GPU 推理优化¶
GPU 是机器学习硬件的标准选择,与 CPU 相比,它们在内存带宽和并行性方面进行了优化。为了在现有或较旧的硬件上处理现代模型的更大规模,或加速大型模型的推理,可以使用多种优化方法。在本指南中,您将学习如何使用 FlashAttention-2(更高效的注意力机制)、BetterTransformer(PyTorch 本地快速执行路径)和 bitsandbytes 来量化模型以降低精度。最后,您将学习如何使用 🤗 Optimum 在 Nvidia 和 AMD GPU 上通过 ONNX Runtime 加速推理。
大多数优化方法也适用于多 GPU 配置!
FlashAttention-2¶
FlashAttention-2 是一种实验性的、更快、更高效的注意力机制实现,它可以通过以下方式显著加速推理:
- 在序列长度上并行计算注意力。
- 在 GPU 线程之间分配工作,减少线程之间的通信和共享内存的读写。
FlashAttention-2 当前支持以下架构:
- Bark
- Bart
- Chameleon
- CLIP
- Cohere
- GLM
- Dbrx
- DistilBert
- Gemma
- Gemma2
- GPT2
- GPTBigCode
- GPTNeo
- GPTNeoX
- GPT-J
- Falcon
- Llama
- Llava
- 和更多...
您可以在 GitHub 上请求支持其他模型。
在开始之前,请确保已安装 FlashAttention-2:
pip install flash-attn --no-build-isolation
要启用 FlashAttention-2,请在加载模型时传递参数 attn_implementation="flash_attention_2":
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "tiiuae/falcon-7b"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
FlashAttention-2 只能在模型的 fp16 或 bf16 精度下使用。确保在使用 FlashAttention-2 之前将模型转换为合适的精度并加载到支持的设备上。
您可以结合其他优化技术(如量化)进一步加速推理:
# 8-bit 量化
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
attn_implementation="flash_attention_2",
)
# 4-bit 量化
model = AutoModelForCausalLM.from_pretrained(
model_id,
load_in_4bit=True,
attn_implementation="flash_attention_2",
)
期望的加速效果¶
对于较长的序列,FlashAttention-2 可以显著加速推理。但是,FlashAttention-2 不支持带有填充标记的注意力分数计算,因此在批量推理时需要手动填充/去填充注意力分数,这会导致显著的减速。为了克服这一点,应该在训练期间避免填充标记(例如通过打包数据集或连接序列直到达到最大序列长度)。
对于无填充标记的序列,单次前向传递的加速效果如下图所示:
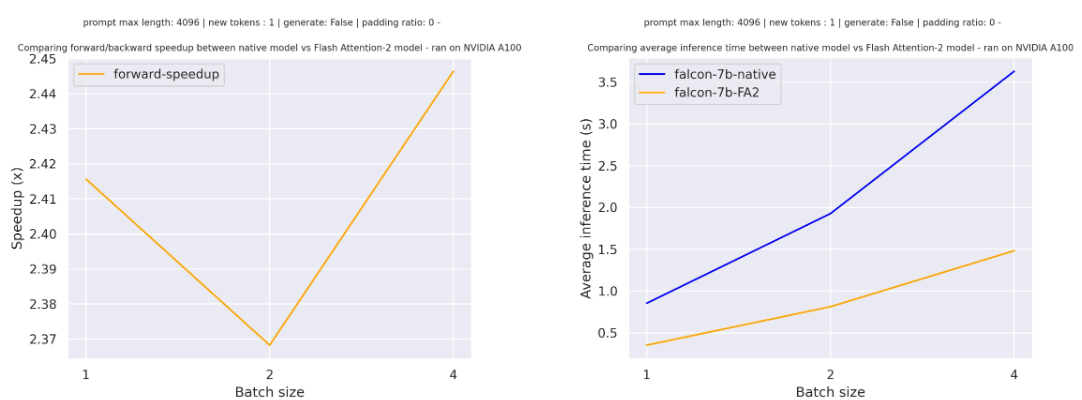
对于带有填充标记的序列,加速效果会有所不同:

FlashAttention 更加节省内存,意味着您可以训练更长的序列而不出现内存不足的问题。对于更长的序列,内存使用量最多可减少 20 倍。更多详细信息请参阅 flash-attention 仓库。
PyTorch 缩放点积注意力¶
PyTorch 的 torch.nn.functional.scaled_dot_product_attention (SDPA) 可以调用 FlashAttention 和高效的注意力内核。SDPA 支持正在加入 Transformers,并在 torch>=2.1.1 中默认使用。您也可以在加载模型时显式设置 attn_implementation="sdpa"。
SDPA 支持的架构包括:
- Albert
- Audio Spectrogram Transformer
- Bart
- Bert
- BioGpt
- CamemBERT
- CLIP
- GLM
- Cohere
- data2vec_audio
- 和更多...
FlashAttention 只能用于 fp16 或 bf16 精度的模型。SDPA 不支持某些注意力参数,如 head_mask 和 output_attentions=True。在这种情况下,您会看到警告信息,并会回退到较慢的 eager 实现。
默认情况下,SDPA 会选择最高效的内核,但您可以使用 torch.backends.cuda.sdp_kernel 来检查特定设置(硬件、问题大小)下是否可用某个内核:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype=torch.float16).to("cuda")
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
如果您遇到错误,可以尝试使用 PyTorch 的 nightly 版本,以获取更广泛的 FlashAttention 支持。
BetterTransformer¶
BetterTransformer 是一种优化技术,通过 PyTorch 本地实现的快速执行路径(fastpath)加速推理。快速执行路径的两个优化点是:
- 融合(fusion),将多个连续的操作合并为一个“内核”以减少计算步骤。
- 跳过填充标记的固有稀疏性,以避免不必要的计算。
BetterTransformer 还将所有注意力操作转换为更节省内存的缩放点积注意力(SDPA),并在后台调用优化内核(如 FlashAttention)。
在使用 BetterTransformer 之前,请确保已安装 🤗 Optimum:
pip install optimum
然后可以使用 PreTrainedModel.to_bettertransformer() 方法启用 BetterTransformer:
model = model.to_bettertransformer()
如果您想恢复原始的 🤗 Transformers 模型,可以使用 reverse_bettertransformer() 方法:
model = model.reverse_bettertransformer()
model.save_pretrained("saved_model")
bitsandbytes¶
bitsandbytes 是一个量化库,支持 4 比特和 8 比特量化。量化可以减少模型的大小,使其更容易在内存有限的 GPU 上运行。
安装 bitsandbytes 和 🤗 Accelerate:
pip install bitsandbytes>=0.39.0 accelerate>=0.20.0
pip install transformers
4-bit¶
要以 4 比特加载模型进行推理,使用 load_in_4bit 参数。device_map 参数是可选的,但建议设置为 "auto" 以允许 🤗 Accelerate 自动高效分配模型:
from transformers import AutoModelForCausalLM
model_name = "bigscience/bloom-2b5"
model_4bit = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto", load_in_4bit=True)
对于多 GPU 环境,您可以控制每个 GPU 分配的内存:
max_memory_mapping = {0: "600MB", 1: "1GB"}
model_name = "bigscience/bloom-3b"
model_4bit = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto", load_in_4bit=True, max_memory=max_memory_mapping
)
8-bit¶
要以 8 比特加载模型进行推理,使用 load_in_8bit 参数:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
model_name = "bigscience/bloom-2b5"
model_8bit = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", quantization_config=BitsAndBytesConfig(load_in_8bit=True))
对于多 GPU 环境,您可以控制每个 GPU 分配的内存:
max_memory_mapping = {0: "1GB", 1: "2GB"}
model_name = "bigscience/bloom-3b"
model_8bit = AutoModelForCausalLM.from_pretrained(
model_name, torch_dtype="auto", device_map="auto", load_in_8bit=True, max_memory=max_memory_mapping
)
🤗 Optimum¶
🤗 Optimum 支持使用 ONNX Runtime(ORT)加速 Nvidia 和 AMD GPU 上的推理。ORT 使用诸如将常见操作融合为单个节点和常量折叠等优化技术,以减少计算步骤并加速推理。ORT 还将最密集的计算任务分配给 GPU,其余任务分配给 CPU,以智能分配工作负载。
要使用 ORT,您需要使用一个特定任务的 ORTModel,并指定 provider 参数,例如 CUDAExecutionProvider、ROCMExecutionProvider 或 TensorrtExecutionProvider。如果要导出模型为 ONNX 格式,可以设置 export=True。
from optimum.onnxruntime import ORTModelForSequenceClassification
ort_model = ORTModelForSequenceClassification.from_pretrained(
"distilbert/distilbert-base-uncased-finetuned-sst-2-english",
export=True,
provider="CUDAExecutionProvider",
)
from optimum.pipelines import pipeline
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased-finetuned-sst-2-english")
pipeline = pipeline(task="text-classification", model=ort_model, tokenizer=tokenizer, device="cuda:0")
result = pipeline("Both the music and visual were astounding, not to mention the actors performance.")
组合优化¶
可以组合多种优化技术以获得最佳的推理性能。例如,您可以加载 4 比特量化模型并启用 BetterTransformer 和 FlashAttention:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
# 加载 4 比特模型
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-350m")
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", torch_dtype="auto", quantization_config=quantization_config)
# 启用 BetterTransformer
model = model.to_bettertransformer()
input_text = "Hello my dog is cute and"
inputs = tokenizer(input_text, return_tensors="pt").to("cuda")
# 启用 FlashAttention
with torch.backends.cuda.sdp_kernel(enable_flash=True, enable_math=False, enable_mem_efficient=False):
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))