EEG-Transformer(2022):Transformer网络对原始脑电数据分类的效能
导出时间:2025/11/24 09:01:53
1、研究背景和动机
1.1 EEG 信号与建模的老难题
- 高噪声 & 个体差异大:肌电、眼动、导联接触等伪迹让原始 EEG 很“脏”;不同被试的脑电分布也常常“各唱各的”。
- 时空耦合强:同一时刻不同电极之间相关、同一电极跨时间点也相关;既要看时间依赖,也要看跨导联关系。
- 特征工程依赖重:传统路子常要做滤波、分段、频带功率、连接性指标等手工特征,流程长、泛化差。
- 端到端深度学习的目标,就是尽量少特征工程,直接从尽可能“原生”的 EEG 中学出判别信息。
1.2 你已学过的四类代表模型:思路与短板
把它们放在一条“时—空—图—全局注意”的轴线上看,会更清晰。
- EEGNet(紧凑 CNN) 核心:深/可分离卷积先做频段样式(时间卷积近似带通滤波),再做空间投影(深度可分离卷积把跨导联混合学出来)。 优势:参数少、端到端、BCI 友好; 可能的短板:卷积感受野有限、跨长时间依赖与远距离导联关系捕捉受限(需要加深或增大核/空洞率才能扩感受野)。
- TSception(多尺度时域 Inception + 简化空间建模) 核心:多种卷积核长度并行,学多时间尺度模式;再配合通道选择/简单空间聚合。 优势:对“节律/节奏快慢不一”的 EEG 友好; 可能短板:空间关系建模相对弱,跨通道全局交互不够灵活。
- EEG-TCNet(TCN + EEGNet 思想) 核心:引入 Temporal Convolutional Network(膨胀/因果卷积) 扩大时间感受野,兼顾长依赖; 优势:比 RNN 更易并行,感受野能很大; 可能短板:时间卷积仍是局部核堆叠,想做到任意两时刻直接交互,不如注意力来得彻底。
- DAMGCN(图卷积家族,动态/自适应图) 核心:把电极当图节点,学习自适应邻接,做跨通道结构化建模;常配注意力或门控机制增强边权更新。 优势:对空间结构/功能连接很强; 可能短板:时间建模常需额外模块(RNN/TCN/CNN);图结构设定/学习也会带来归纳偏置与超参敏感。
小结:
- CNN/TCN 系列:时间建模强,空间全局交互相对弱;
- GCN 系列:空间结构强,长程时间依赖要靠别的模块补;
- 我们想要一个同时覆盖“长时间—跨通道全局”的统一机制,并且尽量少手工特征。
1.3 为何转向 Transformer?
把 EEG 看成“序列/片段的集合”(时间片 × 通道),自注意力天然适配以下需求:
- 长程时间依赖:自注意力一次就能让任意两时刻互相“看到”,不用层层堆卷积或循环。
- 跨通道全局关系:注意力权重本质上是数据驱动的“自适应连接”,等价于“动态学图”,不需要固定邻接。
- 并行与可扩展:相比 RNN,注意力计算能高效并行;相比卷积,全局感受野更直接。
- 减少特征工程:直接吃“清洗后的原始 EEG 片段”,通过嵌入+位置编码+多头注意力学习判别特征,弱化对手工频域/连接性特征的依赖。
1.4 这篇 EEG-Transformer 的经验信号(作为动机的证据)
- 直接用(仅清洗/预处理后的)原始 EEG 训练 Transformer,不做传统特征提取;
- 在年龄/性别与 **STEW 心理工作负荷(二/三分类)**任务上,取得与或优于当时 SOTA 的表现;
- 网络采用多头自注意力 + 前馈(堆叠 4 个编码器),小嵌入维度(如 32)、中等隐藏维度(如 64),二/三/六分类只改最后层即可;
- 结果支持了“Transformer 可显著降低 EEG 特征工程依赖”这一命题。
直观对比到你的已学模型:
- 相比 EEGNet / TSception / EEG-TCNet:Transformer 提供真正全局的时域交互(不是局部核堆叠),更擅长捕捉远距离时序关联;
- 相比 DAMGCN:Transformer 的注意力矩阵可视为“数据驱动的动态全连接图”,不需先验邻接,也能跨导联建模;
- 共同点:都可接轻量预处理(带通、ICA、坏段剔除),坚持端到端;不同点是归纳偏置:卷积偏向局部平移不变、GCN 偏向图结构,Transformer 偏向内容驱动的全局加权。这也解释了其在原始片段上“少特征、强表现”的吸引力。
1.5 面向应用与研究的动机归纳
- 工程动机:想要更短的流水线(更少特征工程模块)、更好的跨被试泛化、可复用到不同范式(只改头部)。
- 科学动机:用注意力权重解释“何时×何导联”在关注,为神经机制假设提供可视化线索。
- 方法学动机:把 EEG 建模从“局部卷积/固定图”推进到“内容自适应的全局交互”,并探索EEG 专属位置编码/嵌入等改进方向(例如把频带、导联拓扑、时频原子融入 embedding)。
2、核心创新点总结
端到端:直接用“清洗后的原始EEG”,不做手工特征
- 论文把 Transformer 直接接在预处理后的原始片段上完成分类,不再依赖 DWT/PSD/PLV 等手工特征与复杂特征工程;并在两个任务(年龄/性别与 STEW 心理负荷)上拿到与/优于当时 SOTA 的结果。这一点是相对 EEGNet/TSception/EEG-TCNet(仍以卷积/时频特征为主)和 DAMGCN(常搭配图上手工或学习到的连接)最显著的范式差异。
统一框架,可换头适配多任务
- 同一套编码器堆叠(4 个 Transformer 编码器)+ 轻量分类头,通过改最后层/注意力头数即可从二分类(性别、二级负荷)切到多分类(年龄 6 类、三级负荷),训练配方基本不变。这种“共享主干 + 任务头可插拔”的设计,降低了跨范式迁移成本。
小参数、全局交互:用多头自注意力同时覆盖“长时间—跨通道”
- 相比卷积/TCN 的局部感受野或 GCN 的固定/自适应邻接,自注意力一次性建模任意片段间关系(时序与通道混合编码后进入注意力),以较小的嵌入维度(32)、中等前馈宽度(64)与少量注意力头(4/8)实现全局交互与良好并行性。对比你学过的模型:它相当于把 EEG-TCNet 的长程时间 与 DAMGCN 的跨通道关联统一到一个权重矩阵里。
位置编码 + 输入嵌入的 EEG 化实践
- 明确给每个片段注入位置编码,与嵌入向量同维后相加;虽然作者也指出当前位置编码并非“专为 EEG 设计”,但这套标准做法已经在原始 EEG 上有效,提示未来可沿“EEG 专属位置编码/通道拓扑编码”继续优化。
可解释性与特征可视化的证据链
- 论文提供了嵌入与学习到的特征表征可视化,辅助理解模型关注的“何时×何导联”模式;这为后续把注意力热力图当作可解释线索打了样。
对“单头注意力”方法的经验性超越
- 消融与横向对比显示:多头注意力的 Transformer 在两个数据集上整体优于以往的基于注意力的 BLSTM 等方法;作者将性能提升归因于 multi-head 能更高效地学习多样关系。这从经验层面支撑了“用注意力统一时空建模”相对 RNN/CNN/单头注意的优势。
强基线结果,支撑“少特征工程”的可行性
- 年龄/性别:94.53%(性别,二分类)/87.79%(年龄,六分类);STEW:95.28%(二级)/88.72%(三级)。这些成绩全部基于“未经手工特征提取的原始 EEG”,为端到端范式提供了“可落地”的分数背书。
训练与预处理流程最小化但规范
- 只做必要清洗(带通、分段、坏段/坏道剔除、ICA),然后直接送入 Transformer;这条流水线对实际 BCI/在线部署很友好,也便于与你熟悉的 EEGNet/TSception 等做公平对比。
3、模型的网络结构
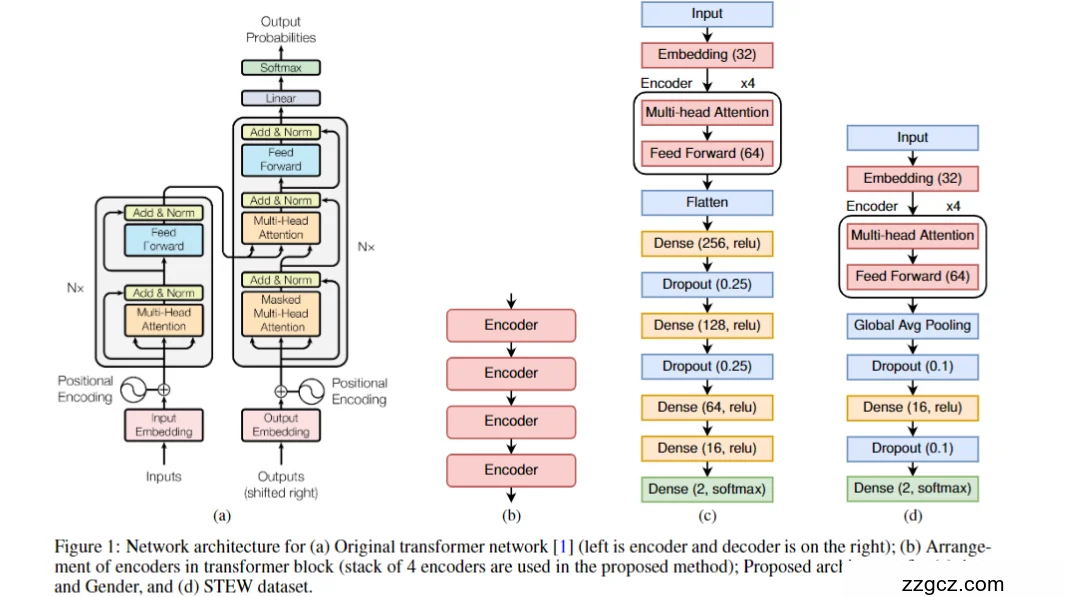
3.1 总体框架(图 a → b)
- 用的是“Encoder-only”的 Transformer:原始 Transformer 有“编码器+解码器”,但本文做分类任务,不需要自回归解码,所以只用编码器堆叠(去掉了解码器)。每个编码器都由 多头自注意力(MHA)+ 前馈网络(FFN) 两个子层组成,并在每个子层外有 残差连接 + LayerNorm(“加&归一化”)。
- 编码器堆叠的层数:4 层编码器串联(图 b)。
3.2 输入到编码器之前:两步“打包”
- Embedding(嵌入):把时序×通道切成片段/向量后,先投到32 维的嵌入空间。
- 位置编码(Positional Encoding):给每个输入向量加一个与嵌入同维的位置信号,然后与嵌入相加,提供时序上下文(注意:位置编码在本文被视为“预处理动作”,不是核心结构)。
这样进入编码器的就是:[32 维嵌入 + 位置编码] 的序列。
3.3 单个编码器的“积木规格”
- 多头自注意力(MHA):一次让任意两个片段“互相看到”。
- 前馈网络(FFN):两层全连接,隐藏维 64(论文给出的实现参数)。
- 残差 + LayerNorm:每个子层外包一圈,稳定训练。
- 注意力头数:默认 4 头;在 年龄 6 类任务里把注意力头增到 8,其余不变。
3.4 任务头(Head):两套“收尾工艺”
同一套 4×Encoder 主干后面,接两种不同的分类头(对应你图里的 c 与 d)。
(A) 年龄/性别(Age & Gender,图 c)
- 主干输出 → Flatten;
- Dense(256, ReLU) → Dropout(0.25);
- Dense(128, ReLU) → Dropout(0.25);
- Dense(64, ReLU) → Dense(16, ReLU);
- 输出层:
- 性别:Dense(2, Softmax);
- 年龄:把最后一层改为 Dense(6, Softmax),并把注意力头数调为 8。 这些层级与超参在图注中明示。
(B) 心理工作负荷 STEW(图 d)
- 主干输出 → Global Average Pooling(用全局均值代替 Flatten);
- Dropout(0.1) → Dense(16, ReLU) → Dropout(0.1);
- 输出层:
- 二分类(无任务 vs SIMKAP):Dense(2, Softmax);
- 三分类(SIMKAP 多任务):Dense(3, Softmax)(改最后一层神经元数即可)。 同样维度/层次写在图注。
3.5 一页式“超参备忘录”
- 嵌入维度:32;注意力头:4(年龄 6 类改 8);FFN 隐层:64。
- 编码器层数:4 层。
- 分类头(Age/Gender):Flatten → 256 → 128 → 64 → 16 → Softmax(2 或 6),含 Dropout(0.25)。
- 分类头(STEW):GAP → Dropout(0.1) → 16 → Dropout(0.1) → Softmax(2 或 3)。
- 说明:本文不使用解码器;位置编码在送入编码器前与嵌入相加。
4、模型的不足与限制(来自论文)
泛化性尚未被更广验证
作者在结论中直说:需要在更多数据集上做对比与复现,当前结果还需进一步验证。
位置编码并非为 EEG 量身定制
论文多次指出:本工作沿用通用位置编码,把它当预处理注入嵌入;这种非 EEG 专用的编码可能导致年龄/性别任务表现不够理想。作者也将此列为改进方向(设计EEG专属位置编码/嵌入)。
与更强基线相比,部分任务成绩仍有差距
在年龄/性别数据集上,Transformer 的效果“具有竞争力但并非最优”,作者把差距的一大原因归因于上面的位置编码/特征使用问题。
数据规模与设备配置的限制
两个实验集样本量较小(本地年龄/性别:60 名;STEW:48 名),且均采自14 通道、128 Hz 的 Emotiv 低密度设备。这限制了空间分辨率与跨设备泛化的可证性。
论文也强调 EEG 的固有缺陷(高噪声、个体差异大、空间分辨率低、伪迹多),预处理容易成为性能瓶颈——这些都会放大小样本、低通道设置下的难度。
任务范围相对单一
本文只在年龄/性别(静息态)与STEW 工作负荷两类场景上做了验证,尚未覆盖更广的 BCI/临床任务(如运动想象、癫痫检测、睡眠分期等的系统性评估)。这是论文研究设计的范围而非通用性结论。
训练设置在“小数据”条件下
数据按 70/15/15 划分训练/验证/测试。在总体被试数有限时,这种划分对结果稳定性与外部泛化的说服力带来约束(作者未声称跨数据库/跨设备迁移能力)。
未利用某些“更有效”的特征/策略
作者坦诚:本研究没有采用某些在特定场景下更有效的特征提取方法,可能也是年龄/性别表现不佳的原因之一;未来方向包括构建更稳健的 EEG 嵌入与专用位置编码。