A081-创新优化DCN可变形卷积网络模型实现新冠肺炎影像分类【准确率从53%提升到83%】
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
1. 项目简介
通过搜集新冠肺炎CT图片数据资料了解到中重症新冠肺炎患者的肺部可能会出现磨玻璃影,铺路石症等症状。该模型中引入了Deformable卷积(DeformConv2D),这是一种改进的卷积操作,用于提升卷积神经网络处理图像特征的灵活性。传统卷积操作使用固定的卷积核,而Deformable卷积通过学习空间上的偏移量来动态调整卷积核的采样位置,使得卷积操作可以适应更加复杂的形状和纹理变化。Deformable卷积特别适合处理包含非刚性结构或几何形变的对象,因此在一些医疗影像分析、自动驾驶视觉系统中表现出色。在该项目中,DeformConv2D的加入不仅增强了模型对特征的捕捉能力,还提高了在处理CT图像中不同区域间复杂边界和纹理变化的效果。
3. 数据集与预处理
COVID-CT-2019冠状病毒疾病CT图像数据集包括349例CT图像,其中216例为COVID-19,其余的都为非新冠肺炎CT影像。
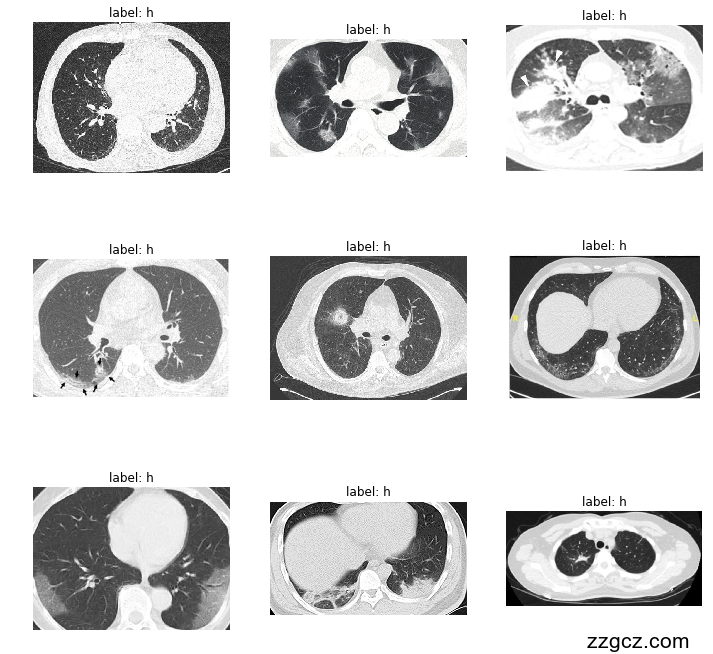
该项目使用的CT影像数据集包含了两类图像——“CT_COVID”和“CT_NonCOVID”,分别代表COVID-19阳性和阴性病例的CT扫描图像。这种数据集具有高分辨率、灰度变化明显、结构复杂等特点,特别适用于医疗影像分类任务,但也对模型的识别能力提出了较高的要求。为了提升模型的泛化性和稳健性,数据集在预处理中进行了精细的处理。
数据预处理流程:首先,图像数据根据模型的输入需求进行统一尺寸的缩放,以确保所有图像能够适应神经网络的输入层。此外,所有图像进行了归一化操作,将像素值调整到固定范围(如-1到1之间),从而减少图像间的亮度差异,便于模型更专注于形状和结构特征。对于每个通道,数据归一化使用均值和标准差,使得图像数值具有相对一致的分布,从而加快模型的收敛速度并提升稳定性。
数据增强:在训练集中应用了数据增强策略,包括随机裁剪、旋转、缩放等。数据增强通过生成多样化的样本来丰富训练数据的特征分布,有助于缓解过拟合,尤其在样本量有限的医疗影像领域尤为重要。随机裁剪、旋转等操作可以帮助模型适应不同的拍摄角度和位置变化,增强模型对真实世界数据的适应性。
特征工程:在特征工程方面,该项目结合Deformable卷积的使用,使得模型能够捕捉复杂的形状变化和细微的纹理特征。虽然没有使用传统的特征提取方法(如SIFT、HOG等),但卷积网络在多层卷积后自动学习到的特征包含了边缘、形状、纹理等丰富信息。这种基于深度学习的特征自动提取方式不仅提高了数据处理的自动化程度,也有效提升了模型在区分COVID-19影像特征上的准确性和泛化能力。通过以上步骤,数据集经过科学的预处理后可供深度学习模型进行高效、精准的训练。
4. 模型架构
模型训练流程如下:
-
优化器与损失函数:模型使用Adam优化器(学习率为0.001),并结合交叉熵损失函数(CrossEntropyLoss)用于计算分类任务的误差。Adam优化器以其自适应的学习率更新策略,有助于加快模型收敛。
-
评估指标:训练过程中使用准确率(Accuracy)作为主要评估指标,以衡量模型对COVID-19和非COVID-19图像的分类能力。准确率指标反映了模型在验证集上正确分类样本的比例,是判断分类任务性能的直观标准。
-
训练与验证过程:模型在300个训练周期中,对每个批次数据进行前向传播和反向传播,不断调整参数以最小化交叉熵损失。每个周期后在验证集上进行评估,以监控模型在不同数据集上的表现,从而避免过拟合。
-
保存模型:训练完成后,模型会将最佳状态的参数保存至指定路径,以便后续进行模型加载与部署。
5. 核心代码详细讲解
-
模型概述
-
这个模型
Dcn1使用了 PaddlePaddle 框架,结合了标准卷积和可变形卷积来增强特征提取能力。可变形卷积(Deformable Convolution)能够灵活地适应图像中的几何变形,使模型更有效地捕捉复杂结构。 -
卷积层(Conv2D)
-
in_channels:输入特征图的通道数。例如,RGB图像有3个通道。 -
out_channels:输出特征图的通道数。每个通道对应不同的特征图。 -
kernel_size:卷积核的大小(如3x3)。 -
stride:步幅,决定卷积操作的滑动步长。步幅为2会减小特征图的尺寸。 -
padding:填充,在特征图边缘添加像素,以控制输出特征图的大小。 -
可变形卷积(DeformConv2D)
-
功能:可变形卷积通过引入偏移量,动态调整卷积核的采样位置,从而更好地适应图像中的几何变形,增强特征提取的灵活性。
-
偏移量生成:
self.offsets卷积层用于生成可变形卷积所需的偏移量。每个卷积核的偏移量包括 x 和 y 坐标,因此输出通道数为 9×2=189 \times 2 = 189×2=18。 -
展平层(Flatten)
-
功能:将多维特征图展平成一维向量,便于输入全连接层进行分类。
-
全连接层(Linear)
-
in_features:输入特征数,即展平后向量的长度。 -
out_features:输出特征数,即神经元的数量,决定了输出向量的长度。 -
激活函数(ReLU)
-
功能:引入非线性,增加模型的表达能力。ReLU(Rectified Linear Unit)能有效缓解梯度消失问题,常用于深度学习模型。
6. 模型优缺点评价
6.1、模型优点:
处理几何变形的能力:可变形卷积能够更好地捕捉图像中具有变形或复杂结构的物体,提高了对物体边界和非刚性形状的建模能力。
灵活性:偏移量是可学习的,并且可以根据不同的数据动态调整,使得模型更具适应性。
增强感受野:通过调整采样位置,可变形卷积能够有效扩展感受野,提高对全局上下文信息的捕获能力。
6.2、模型缺点:
计算开销增加:相比标准卷积,可变形卷积需要额外计算偏移量,并对非整数位置进行双线性插值,增加了计算复杂度和内存消耗。
训练难度:由于偏移量的学习过程较为复杂,模型可能更难收敛,需要更精细的超参数调优和更高的训练稳定性。
对小样本数据的泛化性能:在小数据集上,可变形卷积可能会过拟合,尤其是偏移量的学习会带来额外的模型复杂性。
6.3、应用场景:
目标检测:如 Faster R-CNN、YOLO 和 SSD 等目标检测模型中引入可变形卷积,能够提高检测精度,特别是在物体存在形变或复杂背景的情况下。
图像分割:可变形卷积在图像分割任务中能更好地捕捉物体边界,常用于语义分割和实例分割任务(如 Mask R-CNN)。
人脸识别和姿态估计:在处理存在非刚性形变的人脸或人体姿态时,可变形卷积能提高模型的鲁棒性和准确性。
医学图像分析:在医学图像中,可变形卷积可以更好地适应不同器官或病灶的形态,提高诊断准确率。
6.4、常见模型对比:
与标准卷积的对比
-
灵活性:标准卷积使用固定的采样窗口,而可变形卷积使用可学习的采样位置,具有更高的灵活性。
-
复杂性:标准卷积计算简单,而可变形卷积增加了偏移量计算和双线性插值,计算复杂度更高。
与空间金字塔池化(SPP)和空洞卷积的对比
-
感受野扩展:空洞卷积通过插入空洞来扩展感受野,但仍然使用固定的采样模式;而可变形卷积通过动态调整采样位置,能灵活地适应输入数据的几何特性。
-
特征建模能力:SPP 提供多尺度特征聚合,而可变形卷积更关注局部几何变化的建模,二者可以结合使用以提升性能。
与注意力机制的对比
- 特征增强方式:注意力机制通过加权特征的不同位置来增强重要信息,而可变形卷积通过调整卷积核采样位置来增强特征建模能力,二者可以结合使用以实现更高效的特征提取。
6.5、关键优化点提升准确率
-
使用预训练模型进行迁移学习
-
实现方式:使用
resnet50预训练模型,移除其原有的分类层,并添加一个新的全连接层以适应当前的分类任务。 -
优势:预训练模型在大规模数据集上已经学习到了丰富的特征,可以显著提升模型的特征提取能力和泛化能力。
-
增大输入图像尺寸
-
实现方式:将图像尺寸从32x32调整为224x224。
-
优势:保留更多的图像细节,帮助模型更好地学习和区分不同类别。
-
增强数据增强
-
实现方式:在训练数据预处理部分添加了随机裁剪、随机旋转、颜色抖动等多种数据增强手段。
-
优势:增加数据的多样性,提升模型的泛化能力,减少过拟合。
-
调整训练参数
-
实现方式:
-
批次大小:设置为64,确保训练的稳定性和效率。
-
学习率调度器:使用
StepDecay,每10个epoch将学习率降低为原来的0.1倍,帮助模型在训练后期更好地收敛。 -
优化器:使用Adam优化器,具有自适应学习率的优势。
-
-
优势:稳定训练过程,加速模型收敛,避免陷入局部最优。
-
处理类别不平衡
-
实现方式:计算每个类别的权重,并在交叉熵损失函数中应用这些权重。
-
优势:缓解类别不平衡问题,防止模型偏向于多数类,提高少数类的识别能力。