A009算法创新改进版DenseNet集成SE模块实现猴痘病图像分类效果大幅提升
视频课程:https://www.bilibili.com/video/BV1czyeYnEUH/
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
项目包截图:
1. 项目简介
该深度学习项目旨在利用卷积神经网络(CNN)对图像进行分类。项目中使用了经过优化的DenseNet模型,并结合了SE模块(Squeeze-and-Excitation)来增强模型的通道注意力机制,从而提升特征提取能力。整个项目采用了PyTorch作为主要框架,主要应用场景是图像分类任务,能够识别多种类别的图像,并且通过自定义数据增强策略、分层特征提取、模型压缩等手段提高模型的训练效率与准确性。训练数据来自本地的图像文件夹,通过数据增强处理(如调整尺寸、归一化、水平翻转等)后,送入模型进行训练和验证。模型经过Dense Block和Transition层的交替堆叠,最终使用全局自适应平均池化和线性层进行分类预测。项目目标是在不牺牲模型性能的情况下,提升计算效率,并且通过模块化设计,能够方便地扩展到其他场景,如图像分割、目标检测等。本项目适用于学术研究和工业应用场景,能够在小数据量的情况下有效地完成图像分类任务,并输出高质量的分类结果。
2.技术创新点摘要
-
DenseNet与SE模块的结合:项目使用了DenseNet网络结构,并在每个Dense Layer中集成了SE模块(Squeeze-and-Excitation)。DenseNet通过稠密连接的方式,将前面层的所有特征映射传递给后续层,从而避免了梯度消失问题,并实现了高效的特征复用。而SE模块则通过全局自适应池化和通道权重的重新分配,增强了模型对重要特征的关注度。这种结合可以提升模型在处理复杂图像数据时的表征能力和分类效果。
-
使用自定义的层设计与Efficient Memory机制:项目通过自定义了Dense Layer和Transition模块的构建,并在关键层次中引入了内存效率优化机制(Efficient Memory)。这种设计允许模型在计算过程中动态分配内存资源,尤其在处理大规模数据集时,可以显著减少内存消耗,从而保证模型的稳定性与高效性。
-
自适应模块化设计:模型通过参数化的方式设置了多个Dense Block和Transition层的堆叠,能够根据不同数据集和任务需求进行自由组合与调整。同时,每个Dense Block的输入特征维度、增长率(Growth Rate)和压缩率(Compression Ratio)均可根据实际情况灵活配置,使得模型在保持较高精度的同时能够适配不同规模的计算资源。
-
数据增强策略与优化:项目采用了一套完整的数据预处理与增强策略,包括调整图像尺寸、归一化以及随机水平翻转等,使得模型在数据量较少的情况下仍能保持良好的泛化能力。此外,通过引入学习率调度器和交叉熵损失函数,并结合Adam优化器对模型进行训练,确保了模型的快速收敛和稳定的性能输出。
-
多层次的SE-Block应用与分类层设计:在模型的特征提取和分类阶段,项目在每个Dense Layer中引入了SE模块,用以强化局部特征的重要性,并最终通过全局自适应池化层和线性分类器进行输出。该设计能够在多个层次上优化特征权重分配,使得模型对不同类别的判别能力更为精细。
3. 数据集与预处理
本项目使用的图像数据集来源于本地文件夹,按类别进行组织和存储。每个类别的图像分别存储在不同的文件夹中,这种结构方便使用torchvision.datasets.ImageFolder进行数据加载与标签生成。数据集包含多个不同类别的图像,经过项目中的预处理策略后被划分为训练集和测试集。项目在数据加载时,将80%的数据用于训练,20%用于测试,以确保模型在训练阶段有足够的样本量,同时能够在测试集上评估模型的泛化能力。
数据预处理流程:
-
图像归一化与尺寸调整:所有输入图像都被统一调整到224x224像素的尺寸,确保模型能够接受大小一致的输入。接着对图像进行归一化处理,使其像素值被标准化到[0,1]范围内。标准化过程中使用了预定义的
mean([0.485, 0.456, 0.406])和std([0.229, 0.224, 0.225])参数,这些参数基于通用图像分类数据集(如ImageNet)计算得出,有助于模型更快地收敛。 -
数据增强策略:为了提升模型的泛化能力和应对小样本数据集的过拟合问题,项目在训练集中引入了数据增强策略。常用的数据增强方法包括随机水平翻转(提高模型对图像左右变化的鲁棒性)、随机裁剪(模拟不同视角下的场景)等。数据增强在仅使用基本图像数据的情况下,能够有效增加数据的多样性,使模型在训练过程中能够学习到更多潜在的特征。
-
特征工程:项目中并未使用显式的特征工程,而是依赖模型自身的深度学习网络结构(DenseNet与SE模块)进行自动特征提取和学习。通过引入通道注意力机制,模型可以动态分配不同通道特征的重要性,从而提升特征提取的有效性。
4. 模型架构
1. 模型结构逻辑
本项目使用了改进版的DenseNet网络,并在Dense Layer中加入了SE模块。DenseNet模型由多个DenseBlock和Transition层级联而成,通过稠密连接机制实现高效的特征传递与复用,从而提升模型的特征表示能力。以下是模型各层结构及其数学公式:
-
输入层:
-
输入图像尺寸:
(Batch_Size, 3, 224, 224)。 -
输入通道数为3(RGB通道),经过卷积层(
conv0)后转为num_init_features(初始通道数为64)的特征映射。 -
Dense Block:
-
每个
DenseBlock由多个稠密层(Dense Layer)堆叠组成。 -
在每个稠密层中,输入特征
x_l经过如下操作(公式): -
\[H_l = W_2 \cdot \text{ReLU}(\text{BN}(W_1 \cdot \text{ReLU}(\text{BN}(x_l))))\]
-
其中,
BN表示Batch Normalization,ReLU为激活函数,W_1为第一个1x1卷积核,W_2为3x3卷积核。H_l为该稠密层生成的新特征映射。 -
所有前面层输出的特征映射被级联传递给当前层,使得当前层的输入为所有前层输出的级联(
Concat(x_1, x_2, ..., x_(l-1)))。 -
SE模块(Squeeze-and-Excitation Block):
-
SE模块引入了通道注意力机制,通过全局池化和通道间自适应权重的分配来增强特征的表达能力。其公式如下:
-
\[s = F_{sq}(x) = \frac{1}{H \times W} \sum_{i=1}^{H} \sum_{j=1}^{W} x_{i,j}\]
-
其中,
F_{sq}为全局平均池化操作,将输入特征图x的通道维度进行全局压缩。之后通过全连接层(FC)、ReLU和Sigmoid函数得到通道权重,并通过以下公式重新分配特征权重: -
\[\hat{x} = x \cdot \sigma(W_2 \cdot \text{ReLU}(W_1 \cdot s))\]
-
其中,
W_1和W_2为FC层的权重矩阵,σ为Sigmoid函数,s为全局特征权重。 -
Transition Layer:
-
每个Dense Block之间使用Transition Layer进行特征压缩,防止特征维度过高。其具体操作为:
-
\[x_{out} = \text{AvgPool}(\text{ReLU}(\text{BN}(W_{trans} \cdot x)))\]
-
其中,
W_{trans}为1x1卷积层,AvgPool为2x2平均池化层。 -
分类层:
-
最后通过全局自适应平均池化(Adaptive Average Pooling)将特征映射压缩为
1x1大小,再通过一个全连接层(Linear Layer)完成分类: -
\[y = \text{softmax}(W_{fc} \cdot x_{flatten})\]
-
其中,
W_{fc}为线性层的权重矩阵,x_{flatten}为展平后的输入特征。
2. 模型的整体训练流程与评估指标
训练流程:
-
数据加载与预处理:将输入数据按80%与20%比例划分为训练集和测试集。图像数据经过归一化和数据增强(包括图像缩放、随机水平翻转等)处理后,以批量形式输入模型。
-
模型初始化与参数设置:模型使用
DenseNet结构,通过设定初始通道数、Dense Block层数、增长率(Growth Rate)等参数进行初始化。采用了Adam优化器,初始学习率设定为1e-4。 -
训练与反向传播:
-
在每个训练周期(Epoch)中,模型逐批读取数据,经过前向传播计算预测结果。
-
使用交叉熵损失(CrossEntropyLoss)函数计算预测值与真实标签之间的差距,并进行反向传播(Backpropagation)更新模型权重。
-
评估与模型保存:
-
每个Epoch结束后,在测试集上进行验证,计算准确率(Accuracy)与损失(Loss)。
-
记录最佳模型(以测试集准确率为评判标准),并保存最佳模型参数。
评估指标:
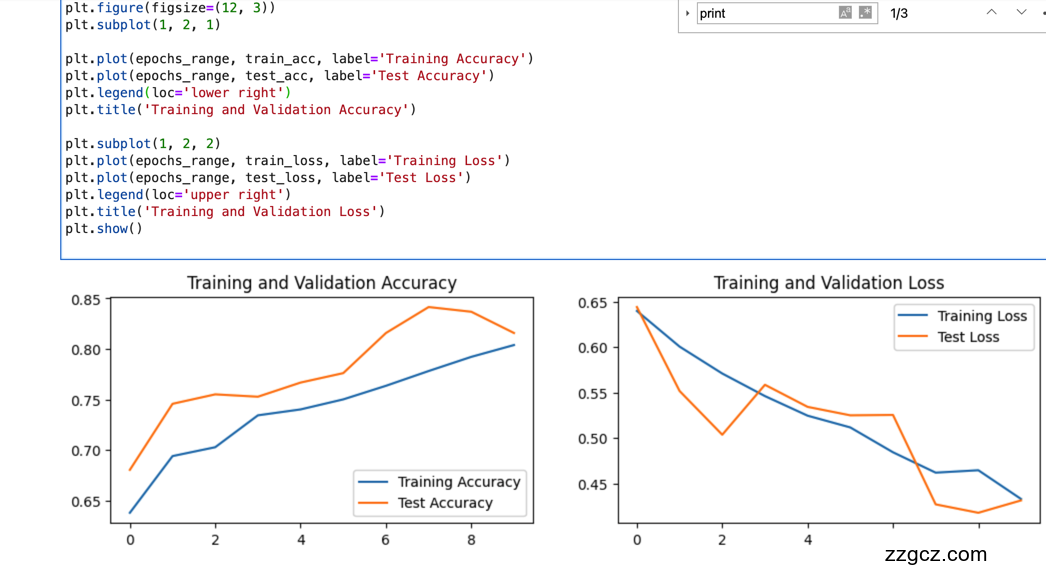
- 训练准确率与测试准确率(Training & Test Accuracy):衡量模型在训练集和测试集上的分类能力。其公式为:
- 训练损失与测试损失(Training & Test Loss):衡量模型在训练集和测试集上的损失值,使用交叉熵损失(Cross Entropy Loss)计算:
其中,y_i为实际类别的one-hot编码,hat{y_i}为模型预测的概率分布。
- 学习率(Learning Rate):每个Epoch结束时记录当前学习率,以确保学习率在优化过程中动态调整。
5. 核心代码详细讲解
5.1、模型构建
-
导入模块和库:
-
from collections import OrderedDict:导入OrderedDict,用于创建有序的字典,确保模块按添加顺序执行。 -
import torch.utils.checkpoint as cp:导入PyTorch的checkpoint模块并重命名为cp,用于实现梯度检查点机制,节省内存。 -
import torch.nn.functional as F:导入PyTorch的函数式接口模块,并重命名为F,提供诸如激活函数、池化函数等操作。 -
import torch:导入PyTorch库,进行张量操作和深度学习模型构建。 -
torch.cuda.empty_cache():清空CUDA缓存,释放未使用的显存。 -
import torch.nn as nn:导入PyTorch的神经网络模块,并重命名为nn,包含各种神经网络层和损失函数。 -
定义辅助函数
_bn_function_factory: -
该函数用于创建一个组合了批归一化(BatchNorm)、ReLU激活和卷积操作的函数,作为密集层的一部分。
-
torch.cat(inputs, 1):在通道维度上拼接输入特征。 -
依次应用批归一化、ReLU激活和卷积操作,生成瓶颈层的输出。
-
定义
_DenseLayer类: -
该类代表DenseNet中的一个密集层,包含两次批归一化、两次ReLU激活、两次卷积操作,以及一个SE注意力模块。
-
add_module方法用于将各层添加到模块中。 -
forward方法定义了前向传播过程,使用检查点机制(如果启用)来节省内存,并在最后应用dropout(如果设置了dropout概率)。 -
定义
_Transition类: -
该类代表DenseNet中的过渡层,用于特征图的压缩和尺寸缩小。
-
包含批归一化、ReLU激活、1x1卷积和2x2平均池化操作。
-
定义
_DenseBlock类: -
该类代表DenseNet中的一个密集块,由多个密集层组成。
-
在初始化过程中,根据
block_config中的层数,依次添加密集层。 -
forward方法将初始特征输入到每个密集层中,并将新特征拼接到特征列表中,最终在通道维度上拼接所有特征。 -
定义
SE_Block类: -
该类实现了Squeeze-and-Excitation(SE)块,用于通道注意力机制。
-
包含全局平均池化和两个全连接层,通过Sigmoid激活生成每个通道的注意力权重,并将其应用到输入特征上。
-
定义
DenseNet类: -
该类实现了DenseNet模型,包括多个密集块和过渡层。
-
在初始化过程中,首先定义初始卷积层(根据输入图像尺寸选择不同的卷积核大小)。
-
依次添加密集块和过渡层,根据
block_config配置每个密集块的层数。 -
最后添加批归一化层和全连接层,用于分类任务。
-
forward方法定义了前向传播过程,包括通过所有特征层、ReLU激活、全局平均池化、展平和全连接层。 -
实例化和配置模型:
-
创建
DenseNet实例,设置生长率、密集块配置、初始特征数、压缩率、批归一化扩展因子、dropout概率、分类数和是否启用高效计算。 -
检查CUDA是否可用,并设置设备为GPU或CPU。
-
将模型移动到指定设备上。
-
打印当前使用的设备信息。
5.2、模型训练
-
导入模块和库:
-
import copy:导入copy模块,用于对象的深拷贝(deepcopy),确保复制后的对象与原对象完全独立。 -
定义训练函数
train: -
参数:
-
dataloader:训练数据加载器,提供训练数据的批次。 -
model:待训练的神经网络模型。 -
loss_fn:损失函数,用于计算预测结果与真实标签之间的差距。 -
optimizer:优化器,用于更新模型参数以最小化损失函数。
-
-
过程:
-
获取训练集的总样本数量和批次数量。
-
初始化训练损失 (
train_loss) 和训练准确率 (train_acc)。 -
遍历训练数据加载器中的每一个批次:
-
将输入数据 (
X) 和标签 (y) 移动到指定设备(GPU或CPU)。 -
将输入数据传入模型,获取预测结果 (
pred)。 -
计算预测结果与真实标签之间的损失。
-
清除优化器中累积的梯度,执行反向传播计算梯度,更新模型参数。
-
计算并累加当前批次的准确率和损失。
-
计算整个训练集的平均准确率和平均损失。
-
返回训练集的准确率和损失。
-
-
定义测试函数
test: -
参数:
-
dataloader:测试数据加载器,提供测试数据的批次。 -
model:待评估的神经网络模型。 -
loss_fn:损失函数,用于计算预测结果与真实标签之间的差距。
-
-
过程:
-
获取测试集的总样本数量和批次数量。
-
初始化测试损失 (
test_loss) 和测试准确率 (test_acc)。 -
使用
torch.no_grad()上下文管理器,禁用梯度计算,节省内存和计算资源。 -
遍历测试数据加载器中的每一个批次:
-
将输入数据 (
imgs) 和标签 (target) 移动到指定设备。 -
将输入数据传入模型,获取预测结果 (
target_pred)。 -
计算预测结果与真实标签之间的损失。
-
计算并累加当前批次的准确率和损失。
-
计算整个测试集的平均准确率和平均损失。
-
返回测试集的准确率和损失。
-
-
定义优化器和损失函数:
-
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4):- 使用Adam优化器,优化模型的所有参数,学习率设置为0.0001。
-
loss_fn = nn.CrossEntropyLoss():- 定义交叉熵损失函数,适用于多分类任务。
-
设置训练参数和记录变量:
-
epochs = 10:设置训练的总轮数为10。 -
初始化四个列表
train_loss、train_acc、test_loss、test_acc,用于记录每个训练轮次的训练和测试损失及准确率。 -
best_acc = 0:初始化最佳测试准确率为0,用于保存性能最好的模型。 -
训练和测试循环:
-
使用
for epoch in range(epochs):循环遍历每一个训练轮次:-
训练阶段:
-
model.train():将模型设置为训练模式,启用如Dropout和BatchNorm的训练行为。 -
调用
train函数,传入训练数据加载器、模型、损失函数和优化器,获取本轮次的训练准确率和损失。 -
测试阶段:
-
model.eval():将模型设置为评估模式,禁用如Dropout和BatchNorm的训练行为。 -
调用
test函数,传入测试数据加载器、模型和损失函数,获取本轮次的测试准确率和损失。 -
保存最佳模型:
-
如果本轮次的测试准确率高于之前的最佳准确率,则更新
best_acc并使用copy.deepcopy(model)深拷贝当前模型,保存为best_model。 -
记录和打印结果:
-
将本轮次的训练和测试准确率及损失分别添加到对应的记录列表中。
-
从优化器的状态字典中提取当前的学习率。
-
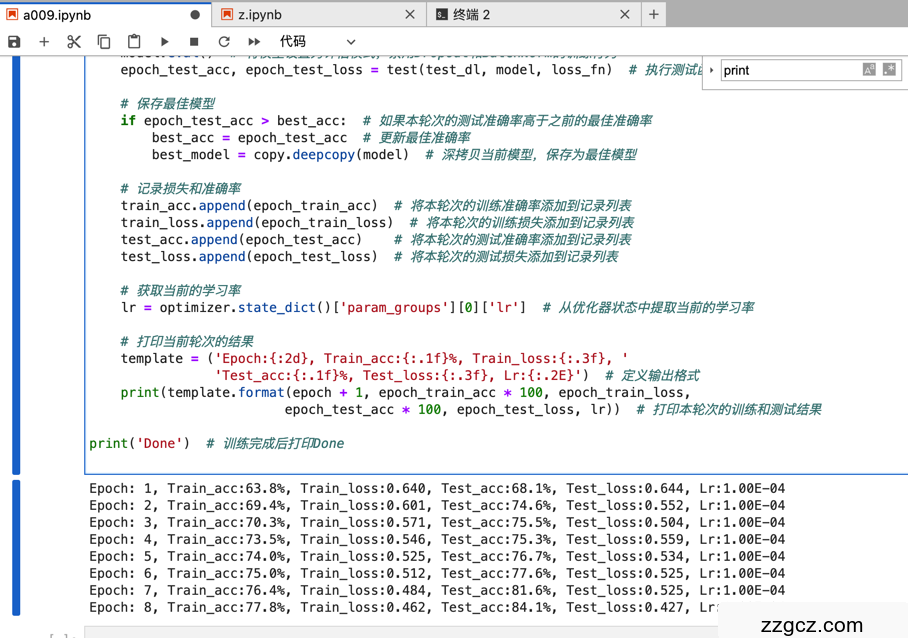
使用预定义的
template字符串格式化输出本轮次的训练和测试结果,包括轮次编号、训练准确率、训练损失、测试准确率、测试损失和当前学习率。
-
-
训练完成提示:
-
print('Done'):在所有训练轮次完成后,打印“Done”以示训练结束。 -
优化器
torch.optim.Adam: -
Adam优化器结合了动量和自适应学习率调整,能够在大多数情况下提供良好的收敛速度和性能。
-
学习率 (
lr=1e-4) 是优化器的重要超参数,决定了每次参数更新的步长。过大的学习率可能导致训练不稳定,过小的学习率则可能导致收敛速度过慢。 -
损失函数
nn.CrossEntropyLoss: -
适用于多分类问题,结合了
LogSoftmax和NLLLoss(负对数似然损失)。 -
输入为未经过softmax的模型输出(logits),以及目标标签的索引。
-
模型模式
model.train()和model.eval(): -
model.train():启用训练模式,启用Dropout层和BatchNorm层的训练行为。 -
model.eval():启用评估模式,禁用Dropout层,并使用BatchNorm层的统计量而非批次统计量。 -
梯度检查点机制(未在此代码中使用):
-
在之前定义的DenseNet模型中启用了梯度检查点(
efficient=True),这有助于在训练大型模型时节省显存,但会增加计算开销。 -
学习率调整(未在此代码中实现):
-
在实际应用中,可能需要根据训练进展动态调整学习率,例如使用学习率调度器(
torch.optim.lr_scheduler)来在训练过程中逐步降低学习率,以提高模型的收敛效果。 -
保存和加载最佳模型:
-
代码中使用
copy.deepcopy(model)保存了性能最好的模型,但在实际应用中,通常会将模型状态字典(model.state_dict())保存到文件中,以便后续加载和使用。 -
准确率计算:
-
(pred.argmax(1) == y).type(torch.float).sum().item():-
pred.argmax(1):获取预测结果中概率最高的类别索引。 -
== y:与真实标签进行比较,得到一个布尔张量,表示预测是否正确。 -
.type(torch.float):将布尔张量转换为浮点数(True为1.0,False为0.0)。 -
.sum().item():计算正确预测的总数,并将其转换为Python标量。
-
-
深拷贝模型:
-
best_model = copy.deepcopy(model):创建模型的深拷贝,以确保在后续训练中模型参数的变化不会影响已保存的最佳模型。
6. 模型优缺点评价
优点:
-
DenseNet与SE模块的结合:模型在DenseNet的基础上集成了SE(Squeeze-and-Excitation)模块,有效增强了模型的通道注意力机制,从而提升了特征表达能力。SE模块能够自适应地为每个通道分配权重,使模型在捕捉关键特征时表现更好。
-
高效的特征复用:DenseNet通过稠密连接的方式,将前一层的所有特征映射传递到后续层,减少了参数量,避免了信息丢失,同时提升了梯度传递的稳定性,减轻了梯度消失问题。
-
灵活的模块设计:DenseNet的各个层数、增长率、压缩率等参数可灵活配置,允许根据不同任务需求进行调整。项目中使用了自定义的Dense Layer、Transition层和SE Block,模型结构具备很强的可扩展性和自适应性。
缺点:
-
计算复杂度较高:由于DenseNet中的稠密连接会导致每层的输入特征图数量迅速增加,使得在较深网络中计算量和内存需求显著增加,不适合特别大型的数据集。
-
SE模块可能导致延迟:虽然SE模块提高了模型性能,但在每个Dense Layer中加入SE模块会增加额外的计算开销,导致模型推理速度下降,特别是在实时应用场景中。
-
对数据依赖性强:模型性能依赖于输入数据的质量和多样性。在数据分布不均衡或数据量较少时,模型可能表现出过拟合问题。
改进方向:
-
模型结构优化:可以尝试减少Dense Layer的数量或调整Dense Block与Transition Layer的排列方式,以降低模型的参数量和计算复杂度。
-
超参数调整:通过优化增长率(Growth Rate)、压缩率(Compression Rate)和Dropout比率来平衡模型的复杂度与性能。