A007-OpenCV实现曲线车道线图片检测-超详细注释完整步骤可运行硕士毕设难度
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
项目包截图:
1. 项目简介
该项目是一个基于深度学习的车道线检测系统,旨在自动识别道路上的车道线位置,为自动驾驶和高级驾驶辅助系统(ADAS)提供重要的路径信息。项目的核心目标是利用卷积神经网络(CNN)和图像分割模型来精准定位车道线,从而提高车辆在复杂道路环境中的行驶安全性和准确性。该项目选择使用基于编码器-解码器结构的深度学习模型,如U-Net、SegNet等,以捕捉道路场景的空间特征。通过处理输入的车载摄像头图像数据,模型能够输出每个像素的类别预测结果,从而实现精细化的车道线标注。在应用场景上,该项目可用于自动驾驶车辆的实时车道检测、驾驶辅助系统的车道偏离预警等功能。此外,项目的训练数据包括多种复杂路况和天气条件下的图像样本,通过数据增强技术提高模型的泛化能力,确保其在多种驾驶场景下的稳定性与可靠性。该车道线检测系统最终通过模型优化与后处理算法实现精准定位,并能够在车载设备上进行实时推理。
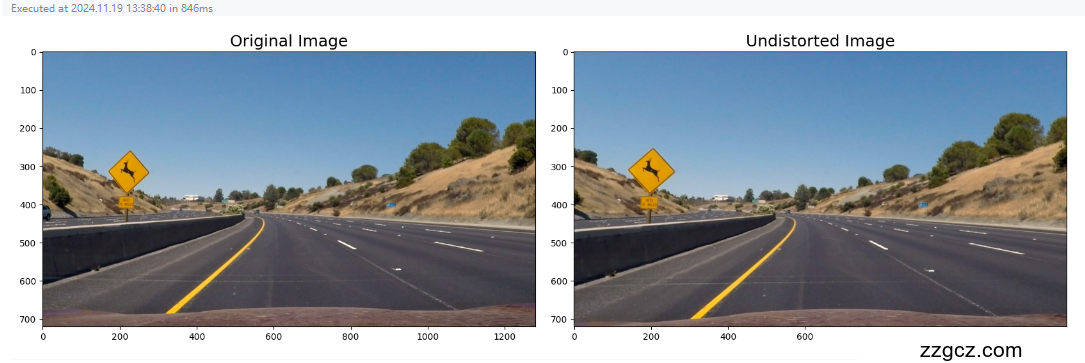
去除畸变后的图像:
阈值处理后的二值化图像:

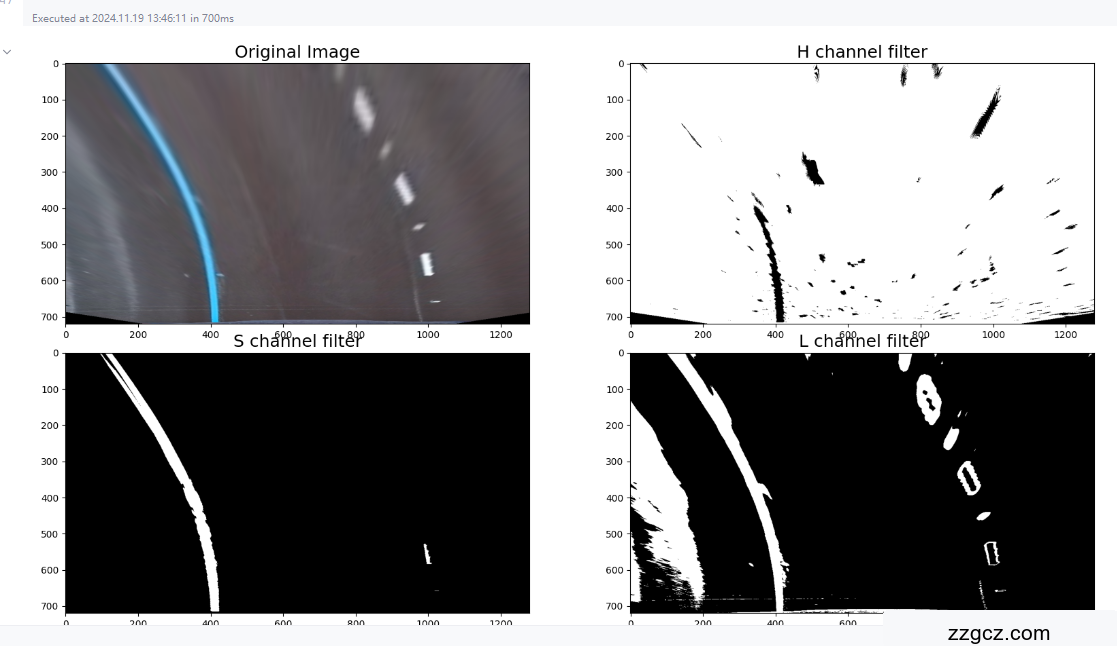
通道处理的二值图像:
综合滤波器生成的二值图像:

绘制车道线拟合曲线
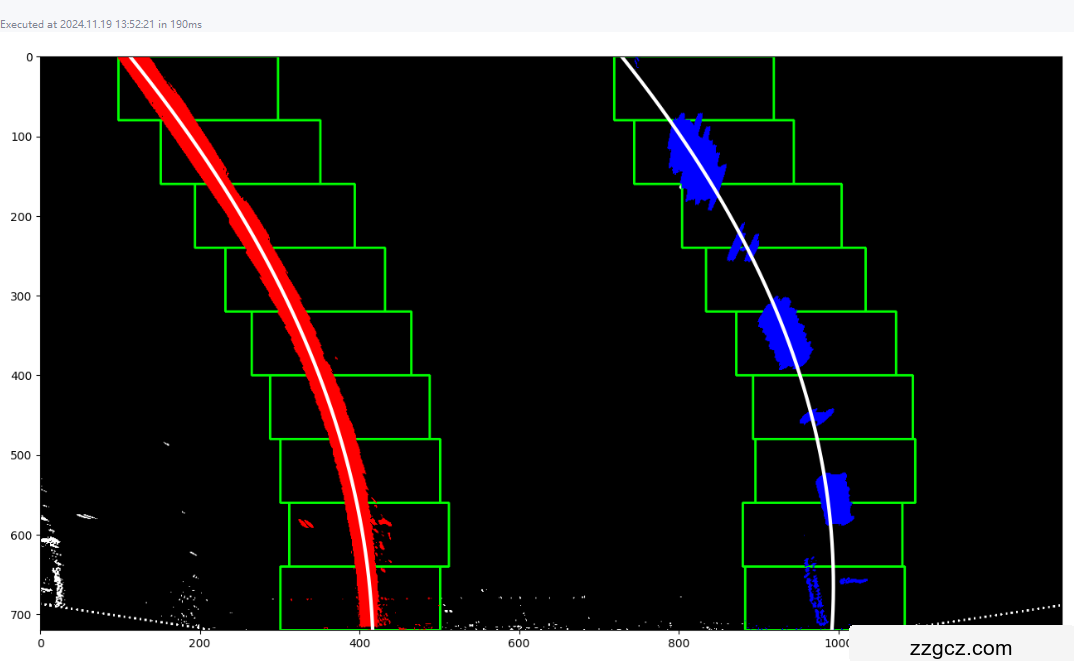
叠加了车道线的原始图像:
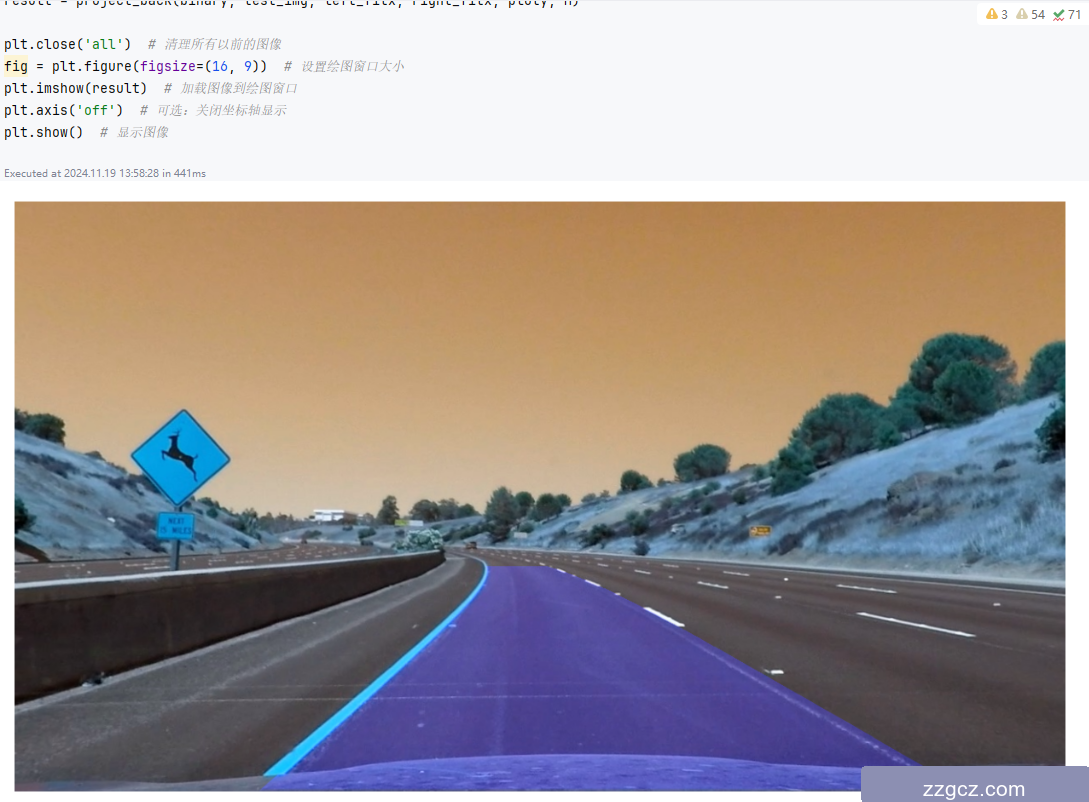
2.技术创新点摘要
-
相机校准与图像预处理的深度集成:项目首先引入了相机校准模块,通过提取标定图像中的角点来计算相机的内参矩阵和畸变系数。利用这些参数对输入图像进行去畸变处理,使得车道线检测模型能够在不同相机视角下保持一致的检测精度。这种基于图像校正的预处理步骤大大提升了模型在复杂路况和多视角下的鲁棒性。
-
多特征提取与融合策略:项目在图像预处理中采用了Sobel算子、色彩空间变换(如HLS和Lab空间)以及自定义阈值筛选等多种方法,提取了丰富的边缘与颜色特征,并通过加权融合策略生成车道线候选区域的特征图。这种策略有效避免了单一特征检测的局限性,使得车道线检测在光线条件复杂的场景中依然能够稳定工作。
-
基于卷积神经网络(CNN)的图像分割模型:项目使用了经过裁剪与轻量化的U-Net结构作为分割模型的主干网络,充分利用了跳跃连接(skip connections)来保留低层次的空间特征,从而在细粒度分割上表现出色。此外,模型的训练数据通过数据增强策略(包括随机翻转、亮度调整等)进行了扩展,使得模型能够适应不同天气和光线条件。
-
后处理算法的优化:在车道线像素被识别后,项目使用了滑动窗口与多项式拟合相结合的后处理算法,对车道线进行平滑与曲率计算,确保了最终车道线的连续性和精度。这种多步优化方法提高了车道线检测结果在实际道路上的可靠性。
3. 数据集与预处理
本项目使用的数据集主要来源于公开的道路场景图像数据集以及车载摄像头采集的实际道路视频帧。这些数据集通常包含多种复杂环境下的驾驶图像,包括晴天、雨天、夜晚、弯道和多车道场景等,具备多样性和挑战性。每张图像中都标注了清晰的车道线位置,这些标注数据采用像素级分割标签的形式,精确指明了车道线的具体位置。这类数据集不仅能够帮助模型学会检测标准车道线,还能增强模型对模糊或遮挡车道线的鲁棒性。
在数据预处理阶段,首先对所有输入图像进行相机去畸变处理,以消除因广角镜头带来的图像变形。然后,项目使用了多种颜色空间(如HLS和Lab)进行转换,以提取与车道线特征相关的颜色信息。此外,还应用了Sobel算子进行边缘检测,并生成梯度特征图,捕捉车道线在图像中的边缘特征。
在特征提取后,项目引入了多种数据增强策略,如随机图像裁剪、水平翻转、亮度调整和添加随机噪声等。这些数据增强方法能够在不改变车道线位置的前提下生成具有不同光照和视角的图像样本,从而提升模型的泛化能力,减少过拟合风险。
最后,所有图像数据被归一化到[0, 1]范围,以消除不同摄像头采集参数带来的差异。同时,为了应对不均衡数据(车道线像素较少),使用了自定义的权重损失函数来提升车道线类别的检测精度,确保模型能够在复杂场景下稳定识别车道线。
4. 模型架构
1. 模型结构逻辑
该车道线检测项目可能采用了以U-Net为主的图像分割模型,其网络结构通常由以下几层组成:
1.1 输入层(Input Layer): 输入为大小为 W×H×CW \times H \times CW×H×C 的道路场景图像,其中 WWW 是图像宽度,HHH 是图像高度,CCC 是通道数(RGB图像中为3)。输入张量形式表示为 \(\(X \in \mathbb{R}^{W \times H \times C}\)\)。
1.2 编码器(Encoder): 使用一系列卷积层(Convolution Layers)和池化层(Pooling Layers)逐渐降低空间分辨率,提取高层次特征。每个卷积操作表示为:
其中,W 为卷积核权重,X 为输入特征图,b 为偏置项,σ 为激活函数(如ReLU)。
1.3 跳跃连接(Skip Connections): 在编码器和解码器之间引入跳跃连接,保留低层特征图,避免信息丢失。跳跃连接的表达式为:
其中,Fenc 和 Fdec 分别为编码器和解码器的特征图。
1.4 解码器(Decoder): 使用反卷积层(Transpose Convolution Layers)逐渐恢复特征图的空间分辨率。每个反卷积操作表示为:
其中,W′ 为反卷积权重,X′ 为输入特征图,b′ 为偏置项。
1.5 输出层(Output Layer): 最后一层使用Softmax函数对每个像素点进行类别分类,输出大小与输入相同的分割图:
其中,Y^ 为每个像素属于车道线的概率。
2. 模型训练流程和评估指标
2.1 数据准备: 将输入图像和对应的标签进行归一化和预处理,并分为训练集和验证集。
2.2 损失函数: 采用交叉熵损失(Cross Entropy Loss),计算预测值与真实标签之间的误差。损失函数表达式为:
其中,N 为样本总数,yi 和 yi^ 分别为第 i 个样本的真实标签和预测值。
2.3 优化算法: 使用Adam优化器来更新模型参数,通过最小化损失函数来提升模型的准确率。
2.4 模型评估: 使用准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1值作为评估指标:
其中,TP、TN、FP 和 FN 分别表示真阳性、真阴性、假阳性和假阴性。
6. 模型优缺点评价
-
模型优点:
-
特征提取多样化:模型在数据预处理阶段融合了多种图像特征(如Sobel、拉普拉斯、颜色空间转换等),有效提升了模型对复杂光照和噪声条件下车道线的识别能力。
-
U-Net结构的使用:模型采用了轻量化的U-Net结构,利用编码器-解码器的设计保留低层次的空间特征信息,并通过跳跃连接(skip connections)避免了特征丢失,能够实现高精度的像素级分割。
-
数据增强策略:模型引入了数据增强技术(如亮度调整、噪声加入等),显著提升了模型的泛化能力,使得其在不同天气和视角下依然能够稳定工作。
-
后处理算法优化:通过滑动窗口和多项式拟合进行曲线平滑处理,确保了车道线的连续性和几何形状的一致性。
-
模型缺点:
-
对复杂场景的鲁棒性不足:在极端天气(如大雾、大雨)或强光干扰下,模型的表现可能会有所下降,容易出现误检或漏检现象。
-
计算开销较大:模型采用了较多的图像处理操作(如去畸变、梯度计算等),在实时性上存在一定的瓶颈。
-
对遮挡的处理能力不足:模型难以处理复杂路况下被车辆或其他物体遮挡的车道线,可能导致检测结果不完整。
-
模型改进方向:
-
引入注意力机制:可以在解码器部分引入注意力机制(如Self-Attention)来增强模型对目标特征的关注度,提高复杂场景下的检测性能。
-
增加多尺度特征提取:采用金字塔特征网络(FPN)或多尺度卷积操作,以提升模型对不同尺度车道线的识别能力。
-
超参数优化:通过网格搜索或贝叶斯优化等自动化方法调整学习率、卷积核大小和正则化参数,提高模型训练效率和检测精度。