联性能下降。
- 改进:提出 MCD(Mask Cross Entropy + Dice)损失:
- 掩蔽交叉熵:忽略无效位置,避免噪声对训练的干扰;
- Dice 系数:平衡类别不均衡,让网络更关注真实目标匹配。
- 结合两者,增强模型在杂波密集和真实目标稀疏时的学习能力。
🔍 直观理解: 像考试时给对的题更高权重,忽略那些根本不该算分的“干扰题”,让网络把精力放在关键的匹配上。
创新点 4:端到端训练,弱化对先验参数依赖
- 问题:传统 JPDA、MHT 必须提前知道杂波密度、检测概率、门控阈值等;LSTM 方法也常需要手动构造特征。
- 改进:Transformer-DA 直接用 预测目标状态 + 量测特征(位置、速度等)构造输入序列,网络端到端学习关联策略。
- 不再需要人工建模杂波统计或调节检测概率参数;
- 对传感器变化或环境不确定性更有适应性。
🔍 直观理解: 不用先做复杂的数学假设,网络直接通过数据自己学会“怎么在乱糟糟的雷达回波里找出正确匹配”。
辅助设计亮点
- 输入特征扩展:不只用欧氏距离,还可以融合雷达的速度、多普勒信息等特征,让网络获得更丰富的匹配线索。
- Transformer 多头注意力 (Multi-Head Attention):能从不同角度(位置差、速度差、历史轨迹)分别学习匹配关系,再综合判断。
- 高效推理:虽然 Transformer 理论上复杂度较高,但通过掩蔽无效量测和稀疏化注意力,可在机载实时任务中保持较高速度。
与 DeepDA 的对比
对比点
| DeepDA (LSTM)
| 本文 Transformer-DA
|
序列建模
| LSTM,长时间依赖有限
| Transformer,全局注意力
|
漏检/虚警
| 支持但不显式建模
| 显式虚拟量测,更自然鲁棒
|
损失函数
| 普通交叉熵
| MCD Loss,解决样本不平衡
|
先验依赖
| 仍需一定假设
| 端到端弱化先验依赖
|
场景适应
| 较受限
| 更灵活,适合复杂雷达场景
|
Transformer-DA 的核心创新在于: 用 Transformer 自注意力 替代 LSTM 来进行全局数据关联,显式建模漏检/虚警,并通过 MCD 损失解决类别不平衡,实现了一个端到端、少依赖先验、在杂波和复杂机动条件下仍鲁棒的多目标雷达跟踪方法。
3、模型结构与工作流程
- 历史轨迹编码(上半部分)
- 当前量测编码(下半部分)
- Transformer-DA 解码与关联概率输出
- 轨迹状态更新(卡尔曼滤波器)
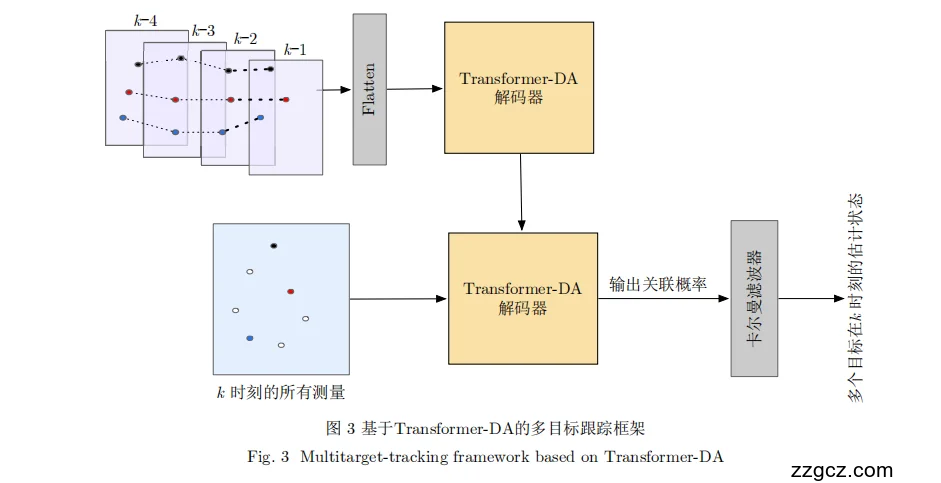
(1) 历史轨迹输入与编码 —— 利用时序信息
- 图中左上角展示了过去连续 k−4,k−3,k−2,k−1k-4, k-3, k-2, k-1k−4,k−3,k−2,k−1 帧的目标状态。
- 每个小圆点代表某一时刻的目标位置或状态(可以包含位置、速度、多普勒等)。
- 这些历史状态首先被 展开 (Flatten):把过去每帧中所有目标的状态信息按序列拼接成一个向量序列,作为 Transformer 的输入。
- 目的:为后续关联提供目标的运动轨迹上下文,帮助模型理解目标的动态趋势。
🔍 直观理解: 就像把过去几秒钟飞机的飞行轨迹记录打包给模型,让它“先复习一下”每个目标的运动习惯。
(2) 当前时刻的量测输入与编码 —— 捕捉实时观测
- 左下角的方框是当前时刻 kkk 雷达检测到的所有量测点(黑点、红点、白点表示不同状态:真实目标、可能虚警、未确定)。
- 这些量测数据(位置、速度、雷达反射特征等)会被送入下方的 Transformer-DA 解码器进行处理。
- 目的:提取当前帧中每个量测的关键特征,为与历史目标进行匹配做准备。
🔍 直观理解: 这是“实时拍的照片”,模型要把当前观测的信息和历史轨迹结合起来推理匹配关系。
(3) Transformer-DA 解码与数据关联概率输出 —— 核心模块
3.1 上方 Transformer-DA —— 历史轨迹特征提取器
- 接收 Flatten 后的历史轨迹序列,用 多头自注意力 (Multi-Head Self-Attention) 学习:
- 目标之间的交互关系(如轨迹交叉、相对速度变化);
- 每个目标历史状态的长时依赖。
- 输出一组富含运动模式和目标间关系的 编码特征向量。
3.2 下方 Transformer-DA —— 数据关联解码器
- 接收两部分信息:
- 当前量测的特征;
- 上方输出的历史轨迹编码结果。
- 通过 解码器的交叉注意力 (Cross-Attention):
- 将当前量测与历史目标状态一一对比;
- 计算匹配强度,同时考虑漏检和杂波(这里显式包含“虚拟量测”作为额外一类输出)。
- 最终输出 关联概率矩阵:
- 行对应历史目标;
- 列对应当前量测 + 一列“未匹配/虚拟量测”选项。
🔍 直观理解: 上半部分是“复习历史”,下半部分是“对比当前观测”,解码器就像一个能看全局的调度员,决定每个旧目标和当前量测的匹配概率。
(4) 状态更新与轨迹维护
- 输出的 关联概率矩阵 会传入 卡尔曼滤波器:
- 概率最高的匹配被用于更新目标状态(位置、速度等);
- 没有匹配到的目标会暂时保留并继续预测;
- 没有被匹配的量测点可能被初始化为新的目标轨迹。
- 卡尔曼滤波器在这里提供稳定的状态估计和噪声抑制,使得整个系统具备 实时性与稳健性。
🔍 直观理解: 最终的更新像一个“航迹管控员”,根据 Transformer 的匹配建议更新每个目标的最新位置,如果出现新点则创建新航迹。
工作流程总结
- 轨迹预测:先收集过去几帧的目标状态,预测其当前位置。
- 特征编码:历史轨迹由上方 Transformer 编码,当前量测由下方 Transformer 处理。
- 自注意力匹配:解码器用注意力机制计算每个历史目标和每个量测的匹配概率,并允许虚拟匹配处理漏检/杂波。
- 卡尔曼更新:根据概率结果更新各目标状态,并维护轨迹生命周期。
与 DeepDA 的区别(结构上)
对比点
| DeepDA
| Transformer-DA
|
序列特征
| LSTM 单向序列
| Transformer 全局自注意力
|
输入组织
| 逐帧距离矩阵
| 历史轨迹序列 + 当前量测联合编码
|
漏检处理
| Softmax 最后一列
| 显式虚拟量测
|
输出
| 关联概率矩阵
| 关联概率矩阵(结合虚拟量测 + MCD Loss)
|
状态更新
| 卡尔曼
| 卡尔曼(类似,但数据输入更鲁棒)
|
4、模型的核心不足与局限
- 对训练数据依赖强,泛化能力有限
- 原因:Transformer-DA 完全依赖端到端监督训练,模型效果依赖大量高质量的带标签数据。
- 问题:机载雷达场景差异很大(平台高度、姿态变化、杂波类型、信噪比、天气等),一旦部署环境和训练环境差别较大,模型性能可能明显下降。
- 对比:传统 JPDA/MHT 有显式统计模型,只需调整参数即可适应新场景;而 Transformer-DA 需要重新训练或微调。
🔍 通俗理解:就像一个在晴天机场学会引导飞机的工作人员,如果被派到暴风雪的军用机场可能就不适应了。
- 计算与存储开销较大,实时性受限
- 原因:Transformer 的自注意力计算复杂度是 O(n2)O(n^2)O(n2),当历史轨迹长度大、目标/量测数量多时计算开销显著增加。
- 影响:在机载实时任务中,目标数和帧率可能较高,模型推理速度和内存消耗都可能成为瓶颈。
- 对比:DeepDA(LSTM) 的复杂度较低,虽然信息表达不如 Transformer 全局,但在低算力平台上更易部署。
🔍 通俗理解:Transformer-DA 很聪明,但也很“费脑子”,在目标多、更新快的场景下可能算不过来。
- 缺少显式的不确定性建模,置信度难解释
- 原因:模型虽然输出关联概率,但这些概率是神经网络学习的“经验值”,并没有严格的概率统计基础。
- 影响:当观测噪声大或目标机动剧烈时,输出的概率可能过于自信或不稳定;安全关键领域难以直接使用。
- 对比:JPDA/MHT 在概率推断上有数学解释,可以提供明确的置信度和可解释性。
🔍 通俗理解:模型会“拍胸脯”告诉你匹配很确定,但其实有时候它的置信度并不可靠。
- 对动态环境和在线适应性差
- 原因:模型在训练后参数固定,无法实时适应杂波密度、检测概率、传感器工作状态等变化。
- 影响:需要频繁重新训练才能适应新环境,缺乏在线增量学习能力。
- 对比:一些概率图模型可在跟踪过程中动态估计检测率、杂波参数,适应环境变化。
🔍 通俗理解:像一个死记硬背的飞行管控员,环境变化后不会自己调整,需要重新培训。
- 对极端稀疏 / 密集目标场景支持不足
- 原因:Transformer-DA 假设目标与量测数量在合理范围内。当目标非常密集或雷达只检测到极少点时,匹配矩阵会非常稀疏或过于庞大,导致模型预测不稳定。
- 影响:在高动态空战场景或海量杂波背景中,可能出现轨迹漂移或漏检严重。
- 外观/多模态信息融合有限
- 原因:当前方法主要使用几何/运动特征(位置、速度、多普勒),对视觉特征、信号微结构等外观信息利用不足。
- 影响:当目标轨迹交叉且运动模式相似时,模型区分不同目标的能力减弱。
- 改进方向:可引入视觉相机、毫米波点云等多模态特征。
- 工程部署难度较高
- 原因:需要大量标注、模型较重、缺少解释性;在航空、军事等关键场景中验证和认证周期长。
- 影响:虽然性能优越,但短期内难以完全替代成熟的概率跟踪算法。
5、后续改进方向
5.1 提升模型泛化能力 —— 迁移学习与域自适应
- 问题:当前模型对训练数据依赖强,在平台、雷达工作模式或杂波条件变化时易退化。
- 改进思路:
- 域自适应 (Domain Adaptation):通过对抗训练、特征对齐,使模型在不同场景下保持一致表示。
- 迁移学习 / 少样本学习:在已有模型上快速适应新环境,减少重新标注和大规模训练的成本。
- 数据增强:构造模拟杂波、机动轨迹、不同信噪比的虚拟数据,增强模型鲁棒性。
5.2 提高实时性与可扩展性 —— 轻量化与高效注意力机制
- 问题:Transformer 在多目标、大量量测时计算开销高,不易在机载实时平台上部署。
- 改进思路:
- 轻量化 Transformer:模型剪枝、量化、蒸馏等方式减少参数量。
- 稀疏/局部注意力:限制注意力计算在时空邻域内,降低 O(n2)O(n^2)O(n2) 的复杂度。
- 分层结构:先粗匹配,再局部精细化关联;或动态选择计算资源用于关键目标。
5.3 增强不确定性建模与可解释性
- 问题:当前输出概率缺乏统计意义,置信度难以解释。
- 改进思路:
- 贝叶斯 Transformer 或 概率注意力:输出匹配分布和不确定性区间,提升置信度可用性。
- 可解释性模块:用注意力可视化或轨迹回溯分析解释关联决策。
- 混合模型:结合概率图模型(如 JPDA)提供理论解释,与深度网络互补。
5.4 在线增量学习与自适应更新
- 问题:训练后模型参数固定,无法适应实时变化的杂波、检测概率。
- 改进思路:
- 在线微调 (Online Fine-tuning):用最近几帧数据或人工校正结果更新模型。
- 持续学习 (Continual Learning):避免灾难性遗忘的增量更新方法。
- 自监督辅助损失:利用轨迹平滑性、前后向一致性等无标签信号做在线优化。
5.5 引入多模态信息融合
- 问题:当前模型主要基于几何与运动特征,缺少外观/信号层信息。
- 改进思路:
- 融合 视觉信息(红外/可见光图像)、毫米波点云或雷达回波微多普勒特征。
- 利用跨模态 Transformer,将不同传感器信息统一到一个特征空间,提升交叉和拥挤场景下的区分度。
- 实现 雷达-相机/激光雷达协同跟踪,提高定位与识别精度。
5.6 面向极端场景的鲁棒增强
- 问题:在目标极稀疏或极密集、强干扰背景下性能下降。
- 改进思路:
- 多级关联策略:先在全局上做粗筛选,再局部高精度匹配。
- 难例挖掘与对抗训练:让模型在训练中重点适应极端条件。
- 动态目标管理:在极端密集场景中做轨迹聚合或分裂管理,减轻模型压力。
5.7 与滤波/状态估计深度融合
- 问题:目前状态更新仍依赖传统卡尔曼滤波,与深度关联网络是解耦的。
- 改进思路:
- 开发 端到端的“关联 + 状态预测/更新”一体化模型,让网络同时学习数据关联和轨迹动态。
- 借鉴 DeepAF、Graph Neural Network + Kalman Hybrid 等设计,把滤波器内嵌到深度结构中,使误差传播更平滑。