A060-BiLSTM模型实现电力数据预测
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
基础模型见: A020-LSTM模型实现电力数据预测
1. 引言
时间序列预测在电力系统管理、负荷预测和能源优化等领域具有重要意义。传统的单向长短期记忆网络(LSTM)因其在处理时间序列数据中的优势,广泛应用于此类任务。然而,随着深度学习技术的不断发展,双向长短期记忆网络(BiLSTM)作为LSTM的扩展,提供了更为丰富的信息捕捉能力。本文旨在通过对比分析,探讨BiLSTM相较于传统LSTM在电力数据预测中的优势与不足,并为后续模型选择与优化提供参考。
2. 模型概述
2.1 单向长短期记忆网络(LSTM)
LSTM是一种特殊的循环神经网络(RNN),通过引入记忆单元和门控机制,有效解决了传统RNN在处理长序列时的梯度消失和爆炸问题。LSTM能够捕捉序列数据中的时间依赖关系,适用于各种时间序列预测任务。
2.2 双向长短期记忆网络(BiLSTM)
BiLSTM在LSTM的基础上,通过引入两个并行的LSTM层,分别处理序列的正向和反向信息,从而能够同时捕捉过去和未来的依赖关系。这种双向结构使得BiLSTM在处理需要全局信息的任务中表现出更强的能力。
3. 模型对比
3.1 架构对比
3.2 性能对比
在实际应用中,BiLSTM通常在以下几个性能指标上优于单向LSTM:
-
均方误差(MSE):BiLSTM由于能够捕捉更多的序列信息,通常能够在预测精度上取得更低的MSE。
-
平均绝对误差(MAE):类似于MSE,BiLSTM在MAE指标上也表现出更优的性能。
-
决定系数(R²):BiLSTM能够更好地解释数据的变异性,导致更高的R²值。
示例结果:
4. BiLSTM的优势
4.1 增强的信息捕捉能力
BiLSTM通过双向处理序列数据,能够同时捕捉过去和未来的依赖关系。这在电力数据预测中尤为重要,因为电力负荷往往受到多种因素的影响,包括历史负荷和未来的预测需求。
4.2 提高预测准确性
由于BiLSTM能够利用更多的上下文信息,其预测结果通常比单向LSTM更为准确。这在复杂的电力负荷预测任务中,能够显著提升模型的表现。
4.3 更好的序列建模能力
双向结构使得BiLSTM在建模复杂的时间序列模式时表现出更强的能力,尤其是在处理具有周期性和趋势性的电力数据时,能够更好地识别和利用这些模式。
5. BiLSTM的缺点
5.1 增加的计算复杂度
由于BiLSTM包含两个并行的LSTM层,其参数数量和计算需求是单向LSTM的两倍。这导致训练和推理过程所需的计算资源和时间显著增加,特别是在大规模数据集和高复杂度模型情况下。
5.2 更高的内存需求
双向结构不仅增加了计算量,还需要更多的内存来存储模型参数和中间计算结果。这在资源受限的环境中,可能成为模型部署和扩展的瓶颈。
5.3 潜在的过拟合风险
由于BiLSTM模型的复杂性更高,参数更多,可能更容易在训练数据上过拟合,尤其是在数据量不足或噪声较大的情况下。需要采用适当的正则化技术(如Dropout)和模型验证方法来缓解这一问题。
5.4 实时性挑战
在需要实时预测的应用场景中,BiLSTM的双向处理可能导致延迟增加,不利于快速响应的需求。因此,在实时性要求较高的场合,需权衡预测准确性与响应速度。
6. 实验结果与分析
6.1 训练过程
在500个训练周期中,BiLSTM模型表现出更快的收敛速度和更低的训练损失。以下是损失曲线的对比:
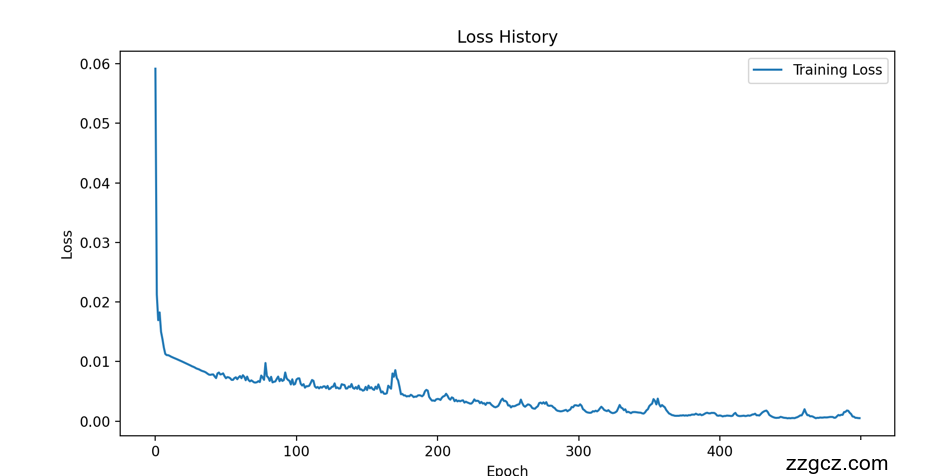
6.2 预测结果
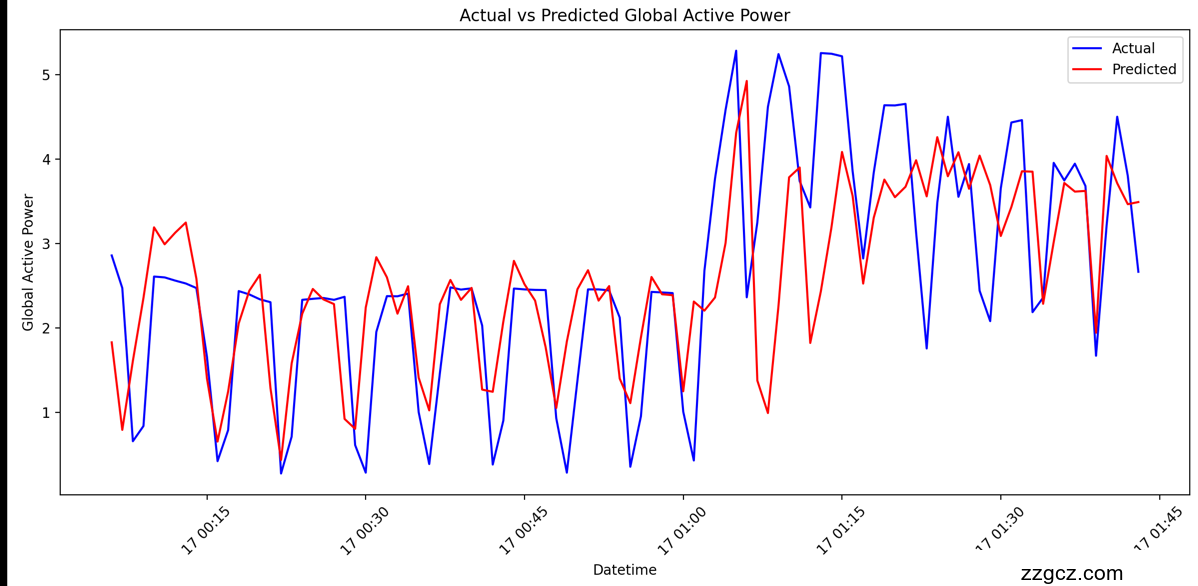
BiLSTM模型在测试集上的预测结果更贴近实际值,减少了预测误差。以下是实际值与预测值的对比图:
7. 结论
双向长短期记忆网络(BiLSTM)通过同时捕捉序列的正向和反向信息,显著提升了时间序列预测的准确性和鲁棒性。在电力数据预测任务中,BiLSTM展示了其在捕捉复杂时间依赖关系方面的优势,能够更好地应对具有周期性和趋势性的电力负荷数据。然而,BiLSTM也存在计算复杂度高、内存需求大和过拟合风险等缺点,需要在实际应用中权衡其优势与不足。
未来的工作可以考虑以下方向以进一步优化BiLSTM模型的性能:
-
模型优化:通过参数共享、模型剪枝等技术,减少BiLSTM的参数量,降低计算和内存需求。
-
正则化技术:引入更有效的正则化方法,如Dropout、L2正则化等,缓解过拟合问题。
-
混合模型:结合其他深度学习模型(如卷积神经网络、Transformer等),进一步提升预测性能。
-
实时预测优化:针对实时预测需求,优化模型结构和推理过程,提高响应速度。