Deep!Shallow ConvNets(2018):基于卷积神经网络的深度学习,用于脑图绘制和从人脑电图中解码运动相关信息
1、研究背景和动机
1.1、为什么要提出 Deep/Shallow ConvNets
🧠 脑机接口(BCI)解码的核心挑战
- 常用方法是 滤波器组共同空间模式(FBCSP)+ LDA/SVM。
- 这类方法需要 手动选择频带、设计空间滤波器、并依赖经验进行特征工程。
- 需要大量领域知识(专家必须先知道 α、β 波等哪些频段重要)。
- 任务适配性差:不同实验范式(运动想象 MI、视觉刺激 ERP 等)都得重新调参。
- 端到端能力弱:无法从原始 EEG 直接学习到最优表示。
比喻:像靠经验厨师一步步手工调味,既慢又不一定能适配新菜谱。
🚀 深度学习的机会与当时的空白
- CNN 理论上可以直接从原始时序信号学习到时频特征和空间分布,无需手工特征工程。
- 但当时 深度学习在 EEG 上还不成熟,存在两个主要障碍:
- 大多数 CNN 架构是为图像设计的,与 EEG 的时序+通道结构不匹配。
- EEG 数据规模小、噪声大,直接套用图像 CNN 很容易过拟合。
- 此外,研究者还希望 CNN 可解释,能展示它学到的频率和脑区模式,而不是完全黑箱。
比喻:想让“图像界的自动特征工程大师”也能读懂脑电,但得改造它,让它适合 EEG 的时空特性。
1.2、DeepConvNet 的提出动机
- 验证 CNN 能否直接从原始 EEG 学习复杂时空模式
- 传统 BCI 方法依赖频带功率、CSP 特征,难以捕捉复杂非线性和时间动态。
- DeepConvNet 用多层卷积(时间→通道→更深的空间/时间模式)去自动学习这些特征 。
- 构建一个可扩展的深层架构,适合数据量较大的场景
- 对于数据充足的运动想象任务(MI-BCI),深网络可能优于浅特征,因为可以建模更细的时间模式和多层次抽象 。
- 探索 CNN 的可解释性
- 作者特别希望通过可视化卷积核和激活模式,理解 CNN 是否学到了与脑电神经生理一致的模式(如 μ/β 节律 ERD、ERP 波形等) 。
一句话概括:DeepConvNet 就是为了把 “图像 CNN 的深度特征学习” 引入 EEG,让模型自动挖掘复杂的时序-空间模式,并证明这些特征是有神经学意义的。
1.3、ShallowConvNet 的提出动机
- 设计一个更轻量、专注于频带功率的浅层 CNN
- 在一些任务(特别是运动想象)中,主要区分信息是 μ/β 节律的功率差异,无需深度特征。
- ShallowConvNet 专门针对 功率特征,只用一层时间卷积+跨通道卷积,再加平方非线性与对数池化,模仿 滤波器组+log 能量+线性判别 这种经典流程 。
- 比较深浅网络在不同任务的适用性
- 深层网络可能在复杂 ERP 或混合模式任务中更好;
- 浅层网络在以功率差异为主的 MI 任务中更稳定。
- 作者希望通过实验系统性评估深 vs. 浅 CNN,给 BCI 研究者选择网络提供依据 。
- 证明 CNN 不需要复杂预处理就能直接从原始 EEG 学习有效特征
- ShallowConvNet 和 DeepConvNet 都在尽量减少预处理的情况下工作,证明端到端深度学习在 EEG 中是可行的。
一句话概括:ShallowConvNet 是一种 轻量化、功率谱导向的端到端 CNN,用来验证:在简单谱差异任务上,浅网络是否比深网络更合适。
1.4、研究意义
- 开创 EEG 深度学习基线 DeepConvNet 和 ShallowConvNet 提供了两个极具代表性的端到端架构,从此成为 EEG 研究中常用对照模型。
- 启发后续模型设计 它们证明了 CNN 可直接处理原始 EEG,为后来的 EEGNet、TSception、EEG-TCNet、EEG-Transformer 等奠定基础。
- 提高可解释性研究 首次提出对 CNN 学到的 EEG 特征进行可视化,使深度模型不再是完全黑箱。
🔑 一句话总结
DeepConvNet / ShallowConvNet 的研究动机是:用 CNN 实现 EEG 的端到端特征学习,探索深浅网络在不同任务中的适用性,并通过可视化验证深度模型是否能自动发现与神经生理一致的时空模式,从而摆脱传统 BCI 对人工特征工程的依赖。
2、核心创新点总结
🌟 总体概念
🚀 创新点 1:端到端从原始 EEG 学习时空特征
- 以往做法:需要先做带通滤波、CSP 特征提取,再送入 LDA/SVM。
- 本研究:直接将原始 EEG 波形输入 CNN,通过网络自己学频率滤波和空间模式,无需手工工程。
- 意义:大幅简化 BCI 流程,减少对领域知识的依赖;开创了 EEG “少预处理 + 深度特征学习” 的先河。
比喻:过去是厨师自己先切配、调味再给机器炒;现在是把原材料直接交给 CNN 厨师机,让它自己调配调料。
🚀 创新点 2:深浅两种结构分别针对不同任务特点
🔹 DeepConvNet
- 多达 4 层卷积-池化模块堆叠,逐层抽取从低级频率到高级时间-空间模式。
- 第 1 层特别设计为 时间卷积 + 跨通道卷积(模仿“先滤波再空间投影”),后续 2-4 层用小核+池化压缩特征。
- 适合捕捉 复杂、非线性、时间精细模式(如 ERP、快速时序变化)。
🔹 ShallowConvNet
- 仅 1 层时间卷积 + 跨通道卷积,加上 平方非线性 + 对数池化,专注于功率谱差异。
- 架构灵感直接来自 FBCSP + log 能量特征,特别适合 运动想象 (MI) 等主要依靠 μ / β 节律功率变化的任务。
意义:首次明确提出根据任务特征选择深或浅 CNN,深网络适合复杂模式,浅网络适合简单功率特征。
🚀 创新点 3:可视化 CNN 学到的脑电特征
- 作者提出多种 网络可解释性分析方法:
- 卷积核可视化:看第一层学到的时间滤波器与频率响应。
- 特征图激活可视化:检查不同类别 EEG 在网络各层的响应差异。
- 输入扰动敏感性分析:评估特定时间段/通道对分类结果的重要性。
- 意义:证明 CNN 不仅能分类,还能学到与神经生理一致的模式,如:
- μ / β 节律的 ERD(运动想象)
- ERP 波形形态(事件相关电位)
比喻:不只是“黑箱预测”,而是给你打开盖子,让你看到 CNN 其实在听哪些“脑电频段和脑区的声音”。
🚀 创新点 4:建立 EEG 深度学习的标准基线
- 在多种 BCI 数据集(尤其是 运动想象 MI)上系统验证深浅 CNN 对比,证明其性能可与或超过经典 FBCSP+LDA。
- 提供 开源实现(braindecode 库),推动 EEG 社区采用深度学习标准化对比。
意义:Deep/Shallow ConvNets 成为后续模型(EEGNet、TSception、EEG-TCNet、Transformer 等)对照的默认基线。
🏆 核心创新点对比表
创新方向
| DeepConvNet
| ShallowConvNet
| 意义
|
端到端
| 从原始 EEG 自动提取时频+空间特征
| 同样支持端到端,但更简化
| 摆脱传统特征工程
|
网络深度
| 4 层卷积-池化,捕捉复杂时空模式
| 单层卷积 + 平方 + 对数池化,聚焦功率谱
| 深适合复杂,浅适合功率任务
|
可解释性
| 卷积核+激活可视化,验证学到 ERP/ERD 模式
| 可视化功率谱响应
| 提升深度模型在 EEG 领域的信任度
|
开源基线
| 提供标准实现,便于对比
| 同上
| 成为 EEG 深度学习的常用 benchmark
|
🔑 一句话概括
DeepConvNet / ShallowConvNet:首次将 CNN 端到端引入 EEG 解码,提出深浅互补的两种架构并提供特征可视化方法,为后续 EEG 深度学习模型奠定了基线与解释性基础。
3、网络结构原理
 | 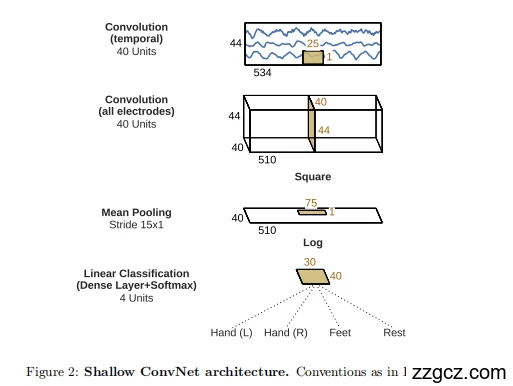 |
🟦 ShallowConvNet ——“轻量化功率特征提取器”
目标:直接模仿传统滤波器组 + log 能量特征提取流程,用最少的卷积层抓住 EEG 的主要功率差异(如 μ/β 节律)。
- Temporal Convolution(时间卷积)
- 做什么:用长度较长的一维卷积核(例如 25 个采样点 ≈ 250ms)沿时间轴卷积,每个通道独立进行。
- 意义:相当于自动做 带通滤波,提取不同频率成分(比如 8–12Hz μ 波,13–30Hz β 波)。
- 比喻:像给音频加不同的均衡器滤波器。
- Convolution (all electrodes)(跨通道卷积)
- 做什么:用卷积核覆盖所有电极通道,对每个时间滤波后的信号做空间加权,学习全头皮的最优空间投影。
- 意义:类似经典的 CSP 空间滤波,把信息从多个电极整合出来。
- 比喻:像给不同话筒的声音加权,合成一条最有用的音轨。
- Square 非线性
- 做什么:对输出做平方运算。
- 意义:把振幅转成功率(幅度平方 = 能量),和传统的 功率谱特征完全一致。
- 比喻:就像把电压转成功率,看能量强弱。
- Mean Pooling(平均池化)
- 做什么:在时间维度上用大步长(stride 15)平均池化,得到一个更平滑、更稳定的功率时间序列。
- 意义:降低时间分辨率,提取稳定的功率趋势。
- Log 非线性
- 做什么:对池化后的功率取对数。
- 意义:把功率特征压缩成更适合线性分类的分布(log 功率是传统 EEG 分析常用形式)。
- 比喻:把功率数值“压平”,避免强信号过度主导。
- Linear Classification(Dense + Softmax)
- 做什么:最后用一个线性全连接层 + softmax,把功率特征映射到分类结果(如左手/右手/脚/静止)。
- 意义:等同于传统线性分类器(LDA/SVM),但特征是网络自动学的。
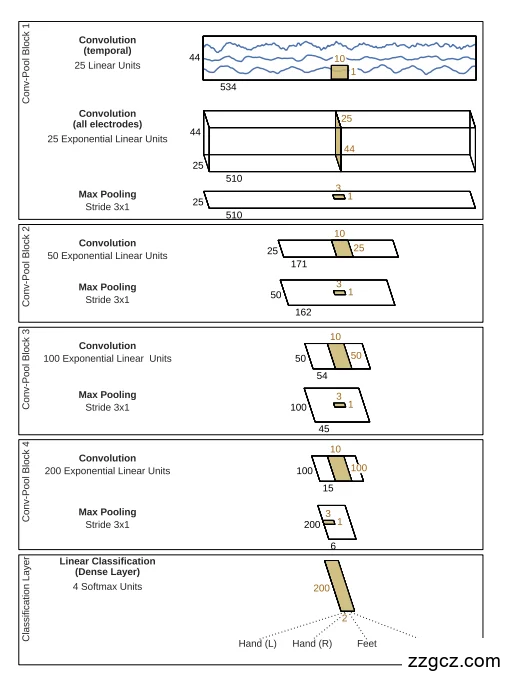
🟧 DeepConvNet ——“多层时空模式捕捉器”
目标:通过更深的网络,学习更复杂的时间模式和非线性特征,适合 ERP 或混合型任务。
Block 1: Temporal Convolution + Spatial Convolution + MaxPooling
- 时间卷积:与 ShallowConvNet 类似,首先在每个通道上做长时间核卷积提取频率成分。
- 跨通道卷积:学习最优空间组合(类似 CSP)。
- 非线性:使用 Exponential Linear Unit (ELU) 而非平方。
- 最大池化 (stride 3):减少时间维度,保留显著局部激活。
- 意义:这一块基本等同于“EEG 滤波+空间滤波+时间下采样”,为后续深层提取准备基础特征。
Block 2–4: 更深的 Conv + MaxPooling 堆叠
- 每个 Block 用 小卷积核(长度 10)+ ELU + MaxPooling。
- 随着层数加深,通道数逐渐增大(25 → 50 → 100 → 200),提取更高阶、更抽象的时间-空间模式。
- 这些层不再分开时间/空间,而是直接对前一层特征做全卷积,逐渐形成复杂的时空表示。
比喻:
- Block1 是在听基本音调和位置;
- Block2-4 像作曲家逐步理解旋律、和声与节奏变化,提取复杂动态。
Classification Layer
- Dense + Softmax:将深层特征映射到分类标签。
- 与 ShallowConvNet 相比,前面已经把特征抽象到高维语义空间,因此最后只需简单线性层即可。
🔍 对比小结
特点
| ShallowConvNet
| DeepConvNet
|
层数
| 1 个卷积块 + 平方 + 对数池化
| 4 个卷积-池化块
|
特征偏好
| 功率谱(慢变化能量差异)
| 复杂时序 + 空间交互
|
非线性
| Square + Log
| ELU
|
参数量
| 少,易训练
| 多,易过拟合
|
任务适合度
| 运动想象 (MI)、功率差异任务
| ERP、复杂时间模式任务
|
🌟 一句话总结
ShallowConvNet:用最少卷积模拟“滤波 + 功率 + log”特征提取,轻量易用。 DeepConvNet:多层堆叠卷积池化,逐级学习复杂时空模式,更适合高复杂度 EEG 解码。
4、模型的核心不足与局限
数据依赖与过拟合问题
DeepConvNet
- 参数量大,易过拟合
DeepConvNet 有 4 个卷积-池化块,卷积核数目逐层递增(25→50→100→200),参数量远大于 EEG 数据通常能提供的样本数。
- 在数据量不足时容易出现过拟合,需要大量正则化(Dropout、最大范数约束)和数据增强。
- 训练时间较长,对硬件要求高 深度结构训练慢,对于实时 BCI 或嵌入式设备部署不友好。
ShallowConvNet
- 数据依赖相对较小,但仍需一定样本量 尽管浅层网络较小,但如果样本极少,仍难以泛化。
比喻:DeepConvNet 像一台“高配置跑车”,需要足够燃料(数据);ShallowConvNet 虽省油,但如果油太少也跑不远。
泛化能力有限,跨被试适应性差
- 两个模型在组内(intra-subject)训练下效果好,但**跨被试(cross-subject)**性能显著下降。
- 需要针对每个新受试者重新微调或训练,这在实际 BCI 使用中非常不便。
- 缺乏迁移学习或领域自适应机制。
比喻:它们就像是量身定制的鞋子,给一个人穿很合脚,换个人就得重做。
对噪声与伪影鲁棒性不足
- EEG 信号容易被眼动、肌电、运动等伪影污染,这两个模型没有显式抗噪设计。
- 对预处理依赖较高,数据若未充分清理,模型性能会明显下降。
比喻:这两个模型在“干净乐谱”上表现好,但如果谱子上有很多杂音,演奏就会跑调。
时间建模能力有限
- ShallowConvNet
- 只用单一长时间卷积和池化,基本只提取平均功率信息,难以建模复杂的时序动态。
- DeepConvNet
- 虽然比 Shallow 更深,但仍是局部卷积和池化叠加,缺乏显式的长时依赖机制(如 TCN、Transformer)。
- 对于持续数秒或更长的动态过程(如认知状态变化、长时间监控),能力有限。
可解释性仍然有限
- 虽然作者提出可视化方法,但:
- 可视化主要是低层卷积核和激活,更深层次仍难直观解释。
- 对非神经科学背景的用户仍然不易理解;难以完全解释复杂决策逻辑。
- 相比线性方法(如 CSP+LDA),仍然是“半透明黑箱”。
实时应用与轻量化受限
- DeepConvNet 模型体积大、推理速度慢,不适合嵌入式或低功耗 BCI。
- ShallowConvNet 虽轻量,但特征表达力有限,难以适应更复杂任务。
- 缺乏现代轻量化技术(如深度可分离卷积、量化、NAS 优化)。
局限方向
| DeepConvNet
| ShallowConvNet
|
数据需求
| 参数多,易过拟合,需要大数据和正则化
| 数据需求较低,但极小样本时仍不稳
|
泛化性
| 跨被试效果差,需要重新训练
| 同样缺乏迁移能力
|
抗噪性
| 对伪影敏感,依赖预处理
| 同样缺乏显式抗噪机制
|
时间建模
| 局部卷积堆叠,缺乏长时依赖
| 仅提取平均功率,无法建模复杂动态
|
可解释性
| 提供可视化但深层仍不透明
| 低层解释较清晰,但整体仍有限
|
实时性/轻量化
| 参数量大,速度慢
| 虽轻量但表达力有限
|
5、未来改进方向
1. 轻量化与小样本友好
背景局限
- DeepConvNet 参数量过大,训练慢且需要大量数据,易过拟合;
- ShallowConvNet 表达力有限,但依然需要适量数据。
改进方向
- 使用轻量化卷积结构
- EEGNet (2018) 引入 深度可分离卷积 (Depthwise Separable Convolution),极大减少参数量和计算量,使网络可在少数据条件下训练并在实时 BCI 中部署。
- 模型压缩与正则化
- 剪枝、量化、Dropout、最大范数约束等被广泛采用;
- 新模型开始重视 few-shot/transfer learning,减少对大样本的依赖。
- 自动架构搜索 (NAS)
- 一些新工作探索自动搜索最优 EEG 网络架构,使模型既轻量又高效。
典型例子:EEGNet 直接针对“参数过多”问题提出 小型化网络,在保留分类性能的同时减少 10~100 倍参数量。
跨被试泛化与迁移学习
背景局限
- Deep/Shallow ConvNets 在跨被试泛化性差,需要每次重新训练或微调。
改进方向
- 领域自适应 (Domain Adaptation)
- 利用对抗训练、统计特征对齐(如最大均值差异 MMD)使模型能适应新被试分布。
- 迁移学习 (Transfer Learning)
- 用大规模 EEG 数据预训练,再微调到新被试;
- 或使用元学习(MAML)快速适应个体差异。
- 图神经网络 (GNN)
- DAGCN (Dynamic Attention-based Graph Convolutional Network) 把 EEG 通道关系建模为动态图,提高跨被试的鲁棒性和结构化泛化能力。
典型例子:DAGCN 将 EEG 电极关系建成图结构,并通过动态图注意力来适配不同被试的脑区差异。
更强的时间建模与长时依赖
背景局限
- ShallowConvNet 只做简单功率平均;
- DeepConvNet 局部卷积难以捕捉长时间上下文。
改进方向
- 时间序列感知增强
- TSception (2019):提出 多尺度时序卷积 (Temporal Sception blocks),不同大小的卷积核并行提取短期和长期依赖。
- EEG-TCNet (2021):在卷积后加入 Temporal Convolutional Network (TCN),用因果扩张卷积建模长时依赖。
- Transformer 架构
- EEG-Transformer:用自注意力 (Self-Attention) 捕捉长时上下文和全局关系,比卷积更适合长时间脑电解码。
- 混合结构
- CNN + RNN/LSTM 或 CNN + Attention,被用于建模复杂的时间动态和阶段变化。
典型例子:TSception 用不同长度卷积核相当于“多种时间放大镜”,EEG-Transformer 则让模型能一次性关注整个序列的任意位置。
噪声与伪影鲁棒性
背景局限
- Deep/Shallow ConvNets 对眼动、肌电等伪影敏感,缺少抗噪设计。
改进方向
- 注意力机制 (Attention)
- 模型自动关注信息丰富的时间段和电极,抑制伪影。
- 自适应滤波 / 噪声建模
- 在网络中集成滤波模块,动态抑制干扰。
- 对抗训练 & 数据增强
- 模拟噪声样本增强训练,或用对抗性扰动提高鲁棒性。
典型例子:DAGCN 的注意力机制帮助模型自动忽略含噪电极;TSception 也在不同时间窗口自适应选择有效信息。
可解释性与可视化提升
背景局限
- Deep/Shallow ConvNets 虽提供卷积核和激活可视化,但仍难解释深层决策逻辑。
改进方向
- 可解释 AI (XAI) 工具集成
- 结合 Grad-CAM、Layer-wise Relevance Propagation (LRP) 等可视化方法,让模型关注的时空位置更清晰。
- 可视化与神经科学结合
- 直接将网络学到的空间权重映射到脑区上,用于神经机制研究。
- 物理/神经约束建模
- 在网络结构中显式加入神经解剖学或信号先验,提高解释力。
典型例子:EEGNet 与后续工作常用 LRP/Grad-CAM 对时空特征进行解释,比原始 DeepConvNet 更直观。
实时化与可部署性
背景局限
- DeepConvNet 模型庞大,难以实时推理;
- ShallowConvNet 虽轻,但特征单一。
改进方向
- 轻量网络 + 边缘部署
- EEGNet 小模型化 + 移动端推理;
- 后续有 MobileNet 化 EEG 模型的研究。
- 在线学习与快速适应
- 结合少量在线校正训练,实现动态自适应。
- 低功耗硬件优化
- 将 EEG 网络量化、稀疏化,适配 FPGA/嵌入式平台。
局限点改进方向代表模型参数量大、过拟合轻量化卷积、正则化EEGNet跨被试泛化差迁移学习、域适应、图网络DAGCN时间建模弱多尺度卷积、TCN、TransformerTSception, EEG-TCNet, EEG-Transformer噪声敏感注意力机制、数据增强、鲁棒训练DAGCN, TSception可解释性有限XAI 可视化、神经先验EEGNet + Grad-CAM/LRP实时性差模型压缩、轻量化部署EEGNet, Mobile EEGNet