A052-SegFormer模型实现医学影像图像分割
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
1. 项目简介
本项目基于A052-SegFormer模型实现医学影像图像分割,旨在提供一种高效且精准的分割方案以满足临床和研究中的图像处理需求。医学影像分割是医疗领域中的一个关键任务,它能够辅助医生进行疾病的精准诊断和分析,例如器官或病灶的定位与形态判断。传统的分割方法依赖手工设计特征或简单的阈值分割,无法处理复杂的结构和形态,而深度学习模型凭借其强大的特征提取和学习能力,可以自动从数据中提取多层次的信息表示。本项目中采用了SegFormer模型,这是一种基于Transformer的图像分割架构,结合了卷积神经网络和Transformer的优点,通过多尺度特征提取和自注意力机制能够有效捕捉医学图像中不同尺度下的特征信息,从而提升分割性能。该模型使用轻量化设计,具有较低的计算开销和内存需求,非常适合应用于资源受限的场景,如实时诊断系统和便携式医疗设备。项目的主要目标是验证SegFormer在医学图像数据集上的分割性能,并通过对比实验和可视化展示其在精度和效率方面的优势,为实际应用提供理论支持和算法参考。
2.技术创新点摘要
该项目基于A052-SegFormer模型,针对医学影像的分割任务引入了一系列技术创新点,以提高分割精度和效率。首先,项目采用了基于Transformer架构的SegFormer模型,与传统的卷积神经网络(CNN)不同,SegFormer通过自注意力机制在特征提取时能够更好地捕捉全局信息,从而提升模型对复杂结构和不同尺寸对象的识别能力。同时,项目针对医学图像数据集的类别不平衡问题,设计了自定义的损失函数——“平滑Dice系数损失+交叉熵损失”组合,通过将Dice损失与交叉熵损失结合,实现了在准确性和边界识别上的平衡,有效应对类别不平衡带来的分割偏差问题。此外,项目还采用了模块化设计理念,使用PyTorch Lightning的LightningModule来简化模型训练和优化配置,实现了代码的高度模块化与可重用性。
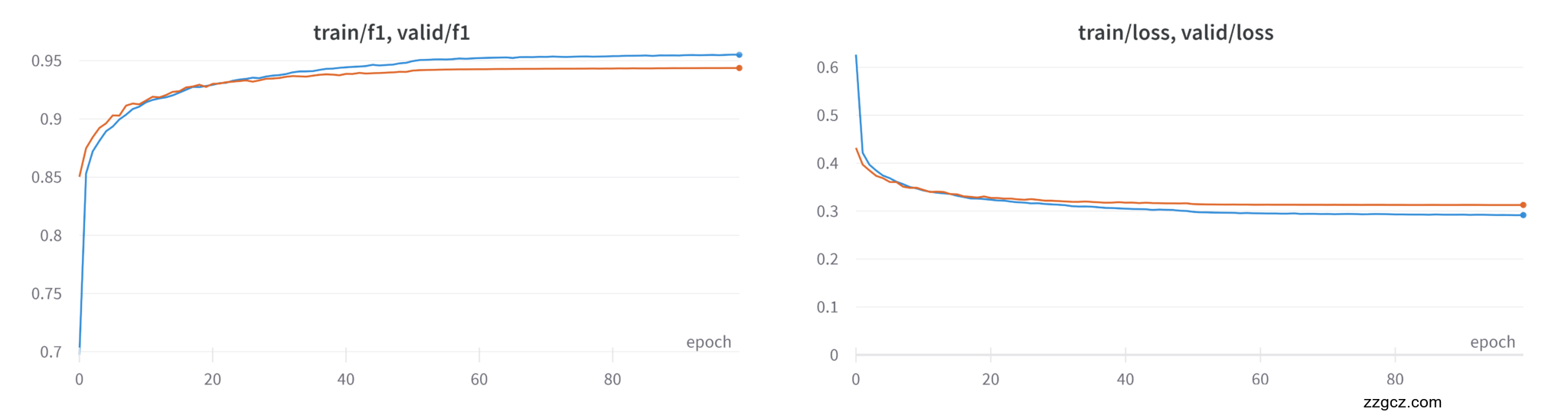
在模型训练过程中,项目引入了多种优化策略,如自适应学习率调整、模型检查点保存策略、学习率监控等,从而保障训练过程的稳定性与模型性能的一致提升。模型性能评估中使用了“宏平均多类别F1评分”作为主要评估指标,该指标能够均衡处理多类别分割场景下的类别间差异。此外,项目还采用了实时数据可视化与性能监控工具(如WandB),使训练过程更加透明化,并通过Gradio接口提供了一个交互式的模型推理和结果展示平台,从而提升了模型在实际应用中的可解释性和易用性。
3. 数据集与预处理
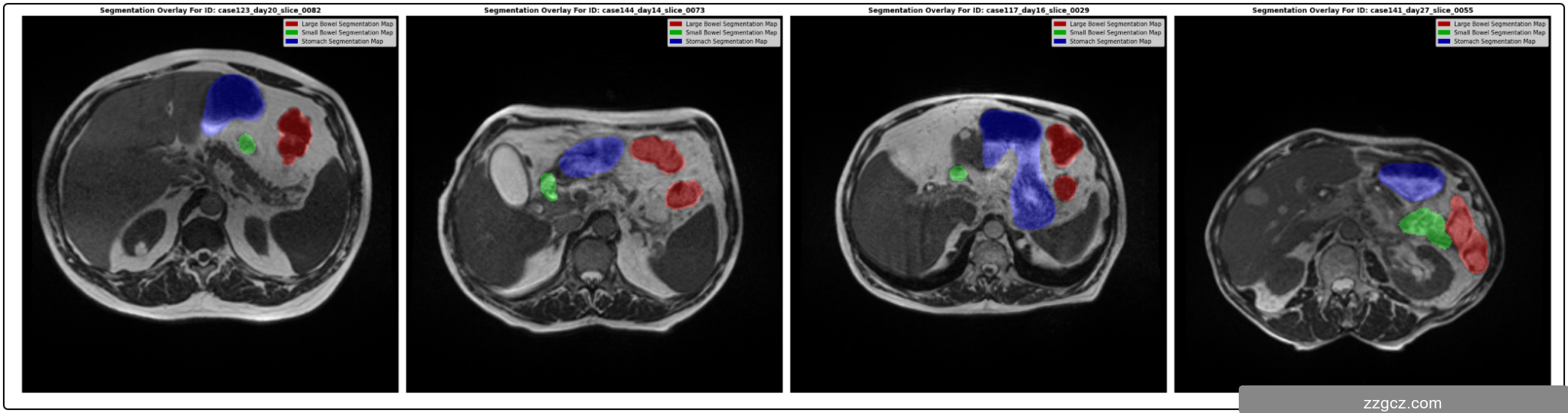
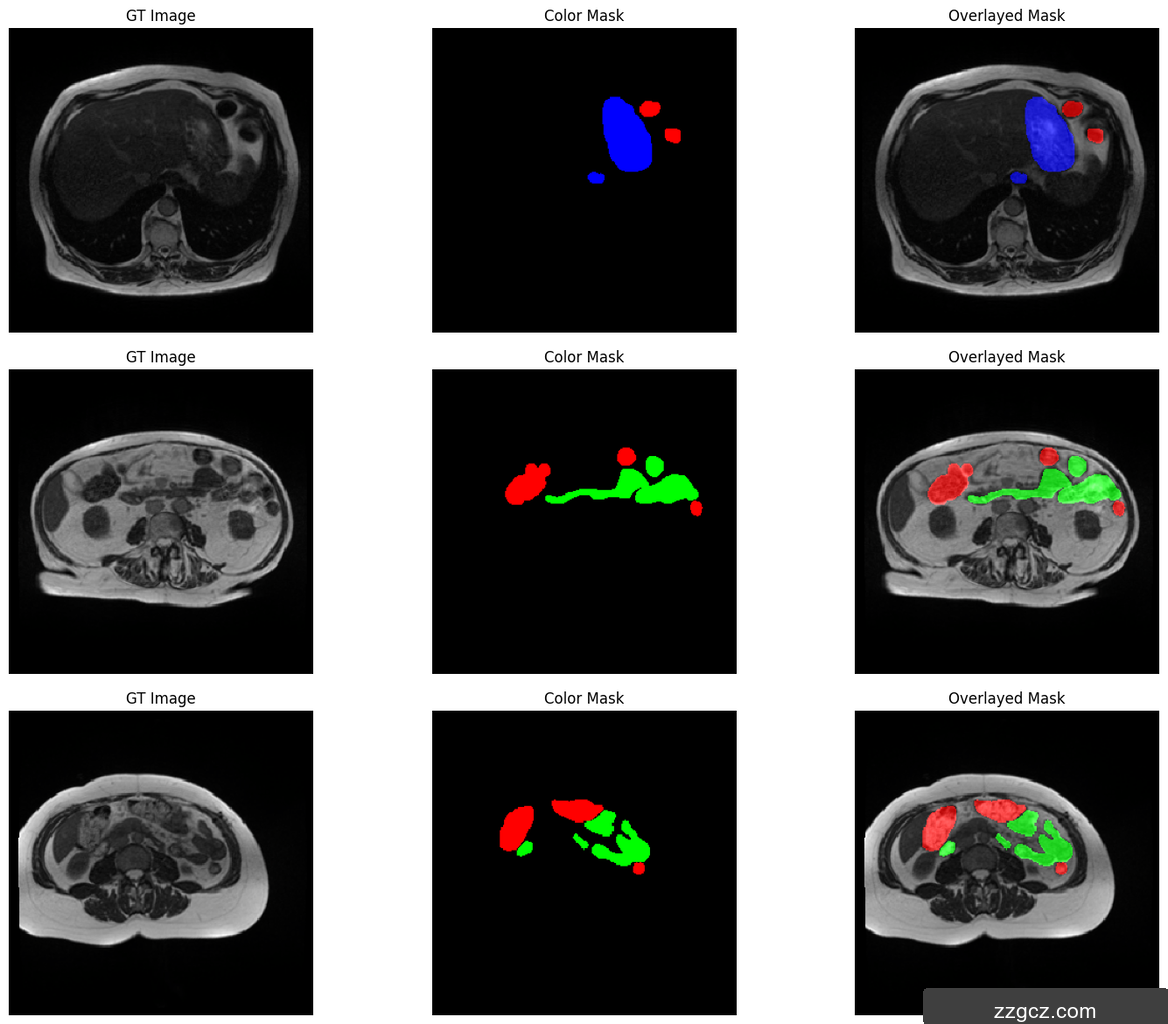
本项目使用的医学影像数据集来源于UW-Madison胃肠道(GI Tract)分割数据集。该数据集主要包含不同患者的腹部CT或MRI图像,并标注了三类主要解剖结构:小肠、大肠和胃。数据集中每个样本包含原始的影像图像(通常是灰度图或RGB图像)以及对应的分割掩码图像(标记不同器官的像素区域)。该数据集的特点是类别不平衡明显,某些器官的像素数量远多于其他类别,这在分割任务中可能导致模型对少数类别的识别能力不足。
由于任务是从图像中分割器官细胞,竞赛以 16 位灰度 PNG 格式图像的形式提供数据集,而真实分割注释是 CSV 文件中提供的 RLE 编码掩码。
关于数据集的一些👀观察。
-
它包含 115488 个样本,每个患者或病例都有多行。
-
在 115488 行中,只有 33913 行(29.364%)具有该类的 RLE 注释。此数字表示可用注释的总数。
-
具有相应注释的图像总数为16590张。
-
这 16590 张图像属于 85 个病例/患者,其中每个患者在多天的每一天都有多次扫描。
-
在这些图像中:
-
我们有8627 (\~52%) 张关于胃的注释图像。
-
我们有11201 (\~67.5%)张小肠的注释图像。
-
我们有14085 (\~84.9%)张大肠的注释图像。
-
有2468 个(\~6.41%) 样本有一个注释。
-
其中,2286 例(\~92.6%)为胃癌。
-
其中123 个(\~4.98%)为大肠。
-
其中59 个(\~2.39%)为小肠。
-
有10921 个(28.37%)样本含有两个注释。
-
其中,7781 个(\~71.3%)为“大肠、小肠”。
-
其中,2980 个(\~27.3%)为“大肠、胃”。
-
其中160 个(\~1.47%)是“小肠、胃”。
-
最后,共存在3,201 个(8.32%)包含所有三个类别的示例。
为了解决类别不平衡和提升模型在医学图像分割中的表现,项目在数据预处理过程中进行了以下几步操作:
-
数据归一化:为了确保模型能够更好地捕捉不同图像特征,所有输入图像的像素值被归一化到 [0, 1] 范围,这样可以避免不同图像灰度值差异过大对模型训练的干扰。
-
数据增强:为了提升模型的泛化能力,采用了多种数据增强策略,包括随机旋转、水平或垂直翻转、平移裁剪和随机噪声添加等。这样能够在训练过程中生成多样化的训练样本,使模型更具鲁棒性。
-
图像尺寸调整:所有输入图像被调整到统一的尺寸(如256x256像素),从而保证在批量训练时能够进行有效的张量运算。对于较小或较大的图像,使用双线性插值方法进行缩放,以保持原始图像的结构比例。
-
掩码标签处理:将每个类别的分割掩码转换为模型可以接受的编码格式(如one-hot编码),以确保损失函数在计算时能够有效区分不同类别。
4. 模型架构
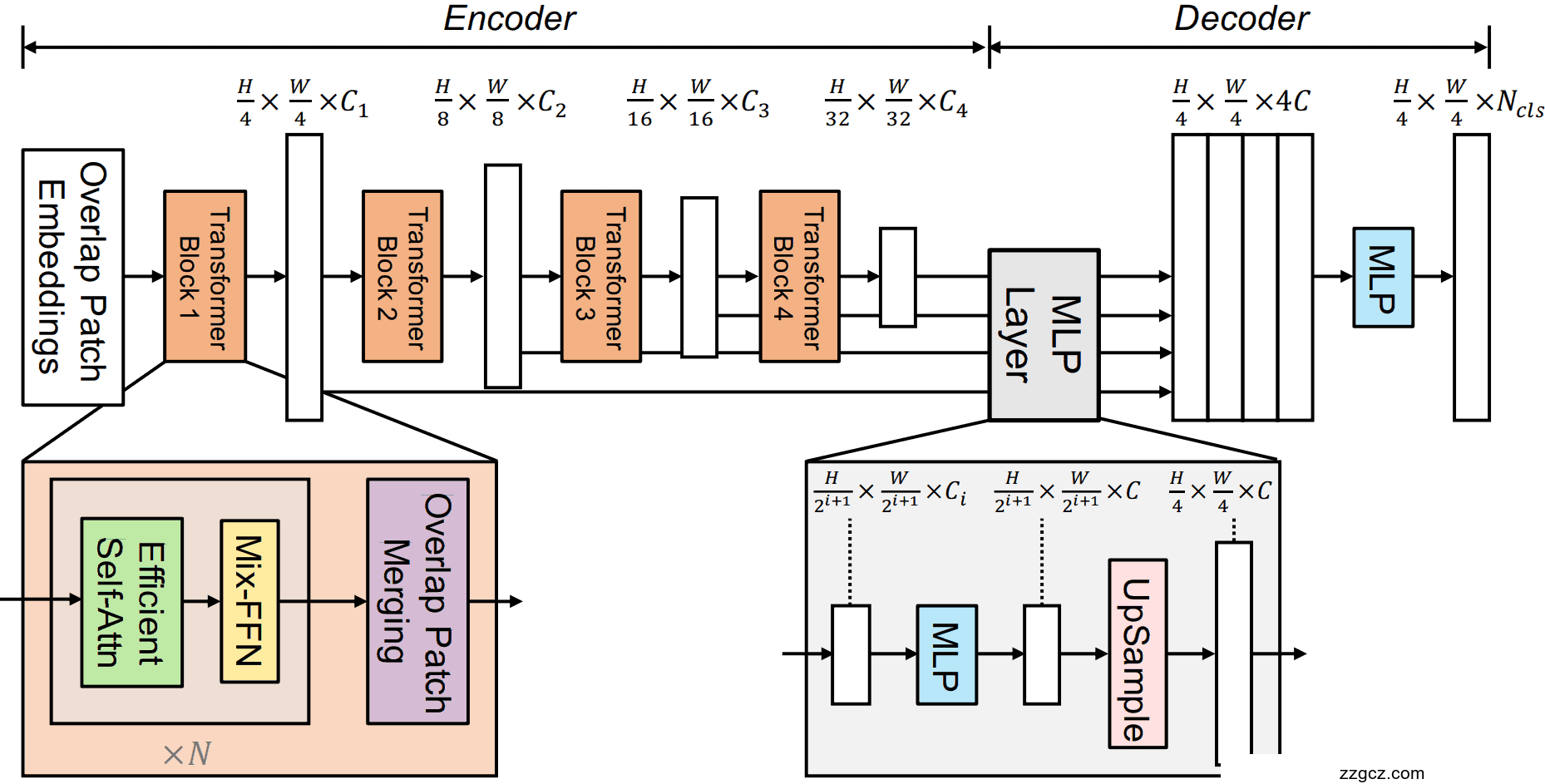
1) 模型结构逻辑与细节
本项目使用的核心模型为SegFormer,其模型架构融合了Transformer和卷积神经网络(CNN)的优点,特别适用于处理复杂的医学影像分割任务。SegFormer的整体结构由多层编码器(Encoder)和解码器(Decoder)组成。具体来说,它的编码器基于**Vision Transformer (ViT)**架构,通过多尺度特征提取来捕捉图像全局和局部信息,而解码器则是一个轻量级的卷积解码网络,用于将编码器输出的特征映射回到原始分辨率,生成精确的分割掩码。
-
编码器(Encoder)结构:
-
多尺度特征提取:SegFormer的编码器采用了多层Transformer模块,每层都有不同的分辨率。具体的数学公式如下:
-
其中,Zl是第 lll 层的特征表示,
MSA表示多头自注意力机制 (Multi-head Self Attention),LN是层归一化 (Layer Normalization),MLP是多层感知机模块 (Multi-Layer Perceptron)。这种多层Transformer编码结构能够在不同的分辨率下生成丰富的图像特征表示,从而实现对细粒度结构的精准捕捉。 -
解码器(Decoder)结构:
-
解码器部分使用卷积层将不同尺度的特征进行融合和上采样,最终输出分割图像掩码。上采样操作采用双线性插值 (
Bilinear Interpolation) 方法逐步恢复图像到原始分辨率。对于每个解码层,输出可以表示为:
- 其中,
Up表示上采样操作,Conv2D是二维卷积,K是卷积核大小。解码器的最终输出是一个分割图,维度与输入图像相同,用于生成不同类别的分割掩码。
2) 模型整体训练流程与评估指标
-
模型训练流程:
-
模型训练采用了PyTorch Lightning框架的
LightningModule来实现模块化设计。训练流程主要包括以下几个步骤:-
前向传播(Forward Pass):输入经过编码器生成多尺度特征图,并通过解码器进行特征融合与上采样,生成与原图像大小相同的预测分割图。
-
损失计算(Loss Calculation):损失函数采用了自定义的组合损失函数(Dice损失 + 交叉熵损失)。公式如下:
-
\(\(\text{Loss} = (1 - \text{Dice}) + \text{CrossEntropy}\)\)
- 其中,Dice损失用于平衡类别不均衡问题,而交叉熵损失能够有效提升分类的准确性。Dice损失的计算公式为:
\(\(\text{Dice} = \frac{2 \sum (P_{i} \cdot G_{i})}{\sum P_{i} + \sum G_{i}}\)\)
-
其中,Pi 是模型预测的概率值,Gi 是对应的真实标签。总损失取Dice损失和交叉熵损失之和,确保在分割精度和类别区分度上都能达到最优表现。
- 优化器(Optimizer)配置:采用了AdamW优化器,并结合了自适应学习率调整策略,在每个训练周期结束时动态调整学习率,以提升模型收敛效果。
-
模型评估指标:
-
本项目主要使用**宏平均F1评分(Macro F1 Score)**作为主要评估指标。该指标在多类别分割场景中能够有效评估模型在各个类别上的整体表现,公式如下:
- 其中,C 是类别数,Precisioni和 Recalli分别表示第 i类的精确率和召回率。
整体来看,模型通过编码器捕捉多尺度信息,解码器精确恢复原始分辨率,并结合自定义损失函数和先进的优化策略,能够实现高效、精准的医学图像分割。
5. 核心代码详细讲解
1. 自定义损失函数(Smooth Dice + Cross-Entropy Loss)
代码片段:
详细解释:
-
def dice_coef_loss(...):定义一个自定义损失函数,将Dice系数与交叉熵损失组合,用于处理医学图像分割任务中的类别不平衡问题。 -
ground_truth_oh = F.one_hot(...):将输入的真实标签转换为one-hot编码格式,这样可以确保标签与模型输出的格式一致。 -
prediction_norm = F.softmax(...):对模型输出进行softmax归一化处理,使得每个类别的输出表示为概率分布。 -
intersection = (prediction_norm * ground_truth_oh).sum(...):计算模型预测值与真实标签的交集。 -
summation = prediction_norm.sum(...) + ground_truth_oh.sum(...):计算模型预测值与真实标签的总和,表示模型预测的整体情况。 -
dice = (2.0 * intersection + smooth) / (summation + smooth):根据Dice系数公式计算平均值,其中smooth是防止除零错误的平滑因子。 -
dice_mean = dice.mean():对所有类别的Dice系数取平均值,表示整体分割精度。 -
CE = F.cross_entropy(...):使用PyTorch内置的交叉熵损失函数来计算分类误差,处理类别之间的区分度。 -
return (1.0 - dice_mean) + CE:返回整体损失值,该值由1减去平均Dice系数再加上交叉熵损失组成,能够同时提升分割精度和类别区分能力。
2. 模型的前向传播与训练逻辑
代码片段:
详细解释:
-
def forward(self, data): 定义模型的前向传播函数,输入为医学图像数据data。 -
outputs = self.model(...):将输入数据传入模型,生成模型在不同尺度下的特征表示(输出为字典格式,包含多尺度的logits)。 -
upsampled_logits = F.interpolate(...):使用双线性插值方法将模型输出的logits调整为与输入数据相同的大小。这一步是因为经过Transformer后的特征图分辨率通常低于原始输入图像,需要上采样以匹配尺寸,从而可以进行逐像素的分割计算。 -
return upsampled_logits:返回上采样后的分割图,用于后续的损失计算与评估。
3. 模型训练流程
代码片段:
详细解释:
-
data, target = batch:从输入的batch中获取训练数据和对应的标签。 -
logits = self(data):执行模型的前向传播,并得到模型的预测结果。 -
loss = dice_coef_loss(...):使用自定义的损失函数来计算当前批次的总损失值,该损失由Dice系数和交叉熵组合而成。 -
self.mean_train_loss(loss, weight=data.shape[0]):记录当前批次的平均损失值,并按当前批次的样本数量加权。 -
self.mean_train_f1(logits.detach(), target):计算并记录当前批次的平均F1分数,用于评估模型的分割效果。 -
self.log(...):将训练过程中的批次损失值和F1分数记录到日志中,以便后续可视化分析与调试。
4. 模型验证逻辑
代码片段:
详细解释:
-
data, target = batch:从输入的batch中获取验证数据和对应的标签。 -
logits = self(data):执行前向传播,获取模型在验证集上的预测结果。 -
loss = dice_coef_loss(...):使用自定义的损失函数计算在验证集上的损失值。 -
self.mean_valid_loss.update(...):更新验证集的平均损失值,并按样本数量进行加权计算。 -
self.mean_valid_f1.update(...):计算并记录当前验证集的F1分数。
6. 模型优缺点评价
模型优点:
-
全局特征捕捉能力强:SegFormer使用了基于Transformer的编码器,可以通过自注意力机制在不同尺度下捕捉图像的全局特征,比传统的CNN架构更有效地处理复杂的医学图像结构。
-
轻量化设计:相比于其他基于Transformer的模型(如ViT),SegFormer采用了简化的模块设计,计算开销低,适用于资源受限的场景,如移动设备或实时分割任务。
-
多尺度特征融合:模型通过多尺度特征提取与融合,在细节分割和全局上下文信息的捕捉上达到了良好的平衡,提升了在不同大小目标上的分割效果。
-
适应性强:自定义的损失函数(Dice + Cross-Entropy)能够有效解决类别不平衡问题,适用于多种医学图像分割任务,如病灶分割、器官分割等。
模型缺点:
-
训练数据需求高:Transformer模型通常对大规模数据集依赖较高,而医学影像数据通常较少且难以标注,可能导致模型在小数据集上容易过拟合。
-
计算资源需求大:虽然SegFormer比传统Transformer模型轻量化,但在训练和推理时仍然对显存和计算能力有较高要求,尤其是在处理高分辨率医学图像时。
-
模型对噪声敏感:模型对数据噪声(如模糊、伪影)较为敏感,需要较为复杂的数据增强和预处理策略。
可能的改进方向:
-
模型结构优化:引入更高级的多尺度特征融合策略,如动态权重调整、注意力机制优化,以进一步提升细粒度特征的表达能力。
-
超参数调整:通过网格搜索或贝叶斯优化策略来自动调整超参数(如学习率、权重衰减),提升模型的稳定性和训练效率。
-
数据增强与正则化:引入更复杂的增强策略(如CutMix、MixUp),并结合正则化技术(如Dropout、Early Stopping)来缓解过拟合风险,提高模型在小数据集上的表现。