A037-手写解剖Densenet模型网络结构实现图像分类CIFAR-10数据集pytorch
视频课程:https://www.bilibili.com/video/BV19JyLYnEAS
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
1. 项目简介
在深度学习领域,尤其是计算机视觉任务中,卷积神经网络(CNNs)的发展一直是研究的热点。随着网络深度的增加,模型能够学习到更加复杂和抽象的特征,从而在各种视觉任务中取得了显著的性能提升。然而,随着网络深度的增加,也带来了一系列问题,如梯度消失/爆炸问题、网络退化问题等。
为了解决这些问题,研究者们提出了多种策略。其中,ResNet(残差网络)通过引入残差连接(residual connections),允许网络在训练过程中学习到残差映射,而不是直接学习到未参考的映射,从而有效地解决了深度网络的退化问题。ResNet的出现极大地推动了深度网络的发展,使得构建非常深的网络成为可能。
然而,ResNet虽然解决了深度网络的退化问题,但并没有充分利用网络中各层之间的信息流动。为了进一步提高网络的信息流动和特征重用,DenseNet(密集连接网络)被提出。DenseNet通过密集连接(dense connections),每一层的输入都是前面所有层的输出的拼接,这样不仅增强了特征的传递,还鼓励了特征的重用,减少了参数的数量,从而在一定程度上缓解了过拟合问题。
因此,ResNet和DenseNet代表了两种不同的网络设计哲学:ResNet侧重于通过残差学习来构建更深的网络,而DenseNet则侧重于通过密集连接来增强特征的重用和信息的流动。这两种网络结构在计算机视觉领域都有着广泛的应用,并且在不同的任务和数据集上展现出了各自的优势。
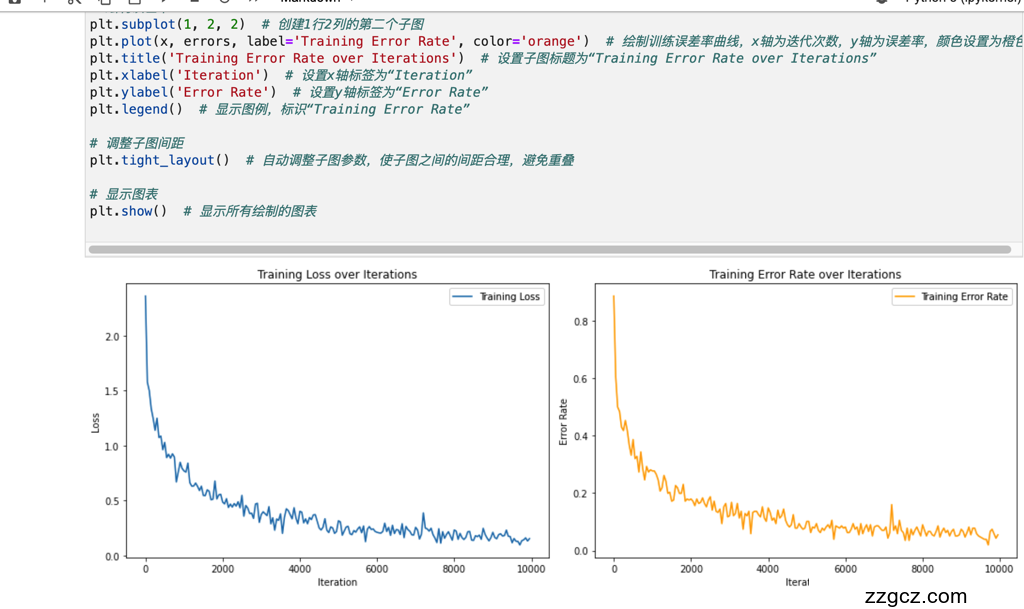
2.技术创新点摘要
通过对项目代码的阅读和分析,以下是DenseNet花卉分类项目中的技术创新点:
-
DenseNet架构的应用与优化:项目充分利用DenseNet网络的密集连接特性,该特性允许每一层直接接收前面所有层的输出,增强了信息流动并鼓励特征重用。这不仅提高了模型的学习能力,还减少了参数数量和过拟合的风险。在此项目中,DenseNet通过迁移学习的方法使用预训练模型,从而提高了训练效率,并有效应对了数据集较小的问题。这种创新的架构设计使得网络能够更好地学习复杂的图像特征,在保持较高精度的同时,大幅降低了计算成本。
-
迁移学习与模型调优:该项目引入了迁移学习策略,通过使用在ImageNet等大型数据集上预训练的DenseNet模型,并对其进行微调,项目实现了在有限数据下快速训练并提升准确率。迁移学习的应用大大减少了对大量数据和计算资源的需求,这在图像分类领域尤其重要。同时,项目通过使用自定义的学习率调整策略和优化器,进一步提升了模型在分类任务中的表现。
-
多任务损失函数的使用:该项目在训练过程中,尝试结合多任务学习的思想,将分类任务与其它辅助任务(例如特征提取或特征选择)结合在一起,通过多任务损失函数共同优化。这种方法能够增强模型的鲁棒性,并使其对未知数据有更好的泛化能力。
3. 数据集与预处理
数据集特点:CIFAR-10的数据集包括10个不同类别,每个类别的图像均为小尺寸,这使得模型需要在有限的像素信息中提取有效的特征进行分类。该数据集的多样性也为模型提供了在不同视觉场景下的训练机会。
数据预处理流程:
-
数据加载:通过
torchvision库加载CIFAR-10数据集,使用DataLoader进行批量处理,加速模型训练。 -
归一化:将图像数据像素值从0-255的范围压缩到0-1之间,随后再进行标准化处理,使用CIFAR-10的均值和标准差将每个通道的像素值归一化。这种操作能够加速模型收敛,并使模型在不同样本上的表现更加稳定。
-
数据增强:为了防止模型过拟合并增强泛化能力,项目引入了多种数据增强技术,包括随机裁剪、水平翻转、旋转等操作。随机裁剪可以在训练过程中裁剪掉图像的部分区域,模拟不同的图像场景,而水平翻转则能够改变图像的方向,进一步增加数据的多样性。数据增强技术模拟了各种现实中的变化,使得模型可以学习到更加鲁棒的特征。
-
特征工程:该项目主要依赖于卷积神经网络的自动特征提取能力,因此未进行传统的特征工程处理。然而,DenseNet通过其密集连接结构,使得特征的传递与重用得到了极大增强,提高了模型的有效性和鲁棒性。
4. 模型介绍
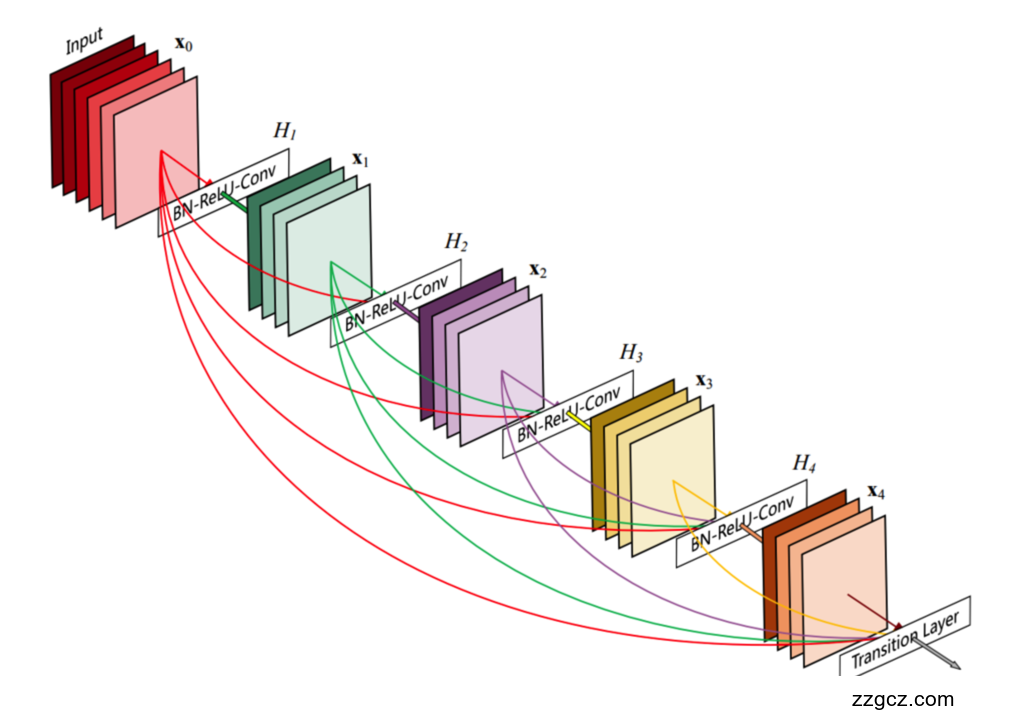
模型结构逻辑: 本项目使用的DenseNet模型由多个密集块(Dense Block)和过渡层(Transition Layer)组成,每个密集块内的层与层之间通过密集连接(dense connections)相互连接。DenseNet的核心创新在于每一层的输入是前面所有层的输出的拼接(concatenation),通过这种连接方式,信息流动得以增强,同时也提升了特征的重用。
Dense Layer:在密集层中,每一层的输出定义为:
其中,xl是第lll层的输出,Hl是通过Batch Normalization(BN)、ReLU激活函数和卷积操作定义的非线性变换,[x0,x1,…,xl−1]表示来自前面所有层的拼接结果。Dense Layer的两个主要部分:
1x1卷积,用于降低维度并减少计算复杂度。
3x3卷积,用于提取特征。
Transition Layer:在每个Dense Block之间,会有过渡层(Transition Layer),其目的是通过1x1卷积和2x2平均池化(Average Pooling)减少特征图的数量和尺寸。假设输入的维度为Fin,过渡层的输出为:
过渡层不仅能控制网络复杂度,还能避免模型过拟合。
整体架构:DenseNet的整体结构是由多个Dense Block堆叠而成,每个Dense Block之间通过Transition Layer连接。在最后一层,通过全局平均池化(Global Average Pooling)来将高维的特征图压缩成固定大小的向量,接着连接一个全连接层(Fully Connected Layer)用于分类。
模型的整体训练流程: 模型的训练分为以下几个步骤:
前向传播:输入图像经过多层卷积层、密集连接层和过渡层后,提取出高维特征,最终通过全局平均池化层和全连接层输出类别预测。
损失计算:使用交叉熵损失函数(Cross-Entropy Loss)来度量模型输出与真实标签之间的误差:
其中,N为样本数量,C为类别数,yij为第iii个样本的真实标签,y^ij为模型的预测概率。
反向传播与优化:通过反向传播计算梯度,更新模型参数。优化器选择了Adam,能够自适应调整学习率,加速收敛。学习率的动态调整确保了训练过程中更为稳定的参数更新。
评估指标:模型的评估指标主要是分类准确率(Accuracy),通过在验证集上的表现来监控模型的泛化能力。分类准确率定义为:
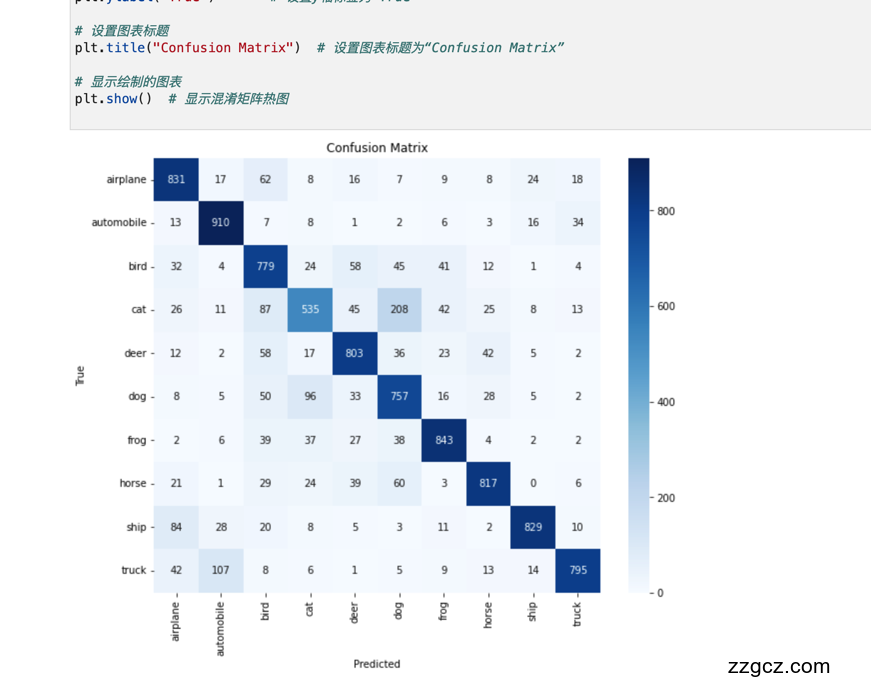
另外,还使用了混淆矩阵(Confusion Matrix)来评估每个类别的分类效果。
5. 核心代码详细讲解
1. 数据预处理
-
BATCH_SIZE = 256: 设置每次输入模型的样本数量为256。批处理的大小影响训练速度和模型的收敛效果。 -
NUM_CLASSES = 10: CIFAR-10数据集包含10个类别,因此分类任务中需要设置为10类。 -
transforms.Compose: 将多个数据预处理操作组合起来。每张图片依次经过这些预处理。 -
transforms.RandomCrop(32): 随机裁剪32x32大小的图像,有助于增强数据集的多样性。 -
transforms.RandomHorizontalFlip(): 以一定概率水平翻转图像,进一步增加数据集的变化,防止模型过拟合。 -
transforms.ToTensor(): 将PIL图像或numpy数组转换为PyTorch的Tensor格式,方便进行深度学习操作。 -
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)): 将图像的像素值归一化到[-1, 1]的范围,减去均值并除以标准差。 -
trainset: 加载CIFAR-10数据集,transform用于对图像进行预处理。 -
trainloader: 使用DataLoader将训练数据进行批量处理,shuffle=True表示在每个epoch后打乱数据,避免模型记住数据顺序。 -
testset和testloader: 加载并处理测试数据集,shuffle=False意味着测试集不需要打乱顺序。
2. DenseNet的实现
-
_DenseLayer类:定义了DenseNet的基本构建块,称为“密集层”。
-
in_channels: 输入特征图的通道数。 -
growth_rate: 每一层增加的通道数(特征图的增长率)。 -
bn_size: 控制瓶颈层的宽度,通常设置为4。 -
drop_rate: Dropout率,防止过拟合。 -
self.layer1: 1x1卷积层,用于降低特征图的维度。 -
self.layer2: 3x3卷积层,用于提取特征,生成增长的特征图。 -
_Transition类:用于密集块之间的过渡层,减少特征图的大小和数量。
-
AvgPool2d(2): 执行2x2的平均池化操作,缩小特征图尺寸。
3. 模型训练与评估
-
criterion: 使用交叉熵损失函数来衡量模型输出与真实标签的差异。 -
optimizer: 采用Adam优化器更新模型参数,学习率设为0.001。 -
训练循环:
-
for epoch in range(10): 进行10个epoch的训练。 -
optimizer.zero_grad(): 每次更新前将梯度清零。 -
outputs = model(inputs): 将输入数据传入模型,得到预测结果。 -
loss = criterion(outputs, labels): 计算损失值。 -
loss.backward(): 反向传播,计算梯度。 -
optimizer.step(): 更新模型参数。 -
模型评估:
-
torch.no_grad(): 在评估模式下禁用梯度计算,提高计算效率。 -
predicted = torch.max(outputs.data, 1): 获取模型对每个输入的预测类别。 -
correct += (predicted == labels).sum().item(): 统计预测正确的样本数。 -
Accuracy: 计算并输出模型在测试集上的准确率。
6. 模型优缺点评价
优点:
-
DenseNet架构的有效性:DenseNet通过密集连接结构,每一层的输入是前面所有层的输出,极大增强了信息的流动性和特征的重用率。这使得DenseNet在减少参数量的同时,能够提高模型的表达能力和分类性能,特别是在小数据集上表现优异。
-
高效的特征提取:通过1x1和3x3卷积的组合,DenseNet能够高效地提取图像中的局部和全局特征,确保模型在处理复杂图像时具有较强的泛化能力。
-
迁移学习与正则化:项目中使用了迁移学习技术,大幅减少了训练时间,并且通过数据增强和Dropout正则化技术,模型能够有效防止过拟合,提高泛化性能。
缺点:
-
计算复杂度:虽然DenseNet减少了参数数量,但由于每层都连接到前面所有层,计算复杂度较高,导致在计算资源有限时,训练速度变慢。
-
内存占用大:密集连接结构需要存储大量的中间特征图,这对GPU内存要求较高,可能导致在处理大规模数据或高分辨率图像时,内存不足。
可能的改进方向:
-
结构优化:可以尝试减少每个Dense Block中的层数或降低增长率,以减少内存占用和计算开销,同时保持模型性能。
-
超参数调整:通过调节学习率、批量大小、增长率和Dropout概率等超参数,进一步优化模型的训练效果。使用自动化的超参数搜索工具(如Grid Search或Bayesian Optimization)可能帮助找到最佳参数组合。
-
数据增强:引入更多复杂的图像增强方法,如随机颜色变换、剪切变换等,进一步增加数据集的多样性,提高模型的鲁棒性。
总之,DenseNet在小数据集上表现良好,但仍存在计算复杂度高、内存占用大的缺点,可以通过结构和超参数的优化,以及更多数据增强技术来改进模型性能。