A088-BERT的新闻标题生成
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
1. 项目简介
本项目旨在开发一个基于BERT的新闻标题自动生成模型,以实现快速、准确的新闻标题生成功能。随着信息流量的不断增加,高效的标题生成对于新闻业和自媒体从业者而言极为重要,一个好的标题能够在简短的语言中抓住新闻的核心内容,吸引更多的读者关注。为实现这一目标,本项目引入了BERT(Bidirectional Encoder Representations from Transformers)模型,通过其双向编码能力获取文本的深层语义信息,使生成的标题不仅符合文章内容,还具有较高的吸引力和逻辑性。项目参考了深度学习自然语言处理领域的前沿技术,并结合了微博新闻摘要数据集,使用部分数据进行训练,以提升模型的训练效率和生成精度。该项目的成果不仅可以用于新闻标题生成,还能够扩展应用于文章摘要、关键词提取等场景,为新闻传媒、公务员考试中信息总结题等提供智能化的解决方案。
🐱 基于BERT的文本标题生成
一个好标题则是基于文章内容的巧妙提炼,能迅速引起读者的兴趣。
为了快速精准的生成新闻标题,本项目使用经典的BERT模型自动完成新闻标题的生成。
📖 0 项目背景
新闻头条新闻的目的是制作一个简短的句子,以吸引读者阅读新闻。一篇新闻文章通常包含多个不同用户感兴趣的关键词,这些关键词自然可以有多个合理的头条新闻。快速的生成合适的新闻标题能帮助自媒体从业者从热点信息中迅速获得大量流量。此外,该任务也可以应用于公务员考试中的关键信息总结题。因此,将该过程自动化具有广泛的应用前景。
🍌 1 数据集
lcsts摘要数据是哈尔滨工业大学整理,基于新闻媒体在微博上发布的新闻摘要创建了该数据集,每篇短文约100个字符,每篇摘要约20个字符。共计2108915条数据
由于数据量较大,本项目仅使用部分数据训练【训练结果仅为部分数据。需要二次修改创新模型,请联系我们:zzgcz_com】

🍉 2 论文解读
BERT(**B**idirectional **E**ncoder **R**epresentations from **T**ransformers)意为来自Transformer的双向编码器表征。不同于最近的语言表征模型,BERT旨在基于所有层的左、右语境来预训练深度双向表征。因此,预训练的BERT表征可以仅用一个额外的输出层进行微调,进而为很多任务(如问答和语言推理)创建当前最优模型,无需对任务特定架构做出大量修改。

- Bert提出了一种新的预训练方法,能有效提高预训练模型在下游任务中的表现。
>介绍
语言模型预训练已被证明可有效改进许多自然语言处理任务。
将预训练语言表征应用于下游任务有两种现有策略:基于特征feature-based和微调fine-tuning。
基于fine-tuning的方法主要局限是标准语言模型是单向的,极大限制了可以在预训练期间使用的架构类型。
BERT通过提出一个新的预训练目标:遮蔽语言模型”(maskedlanguage model,MLM),来解决目前的单向限制。
该MLM目标允许表征融合左右两侧语境语境。除了该遮蔽语言模型,BERT还引入了一个“下一句预测”(nextsentence prediction)任务用于联合预训练文本对表征。
论文贡献如下:
-
证明了双向预训练对语言表征量的重要性。
-
展示了预训练表征量能消除许多重型工程任务特定架构的需求。
(BERT是第一个基于微调的表征模型,它在大量的句子级和词块级任务上实现了最先进的性能)
- BERT推进了11项NLP任务的最高水平。
> 模型框架
BERT模型架构是一种多层双向Transformer编码器。
本文设置前馈/过滤器的尺寸为4H,如H=768时为3072,H=1024时为4096。
主要展示在两种模型尺寸上的结果:
-
BERTBASE:L=12,H=768,A=12,总参数=110M
-
BERTLARGE:L=24,H=1024,A=16,总参数=340M
- 注意:BERT变换器使用双向自注意力机制
> 输入表征
对于每一个token, 它的表征由对应的token embedding, 段表征(segment embedding)和位置表征(position embedding),其中位置表征支持的序列长度最多为**512**个词块。
(如果使用bert预训练模型的话不能改,要是自己训练的话可以自己定义,不一定要按照512,这里原文是为了平衡效率和性能)
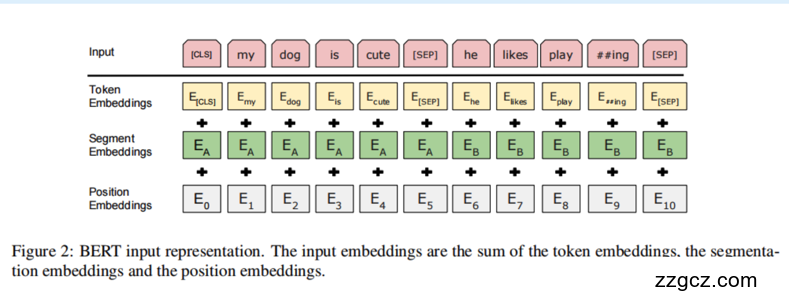
其中,位置表征(position embedding)是由Transformer提出,目的是为了对不同位置的信息进行编码。
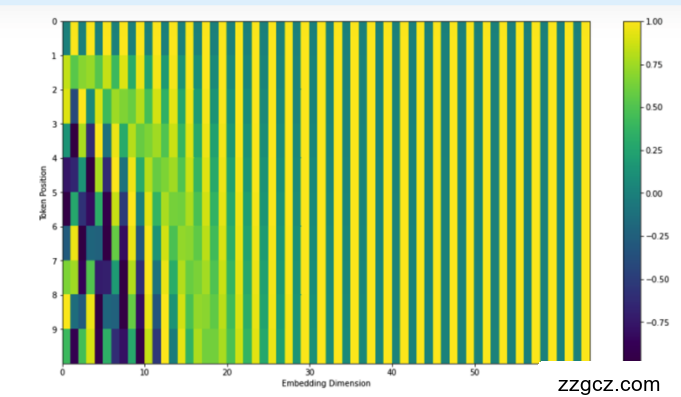
这里有两种实现方法:拼接和求和,详情见Transformer 中的 positional embedding
> 预训练任务
作者使用两个新型无监督预测任务对BERT进行预训练
- 遮蔽语言模型
随机遮蔽输入词块的某些部分,然后仅预测那些被遮蔽词块。Bert将这个过程称为“遮蔽LM”(MLM)。
具体实现方式为:
训练数据生成器随机选择15%的词块。然后完成以下过程:
并非始终用[MASK]替换所选单词,数据生成器将执行以下操作:
-
80%的训练数据:用[MASK]词块替换单词,例如,【我的狗是毛茸茸的!】【我的狗是[MASK]】
-
10%的训练数据:用随机词替换遮蔽词,例如,【我的狗是毛茸茸的!】【我的狗是苹果】
3) 10%的训练数据:保持单词不变,例如,【我的狗毛茸茸的!】【我的狗毛茸茸的!】这样做的目的是将该表征偏向于实际观察到的单词。
- 下一句预测模型
为了训练一个理解句子关系的模型,我们预训练了一个二值化下一句预测任务,该任务可以从任何单语语料库中轻松生成。
具体实现方式为:选择句子A和B作为预训练样本:B有50%的可能是A的下一句,也有50%的可能是来自语料库的随机句子
总结
BERT使用了更加高效的Transformer结构,高效获取了训练数据的双向表征信息。
文章做了非常详细的消融实验,建议感兴趣的同学可以详细的品读一下原文。
参考资料
[1] https://www.cnblogs.com/guoyaohua/p/bert.html
[2] https://zhuanlan.zhihu.com/p/171363363
[3] https://zhuanlan.zhihu.com/p/360539748
[4] https://arxiv.org/pdf/1810.04805.pdf
2.技术创新点摘要
本项目基于BERT模型,聚焦于新闻标题的生成任务,通过对BERT的结构和使用方式进行优化,实现了生成式文本摘要的创新应用。以下是该项目的主要技术创新点:
-
下三角掩码矩阵的使用:项目在标题生成过程中应用了下三角掩码矩阵,用于在多头自注意力机制中掩盖未来词的信息。这种方法源于生成模型的需求,有效地限制了注意力机制只关注历史信息,确保生成的文本符合自然语言生成的顺序性。
-
结合BERT预训练模型与微调机制:项目使用BERT的双向编码特性,通过引入额外的输出层,以新闻标题生成为特定任务进行微调。BERT模型的结构包含多层双向Transformer编码器,能够有效提取上下文信息,而项目在标题生成时仅使用了一部分数据进行训练,从而显著提高了生成效率。这种微调方法不仅保留了BERT的丰富语义理解能力,还将其有效地应用于生成任务中。
-
基于新闻领域的数据集与任务优化:该项目使用了由哈尔滨工业大学整理的新闻摘要数据集,包含超过200万条新闻摘要数据。数据集的丰富性为模型提供了充足的语料,同时也面向新闻标题生成任务进行了数据过滤,以确保模型关注新闻内容的核心信息。由于数据量庞大,项目仅使用了部分数据进行训练,提高了资源利用效率。
-
多层注意力权重计算的优化:在生成标题时,项目通过对输入句子中有效位置的注意力掩码进行处理,将注意力矩阵精确到单词级别,有效提高了标题生成的准确性和逻辑性。这一优化不仅提升了模型的计算效率,还显著增强了模型在标题生成任务上的表现。
3. 数据集与预处理
本项目使用的新闻标题生成数据集为哈尔滨工业大学整理的LCSTS(Large Scale Chinese Short Text Summarization)数据集,基于在微博发布的新闻摘要构建。该数据集包含约210万条新闻文本,每条数据包含一个约100字的新闻正文和一个约20字的摘要,适用于中文文本生成和自然语言理解等任务。数据集的规模和文本的简短性符合标题生成任务的需求,特别适用于基于深度学习的文本生成模型。
数据预处理流程
-
数据清洗:首先对原始数据进行清洗,去除文本中多余的特殊符号、HTML标签和冗余空格,以确保输入模型的数据具备较高的质量和一致性。
-
数据筛选与分割:由于数据量庞大,项目仅选择了一部分数据用于训练和验证,确保数据的多样性与代表性。同时,数据集划分为训练集、验证集和测试集,以评估模型的泛化能力。
-
分词与编码:由于BERT模型对输入有长度限制且采用基于词片的编码方式,因此项目对文本进行分词处理,并将分词结果转为词片级别的ID编码。同时,加入了[CLS]和[SEP]特殊标记,以适应BERT的输入格式,帮助模型更好地理解文本的结构与意义。
-
特征工程与掩码机制:为提升生成质量,项目通过下三角矩阵掩码确保标题生成过程中注意力集中在历史信息,避免对未来词产生依赖。注意力掩码作为输入特征的一部分,可以在训练时过滤出不相关的信息,从而有效提升模型的注意力计算效果。
-
归一化处理:对输入的长度和文本进行了标准化,填充短文本,使其达到固定长度。这种处理有助于模型的批量化训练和显存优化,避免因输入长度不一致带来的处理开销。
通过以上预处理步骤,项目构建了符合BERT模型输入格式的高质量数据集,为后续的模型训练和优化打下了坚实基础,有效提高了标题生成的准确性与一致性。
4. 模型架构
-
模型结构的逻辑: 本项目基于BERT(Bidirectional Encoder Representations from Transformers)预训练模型,构建了适用于新闻标题生成的特定结构。模型首先加载了预训练的BERT模型,并在此基础上进行了优化,以适应生成任务的需求。具体而言,模型利用了BERT的双向编码器结构,结合BERT内置的词嵌入层和自注意力机制,对输入文本的上下文信息进行编码。为了确保生成的标题顺序性,模型构建了一个下三角掩码矩阵,该矩阵在自注意力机制中屏蔽了未来的词语,从而确保在生成过程中仅参考已生成的词。模型使用
BertForTokenClassification类来进行词级别的分类任务,从而在每个生成步输出一个词片,使标题逐步生成,直到满足设定的长度或结束标记。 -
模型的整体训练流程与评估指标: 在模型训练过程中,首先对输入文本和标题数据进行分词编码和长度标准化处理。然后将数据通过自定义的数据加载器送入模型,每个批次的输入包括内容的词片ID、类型ID和掩码。训练采用了交叉熵损失函数,对生成的标题词片和真实标题词片逐词进行对比,逐步优化模型的生成效果。模型的优化采用梯度下降法,通过反向传播更新参数。
-
在评估阶段,模型生成的标题将与真实标题进行比较,常用的评估指标包括BLEU和ROUGE分数,这些指标能有效衡量生成文本的准确性和覆盖度。其中,BLEU主要关注生成标题与真实标题的n元组相似度,ROUGE则衡量生成标题对真实标题的召回情况。综合这两项指标,模型能够获得对标题生成质量的多方面评价,帮助调优生成效果,使其更符合新闻标题生成的要求。
6. 模型优缺点评价
优点: 本项目基于BERT预训练模型,具备强大的双向语义理解能力,使得生成的标题能更好地抓住新闻文本的核心要点。同时,通过下三角掩码矩阵的使用,模型避免了未来词信息泄露,有效保证了生成文本的顺序性。此外,项目在数据预处理中应用了长度标准化和填充掩码策略,提升了模型的批量处理效率,使训练更加稳定。此外,通过交叉熵损失函数加权忽略填充值,模型优化更为高效,生成质量得到了较好的保障。
缺点: 由于BERT模型的参数量较大,本项目在训练过程中对硬件资源要求较高,并且由于数据规模的限制,模型对某些样本的生成质量可能欠佳。此外,BERT作为编码器在生成文本时存在局限性,它并非专为生成任务设计,可能在生成流畅性和一致性方面稍逊。模型还未引入丰富的数据增强方法,导致数据的多样性不足,可能影响模型在不同新闻风格上的适应性。
改进方向:
-
模型结构优化:可以将BERT与生成式模型(如GPT或T5)结合,利用BERT提取特征,结合生成式模型增强生成能力。
-
超参数调整:优化学习率、批次大小等超参数,并尝试不同的优化算法,以提升训练效果和生成质量。
-
数据增强:引入基于同义词替换、句子重排的增强方法,提升模型对多样化表达的适应性。