EEG-TCNet(2020)一种用于嵌入式电机图像脑机接口的精确时间卷积网络
导出时间:2025/11/24 09:01:32
1、研究背景和动机
1)脑机接口(BCI)与 EEG 解码的挑战
脑机接口(BCI)技术希望通过 解码脑电信号(EEG) 来实现与外部设备的交互,例如运动想象(Motor Imagery,MI)控制假肢、辅助交流或康复训练。
EEG 具有非侵入性和高时间分辨率的优势,但也面临一些长期难题:
- 信号低信噪比:容易受到肌电、眼动和环境噪声干扰;
- 个体差异大:不同被试的脑电模式差异显著,迁移难度高;
- 特征提取困难:传统方法(如 CSP + LDA)依赖手工构造特征,对信号非平稳性适应差;
- 数据量有限:BCI 研究中可用标注 EEG 数据往往较少,深度模型易过拟合。
2)深度学习在 EEG 解码中的进展与不足
早期 CNN 模型(如 DeepConvNet / ShallowConvNet)和轻量化架构(如 EEGNet)证明了端到端学习的可行性,但仍存在显著问题:
- 时间建模不足
- CNN 核心依赖局部卷积和池化,感受野有限;
- EEG 中存在长时间依赖(如 MI 任务中 1~4s 的持续信号),单纯卷积难以捕捉全局时间结构。
- RNN/LSTM 尝试效果不佳
- 一些研究用 LSTM、GRU 建模时间序列,但这类循环网络训练难度高、计算开销大、梯度易消失,且对小样本不友好。
- 轻量化与性能平衡
- DeepConvNet 参数量大,难以在实时 BCI 部署;
- EEGNet 虽轻量但在复杂时间结构任务上性能不够强。
因此,需要一种 既能建模长时间依赖,又保持轻量高效的网络。
3)EEG-TCNet 的提出动机
针对上述挑战,作者提出 EEG-TCNet(Temporal Convolutional Network for EEG decoding),其设计目标包括:
- 强化时间序列建模能力
- 引入 Temporal Convolutional Network (TCN),用 扩张卷积(dilated convolution) 在不增加参数的情况下实现长时间上下文建模,替代传统 RNN。
- 保持模型轻量化和小样本适应
- 将 TCN 模块嵌入 EEGNet 的轻量架构中,保持参数量低、易在小规模 EEG 数据上训练。
- 提升 MI 任务的解码性能
- 专门针对 运动想象(Motor Imagery)BCI 进行优化,改善分类准确率并保持低延迟推理,适合实时应用。
- 兼顾端到端与可部署性
- 不依赖手工特征工程,直接从原始 EEG 提取时空特征并输出分类结果,便于在 BCI 系统中直接部署。
🌟 一句话总结
EEG-TCNet 的动机是结合 CNN 的轻量化优势与 TCN 的长时依赖建模能力,解决 EEG 解码中时间信息捕获不足、RNN 训练困难和小样本难题,从而在运动想象等 BCI 场景实现更高精度和实时性。
2、核心创新点总结
🌟 总体概念
EEG-TCNet = “EEGNet + TCN”
在 EEGNet 的轻量时空卷积基础上,引入 Temporal Convolutional Network (TCN) 来建模 长时序依赖,实现 高精度 + 小样本友好 + 实时可部署 的 EEG 解码网络。
🚀 创新点 1:引入 TCN 长时依赖建模替代 RNN/LSTM
- 问题背景:
- CNN(如 EEGNet、DeepConvNet)时间感受野有限,难以捕捉运动想象等任务中持续几秒的信号模式;
- RNN/LSTM 虽能处理序列,但训练难度大、推理慢且参数多,对 EEG 小样本不友好。
- EEG-TCNet 的做法:
- 在 EEGNet 卷积特征后接入 Temporal Convolutional Network (TCN),使用 扩张卷积(dilated convolution) 来指数级扩大感受野。
- TCN 使用残差连接和因果卷积,保证长时间上下文建模时 训练稳定、并行高效。
- 意义: 在保持轻量和可并行的同时,解决了 CNN 时间建模不足、RNN 训练慢的问题。
🧩 类比:CNN 只能“看窗外几米的景色”,TCN 像装了望远镜,能看到更远的历史画面。
🚀 创新点 2:保持 EEGNet 的轻量化优势
- 问题背景: 深度时序模型(如 RNN/LSTM)往往参数量大,不适合实时 BCI。
- EEG-TCNet 的做法:
- 主干部分继承 EEGNet 的深度可分离卷积,先用轻量化卷积提取空间与频率特征;
- TCN 模块参数可控,通过调整层数和扩张率来平衡计算量与感受野。
- 整体参数量和计算开销仍保持在低水平,比 DeepConvNet 小得多。
- 意义: 既保留了 EEGNet 在实时 BCI 中的高效性,又提升了时间特征建模能力。
🧩 类比:在轻便微单相机上加了长焦镜头,依旧轻巧但视野更远。
🚀 创新点 3:端到端训练,减少手工特征工程
- 问题背景: 许多传统 EEG 解码方法依赖功率谱密度 (PSD)、CSP 等人工特征,对数据预处理要求高。
- EEG-TCNet 的做法:
- 保留 EEGNet 的端到端思路,直接输入原始或轻预处理的 EEG 数据。
- CNN + TCN 联合训练,自动学习时频特征和长期动态模式。
- 意义: 简化了 EEG BCI 系统的构建流程,让模型直接适应原始信号特征,减少工程复杂度。
🚀 创新点 4:在小样本与实时 BCI 中表现优异
- 问题背景: BCI 实验数据采集成本高、样本量有限,传统深度网络易过拟合且推理延迟大。
- EEG-TCNet 的做法:
- TCN 通过残差结构与扩张卷积高效利用有限数据。
- 参数规模较小,推理延迟低,适合实时脑机接口(在线反馈)。
- 意义: 对小数据集训练友好,并能满足在线控制和临床应用的延迟需求。
🚀 创新点 5:在运动想象任务上显著提升性能
- 问题背景: 运动想象 (MI) 是 BCI 的核心任务,但以往 CNN 性能受限于时间信息捕获能力。
- EEG-TCNet 的做法:
- 用 TCN 扩展时间建模,使模型能同时捕捉 µ、β 节律变化 和 长时动作想象动态。
- 在公开数据集(如 BCI Competition IV 2a/2b)上,准确率优于 EEGNet、ShallowConvNet 等基线。
- 意义: 实验验证了其在 MI BCI 解码中的实用价值,是 EEGNet 的重要进化版本。
🏆 创新点对比表
特性
| EEGNet
| RNN/LSTM
| EEG-TCNet
|
时间建模
| 局部卷积
| 长依赖(训练难、慢)
| 扩张卷积+残差连接,高效建模长时依赖
|
模型轻量
| ✅
| ❌
| ✅
|
并行计算
| ✅
| ❌(序列依赖)
| ✅
|
小样本适应
| 中等
| 较差
| 较好
|
实时部署
| ✅
| 较差
| ✅
|
✨ 一句话总结
EEG-TCNet:将轻量 CNN(EEGNet)与扩张卷积的 TCN 相结合,实现端到端长时依赖建模,在保持高效率的同时显著提升了 EEG 解码(尤其是运动想象 BCI)的准确率和实时性。
3、总体架构概览
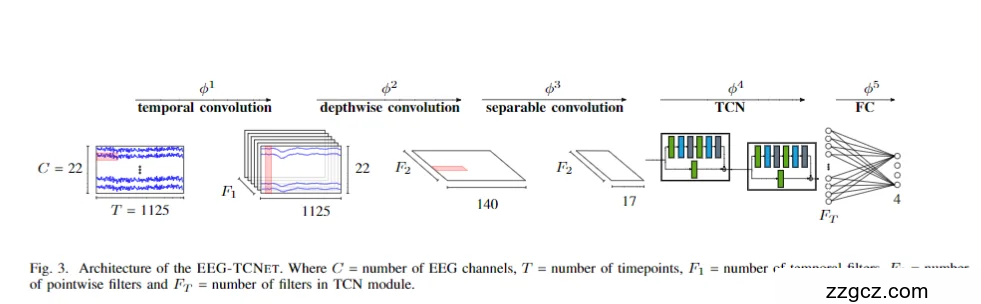
EEG-TCNet 可以看成两部分组合:
- EEGNet 前端 —— 轻量化 CNN 提取时空特征
- TCN 模块 —— 用扩张卷积(dilated causal conv)建模长时间依赖
- 全连接层(FC) —— 输出任务类别(如运动想象左手、右手、脚、休息)
整体思路:先用 CNN 从原始 EEG 中提取时频和空间信息,再用 TCN 像“长焦镜头”一样捕捉长时间上下文,最后用简单分类器输出结果。
1️⃣ CNN 前端(EEGNet 基础部分)
(1)Temporal Convolution —— 时间卷积层
- 作用:从每个通道的原始 EEG 序列中提取频率相关特征(如 μ、β 波)。
- 做法:使用一维卷积核沿时间轴滑动,等价于对信号做可学习的滤波器组。
- 效果:提取不同频段的局部时序模式,减少手工滤波需求。
(2)Depthwise Convolution —— 空间卷积(分通道卷积)
- 作用:在时间特征上学习每个通道的独立空间模式。
- 做法:每个时间特征图只对自己通道做卷积,避免参数爆炸。
- 意义:实现空间特征提取的同时保持轻量化。
(3)Separable Convolution —— 深度可分离卷积
- 作用:将深度卷积和逐点卷积分开,减少参数,同时融合跨通道信息。
- 意义:在保留表示能力的同时显著减轻计算负担,这是 EEGNet 轻量化的关键。
🧩 总结:CNN 前端相当于自动学习了一组滤波器来提取时频特征,并用轻量化方法融合空间信息。
2️⃣ TCN 模块 —— 长时间依赖建模的核心
这是 EEG-TCNet 相比 EEGNet 的最大创新部分。
(1)为什么需要 TCN
- CNN 局部卷积感受野有限;
- RNN/LSTM 虽能建模长序列,但训练慢、难以并行。
- TCN (Temporal Convolutional Network) 用扩张卷积在保持并行计算的前提下扩大时间感受野。
(2)TCN 结构细节(图 2)
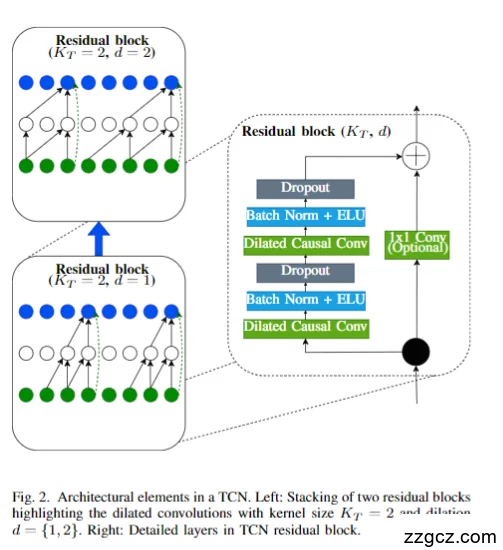
- Dilated Causal Convolution(扩张因果卷积)
- 扩张率 d = {1,2,…},通过在卷积核之间插入空洞指数级扩大感受野;
- 因果卷积保证输出只依赖当前和过去的时间点,符合时间序列因果性。
- Residual Block(残差连接)
- 每个残差块包含两层扩张卷积 + BN + ELU 激活 + Dropout;
- 残差连接缓解深层网络的梯度消失,并让训练更稳定。
- 可选的 1×1 卷积 用于匹配维度。
- 堆叠多级残差块
- 多层级扩张(如 d=1,2,4,…),使感受野呈指数级增长,在小参数量下捕捉长时间依赖。
🧩 直观理解:TCN 像一个“多级时间放大镜”,能在不增加太多计算的前提下看得更远、更长的 EEG 时间序列。
3️⃣ 全连接分类器(FC)
- 作用:将 TCN 输出的时序特征映射到具体任务类别(如左手、右手、脚、休息)。
- 做法:一到两层全连接 + Softmax 输出。
- 意义:因为前面特征提取已充分,分类头非常轻量,不增加计算复杂度。
🔬 数据流与特征演化
- 输入:原始 EEG(C 通道 × T 时间点)
- Temporal Conv:时间卷积提取频率成分
- Depthwise Conv:各通道独立空间建模
- Separable Conv:轻量融合跨通道时空信息
- TCN 模块:多级扩张卷积捕捉长时序上下文
- FC:全连接输出任务类别
4、模型的缺陷
峰值精度仍落后于最强 SOTA
论文在 BCI IV-2a 上给出:EEG-TCNet(固定超参)平均 77.35%;做被试特定的网格搜索后提升到 83.84%。而重模型 TPCT 可达 88.87%(但代价是 7.78M 参数、1.73G MACs)。这表明在追求“最高精度”方面,EEG-TCNet 仍逊于极大模型。
依赖“被试特定”超参数调优
作者明确报告:通过“为每位受试者优化网络超参数”才能把准确率从 77.35% 再提升 +6.49% → 83.84%;并展示不同被试间精度差异显著、需个体化配置的动机与做法。这意味着模型开箱即用的通用性有限,需要额外搜索成本与工程流程。
精度–资源的权衡仍存在
论文指出:相较固定版,可变(被试特定)EEG-TCNet 为提升精度,参数量最高可增至 4.80×、MACs 至 1.78×;虽然总体仍小于大模型,但要拿到最佳效果依旧要付出更多算力/内存开销。
跨数据集一致性受限(方差大)
在 MOABB 的荟萃分析中,作者特别提醒:不同数据集间存在显著方差,“在这些数据集上评估方法,可能导致相互矛盾的结果。”这说明即便整体元效应优于基线,跨数据集的稳定泛化仍是挑战。
实验设定对数据前提较敏感
论文的主实验固定使用 0.5–4.5 s 时间窗、不额外带通滤波(仅数据集自带预处理),并且先据 EOG 标注剔除了约 9.41% 含伪迹试验后再训练评估。此设定利于得到干净训练样本,但也意味着对窗口与预处理假设较敏感、在更嘈杂或不同协议的数据上可能需重新设定流程。
5、EEG-TCNet:下一步创新与改进方向(基于论文证据的推演)
1. 个体化/会话自适应学习(更稳)
- 做什么:在共享主干上加“超轻个性化头”(或自适应BN/少量可训练门控),上线后做少量快速微调;结合不需要标签的测试时自适应(TTT/TENT风格)与域对抗(DANN)稳住分布漂移。
- 为什么:论文表明“为每位受试者优化超参”把BCI IV-2a 的准确率从固定配置的 77.35% 拉到 83.84%,说明个体差异巨大、个性化收益显著。
- 同时,MI-BCI 的核心难点之一就是低信噪比与“不同受试者/会话方差大”,很难用一个统一模型搞定所有人。
- 另外,论文也直接建议针对输入分布变化做鲁棒ConvNet(引用Ganin等人的思路),以缓解会话间分布漂移。
时间建模升级:可变感受野 + 早退(更快)
- 做什么:把TCN固定的膨胀率表改成“可学习/自适应”或多分支动态膨胀;在若干TCN层后插入“早退”分类头,滑窗到足够自信就提前输出,降低延迟。
- 为什么:TCN 的感受野由核长K、残差块数L决定并呈指数增长(RFS公式),当前是固定表;改成可学/动态更能贴合不同被试与范式的最优时长。
- 论文使用 0.5s 提示前至MI结束的 4.5s 窗口做训练与推理,适合做滑窗早退以兼顾“精度–延迟”。
端侧部署联动设计:量化/剪枝/蒸馏一体化(更省)
- 做什么:把EEG-TCNet主干做 8-bit 量化感知训练(QAT),叠加结构化剪枝与知识蒸馏;做“算力-内存联合约束”的神经架构搜索(NAS),直接针对MCU SRAM 与 MACs 预算找解。
- 为什么:论文在比较内存时明确按“8位量化特征图+权重几乎不损精度”的假设来估算,并给出MACs计算与内存定义;这为QAT与内存感知设计提供了依据。
- 同时,设备侧有硬约束,必须从“参数/MACs/中间特征尺寸”三方面共同压缩。
- 论文也指出时间卷积与中间特征图是主要算/存开销,剪枝+蒸馏能精准对症。
伪迹鲁棒与多模态协同(更稳)
- 做什么:在训练时加入“合成伪迹增强”(眨眼/EOG、肌电/电源噪声模拟)与伪迹判别辅助头;若应用允许,联合EOG/IMU等多模态做“伪迹抑制→EEG判别”的级联。
- 为什么:BCI IV-2a 中有 9.41% 的试次因EOG伪迹被剔除,且按竞赛规则不允许使用EOG通道;现实应用里无法总是剔除,模型应学会“带伪迹也能判”。
多尺度时频融合的“EEG-TCNet-MS”
- 做什么:在TCN前加入多尺度时间核/子带并行支路(Inception-like),或把可分离卷积的时间核尺度做成与采样率成比例的多级集合,再由TCN汇聚。
- 为什么:EEG模型对时间核长度/频带非常敏感:EEGNet就把时间核长度与采样率绑定以覆盖关键频段;把这种“与采样率耦合的多尺度”带到TCN能更稳地覆盖被试差异。
跨数据集泛化与评测升级(更广)
- 做什么:在MOABB上采用域泛化(IRM、RSC等)与“元学习+跨数据集轮换”的训练日程,并把“能否免校准/少校准迁移”的指标列为一等公民。
- 为什么:论文的MOABB荟萃分析明确指出“不同数据集间存在显著方差,在这些数据集上评估方法可能导致相互矛盾的结果”,因此需要面向“跨数据集一致性”的方法与指标。
- 同时,EEG-TCNet在MOABB上整体优于强基线(元效应+0.25),是很好的起点。
在线/实时解码策略联动(更灵)
- 做什么:采用“裁剪(crop)训练+滑窗推理+延迟–精度可调”的运行策略,把模型结构优化与解码策略协同起来(例如短窗快速决策,长窗高置信度)。
- 为什么:裁剪训练被证明有利于在线解码场景中平衡“首个可用控制信号的时长(延迟)与精度”。
- 结合第2点的早退头,可以在端侧把平均响应时间进一步压低。
空间拓扑显式化(更准)
- 做什么:把电极拓扑编码进模型:在可分离卷积后接“图卷积/注意力”(通道=节点,边=物理邻接/功能相关),或用可学习的通道重排与通道注意力(SE/EMA风格)提升跨通道信息建模。
- 为什么:当前框架主要靠深度卷积捕捉空间特征;把“拓扑先验”显式注入,能在不显著增参的前提下提升跨通道判别力(与端侧剪裁兼容)。论文已显示EEG-TCNet将EEGNet的浅层时空抽取与TCN串联,是自然的插入点。
训练–部署一体的“能耗/内存度量”与共同优化(更可落地)
- 做什么:把“每次推理的MACs、峰值中间特征内存、8bit量化假设下的占用”纳入训练目标(如FLOPs/显存正则或资源约束NAS),在MOABB与BCI IV-2a上同时报告“能量/延迟/内存—精度”帕累托前沿。
- 为什么:论文已系统给出MACs计算与“按8bit量化估算内存”的规范,这天然适合作为多目标优化的度量标准,并且EEG-TCNet在参数/MACs–精度上已处于帕累托前沿,适合继续做共设计。