A054-Faster R-CNN模型微调检测航拍图像中的小物体
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
1. 项目简介
本项目的目标是基于Faster R-CNN模型对航拍图像中的小物体进行检测和识别。航拍图像通常具有视角广、分辨率高、小目标密集且物体尺寸较小的特点,因此检测难度较大。传统的目标检测模型在处理小物体时,容易受到物体尺寸、分辨率及背景复杂度的影响而出现漏检或误检。本项目通过对Faster R-CNN模型进行微调(Fine-Tuning),提升其在小物体检测任务中的性能。具体地,我们基于预训练的ResNet或MobileNet等主干网络,对模型的各层参数进行适当冻结,并结合数据增强、图像切片(Patch Generation)等方法,优化模型在小物体密集分布情况下的检测效果。该项目的主要应用场景包括城市规划、农业监测、灾害评估及交通管控等领域,通过精准识别航拍图像中的小型目标(如车辆、行人、建筑结构等),为实际应用提供技术支持。项目重点在于提升模型对小目标的检测精度,并验证其在不同复杂场景下的鲁棒性。
2.技术创新点摘要
本项目的深度学习模型针对航拍图像中小目标检测的挑战提出了多种创新点和优化策略,从数据预处理、模型结构调整到目标检测算法的优化,均进行了深入设计。首先,在数据预处理阶段,项目采用了图像切片(Image Patch Creation)技术,将大尺寸的航拍图像分割成多个小块(patches),从而有效提升小目标在图像中的分辨率,使模型更易识别细小目标。这种方法结合了自定义的切片大小、重叠比例和数据增强策略,有效增加了小目标的样本数量,提高了模型的检测精度。
在模型结构上,项目采用了基于ResNet和MobileNet的Faster R-CNN主干网络(Backbone)微调策略。通过适当冻结部分网络层,结合迁移学习(Transfer Learning),使得模型在复杂场景中的小物体检测任务中具备更好的泛化能力。此外,项目通过使用预训练模型和自定义训练策略,最大化地利用了现有数据集的特征表达能力,同时降低了训练时间。
另一个创新点是引入了多尺度特征融合技术(Multi-scale Feature Fusion),利用不同尺度下的特征层进行联合预测,从而在复杂背景和目标密集分布的场景下依然保持较高的检测精度。最后,在模型评估阶段,项目结合使用了COCO API和其他精细化度量(如平均精度AP),实现了小目标检测的精准评估。综合来看,该项目在小目标检测中通过数据处理、网络结构设计及检测策略优化等多个维度进行了创新探索。
3. 数据集与预处理
本项目使用的主要数据集来自SeaDroneSee数据集,该数据集专门用于航拍图像中的小目标检测,包含多个类别的小物体(如游泳者、船只、水上摩托、浮标等),场景复杂、目标密集且存在较多遮挡现象。该数据集具有视角广、目标尺寸不均衡和背景复杂的特点,因此对目标检测模型提出了较高的识别精度和泛化能力要求。
SeaDronesSee 分为三个部分:
-
物体检测:这教会系统识别浩瀚海洋中的人等物体。
-
单目标跟踪:一旦发现一个人,系统就会学会跟随他们,即使他们四处走动。
-
多目标跟踪:实际 SAR 任务中可能会有多名幸存者。此部分训练系统同时跟踪所有幸存者
通过分析这些数据,无人机可以更熟练地协助搜救任务,成为更智能的救生员。
本文重点关注SeaDroneSee 数据集的对象检测 v2 子集,其中包含:
-
8930列车
-
1547 瓦尔
-
3750 测试
此类数据集中的一个关键挑战是实现对对象的标签的准确识别,特别是因为许多类别非常小且难以检测。
需要注意的是,整个数据集中的图像尺寸并不统一。
以下是数据集的图像尺寸(宽,高):
-
(5436,3632)
-
(3840,2160)
-
(1230,932)
-
(1231,933)
-
(3632,5456)
-
(1920,1080)
类别:
0:'忽略', 1:'游泳者',2:'船',3:'水上摩托艇',4:'救生设备',5:“浮标”
“忽略”区域包含由于分辨率低、人群密集或数据集中不需要的对象,因此难以注释。
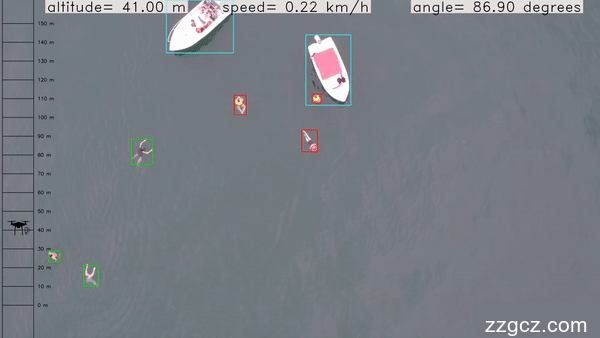
图 4:SeaDroneSee 数据集
我们还观察到该数据集是不平衡的,游泳者、浮标和救生设备等小物体实例之间存在明显的类别分布差异。

图 5:SeaDroneSee 类别分布
在数据预处理阶段,首先进行了数据切片(Image Patch Creation)操作,将原始大尺寸图像分割成较小的图像块(patch),从而放大小目标的相对尺寸,提高模型对小目标的检测能力。每个图像块根据需求设置了不同的切片大小和重叠比例,确保切片中能够保留足够的目标信息并避免目标被切割,从而提升模型训练时的上下文感知能力。
然后对图像进行了归一化处理(Normalization),将像素值缩放到[0,1]区间,确保输入数据具有相同的数值分布。此外,还采用了多种数据增强策略(Data Augmentation),包括随机裁剪、翻转、旋转、平移和亮度调节等,以增加数据的多样性和鲁棒性,从而提升模型的泛化能力。
在特征工程方面,使用了多尺度特征提取(Multi-scale Feature Extraction)技术,基于Faster R-CNN模型对不同尺度下的图像块进行特征融合,确保模型在处理不同尺寸目标时能够有效提取关键特征。这样,通过多种数据预处理和特征优化策略的综合应用,使模型在小目标检测任务中能够实现更好的性能表现。
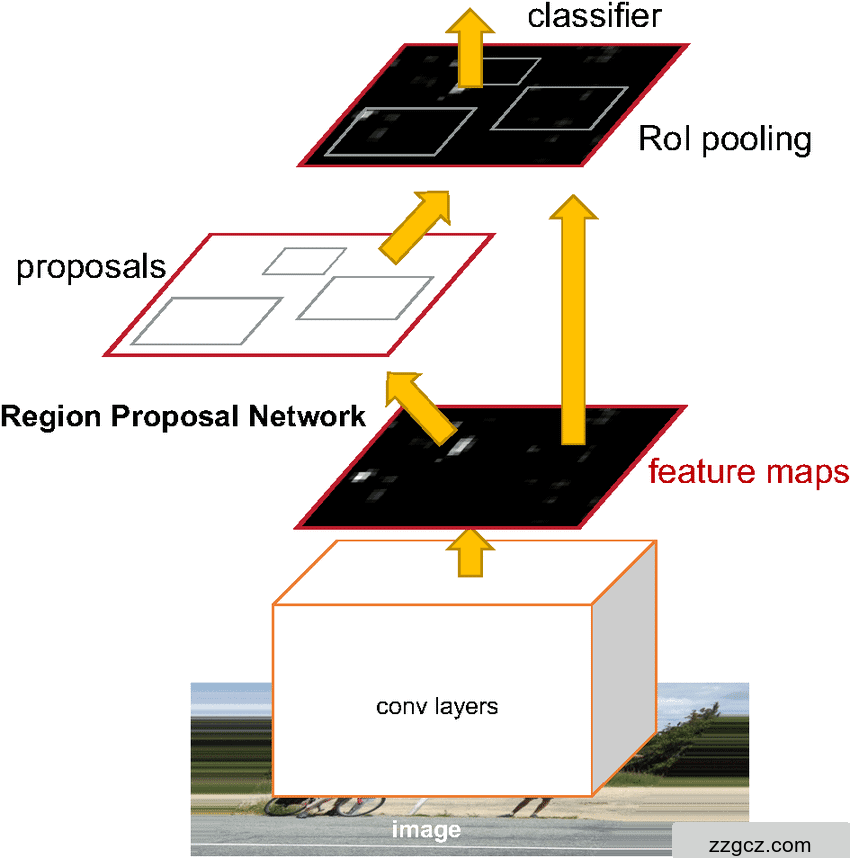
4. 模型架构
本项目采用了经典的Faster R-CNN(Region-based Convolutional Neural Networks)模型作为目标检测的基础架构。Faster R-CNN 模型主要分为以下几部分:
-
输入层:输入为经过预处理的图像切片(patch),每个图像尺寸为 \(H \times W \times 3\)。图像经过归一化处理后,传递到特征提取模块。
-
特征提取层(Backbone):采用预训练的ResNet或MobileNet网络作为主干网络(Backbone),用于提取图像特征。主干网络输出的特征图可以表示为 \(f(x) \in \mathbb{R}^{C \times H’ \times W’}\),其中 \(C\) 表示通道数,\(H’\) 和 \(W’\) 是经过下采样后的特征图尺寸。
-
区域建议网络(RPN, Region Proposal Network):使用滑动窗口在特征图上生成锚点(Anchors),并通过两分支网络(分类分支与回归分支)预测每个锚点是否包含目标及其边界框(Bounding Box)回归。分类分支使用 \(softmax\) 函数计算目标存在概率,而回归分支根据以下回归损失函数来调整边界框坐标:
-
其中,\(t\_i\) 和 \(t\_i^\*\) 分别表示预测框和真实框的坐标参数。
-
ROI池化层(Region of Interest Pooling Layer):通过RPN生成的候选区域(ROIs),进行ROI池化操作,将不同尺寸的候选区域转换为固定尺寸的特征图,用于后续分类和边界框回归。
-
分类器与边界框回归器(Head Network):ROI池化后的特征图输入到Head Network中。模型包含两个输出分支:一个分支输出目标类别的置信度(\(softmax\) 分类),另一个分支输出每个ROI的边界框回归参数。
-
损失函数(Loss Function):总损失函数为分类损失(\(L\_{cls}\))和回归损失(\(L\_{reg}\))的加权和:
- 其中,\(\lambda\) 为平衡系数。
2) 模型的整体训练流程
-
数据预处理与加载:首先对图像进行切片(patch),归一化,并应用数据增强策略。然后将预处理后的数据输入到训练管道中。
-
模型初始化:使用预训练的ResNet或MobileNet作为主干网络,对最后的分类层进行调整,确保输出层与目标类别数匹配。
-
训练阶段:
-
设定初始学习率和优化器(如SGD优化器),并使用学习率调度器(如StepLR)动态调整学习率。
-
前向传播:输入图像传入Faster R-CNN模型,经过特征提取、RPN、ROI池化和分类回归,得到预测结果。
-
计算损失:使用分类损失和回归损失评估模型输出。
-
反向传播:根据总损失反向更新模型参数。
-
学习率调整:定期降低学习率,提高模型在训练后期的稳定性。
-
评估与验证:
-
使用平均精度(mAP, Mean Average Precision)作为主要评估指标,计算不同阈值下的平均检测精度,公式如下:
\(\(AP = \frac{\sum_{i=1}^{N} p(i) \cdot \Delta r(i)}{N}\)\)
-
其中,\(p(i)\) 是精度,\(\Delta r(i)\) 是召回率的变化值,\(N\) 是所有检测的目标数量。
-
模型保存与加载:每次迭代后保存最佳模型,并进行超参数调整以获得最优性能。
通过以上架构设计和训练流程,模型能够在复杂的航拍场景中实现高效的小目标检测。
5. 核心代码详细讲解
1) 数据预处理与特征工程
解释:
-
该代码块用于设定随机种子,以确保每次实验中数据的随机性和模型的训练结果一致性。
-
torch.manual_seed控制了 CPU 的随机性,而torch.cuda.manual_seed确保了 GPU 的随机行为。 -
torch.backends.cudnn.deterministic保证卷积操作的可重复性。
解释:
-
T.ToTensor()将图像从 [0, 255] 的像素值范围转换为 [0, 1] 的张量表示。 -
T.Normalize()通过减去均值并除以标准差进行归一化操作,目的是消除不同图像之间的亮度差异,使模型训练更稳定。
2) 模型架构构建
解释:
-
使用
torchvision.models.resnet50加载预训练的ResNet模型,并去除最后两层,保留特征提取部分。 -
AnchorGenerator用于生成多尺度多比例的候选框,以适应不同尺寸的目标检测任务。 -
MultiScaleRoIAlign是一种高级池化层,能够将不同大小的候选区域转换为固定尺寸(7x7)的特征图,适合后续分类和回归操作。 -
FasterRCNN构建了完整的Faster R-CNN模型,包括特征提取、RPN、ROI池化和分类回归部分。
3) 模型训练与评估
解释:
-
使用
SGD优化器(随机梯度下降)进行模型参数的更新,并设置动量momentum=0.9和权重衰减weight_decay=0.0005,以防止过拟合。 -
StepLR是一种学习率调度策略,每过step_size个周期将学习率降低gamma倍,用于控制训练的收敛速度。
解释:
-
loss_dict返回模型在当前批次图像上的损失,包括 RPN 损失、分类损失和边界框回归损失。 -
sum(loss for loss in loss_dict.values())将所有损失值求和。 -
losses.backward()通过反向传播计算梯度,并使用optimizer.step()更新模型参数。
4) 模型评估指标
解释:
-
MeanAveragePrecision是目标检测任务中常用的评估指标,update(preds, target)将模型预测结果与真实标签输入评估模块。 -
metric.compute()计算最终的mAP结果,用于衡量模型在不同置信度阈值下的检测精度。
6. 模型优缺点评价
模型优点:
-
小目标检测能力强:通过采用图像切片(Patch Generation)技术,将大图像分割为多个小块来提高小目标的相对尺寸,使模型在复杂背景下能够更好地捕捉细微目标的特征。
-
多尺度特征融合:模型使用多尺度的锚点生成器(RPN Anchor Generator)和ROI池化层(Multi-Scale RoI Align),能够在不同尺度下有效提取目标特征,提升了检测的精度。
-
基于预训练模型进行微调:利用预训练的ResNet和MobileNet模型作为主干网络,通过微调策略大大缩短了训练时间,同时保留了原模型的特征提取能力,使模型在小样本场景中也能表现出色。
-
灵活的模型设计与扩展性:Faster R-CNN模型架构的模块化设计便于集成其他模型组件,例如替换主干网络或增加Attention机制,从而适应不同场景下的需求。
模型缺点:
-
计算复杂度高:模型使用了多尺度特征图和候选框生成策略,计算复杂度较高,导致在高分辨率图像上训练和推理速度较慢。
-
内存占用大:模型在处理大尺寸图像或多目标检测任务时需要较多的显存(GPU Memory),不适合在低硬件配置环境中运行。
-
对超参数敏感:模型的训练结果高度依赖于学习率、权重衰减、RPN锚点参数等超参数的设定,容易因参数选择不当导致欠拟合或过拟合。
改进方向:
-
引入轻量化网络:可考虑使用更轻量化的主干网络(如MobileNetV3、EfficientNet)替代ResNet,以减少计算开销并提升推理速度。
-
优化RPN策略:采用更加智能的Anchor-Free方法(如CenterNet、FCOS)替代传统锚点生成策略,以简化候选框生成过程并降低模型复杂度。
-
加入Attention机制:在特征提取层或ROI池化层引入多头注意力机制(Multi-Head Attention),增强模型在复杂场景下对小目标的识别能力。
-
扩展数据增强策略:增加图像旋转、模糊、颜色扰动等数据增强方法,进一步提升模型的鲁棒性和泛化能力。