A094-albert模型实现微信公众号虚假新闻分类基于flask系统带论文带手把手代码讲解教程
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
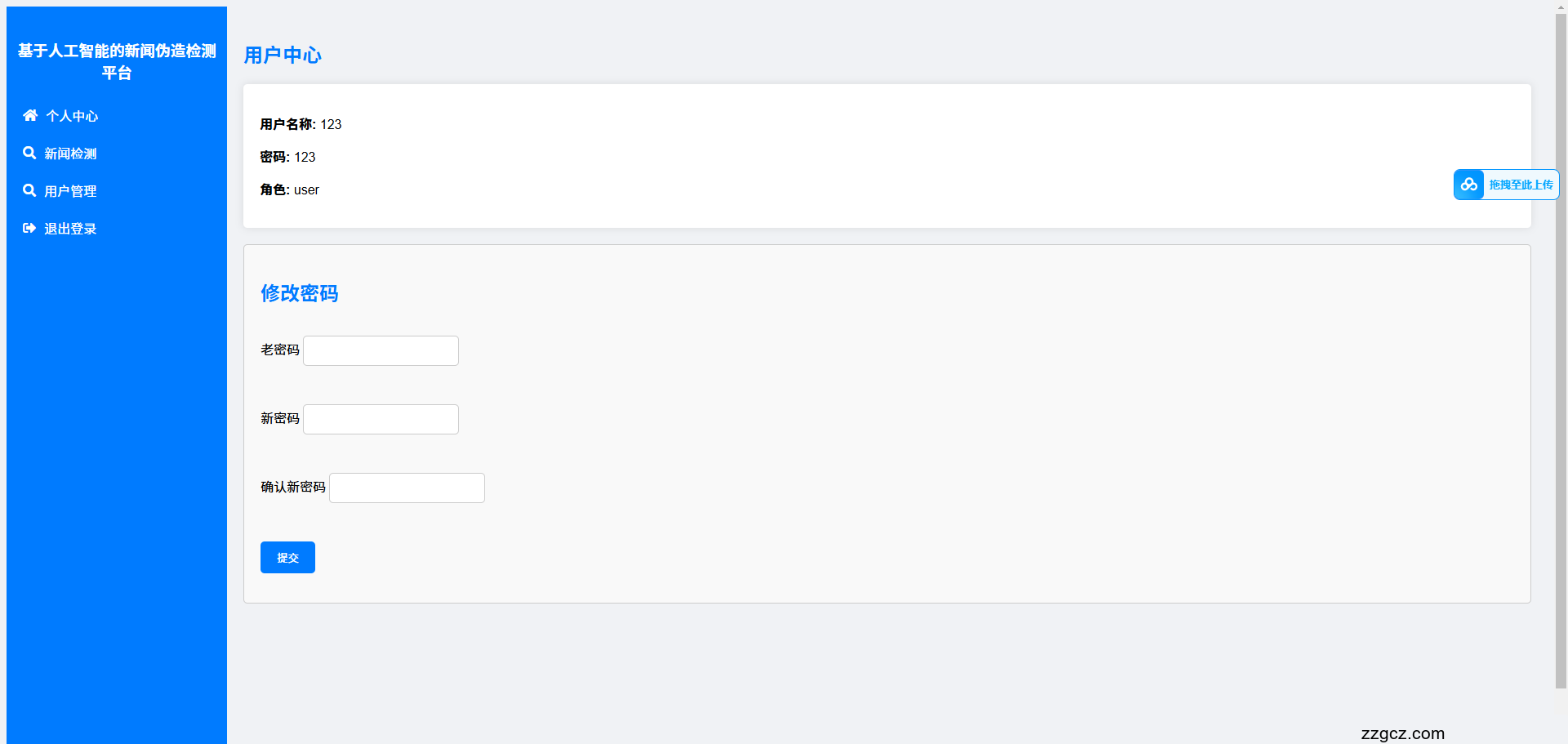
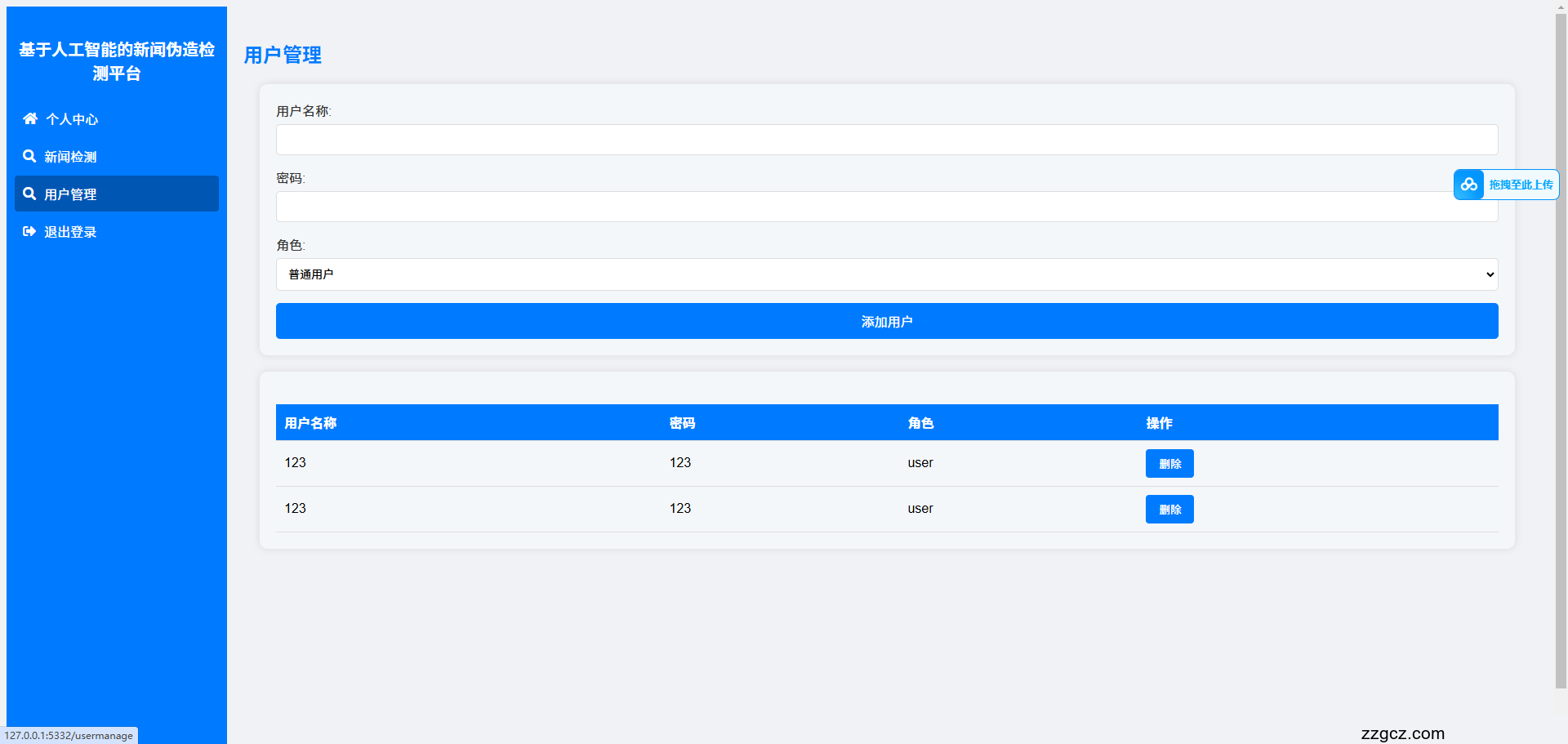
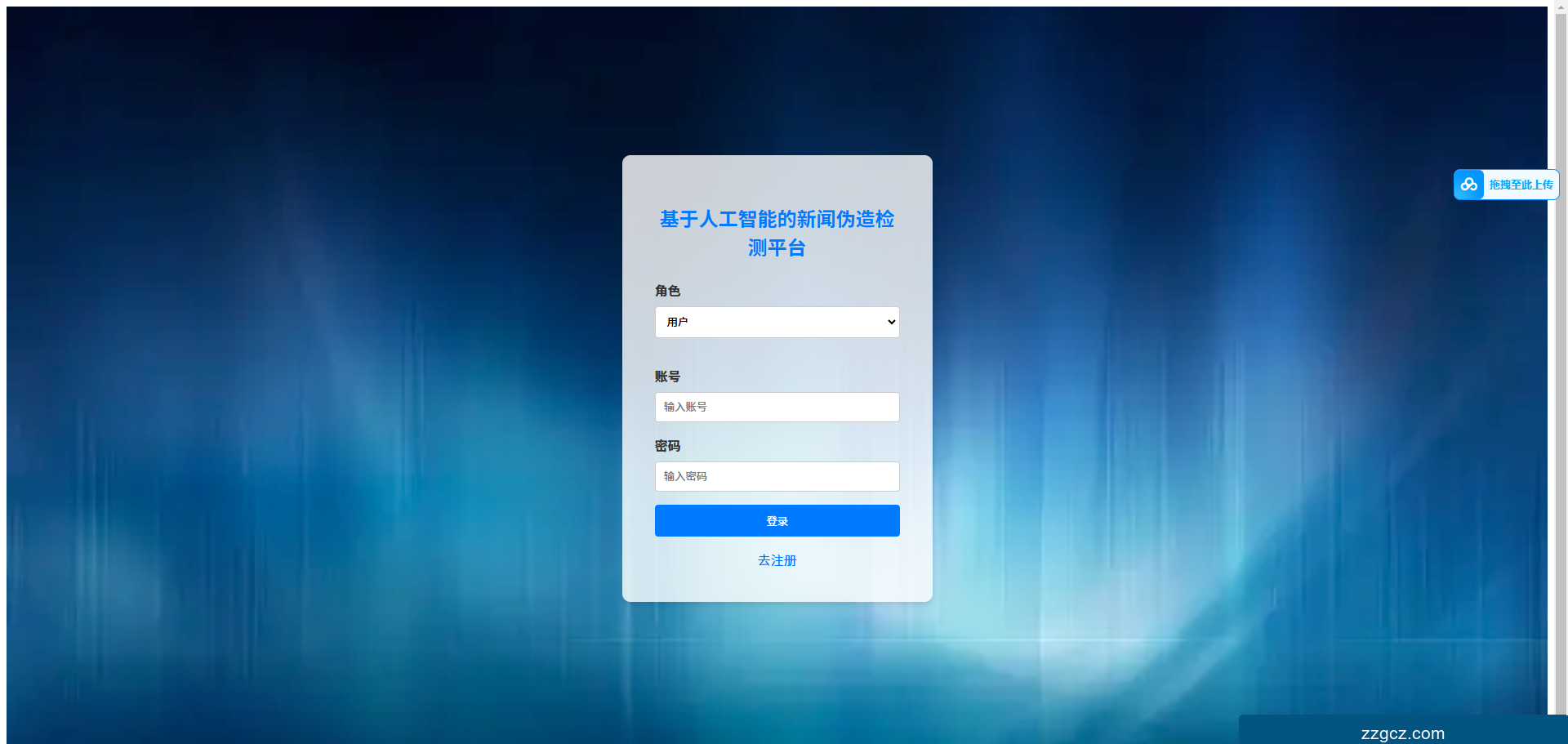
运行截图:

4. 模型介绍
4.1、模型结构
ALBERT(A Lite BERT)是一种基于BERT的轻量级预训练语言模型,旨在减少参数数量并提高训练效率。ALBERT通过参数共享和分解技术,显著降低了模型的参数量,同时保持了与BERT相当的性能。
- 模型结构概述
AlbertForSequenceClassification是一个用于序列分类任务的ALBERT模型。它由以下几个主要部分组成:
-
AlbertEmbeddings: 负责将输入的单词、位置和句子类型信息转换为嵌入向量。
-
AlbertTransformer: 包含多层ALBERT编码器,用于处理嵌入向量并生成上下文相关的表示。
-
Pooler: 对编码器的输出进行池化操作,生成句子级别的表示。
-
Classifier: 将池化后的表示映射到分类任务的输出空间。
- 模型组件详解
2.1 AlbertEmbeddings
AlbertEmbeddings负责将输入的单词、位置和句子类型信息转换为嵌入向量。它包括以下子模块:
-
word_embeddings: 将输入的单词ID映射为128维的嵌入向量。词汇表大小为21128,
padding_idx=0表示填充符号的索引为0。 -
position_embeddings: 将位置ID映射为128维的嵌入向量。最大序列长度为512。
-
token_type_embeddings: 将句子类型ID(如句子A和句子B)映射为128维的嵌入向量。句子类型数量为2。
-
LayerNorm: 对嵌入向量进行层归一化,稳定训练过程。
-
dropout: 在训练过程中随机丢弃部分神经元,防止过拟合。
2.2 AlbertTransformer
AlbertTransformer是ALBERT模型的核心部分,包含多层ALBERT编码器。它由以下子模块组成:
-
embedding_hidden_mapping_in: 将128维的嵌入向量映射到768维的隐藏空间。
-
albert_layer_groups: 包含多个
AlbertLayerGroup,每个组共享参数以减少模型大小。 -
AlbertLayer: 每个
AlbertLayer包含以下组件:-
full_layer_layer_norm: 对输入进行层归一化。
-
attention: 自注意力机制,包括
query、key、value线性变换和注意力输出。 -
attention_dropout: 在注意力计算中随机丢弃部分权重。
-
output_dropout: 在注意力输出中随机丢弃部分神经元。
-
dense: 将注意力输出映射回768维空间。
-
LayerNorm: 对注意力输出进行层归一化。
-
ffn: 前馈神经网络,将768维的输入映射到3072维的中间空间。
-
ffn_output: 将3072维的中间表示映射回768维的输出空间。
-
activation: 使用ReLU激活函数。
-
dropout: 在前馈网络输出中随机丢弃部分神经元。
-
2.3 Pooler
Pooler用于生成句子级别的表示:
-
Linear: 将768维的隐藏表示映射到768维的池化表示。
-
Tanh: 对池化表示应用Tanh激活函数。
2.4 Classifier
Classifier用于将池化后的表示映射到分类任务的输出空间:
-
Linear: 将768维的池化表示映射到2维的输出空间(适用于二分类任务)。
-
dropout: 在分类器输出中随机丢弃部分神经元,防止过拟合。
-
模型参数与配置
-
词汇表大小: 21128
-
嵌入维度: 128
-
隐藏层维度: 768
-
中间层维度(FFN): 3072
-
最大序列长度: 512
-
句子类型数量: 2
-
分类任务输出维度: 2
4.2、AdamW优化器介绍
AdamW 是 Adam 优化器的一个改进版本,专门针对深度学习模型的训练进行了优化。它在 Adam 的基础上引入了**权重衰减(Weight Decay)**的正确实现方式
1.2 Adam 的问题
在原始的 Adam 优化器中,权重衰减(L2 正则化)的实现方式存在问题:
- 权重衰减被直接添加到梯度中,导致权重衰减与学习率耦合。这种耦合会导致权重衰减的效果受到学习率的影响,从而影响模型的训练效果。
1.3 AdamW 的改进
AdamW 通过将权重衰减与梯度更新分离,解决了上述问题:
-
权重衰减不再直接添加到梯度中,而是在参数更新时单独应用。
-
这种方式使得权重衰减的效果更加稳定,且与学习率无关。
常见的 Transformer 优化器
-
AdamW
-
特点:Adam 的改进版本,解耦了权重衰减和学习率。
-
适用场景:训练大规模预训练模型(如 BERT、GPT)。
-
优点:稳定、高效,适合复杂模型。
-
缺点:超参数较多,需要调参。
-
Adam
-
特点:自适应学习率优化器,结合动量和 RMSProp。
-
适用场景:通用深度学习任务。
-
优点:自适应学习率,收敛速度快。
-
缺点:权重衰减与学习率耦合,可能导致训练不稳定。
-
SGD(随机梯度下降)
-
特点:经典的优化算法,直接使用梯度更新参数。
-
适用场景:小规模数据集或简单模型。
-
优点:简单、易于理解。
-
缺点:收敛速度慢,容易陷入局部最优。
-
RMSProp
-
特点:自适应学习率优化器,基于梯度的二阶矩。
-
适用场景:非平稳目标函数(如 RNN)。
-
优点:适合处理非平稳目标。
-
缺点:对学习率敏感。
-
Adagrad
-
特点:自适应学习率优化器,适合稀疏数据。
-
适用场景:稀疏数据或特征频率差异较大的任务。
-
优点:自动调整学习率。
-
缺点:学习率会逐渐减小,可能导致训练过早停止。
-
Adafactor
-
特点:Adam 的轻量级版本,减少内存占用。
-
适用场景:大规模模型训练(如 T5)。
-
优点:内存效率高。
-
缺点:性能可能略低于 AdamW。
优化器对比表格
优化器的选择建议
-
AdamW:
-
推荐用于训练 Transformer 模型(如 BERT、GPT)。
-
适合需要解耦权重衰减的场景。
-
Adam:
-
适合通用深度学习任务。
-
如果不需要解耦权重衰减,可以使用 Adam。
-
SGD:
-
适合小规模数据集或简单模型。
-
如果需要更强的泛化能力,可以尝试 SGD。
-
RMSProp:
-
适合非平稳目标函数(如 RNN)。
-
在处理时间序列数据时表现较好。
-
Adagrad:
-
适合稀疏数据或特征频率差异较大的任务。
-
在自然语言处理任务中可能有用。
-
Adafactor:
-
推荐用于大规模模型训练(如 T5)。
-
在内存受限的情况下表现优异。
4.3、学习率调度器介绍
-
学习率调度器可以根据训练进度动态调整学习率,从而提高模型的训练效果。
-
常见的学习率调度策略包括:
-
预热(Warmup):在训练初期逐步增加学习率,避免模型参数更新过快。
-
衰减(Decay):在训练后期逐步减小学习率,使模型更稳定地收敛。
-
常见的学习率调度器
1.1 线性学习率调度器(Linear Schedule)
-
特点:学习率从初始值线性衰减到 0。
-
适用场景:通用深度学习任务,尤其是 Transformer 模型。
-
优点:简单易用,适合大多数任务。
-
缺点:衰减策略较为固定,可能不适合复杂任务。
1.2 余弦学习率调度器(Cosine Schedule)
-
特点:学习率按照余弦函数从初始值衰减到 0。
-
适用场景:需要平滑调整学习率的任务。
-
优点:平滑衰减,避免学习率突变。
-
缺点:计算复杂度略高。
1.3 指数学习率调度器(Exponential Schedule)
-
特点:学习率按指数函数衰减。
-
适用场景:需要快速衰减学习率的任务。
-
优点:衰减速度快,适合快速收敛。
-
缺点:可能过早衰减学习率,导致训练停滞。
1.4 带预热的学习率调度器(Warmup Schedule)
-
特点:在训练初期逐步增加学习率(预热),然后按照某种策略衰减。
-
适用场景:大规模预训练模型(如 BERT、GPT)。
-
优点:避免训练初期学习率过大导致不稳定。
-
缺点:需要设置预热步数。
1.5 多步学习率调度器(MultiStep Schedule)
-
特点:在预定义的训练步数或 epoch 处将学习率乘以一个衰减因子。
-
适用场景:需要分段调整学习率的任务。
-
优点:灵活,适合复杂任务。
-
缺点:需要手动设置衰减点。
1.6 循环学习率调度器(Cyclic Schedule)
-
特点:学习率在预设范围内周期性变化。
-
适用场景:需要跳出局部最优的任务。
-
优点:有助于跳出局部最优。
-
缺点:训练过程不稳定。
- 学习率调度器的对比表格