LGGNet(2022):脑机接口中的局部-全局图表示学习
导出时间:2025/11/24 09:02:02
1、研究背景与动机
1.1 BCI/EEG 的老难题
- EEG 噪声重、个体差异大:眨眼、肌电、导联接触等伪迹很多;不同被试的脑电分布也不一样,建模很难稳定。
- 时空耦合强:同一电极的时间依赖 + 不同电极之间的空间依赖要一起学;只看时域或只看空域都容易丢信息。
- “全局 vs 局部”两头难兼顾:
- CNN/TSception 之类能抓时间动态,但把所有通道“摁成一锅粥”时,局部功能区的细粒度关系常被冲淡;
- 图神经网络(GNN)能建全局连接/自适应邻接,但很多做法弱化了功能区内部的局部活动模式,或只用距离/相关性这类“粗”关系。
1.2 关键科学直觉:大脑是“分区+协作”的层级网络
- 神经科学告诉我们:大脑有功能分区(额叶、顶叶、枕叶等),区内有局部回路,任务执行时各区还会协同。也就是说,**“区内强交互 + 区间有选择的互联”**才像真的脑。
- 因此,EEG 的空间建模不能只靠“全连接或全局相关性”,也不能只看“几何邻近”;需要把先验功能区(local)和跨区交互(global)同时放进模型。
1.3 差距与痛点(对现有方法的补位)
- 仅用卷积/时频:能学到多尺度时间特征,但跨功能区关系表达力不够。
- 仅用全局图:容易学到“谁都连谁”的粗连接,忽略区内细节;有的还把邻接固定死,难以适配不同被试/任务。
- 缺少“神经科学先验”的显式注入:很多图结构是为方便计算而定,并非根据功能区来划分与连接。
1.4 LGGNet 的核心动机
- 把神经科学先验落到结构上
- 先把电极按 10–20 系统和功能区划成若干局部图(Local),区内全连接以强化该区的共同活动;再在这些局部图之间构建全局图(Global),让模型去学跨区协同。这就把“像大脑一样组织”的偏置写进了网络。
- 时间×空间的解耦再耦合
- 先用多尺度一维卷积直接从原始 EEG 学时间/频率动态;用核级注意力融合把不同时间尺度的信息“加权拼好”;再把每个通道的时间表征作为图节点属性,进入“局部→全局”两级图过滤,完成时空的“先分后合”。这样既保留细粒度时间信息,又显式建模空间结构。
- 全局连接要“可学、因样本而变”
- 全局图不是写死的:先用样本级相似性构出基础邻接,再配一个可训练的注意力掩码去强调/抑制关键跨区边,从而让不同被试、不同任务下的“区间通路”能自适应变化。
- 一套架构,覆盖多种 BCI 任务
- 论文在注意力、疲劳、情绪、偏好四类任务、三个公开数据集上做了系统评估与消融,动机是验证“局部-全局图表示”的通用性与有效性,而不是只在单任务里调参取巧。
1.5 期望收益
- 精度与稳健性:区内聚合 + 区间选择性连接,帮助模型在小样本、跨被试差异下更稳。
- 可解释性:局部/全局邻接与注意力权重可视化,能直观看到“哪个功能区、哪些跨区通路”在起作用。
- 通用范式:把“神经科学先验”变成可复用的图定义与层级模块,方便迁移到更多 BCI 场景。
一句话总结:LGGNet 想解决的是“EEG 的时空统一建模缺乏神经科学结构感”。它把功能区的局部图和跨区的全局图一起学,把“像大脑那样组织”的先验写进网络,从而在多任务上取得更可靠的表现与更好的可解释性。
2、核心创新点总结
- “时间先学好,再做图”:多尺度时域卷积 + 核级注意力融合
- 先用并行的一维多尺度卷积学出不同时间/频率节律;再用核级注意力融合把多尺度特征按重要性加权整合,得到每个通道的时间表征作为“图节点特征”。这是整套方法的入口。
- 把“功能区”写进图:局部图过滤层(Local)
- 依据神经科学把电极分成若干功能区子图,区内采用全连接,并用注意力式的“局部过滤 + 区内聚合(平均)”得到每个功能区的隐藏表示,显式强化区内协同活动。
- 再学“区与区怎么协同”:全局图过滤层(Global)
- 先用样本级相似性矩阵作为全局邻接的基座,再引入可学习的注意力掩码(训练时反向传播更新)选择/抑制关键跨区连边,从而适配不同被试与任务下的全局交互。
- 三种“局部–全局”先验图,一套网络多任务泛用
- 给出通用(G)、额叶(F)、半球(H)三种图定义:通用图依 10–20 系统按功能区分组;额叶图进一步细化并利用额叶左右非对称先验;半球图在各功能区都加入左右对称子图。不同任务可选更合适的先验图。
- “时—图”两级协同的整张蓝图(方法论统一)
- 全结构由**时序学习模块(多尺度卷积 + 核级注意力)与图学习模块(Local→Global)**组成,数据流清晰、可替换,便于在不同 BCI 任务间迁移。图 1 对此做了总览示意。
- 与主流深度/图方法系统对比 + 嵌套交叉验证
- 和 DeepConvNet、EEGNet、TSception、RGNN、AMCNN-DGCN、HRNN、GraphNet 等广泛对比,并在三个公开数据集(注意力、疲劳、DEAP)与四类任务(注意力、疲劳、情绪、偏好)进行评估,统计显著性多数优于对手。
- 充分的消融实验,量化每个模块的“份额”
- 对核级注意力融合、局部图过滤、全局图过滤逐一移除做消融,直观看到性能跌幅,验证三块积木都在“出力”。
- 神经科学先验 → 可解释性输出
- 通过显著性图与学习到的邻接矩阵可视化,展示哪些功能区/跨区通路在不同认知任务中重要,增强模型的可解释性与分析价值。
- 设计细节贴合 EEG 物理意义
- 在时域分支用“功率—对数”式激活与池化,等价于学习经典 EEG 功率特征,但由网络端到端完成,兼顾可解释与性能。
- 方法定位:把“神经科学结构感”注入 GNN
- 论文明确把贡献总结为:提出 LGGNet;提出三类局部–全局图定义;做了大规模对比与消融,证明将神经科学先验融入图学习能显著提升 BCI 分类。
—— 一句话版:LGGNet 把“多尺度时间特征”与“功能区先验图”两级结合,先学区内、再学区间,还让全局连边可学习,从而在多任务上取得更稳更强、且更可解释的 EEG 表征。
3、模型的网络结构
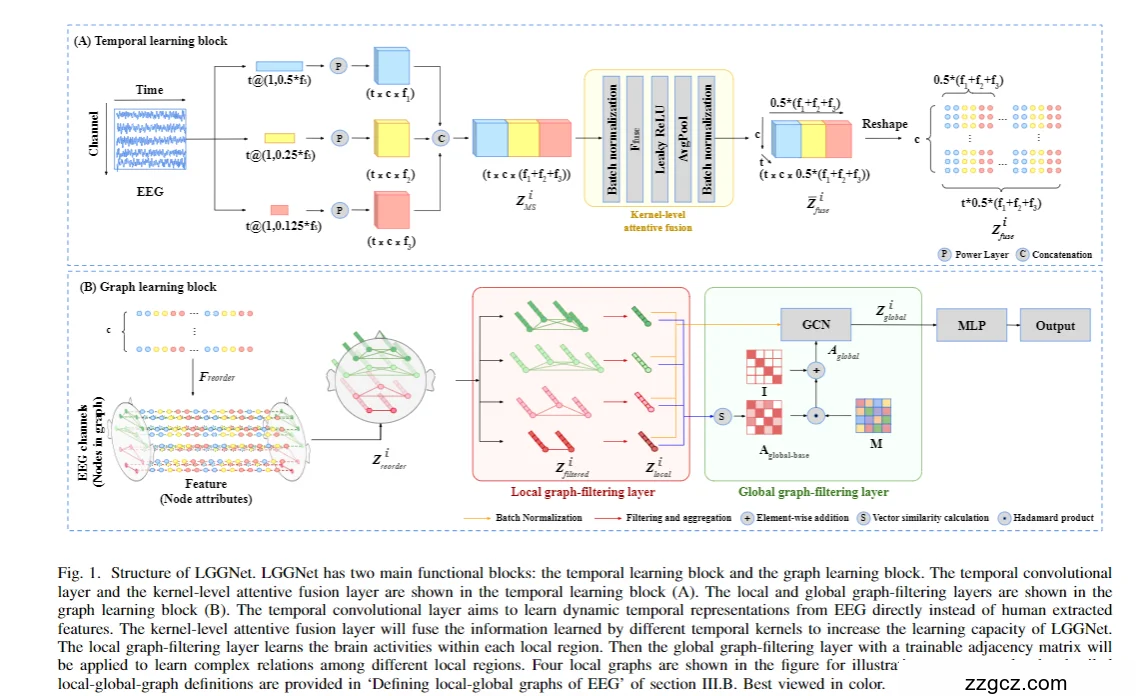
整体结构(一句话)
LGGNet 分两大块:①“时间学习块”把原始 EEG 逐通道变成更有判别力的节点属性;②“图学习块”先在每个功能区内做局部图过滤,再在功能区之间做全局图过滤,最后用 MLP 做分类。
(A) 时间学习块(Temporal learning block)
目的:直接从原始 EEG 里学到动态的时频特征(不用手工特征),并把每个通道的特征整理成后面图网络的“节点向量”。
- 并行多尺度一维卷积(Conv1D)
- 三条并行支路,卷积核长度按采样率 fsf_sfs 的比例取 0.5fs,0.25fs,0.125fs0.5f_s, 0.25f_s, 0.125f_s0.5fs,0.25fs,0.125fs(论文里记作 Q=0.5,K=3Q=0.5, K=3Q=0.5,K=3 的多级 T-kernels)。这相当于用不同“时间窗”去捕捉不同频段/节律。三支路在特征维拼接。
- 功率层(Power layer):每条支路的卷积输出先平方→短时平均池化(得到平均功率)→取对数(稳定方差、提升鲁棒性)。这一步就是把“滤波后的能量”喂给网络。
- 核级注意力融合(Kernel-level attentive fusion)
- 把三条支路的特征拼起来后,用逐点卷积(1×2) 做“核级注意力”以学会各尺度的权重;卷积前后都批归一化,中间用 LeakyReLU,再接平均池化降维。
- 重塑(reshape):把得到的张量按“通道为节点”重排,得到每个通道对应的节点属性向量,为后续图学习做准备。
小结:这块等价于“多尺度滤波 + 功率特征 + 注意力加权”,最后把每个电极变成一个向量节点。
(B) 图学习块(Graph learning block)
目的:显式描述“区内(局部)”和“区间(全局)”两层脑网络依赖。
B1. 局部-全局图的定义与通道重排
- 依据神经生理知识把电极分成若干局部图(功能区),并构建三套图:通用型、额叶型、半球型。它们共享思路:区内全连接、区间保留全局联系;为了聚合方便,先按局部图把通道重新排序。
B2. 本地图过滤层(Local graph-filtering)
- 邻接:每个局部图内完全连接(矩阵元素全为 1),假设同一区域的电极反映相似活动。
- 过滤(注意力):对每个节点属性做可训练的逐元素加权(Hadamard 乘积),再过 ReLU,得到带注意力的节点表示
- 聚合:把每个局部图内的节点向量做平均聚合,得到该功能区的一个隐藏向量 hrlocal;所有局部图堆成 Zlocali(维度 = “局部图个数” × “特征长”)。
B3. 全局图过滤层(Global graph-filtering)
- 实例级相似性作为“全局基邻接”:先用各局部图的隐藏向量做两两点积,得到对称的 Aglobal-baseA(R×R,R 为局部图个数)。这刻画“哪两个功能区在当前样本里更相似”。
- 可学习注意力掩码 MMM:为不同样本的全局关联再加一层可学习权重(对称矩阵)。实际邻接用 Hadamard 乘把 MMM 作用到基邻接上,再加自环并过 ReLU:
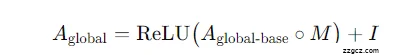
B4. 分类头
- 把 Zglobali(也可拼上局部/时间特征)送入 MLP,输出类别概率(对应你图右上的“MLP → Output”)。
把图和流程对应起来(阅读指引)
- 左上(A):三条多尺度 Conv1D → 功率层(平方/均值池化/取对数)→ 核级注意力融合 → reshape 成节点属性。
- 左下(B-Local):通道重排→本地图过滤(Hadamard 注意力 + ReLU)→平均聚合成各功能区向量。
- 右下(B-Global):各功能区向量做点积→ 得到 Aglobal-base乘以可学习掩码 MMM → +I、ReLU → GCN → MLP。
一句话记忆
“多尺度滤波提功率 → 注意力融合成节点 → 区内全连接 + 注意力聚合 → 区间相似性 + 可学习掩码 + GCN → MLP 分类”。这就是 LGGNet 的网络结构主线。