EEGNet(2018):一种基于脑电图的脑机接口紧凑型卷积神经网络
1、研究背景和动机
1.1、为什么要研究 EEG(脑电图)模型
1)脑机接口(BCI)的目标
- 帮助截瘫患者控制机械手臂
- 协助病人拼写文字进行交流
- 甚至帮助健康人提升运动或操作效率
2)传统方法的痛点
- 先预设滤波器(只保留某些频率,比如 α 波 8-12Hz)
- 再提取空间特征(找哪些电极区域活跃)
- 最后用分类器判别
- 需要 大量领域知识(得知道哪个频段重要、哪块脑区活跃)。
- 每种任务都要重新设计流程(比如运动想象 vs. 视觉刺激信号完全不同)。
- 很可能把有用的隐藏信息滤掉了。
“过去科学家用放大镜一点点在 EEG 里找规律,每次换一个任务都要重新调放大镜角度,很费人力,还容易漏掉重要信息。”
3)深度学习的机会与挑战
- 以前的 CNN 架构是为图像设计的,参数巨大,需要海量数据训练;而 EEG 数据常常很少。
- 许多研究只针对单一类型任务(比如只做运动想象),难以泛化到其他脑机接口场景。
- CNN 提取的特征不易解释,难以让神经科学家理解大脑活动的含义。
1.2、EEGNet 的提出:紧凑、通用、可解释
痛点
| EEGNet 的解决思路
|
数据少
| 用 紧凑型网络(大幅减少参数量,甚至比 DeepConvNet 少 100 倍以上)
|
任務多樣
| 设计成 跨任务通用,能处理事件相关电位(ERP,如 P300/ERN/MRCP)和振荡类信号(SMR)
|
难解释
| 网络结构上借鉴经典 EEG 分析方法(如空间滤波、滤波器组),并设计可视化方法帮助理解模型学到的脑区与频率特征
|
如果说以前的 CNN 是“巨无霸机器”,需要大数据喂饱才能工作;EEGNet 就像是专门为脑电打造的“小型多功能瑞士军刀”,小巧但专业,既能适配不同任务,还能看清每把刀片的用途(可解释性)。
🌍 研究意义
- 实用性:即使在训练数据很少的情况下,EEGNet 也能保持较好性能,这对临床和实际应用很重要。
- 通用性:一个模型能处理多种脑机接口任务,减少为每个新实验重新设计网络的工作量。
- 科学解释:提供可视化方法,帮助神经科学家理解 CNN 学到的脑电特征,而不是“黑箱”。
🔑 小结
EEGNet 的研究动机就是: 让脑机接口模型更轻量、更通用、更可解释,摆脱传统人工特征提取的繁琐和深度学习模型的黑箱问题,让深度学习真正适应 EEG 这个小数据、任务多样的领域
2、EEGNet 的核心创新点
🌟 总体概念
🚀 创新点 1:极度紧凑的网络设计,适合小数据场景
- EEGNet 引入 深度卷积(Depthwise Convolution)+ 可分离卷积(Separable Convolution) 结构,大幅减少参数数量。
- 与常用的 DeepConvNet 和 ShallowConvNet 相比,EEGNet 的参数量最多能减少 两个数量级(如从十几万减到几千)。
- 这意味着即使只有少量 EEG 数据也能训练模型,不再需要海量样本。
形象比喻: 以前的模型像全能型重型机器,需要大量燃料(数据)才能运转;EEGNet 是一台专门为 EEG 定制的“省油小跑车”,小巧但高效。
🚀 创新点 2:跨任务的通用性
- EEGNet 并不是针对单一脑机接口任务设计,而是可以在 四种典型 BCI 范式上工作:
- 视觉诱发电位(P300)
- 错误相关负波(ERN)
- 运动相关皮层电位(MRCP)
- 感觉运动节律(SMR)
- 以往模型往往只适用于单一信号类型,而 EEGNet 证明了 同一个网络可以处理事件相关电位(ERP)和振荡类信号,具有很强的泛化能力。
比喻: 传统方法像专用工具(螺丝刀只能拧螺丝),EEGNet 像一把“多用瑞士军刀”,在不同任务都能直接上手。
🚀 创新点 3:结合经典 EEG 特征提取理念进行结构设计
- 网络结构灵感来自 EEG 传统分析方法,如 滤波器组共同空间模式(FBCSP) 和 最优空间滤波。
- 在时间卷积层学习不同频带的滤波器,再用深度卷积为每个频带学空间分布,这与传统的“先滤波、再空间滤波”步骤一致,但通过深度学习实现自动化。
- 这种设计让网络既继承了 EEG 分析的物理合理性,又能自动优化参数。
比喻: 把人类 EEG 专家的工作流程“数字化”并塞进神经网络里,让网络学得既聪明又符合神经生理逻辑。
🚀 创新点 4:增强的可解释性
- EEGNet 提出了 三种特征可视化方法:
- 隐藏单元激活分析(看不同类别下的时频特征差异)
- 卷积核权重可视化(理解时间滤波器和空间滤波器的意义)
- 单次试验特征相关性分析(用 DeepLIFT 解释每次预测依据)
- 这使得研究人员可以直接看到模型学到了哪些脑区、哪些频率的活动,确保结果不是噪声或伪影。
比喻: 以前 CNN 像“黑箱魔术师”,你不知道它怎么判断;EEGNet 把决策过程拆开,让科学家可以用“显微镜”去看它学到了哪些脑信号。
🚀 创新点 5:无需数据增强即可达到先进性能
- DeepConvNet 等大型模型往往需要复杂的数据增强(Data Augmentation)来防止过拟合。
- EEGNet 即使在小数据集上,也能在 组内(intra-subject)和跨被试(cross-subject)分类中表现良好,无需复杂预处理或数据增强。
🏆 核心创新总结表
创新方向
| EEGNet 的具体做法
| 意义
|
轻量化
| 深度卷积 + 可分离卷积,参数量比传统 CNN 小两个数量级
| 小数据也能训练;适合实际 BCI
|
通用性
| 单一架构可处理 ERP 与 SMR 等不同 EEG 任务
| 降低每次任务都重设计的成本
|
物理合理性
| 借鉴 FBCSP 与空间滤波思路
| 网络结构更符合脑电信号特性
|
可解释性
| 提出 3 种特征可视化与消融分析方法
| 揭示模型学习的神经生理含义
|
实用性
| 不需要大规模数据增强
| 适合医疗/实验等真实场景
|
🔑 一句话概括
EEGNet 的核心创新在于:用小巧高效的深度卷积架构,融合 EEG 经典特征提取理念,构建跨任务通用且可解释的脑电深度学习模型,让 BCI 更易用、更稳健、更可信。
3、EEGNet 的网络结构原理
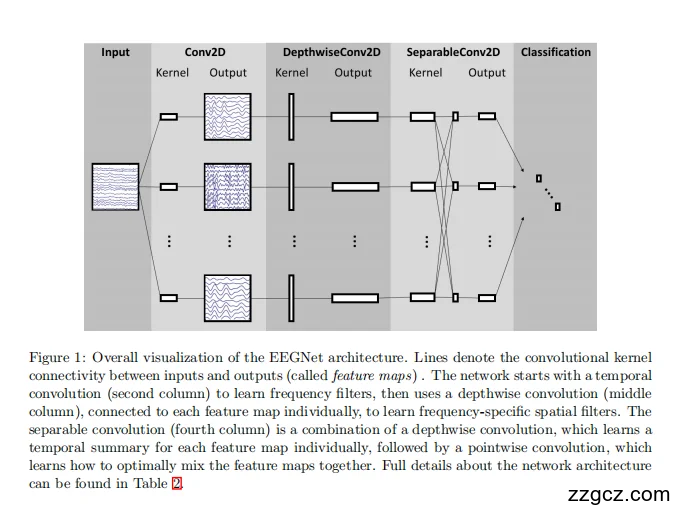
Input(输入)
- 形状是 (C, T):C 个电极通道、T 个时间点。实现里常把它 reshape 成 (1, C, T) 以便用 2D 卷积函数,但本质都是 “沿时间的一维卷积”
- 可以理解成:一摞并排的“脑电时间波形”。
Conv2D(时间卷积:学“频率滤波器”)
- 做什么:沿时间轴做一维卷积,学习一组“带通滤波器”,相当于自动学出 α/β/θ…等频段的通道内频率特征。
- 为什么这样设:时间核长度设为采样率的一半(例如 128 Hz 采样就用 64 个采样点),这样天然覆盖 ≥2 Hz 的频段,等于先给 EEG 做“均衡器/分频”
- 输出:得到 F1 张时间滤波后的特征图(每一张就是一个“频段视角”)
- 理解比喻:这一步像给音乐开均衡器,把整首歌切成低音/中音/高音三路分别听。
细节:卷积后接 BatchNorm,再做 ELU 非线性与 Dropout;这一步仍保持线性卷积核以贴合频率滤波的物理含义
DepthwiseConv2D(深度卷积:学“频率特定的空间滤波器”)
- 做什么:对上一步每一张“频段特征图”分别做“跨通道(跨电极)的卷积”,卷积核大小是 (C, 1),也就是一次性看所有电极,学这个频段在头皮上的空间分布(等价于“最优空间滤波”)
- D(depth multiplier):给每个频段学 D 个不同的空间滤波器,所以输出张数变成 D×F1
- 为什么这样设:它把“先分频→再做空间滤波”的经典做法(比如 FBCSP)直接神经网络化,而且因为是 depthwise,参数量少、每个频段各自学自己的空间模式,物理含义清晰
- 理解比喻:像给每个分频都配一套“天线权重”,看这个频段主要来自哪块皮层。
细节:加 最大范数约束(让空间滤波权重不发散)、平均池化 (1,4) 把采样率降到 32 Hz,随后接 Dropout 做正则
SeparableConv2D(可分离卷积:按时间做摘要 + 点卷积做融合)
- Depthwise(沿时间的深度卷积)
- 卷积核尺寸 (1, 16)(在 32 Hz 下约 0.5 s),对每一张特征图各自做时间汇总,提取“半秒级”的动态摘要
- Pointwise(1×1 点卷积)
- 再用 1×1 卷积在特征图之间做最优线性组合,把前面学到的“不同频段×不同空间模式”的信息有效混合;输出张数设为 F2(常用 F2 = D×F1)
- 为什么这样设:把“每张图先各自总结→再学会怎么加权混合”拆开做,既降参又可解释:你能区分“时间摘要学到了什么”和“特征图之间怎么混合”的作用
- 理解比喻:先让每个分频-空间视角写个 0.5 s 小结,再由“编辑(1×1 卷积)”把多份小结拼出最好的一版报道。
Classification(分类)
- 把特征 Flatten 成长度约为 F2 × (T//32) 的向量(累计两次池化后的时间长度),直接接 Softmax 输出 N 类概率;不用额外全连接层,以进一步减少自由参数和过拟合风险
- 实践中常见两种小配置:EEGNet-4,2、EEGNet-8,2(含义:F1=4/8,D=2),在多数据集上已证明能以极少的参数达到与大型 CNN 相当的效果,参数量可比传统 CNN 少两个数量级
整体“数据流”一眼看懂
为什么“小而强”
- 参数极少:大量用 depthwise / separable 卷积,避免“所有特征图彼此全连接”的巨量参数
- 贴合 EEG 机理:时间卷积≈分频;深度卷积≈空间滤波;可分离卷积把“时间摘要”和“跨特征混合”解耦——这些都与经典 EEG 方法(如最优空间滤波、FBCSP)一一对应,因此更稳健且可解释
4、模型的核心不足与局限
1. 数据依赖与泛化能力不足
- 跨被试性能依赖数据量 虽然 EEGNet 在组内(intra-subject)任务中表现出色,但在 跨被试(cross-subject)分析中,性能会受到训练数据规模限制。如果训练集太小,模型泛化到新受试者时效果会明显下降,需要比组内训练更多的样本才能达到相同的精度
- 个体差异难以完全克服 EEG 信号因头皮厚度、电极接触、脑区解剖差异等因素在个体间差异大,EEGNet 虽然在一定程度上减少了人工特征选择,但仍无法完全解决“每个人的脑电差异巨大”这一根本问题。
比喻:就像教一群人用同一辆自行车,但每个人的身高和习惯不同,车的调节能力有限,还是得单独微调。
对噪声与伪影的鲁棒性有限
- 易受非脑信号干扰 EEG 本身信噪比低,容易受眨眼、肌电、头部运动等伪影影响。虽然 EEGNet 的卷积层可以学到一定的抗噪能力,但与专门的伪影去除或稳健特征提取算法相比,仍缺少对干扰的明确抑制机制。
- 依赖预处理质量 EEGNet 仍假定输入信号经过合理的预处理(滤波、重参考等),如果数据质量较差,模型性能会显著下滑。
比喻:EEGNet 像是对干净的乐谱演奏很流畅,但如果乐谱上到处是噪点,它就容易跑调。
解释性仍有限度
- 可解释性不是完全透明
EEGNet 提供了滤波器可视化、特征消融和相关性分析等方法,让模型比普通 CNN 更可解释,但它仍是一个深度模型:
- 特征可解释性依赖于专家对脑电频段和空间分布的理解。
- 无法像线性模型那样直接得到“每个电极权重对应某个具体神经活动”的严格数学关系。
- 对非专家来说,卷积核和相关性图仍然抽象,不如传统 CSP 或频段功率特征直观。
比喻:EEGNet 已经把“黑箱”变成“半透明玻璃”,但要真正看懂里面的齿轮,还需要神经科学知识。
对任务类型的适应仍需调参
- 虽然通用,但仍需参数选择
EEGNet 被设计为跨任务通用,但其超参数(如时间核长度、滤波器数 F1、空间滤波器倍数 D、池化大小等)在不同范式下仍需调整。例如:
- ERP 任务和 SMR 任务的最佳时间卷积长度不同。
- 数据采样率不同,需要相应修改卷积核和池化步长。
- 这意味着模型并非“完全即插即用”,仍需要一定的经验和调优。
比喻:EEGNet 是“多功能瑞士军刀”,但要切肉、削木头时,还是要换刀片长度。
对数据增强和正则化仍有依赖
- 在大规模跨被试任务中,尽管 EEGNet 参数少,但在数据有限时仍可能过拟合,需要数据增强或正则化(如 Dropout、最大范数约束等)来提升泛化能力
- 相比专门设计的抗过拟合 CNN(如更强的数据增强管线),EEGNet 在数据极度稀缺时仍可能表现受限。
缺乏时序依赖建模
- EEGNet 主要通过卷积和池化提取时间局部特征,但缺少显式的长时依赖建模(如 RNN、Transformer 那样的全局时间上下文)。
- 对一些需要捕捉长时间动态变化的任务(如长时间注意力监测、慢变状态检测),它可能不如时序模型有效。
比喻:EEGNet 擅长看“几秒钟的短片段”,但要理解一部电影的完整剧情,还需要长程记忆机制。
5、EEGNet 的未来改进方向概览
- 增强时间序列建模能力
- 加入更强的长时依赖捕捉机制(如时间卷积堆叠、循环网络、Transformer 注意力)。
- 保留 EEGNet 的紧凑性,同时扩大时间上下文感受野。
- 引入多尺度与自适应特征提取
- EEG 信号包含多种时间频率成分(δ/θ/α/β/γ),后续模型通过多尺度卷积、不同感受野并行设计来更全面捕捉。
- 利用图神经网络 (GNN) 挖掘空间连接信息
- EEG 电极之间天然构成图结构,后续方法尝试用 GCN/GAT 等显式建模空间关系,而不是仅用深度卷积近似。
- 结合注意力机制与 Transformer
- 通过注意力来提升跨通道/跨时间的信息交互能力;增强模型对动态脑网络的适应。
- 提升跨被试泛化与小样本学习能力
- 加入领域自适应、迁移学习或对抗训练来减少个体差异的影响。
- 增强可解释性与临床可用性
- 使用可视化、注意力权重解释、或者结合神经解剖先验,使模型预测更易被神经科学家理解。
6、代表模型如何基于 EEGNet 演进
1. TSception (Temporal-Spectral Sception Network)
- 动机:EEGNet 的时间卷积核长度固定,难以同时捕捉不同频率成分;对时序特征提取不够灵活。
- 做法:
- 采用 多尺度时间卷积(短核提取快速动态,长核捕捉低频慢波),并在频域上用多组卷积并行捕捉 δ/θ/α/β 等不同节律。
- 仍保持类似 EEGNet 的深度可分离卷积设计来降低参数量。
- 优势:对跨任务 EEG 特征提取更鲁棒,尤其适合情感识别、认知负荷检测等需要多频段信息的场景。
类比:EEGNet 是单一镜头,TSception 则像“多焦镜头相机”,能同时拍远景和特写。
2. EEG-TCNet (EEG Temporal Convolutional Network)
- 动机:EEGNet 时间建模主要靠第一层卷积和池化,长时依赖不足。
- 做法:
- 用 Temporal Convolutional Network (TCN) 堆叠扩张卷积,感受野可指数扩展,从而覆盖更长的时间上下文。
- 保留 EEGNet 的深度卷积空间滤波部分,将时间建模与空间建模解耦。
- 优势:在需要长时间上下文的任务(如运动想象、连续状态监测)中,能比 EEGNet 提取更丰富的时序信息,同时保持较低参数量。
类比:EEGNet 像“只看几秒视频”,EEG-TCNet 给它加了“可看长剧情的时间放大镜”。
3. DAGCN (Dynamic Adaptive Graph Convolutional Network)
- 动机:EEGNet 用深度卷积近似空间滤波,但它假设电极排列是固定矩阵,无法自适应建模复杂的脑区连接。
- 做法:
- 将 EEG 电极视为图节点,用 自适应图卷积 (Adaptive GCN) 学习通道之间的动态连接权重。
- 同时结合时序卷积或注意力增强时间建模。
- 优势:能捕捉更真实的脑区交互模式,在跨个体和动态脑状态分析(如情绪、任务切换)中效果更佳。
类比:EEGNet 的空间滤波像是“静态天线阵列”,DAGCN 则是“自动调节的智能天线网络”。
4. EEG-Transformer
- 动机:EEGNet 缺少显式的长程依赖建模;卷积局限于局部时间窗口。
- 做法:
- 用 Transformer 编码器对时间序列建模,通过自注意力在所有时间点和通道之间建立全局依赖关系。
- 一些实现中先用类似 EEGNet 的前端卷积做低层时频提取,再送入 Transformer 提取全局动态。
- 优势:在需要整合长时间信息、复杂任务序列或跨试次上下文时性能更优;对大规模数据训练也更适用。
类比:EEGNet 是“看窗外的一段景色”,EEG-Transformer 是“卫星视角全局观察”,可以同时考虑全时段和所有通道关系。