A107-【完整论文代码】基于CAM和segnet的图像分割关键算法
导出时间:2025/11/26 13:45:47
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
摘要
随着大数据的应用和机器学的发展,人工智能逐渐从虚无走向现实。在机器人学中,机器人的学习都是基于大量数据的基础上,对大量的数据进行特征提取和特征分析,进而找到不同数据之间的相同点,进而进行判断。当处理图片时,深度学习也是通过区分图像中每隔像素的RGB或者灰度进行判断,并在像邻域内部进行特征提取。针对图像分割问题,本文从弱监督学习的角度出发进行图像分割,通过一定的规则对图像中部分物体的缺失部分进行补偿,其具体实现流程如下:
根据所需要处理的图像构建该图像的邻域图,在构建邻域时,需要参考图像和其相对应的激活映射关系。需要将像素内部及像素周边设定半径范围内像素进行连接。连接的语义相似度可以通过AN进行估算。对于单个的类而言,CAM中的稀疏激活是随着图上的随机游走将稀疏激活传递到周边语义相同的区域,边缘相似度对鼓励语义相似区域进行稀疏激活传播,同时也对边缘不相似区域惩罚稀疏激活传播。这种传播规则会一定程度的对CAM进行修改,通过修改CAM可以恢复图像的形状。这一系列过程作为一个集合,并将大量的类似集合作为训练集进行图像训练。这样一来可以获得分析大量像素处修改的CAM的最大激活相关联的类标签,进而可以进一步合成分割标签。然后通过将大量训练生成的分割标签通过SegNet网络进行二次训练,进而得出用于测试的图像分割模型。
本文的算法是在标准数据集的基础上进行了检验,根据实验结果,可以明显的验证了本文算法的合理性及有效性。
关键词:神经网络;弱监督学习;语义分割
Key Algorithm of Image Segmentation Based on Deep Learning
Abstract
With the application of big data and the development of machine science, artificial intelligence gradually moves from nothingness to reality. In robotics, robot learning is based on a large number of data, a large number of data for feature extraction and analysis, and then find the same point between different data, and then judge. When processing a picture, depth learning is also judged by distinguishing the RGB or grayscale of every pixel in the image, and extracting features in the image neighborhood. In view of the problem of image segmentation, this paper starts from the perspective of weak supervised learning to segment the image, and compensates the missing part of some objects in the image through certain rules. The specific implementation process is as follows:
The neighborhood map of the image is constructed according to the image to be processed. When constructing the neighborhood, it is necessary to refer to the activation mapping relationship between the image and the corresponding image. It is necessary to connect the pixels within the radius set by the interior and periphery of the pixel. The semantic similarity of connections can be estimated by an. For a single class, the sparse activation in cam transfers the sparse activation to the region with the same semantics as the random walk on the graph. The edge similarity encourages the sparse activation propagation in the semantic similar region, and also punishes the sparse activation propagation in the edge dissimilar region. This kind of propagation rule will modify cam to a certain extent, and the shape of image can be restored by modifying cam. This series of process as a set, and a large number of similar sets as training sets for image training. In this way, we can get the maximum activation related class label of cam which is modified at a large number of pixels, and further synthesize the segmentation label. Then, the segmentation tags generated by a large number of training are trained twice through the segnet network, and then the image segmentation model for testing is obtained.
The algorithm in this paper is tested on the basis of standard data set. According to the experimental results, it can obviously verify the rationality and effectiveness of the algorithm in this paper.
Keywords:Neural Network; Weak Supervised Learning; Semantic Segmentation
目录
摘要1
Abstract2
目录4
1 绪论6
1.1 研究背景与意义6
1.2 国内外研究现状8
1.3 存在的问题及技术难点11
1.4 论文的主要内容架构12
1.5 本章小结12
2 AN算法的设计13
2.1 神经网络基本概念13
2.1.1 卷积层13
2.1.2 激励层14
2.1.3 池化层15
2.2 弱监督语义分割标注信息生成16
2.2.1 类激活映射热力图16
2.2.2 生成语义相似度标签18
2.2.3 AN网络训练19
2.2.4 利用AN网络修改CAM20
2.3 训练SegNet网络21
2.3.1 残差网络基本结构22
2.3.2 残差网络的特性22
2.4 AN算法总流程23
2.5 本章小结24
3 实验结果与分析25
3.1 实验系统开发环境与平台25
3.2 VOC训练数据集26
3.3 AN网络训练26
3.4 图像分割关键算法评价标准28
3.5 AN网络图像分割实验28
3.5.1 本文算法实验结果与分析28
3.5.2 AN算法与其他算法的比较30
3.6 本章小结31
4 总结与展望32
4.1 总结32
4.2 展望33
参考文献34
致 谢36
1 绪论
1.1 研究背景与意义
随着社会与经济的长足发展与进步,人工智能(Artificial Intelligence)变得炙手可热,成为了目前人类最美好的梦想之一。虽然科学技术与计算机技术的发展已经取得了显著的进步,但是截止到目前为止,能产生“自我”意识的电脑还没有被发明出来。在1950年,英国数学家阿兰·图灵发表了一篇关于机器是否会思考的论文,由此将人工智能带入到人类的视线中,并提出了一些实验方法以此来测试机器人是否会进行思考,测试方法具体如下:
如果本文在两间相互独立且不干扰的屋子里搁置一个人和一台计算机,然后屋外的提问者分别对两者进行相同的问答测试。如果提问者通过分析计算机和人的答案之后,无法判断出屋内的到底是人还是计算机,并且这种情况还发生了很多次,这样的话就可以证明出来计算机已经具备一些类似于人的智能
深度学习在各种任务中取得了巨大成功,特别是在分类和回归等监督学习任务中。预测模型的学习需要大量的训练样本,每一个训练样本都代表着一个事件或者一个对象。训练样本由两部分组成,一个是样本自身或者自身特征值,另一个是人为的给该样本赋予的标签。当需要对图片进行前景和背景的分割时,人们可以将训练图像分割样本分成两个部分,一部分为前景,另一部分为背景。前景类主要就是图片中人们关心的内容,该部分的标签就为前景,在计算机运算中可以用1代替前景含义。背景类主要就是除前景之外其他的人类不关心的内容,该部分样本标签就为背景,在计算机运算中可以用0代替背景的含义。因此,图像分割有两种可行的分类方式,分别如下:
- 按模型分类:
若按照不同的模型来实现图像分割是主要有两个模型,其一为依靠大量数学公式推导的传统的图像分割模型,另一种为基于卷积神经网络、SVM、随机数等基于深度学习方法对图像进行分割。
- 按任务分类:
若按照图像分割的具体任务任务来进行分类时,主要有三种方式,分别为实例分割、全景分割和语义分割。
语义分割在机器视觉领域发展十分广泛,其主要功能是给摄像机获取的图像中的每个像素点标注一个对应的语义信息,简单的说就是实现像素点与语义的相互映射。再加之借助卷积神经网络等学习能力强的算法,使其得到快速发展。与此同时,卷积神经网络进行语义分割训练时所需训练数据也都应为像素级标注数据。
若进行图像分割时对图像的每个像素进行语义标注,其工作量会变得非常庞大,再加上特殊情况下需要人为的对一些像素进行标注,这一以来会导致图像分割用时会变得很长,当面临大批量的图像分割时,难免无法满足需求。例如,在CityScapes下精确标注一张图片需要90分钟。高额的时间和金钱成本使人们开始探寻新的图像分割方法。
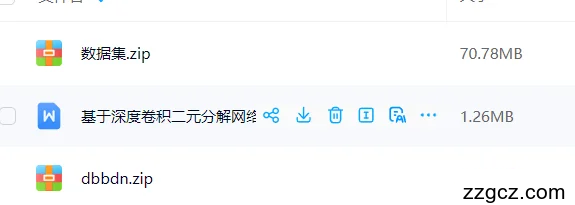
一种新的网络训练方法逐渐走入人类视线。经研究发现,如果只对图像中的特殊点、边界框等色彩差异大或者灰度差异大的像素进行语义标注时,也可以实现良好的图像分割。这种方法利用的是弱监督的网络训练方式,通过选取关键的像素点为代表进行语义标注,进而完成训练数据构建,来最终达到训练目的。通过使用Image-Leveltags和boundingboxes两种输入,弱监督可以明显的框选出Truck和Car,效果如图1.3所示。

图1.3 弱监督标注示例
可以清楚的发现,通过弱监督的方式标注的像素点会比通过卷积神经网络进行标记的像素点减少很多。单单从标注的时间来看,boundingbox标注和image-leveltag标注用时分别为7秒和1秒,若使用这种方式对CityScapes数据库进行标记时,其所需时间至少可以缩短30倍。这些标注可以直接作为输入用于图像分割的和后续弱监督算法,也可以在此基础上再进行特征筛选,进行进一步的二级像素点标注,再将这些二级像素点作为后续弱监督算法的输入。例如在标注面的基础上可以继续提取标注线,在标注线的基础上可以转化为顶点标注等方法。这样一来可以大大降低所需标注像素的数量,加快了标注效率,降低成本。
弱监督语义分割的难点在于关键像素点与对应语义目标之间进行有效匹配。目前大多数的算法都是通过低层信息检测器从原始图像中对像素信息进行处理进而生成语义信息。这种方法可以很好的区分出像素级的显著性,但是从整个图片来看,区分不同前景目标的能力较差。因此,判别语义实例的能力尤为关键。
1.2 国内外研究现状
弱监督语义分割的最大难点是弱标签并非提供语义分割所需的全部信息,而是只提供部分关键的监督信息。如图1.4所示,弱标签在不同级别下只对不同物体进行了框选、点或者部分线段轮廓,而没有整个的轮廓信息。这样一来,在使用弱标注数据训练分割模型时,需要在预测每个像素标注信息的同时学习分割网络的模型参数。
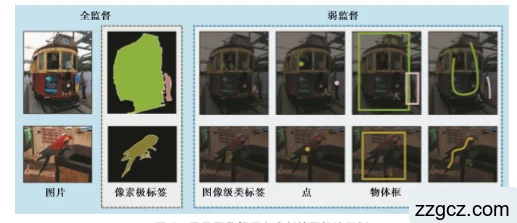
图1.4 弱监督标注方法
(1)图像级类标签
图像级类标签指图像中是否存在着语义实体,是一种较为简单的弱监督信息且一般不需要认为进行标注。此外其样本来源广泛,现有的很多数据集都可以提供样本,因此在弱监督语义分割中图像级类标签应用十分频繁也十分基础。同时图像级类标签也有不可避免的缺点,其无法提供目标的空间信息,因此无法单单依靠图像级类标签进行分割网络训练。因此部分学者提出利用像素级标签作为训练模型的隐变量的方法,这样一来可以在提供目标的空间信息的同时联合图像级类标签优化分割网络的参数。还有些学者通将DCNN中卷积层的输出与像素级标签进行最大似然估计并进行映射,以此来弥补单一图像级标签的缺点,在此基础上使用全局池化操作,通过融合所有像素上的输出概率得分用来生成图像级的类别得分,这部分图像级标签便可作为标记过的训练数据进行分类网络训练。
基于此,Pathak等[1]针对增强约束问题,提出了使用最大全局池化操作的方法,也就是说用于训练的每个图像应当至少设定一个正类像素。Papandreou等[2]针对约束性问题,提出了与Pathak不同的方法,他认为通过采用期望最大化的递归细化方法可以有效的增强约束。也就是不断地将现有模型预测到的像素级标签作为训练输入不断的加入预测模型中继续进行训练,以此实现期望最大化。
若是单单采用图像类级标签进行弱监督,其所获取的信息都不够细致,当然分割结果也不完美。为了解决这一问题,通常需要引入更多数据来获取位置和形状信息。Zhou B[3]针对定位这一问题,提出了基于DCNN的判别式定位技术。该技术主要是通过结合DCNN的各个隐藏单元对网络输出类别概率得分的贡献,以此来对各个物体的大致位置进行判断。并在此基础上对每个语义类别的位置种子进行设置,然后将位置种子朝着相邻像素进行扩展进而判断出相邻像素的语义类别[4-6]。
与此同时,超像素由于其自身丰富的数据信息,也作为一种标签用于判断形状信息[7-8],超像素是一种像素块,是由若干个相邻的像素块组成,这些像素快的颜色、灰度、纹理等都比较相似,便于从底层反应图像的结构信息。Pinheiro和Collobert[7]为了解决像素级标签不平滑的问题,提出使用超像素进行二次处理的方法。Kwak[8]将超像素应用到卷积神经网络的池化操作过程中。
这些方法只可以粗糙地对目标进行定位,由于在训练时过于关注通过物体的局部信息来进行定位,虽然可以减小工作量,但是丢失了很多像素的标签。因此,可以在使用图像级类标签作为训练数据的同时引入额外的弱标注信息(先验信息)以此来降低粗糙程度。
(2)先验知识
图像级类标签只可以判断出图像中是否包含某物实体,无法判断物体在图像中的位置和图像所包含像素信息。因此需要引入物体的先验知识来弥补这些信息的确是。Parthak[9]认为物体在整个图像占据比例的大小可以作为一种先验信息。使用这种先验信息时需要事先设计一个阈值,例如,如果阈值设置为10%,当物体的尺寸超过这个阈值时,此时该先验信息需要置1,若物体尺寸没有超过这个阈值,则该先验信息需要置0。此外显著性也是一种先验信息[5,7,10-11],在二分类问题中,显著性只对区域或者像素是属于前景还是背景进行判断,显著性判断需要从全局来进行分析,因此在一定程度上有助于弥补弱监督方法的信息缺失问题。为此,Pinheiro和Collobert[7]进行显著性图分析时,先对整个图像中明显的显著性区域进行筛选,在此基础上,针对每个显著性区域进行像素级显著度筛选,然后将像素级显著度与原始图像显著度结合起来绘制综合加权显著性图。此外,显著性作为先验知识还被广泛应用于点监督、线监督、框监督等弱标签中[11]。Wei等[12]提出初始化时使用显著性掩码,以此来进行像素级分类,他还认为显著图可以作为监督信息。Oh等[5]首先通过一个前景分割网络生成也是通过显著性掩码进行物体的大致定位,但其生成显著性掩码的方法与Wei不同,其时通关前景分割网络获得的。
(3)点监督
实例点是若标记中最简单的标注形式,仅仅单一的指出了物体的几何中心。当用户单击物体时便可获得实例点。对于物体分类和物体定位任务,Bearman等[10]针对图像中物体的分类和定位问题,提出了一种组合损失函数的方法,其中通过人为的点标记确定物体用于定位的像素级标签。在此基础上通过点监督约束附加与物体的先验知识,结果表明这种方法在预测物体前景区域的效果更佳。
(4)物体框
物体框与点监督相比,其可以满足点监督提供的信息,再次基础上还增加了物体覆盖区域的信息。物体框标注是通过一个矩形区域将物体所在区域覆盖起来。这种标注方式的成本远低于像素级分割标注,用时也更短。现有的使用物体框进行语义分割时,主要是分割前景和背景,即分割关键物体和非关键物体。Papandreou等[2]为了更好的找出图像中的关键物体,提出了以物体框为辅助信息来分割前景趋于的交互式图像语义分割方法。详细的说就是初始种子为物体框的内部和外部,内部为前景,外部为背景,然后训练所需GT为估计的分割掩码,以此来进行分割模型训练。Dai等[13]提出了通过判断候选区域与物体框之间的重叠程度来确定最佳候选区域的方法,该方法提高了分割预测流程效率。
(5)微用户标注
微用户标注方法是一种折中的标注方法,其权衡了标注成本因素和监督信息强度因素。理论上监督信息强度越高,标注成本越高,但是过低的标注成本,监督信息可能会不满足图像分割需求。因此提出了微用户标注的方法。微用户标注需要用户在模型提供的语义分割候选掩码集中选取自己需要的最佳掩码。这样一来通过简单的人工成本可以或者用户更需要的像素级分割掩码,以便后续处理生成具有代表性的分割掩码。这样一来,用户选择最佳掩码的好坏会影响到最终分割掩码的好坏。问题逐渐演变成如何选取最佳掩码。Saleh等[14]针对如何选取最佳掩码问题,提出了CRF的后处理方案,这样一来可以在细化候选掩码的基础上,便于用户选取最佳细化掩码。Kolesnikov和Lampert[15]通过结合DCNN的方式,提取候选区域的特征向量,并进行分组来筛选候选掩码。上述两种方法有助于提高用户在选择模型提供的预测的候选掩码时选择最佳集中掩码的概率。
1.3 存在的问题及技术难点
语义分割中,训练模型所需要的大量的数据收集起来需要耗费大量的人力成本和资金成本。因为除了搜集图片之外,还需要人为的去给每个图片加上标签。其次,在实际具体应用中,很多学科图像分析时加标签需要专业的学科知识,例如探测学中,给GPR雷达图谱加标签,医学中给医学检测图像加标签,这类除了数据量少之外,标签也不好加。而且人工加标签时由于个体差异会导致标签不准确,还有可能出现标错标签的现象。
而弱监督语义分割的难点在于其标签提供的语义分割的信息并不完善,弱标签只能提供部分用于语义分割的监督信息。弱标签无法提供物体具体的形状和位置信息,因而单单依靠弱标签进行预测分割掩码是不可行的。弱标签在不同级别下只对不同物体进行了框选、点或者部分线段轮廓,而没有整个的轮廓信息。这样一来,在使用弱标注数据训练分割模型时,需要在预测每个像素标注信息的同时学习分割网络的模型参数。
针对上述问题,本文提出了一种弱监督学习算法,并通过一定的规则对图像中部分物体的缺失部分进行补偿,其具体实现流程如下:
根据所需要处理的图像构建该图像的邻域图,在构建邻域时,需要参考图像和其相对应的激活映射关系。需要将像素内部及像素周边设定半径范围内像素进行连接。连接的语义相似度可以通过AN进行估算。对于单个的类而言,CAM中的稀疏激活是随着图上的随机游走将稀疏激活传递到周边语义相同的区域,边缘相似度对鼓励语义相似区域进行稀疏激活传播,同时也对边缘不相似区域惩罚稀疏激活传播。这种传播规则会一定程度的对CAM进行修改,通过修改CAM可以恢复图像的形状。这一系列过程作为一个集合,并将大量的类似集合作为训练集进行图像训练。这样一来可以获得分析大量像素处修改的CAM的最大激活相关联的类标签,进而可以进一步合成分割标签。然后通过将大量训练生成的分割标签通过SegNet网络进行二次训练,进而得出用于测试的图像分割模型。
1.4 本章小结
本章首先阐明了图像分割的意义与图像分割的背景,并在此基础上指出研究图图像分割算法的研究目标。其次对国内外弱监督语义分割的发展进行了说明,进而提出了弱监督语义分割所遇到的技术难点图像分割关键算法。还分析了本论文研究的图像分割算法的重点和难点问题。
2 图像分割关键算法的设计
在本章节中,本文主要研究了从弱标记图像学习语义分割网络的问题。在弱标签的各种设置中,图像级标注是最经济和有效的设置之一。在这种情况下,每个训练图像都有其图像类/类别标签。这意味着属于类标签的对象出现在图像中,但是,对象的位置是未知的,本文需要推断对象的像素级位置。因此,训练弱监督语义分割网络的主要任务和难点是如何将图像级标签准确地分配给它们对应的像素。
2.1 神经网络基本概念
2.1.1 卷积层
在卷积神经网络中,本文会在完成图片的基础上进行筛选,先确定一个局部区域,该局部区域面积不用太大也可称其为局部微小区域,然后再通过筛选出的局部的微小区域去扫描完整的图片,然后将所有局部微小区域内所覆盖的节点与下一层的节点进行连接。其基本结构如图2.1所示。
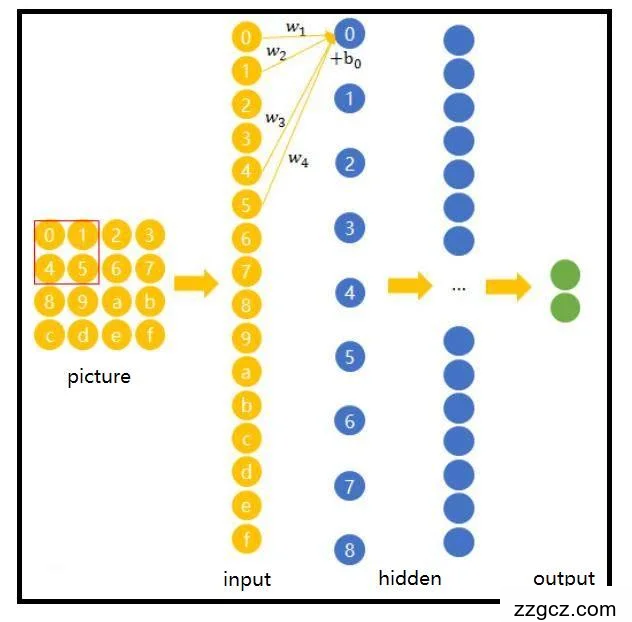
图2.1 局部微小区域
从上图中可以很明显的看出,该局部微小区域呈现出矩阵式,但这并不影响本文把将这些以矩阵形式排列的所有节点展成以向量形式的。可以更清晰的了解卷积层和输入层的连接规则。途中picture上方的红色方框为局部微小区域,局部微小区域的尺寸可以通过认为的进行设定,本图中的尺寸为2*2的尺寸。该局部微小区域会不断进行滑动,在本图中是从左上角区域滑动到右下角区域。滑动过程中局部微笑区域的面积不会发生变化,每次滑动会产生四个权重值,这四个权重值组合起来的矩阵就是卷积核。
卷积核虽然是算法自己通过学习得到的,但是它会与上一层同时进行计算,比如,第n层的某节点0的卷积核数值就是对某个局部微小区域进行线性组合(w1*0+w2*1+w3*4+w4*5)获得的,即局部微小区域内各个节点数值与节点所占权重之积,然后相加。
2.1.2 激励层
激励层的意思是将图像经过卷积层运算之后的输出结果作为输入,然后做一次非线性映射。
如果本文在使用激励的过程中,不施加任何的激励函数,其实质上本文就是默认f(x)=x为激励函数。在激励函数为f(x)=x的情况下可以很明显的得出,每一层的输出结果与上一层的输入结果存在着线性函数的关系。由此可以看出,不管一张完整的图片含有多少层的BP神经网络,其最终的输出结果都是由若干个初始输入结果的线性组合,这种最终输出结果在本质上与使用最原始的感知机理的效果是一样的。
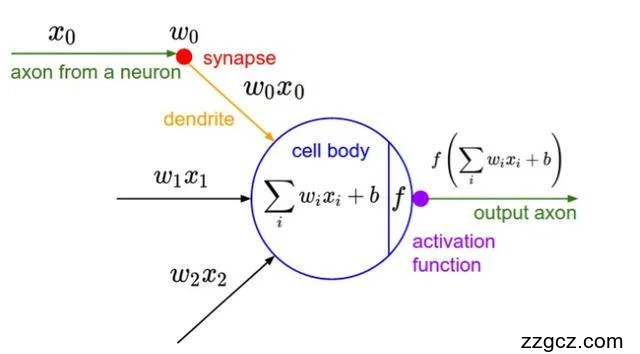
图2.2 激励层
如图2.2所示,图中f代表激励函数,可以清晰的看出其输出结果是由若干个初始向量按照不同的权重进行线性组合。此外,本文常用的几种激励函数有:ReLU、Leaky ReLU、Maxout、Tanh函数。
从图2.3中可以清晰的看出卷积神经网络激励层的基本工作原理,通过将图像经过卷积层运算之后的输出结果作为输入,然后做一次非线性映射。其最终结果代表的含义为对原始图像进行一次非线性修正,然后输出新的修正后图像。修正后图像的特征值也相当于原始图像特征值经非线性修正之后的结果。

图2.3 非线性映射
2.1.3 池化层
虽然本文通过前面介绍的两种操作——卷积操作及激励操作,完成了对输入图像的降维处理及抽取图像的基本特征,但输入图像的特征中其维数还是比较高的。而维数较高不仅会导致较长的计算时间,而且容易导致过拟合的发生。为此,本文一般引入了下采样技术,即池化操作。
池化操作需要在卷积层操作和激励操作之后进行,在此基础上,池化操作主要实现输入特征图像的分块处理。该特征图像就被划分成的多个不相交块,对这些不相交块内的数值进行计算,获得其中的最大值或平均值,进而获得池化后的特征图像。
池化操作的两种类型——均值池化和最大值池化,都可以完成下采样操作的过程,而前者的均值池化是线性函数,后者的最大值化是非线性函数,一般情况下具有非线性函数的最大值池化有更好的下采样操作效果。
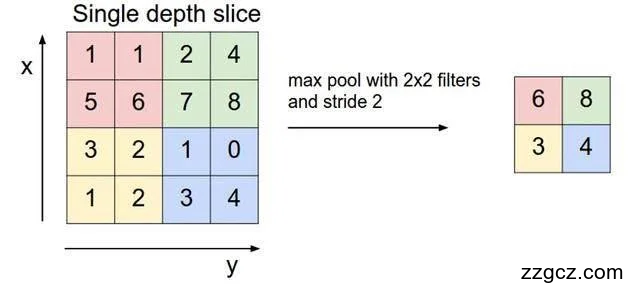
图2.4 非线性函数的max池化
通过上文本文可以认识到卷积核存在的意义是为图像分割算法找到特定的维度信息。但是一个图像中一类形状出现个数总是有限的,其他与想要的形状不同的形状也会在卷积核中形成一个结果,但该结果并不是本文想要的结果,这部分结果进行分析时不会产生作用,因此本文需要池化层这一步操作来剔除掉这些没有作用的卷积核,这样有助于产生更好的识别结果。
2.2 弱监督语义分割标注信息生成
弱监督语义分割的最大难点是弱标签无法提供语义分割所需的全部监督信息。通常都不会包括位置信息和形状信息,但物体的形状信息作为预测分割掩码的关键在图像分割中是非常重要的。因此,在使用弱标注数据训练分割模型时,需要在预测每个像素标注信息的同时学习分割网络的模型参数。
2.2.1 类激活映射热力图
类激活图可视化是通过热力图的方式将输入图像中每个位置的重要程度表达出来,通过类激活图可以直观的看出图像中每个部分的重要程度。有助于了解一张图片的那个部分使得卷积神经网络做出最终的决策,还可以定位图像中特定的目标。
而类激活图仅仅通过将位于不同位置的视觉图案进行加权线性和,然后将其映射成采样所需图像的尺寸。本文可以通过这种方式识别与特定类别最相关的图像区域,计算公式如2-1所示:
Mc(x,y)=wcT f cam(x,y) (2-1)
Mbg(x,y)={1 - max Mc(x,y) }α (2-2)
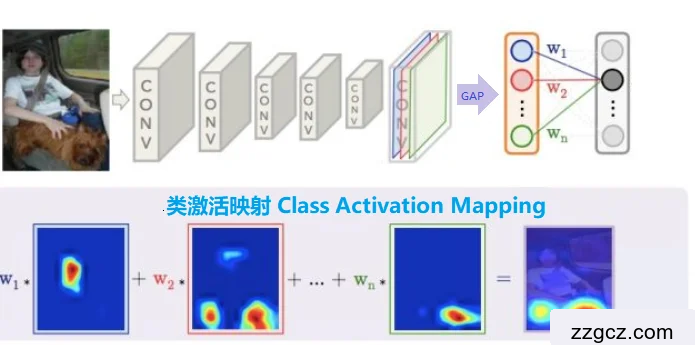
图2.5 类激活映射图计算过程
图2.5详细的解释了CAM算法计算流程,左侧的图片中一个人和狗在车子内部,这个图片为CAM算法的输入,中间的五个CONV就是卷积层处理,在圈基层处理右侧为全局平均池化层,经过该层之后会得到n个节点特征值,最后再通过Softmax输出图片。从最下面一排热力图本文可以看出,最终图片是通过将不同类在每个特征图与对应的不同权重进行乘法运算,然后将不同特征图片乘法运算之后的特征图进行叠加,进而可以输出出不同的类。上图中最终输出的是狗,因此需要将狗这个类对应的权重与各个特征层进行乘法运算,然后加法运算,其热力图结果可以从图2.5右下角热力图中看出,可以清晰的发现热力图可以明显的输出狗的位置。上图中,最下侧的热力图如式2-3所示:
W1*蓝色层+W2*红色层+…+Wn*绿色层=类激活映射(CAM) (2-3)
因此可以CAM的本质其实是一个加权线性和。一般情况下,经过卷积层处理后的大小会小于原图片大小,所以需要将类激活映射到原图片大小,在此基础上才可以进行加权线性和。这样一来才可以看出该输出重点关注图片的区域位置。因此本文可以得出结论,最终观察到的结果可能是原图像中的任意部分,结果的具体位置与选取的类和其相对应加权有关。
由图2.6可以看出粉色(人脸部分)和黑色(背景)区域是已确定标签区域,而其他白色的区域是CAM算法不能确定提取的部分。

图2.6 CAM算法生成的算法种子
CAM技术虽然适用于很多场合,但其也有一些不可避免的缺陷,一方面本文必须要调整网络结构,但这种情况会不利于训练,其次该方法只是一种分类可视化技术,解决回归问题时效果不佳。
2.2.2 生成语义相似度标签
在训练AN的标签用时如果只有图像级标签,则需要额外的将训练图像的CAM作为监督来源。实际情况下,CAM的误差是非常大的,但是可以通过对CAM进行一系列处理,来获取的语义相似度的可靠监督。
本文需要从CAM中分别出图像那些区域最大概率为背景,那些区域最大概率为前景。分析出最大置信区域后,取样时只从这些区域进行选取。这样一来可以极大程度的提高所获取的相邻采样坐标之间的语义等价准确度。其具体操作如下:首先本文可以参考公式2-2,可以减小参数α来达到增大Mbg的目的,此时CAM中对象的无关紧要激活得分受背景得分主导,进而通过这种方式可以初步估计前景的高置信区域。同时如果可以增大参数α来达到减小Mbg的目的,也可以初步估计背景的高置信区域。这部分结果可以参考图2.7中的(a)小图。其次,本文需要对每对坐标进行二元相似类标签分配。分配过程中需要参考置信区域内确定的类标签。为了提高成对相似标签的准确性,如果两个标签中其中一个为中性标签,则本文需要舍弃这对标签。若两个非中性坐标(xi,yi)和(xj,yj)的类相同,则其相似标签将会被赋值1,若其的类不相同,则其相似类标签会被赋值0。可以参考图2.7,其中Positive为积极的也就是相似的,Negative为消极的也就是不相似的,Don’t care就是不关心点,也就是中性的点。
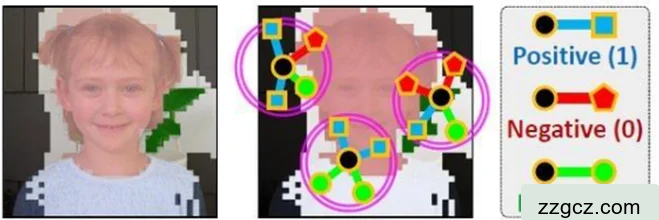
(a) (b)
图2.7 生成语义相似标签的概念图
图2.7就是生成语义相似标签的具体过程,其中第一步主要完成了确定背景和前景最大置信区域的工作。可以从图中看出,黑的部分为背景最大置信区域、粉色和绿色部分为前景最大置信区域、其余部分为不关心区域。而下一步则在最大置信区域内选取坐标进行AN训练,忽略不关心区域的坐标之后,可以得到最大置信区域内坐标的相似标签。例如图(b)中左上角第一个最小半径,黑色部分为相似坐标,粉色部分坐标为不相似坐标,白色部分坐标为不关心坐标,直接忽略。
2.2.3 AN网络训练
位置相近的像素属于同一个类的概率会大一些;生成训练标签时,需要预先处理物体区域的假阳性块和缺失块。在此基础上通过网络生成包含丰富上下文的特征图,该特征图中不同的像素会对应一个不同的向量V,当像素的类相同时,其V也会比较相似。
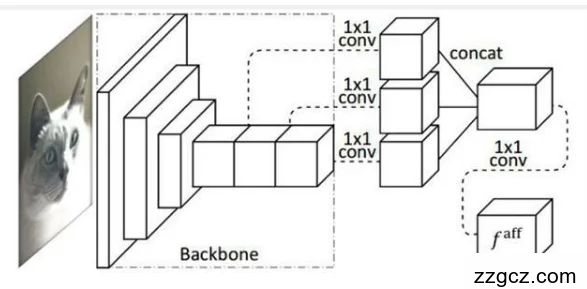
图2.8 AN基本网络
在训练的过程中首先需要知道哪些像素具有相同的或者不同的标签,然后将他们生成训练监督信息。其中相似度标签可以通过CAM计算得出,如图2.9所示,相同颜色的方块代表着相同的标签,不同颜色的方块就代表着不同的标签,由相同标签和不同标签的像素对之间的相关性,通过训练指导不确定标签(橙色像素)与确定标签的像素对之间的相关性,这是一种通过周围有监督训练部分无监督的数据的一种方法。
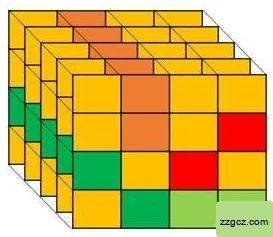
图2.9 特征图的表达方式
在网络的反向传播中需要通过计算损失函数,从而使网络的反向传播的梯度下降,达到泛化的目的,训练损失函数需要以下三个部分:
(1)定义相关点集合P:d为欧式距离,γ为5
P = {(i,j) | d ( (xi,yi), (xj,yj) ) <γ, i≠j } (2-3)
(2)将相关点集合P根据pixel pairs属于相同还是不同类集合P+划分为P+bg,和P+fg。
p+ ={(i,j) | (i,j)∈P,Wij*=1} (2-4)
p- ={(i,j) | (i,j)∈P,Wij*=0} (2-5)
(3)损失函数
(2-6)
其中,Wij =exp { - || f aff (xi,yi) - f aff (xj,yj) ||},i和j表示第i行第j列。
若像素属于同一个类别,则该类像素特征提取之后得到的特征一般是相似的,同时不同类别像素的特征一般都是完全不同的。因此可以以此为依据在通过网络训练的方式对不确定的像素进行判断。最终使不确定的像素的特征与已经确定的某个像素特征相似。
2.2.4 利用AN网络修改CAM
AN网络修改CAM时首先需要计算出确定的像素特征与不确定的像素特征之间的均值,在此基础上,在根据比较不确定像素特征与已确定像素特征值之间相似度的大小,选择最相似的已知像素特征的类作为不确定像素的类。AN预测的局部语义相似度被转换为转移概率矩阵,这使得随机游走能够识别图像中的语义边界,并鼓励它在这些边界内扩散激活分数。通过多次实验,本文发现语义转换矩阵的随机游走可以极大程度的改善CAM的质量,进而获得更清晰更准确的图像分割标签。从图2.10中可以清楚的看出没有经过随机游走的CAM图像分割标签比较粗糙和模糊,而处理后的分割标签会更加精确更加清晰。
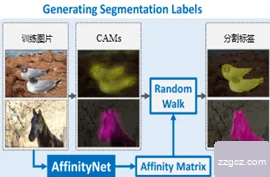
图2.10利用AN网络修改CAM
获取到输入图像之后,AN会通过生成卷积特征图的方式计算映射中的不同特征之间的语义相似度。语义相似度可以进一步计算出相似度矩阵W,该矩阵对角元素均为1。随机游走的转移概率矩阵T为 D-1Woβ,其中Dii= Wij β。i和j表示第i行第j列,超参数β具有大于1的值,使得原始相似度矩阵的Hadamard幂Woβ,忽略W中的无关紧要的相似度。因此,使用Woβ而不是W使本文的随机游走传播更加保守。计算对角矩阵D用于Woβ的行为方向归一化。
通过将随机游走T乘以CAM来实现语义传播的单步处理。然后进一步进行迭代运算,直到游走完图片的全部区域,或者迭代次数达到预设次数。在此基础上再进行Mc*运算,修改后的c类CAM由下式给出:
vcc(Mc*) = Tt · vcc(Mc) , c∈C∪{bg} (2-7)
其中,vcc(·)表示矩阵的矢量化,t是迭代次数。
2.3 训练SegNet网络
在完成上一章节利用AN修改CAM之后,可以获取更加准确的图像分割标签。单CAM的尺寸会小于原始的图像尺寸,因此需要对其进行上采样使其到达原始图片的分辨率,上采样过程中需要使用双线性差值并通过dCRF进行整理。在此基础上本文获得训练图像的分割标签时可以通过调整上采样的CAM中的每个像素处的最大激活分数相关联的分类标签。
2.3.1 残差网络基本结构
通过上述过程获得的图像分割标签可以被用于训练分割网络的监督。本文的语义分割训练卷积使用的是resnet38,因为本文提供了训练图像的分割标签。ResNet38提供残差网络结构可以帮助本文将网络层分成高达千余层,这样一来可以极大的提高分类效果,其基本结构可以参考图2.11,从图中可以清晰的看出resent网络具有跳跃结构。
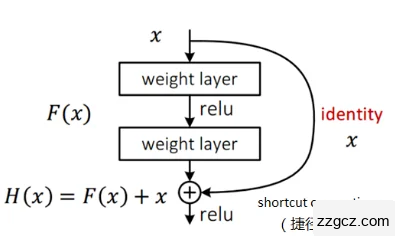
图2.11 resnet网络
对图2.11的具体解释如下:若输入的神经网络为x,通过一定规则进行变换后得到期望输出H(x),期间的转换规则可以通过权重法一层一层进行处理,也可以通过一种捷径连接进行处理,该捷径连接最终也可以获得期望输出。但若想掌握该类学习模型是非常困难的。
2.3.2 残差网络的特性
与Plain network相比,resnet具有的特性如下:
- 网络层数并非越多越好:若网络层数较多,当需要进行反传时会发生较为严重的梯度弥散,如果在反传过程中某一步出现导数小于1的情况,则再经过若干次反传之后,得到的数据已经无法表示梯度了。通俗的讲就是从深的网络层往上反传时,若中间部分导数小于1可能传递到浅层之后浅层网络已经无法获取梯度信息。所以选择网络深度时,要选取适当的层数,在适当的层数内增加网络层数会的效果会更好,但超过这个临界值,随着层数的增加,效果会越变越差。
- 特征冗余:再进行正向卷积过程中由于并非提取图像的全部信息,因此,随着层数的增加,图像数据丢失会越来越严重,到最终只能获得原始图像的部分特征信息。因此时常会出现欠拟合的现象。
- Shortcut结构:可通过加入shortcut结构保留更多原始信息,提方式是通过给每一层的block额外加入上一层图像的全部信息,通过这样的操作可以保留更多的原始信息。加入shortcut后相当于一个ensemble模型,输出结果为前面各个block及其组合进行投票选择的结果。
2.4 AN算法总流程
在本章节中,本文提出了一种基于AN组件的DNN框架,该框架可以通过原始图像预测出相邻坐标之间的语义相似度。其无需外部额外的监督便可以补偿物体形状的缺失信息。
为了解决在没有额外数据监督的条件下学习AN问题,本文将初始训练图像的CAM指定为监督源。但CAM会出现不准确的情况并会遗漏一些信息,但从局部角度来看一般都是正确的,可以完成局部小区域的语义相似度判断。从而给局部坐标进行准确标记。为了提高定位语义相似度的标签的可靠程度,在数据处理时本文需要选择性的放弃一些数据,一般来说激活分数低的区域本文将其放弃掉,保留下的区域一般都是高置信的背景区域或者前景区域。进行训练时仅在这些保留下来的区域进行样本选取,为了提高成对相似标签的准确性,如果保留区域内两个标签中其中一个为中性标签,则本文需要舍弃这对标签。若两个非中性坐标(xi,yi)和(xj,yj)的类相同,则其相似标签将会被赋值1,若其的类不相同,则其相似类标签会被赋值0。具体详细步骤如下所示,流程图如图2.12所示:
1.根据所需要处理的图像构建该图像的邻域图,在构建邻域时,需要参考图像和其相对应的激活映射关系。需要将像素内部及像素周边设定半径范围内像素进行连接。连接的语义相似度可以通过AN进行估算。
2.对于单个的类而言,CAM中的稀疏激活是随着图上的随机游走将稀疏激活传递到周边语义相同的区域,边缘相似度对鼓励语义相似区域进行稀疏激活传播,同时也对边缘不相似区域惩罚稀疏激活传播。这种传播规则会一定程度的对CAM进行修改,通过修改CAM可以恢复图像的形状。
3. 上述系列过程作为一个集合,并将大量的类似集合作为训练集进行图像训练。这样一来可以获得分析大量像素处修改的CAM的最大激活相关联的类标签,进而可以进一步合成分割标签。然后通过将大量训练生成的分割标签通过SegNet网络进行二次训练,进而得出用于测试的图像分割模型。
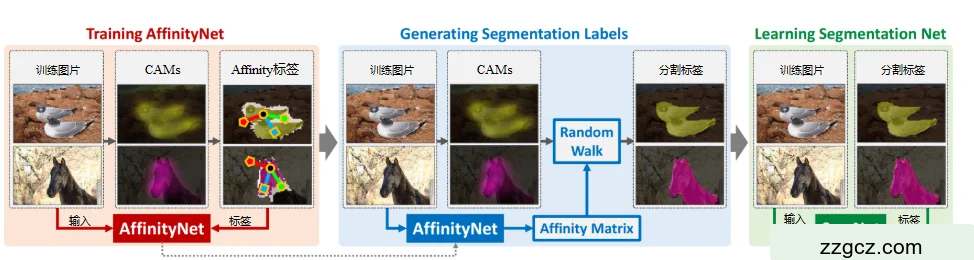
图2.12 AN算法总流程图
2.5 本章小结
本章首先介绍了深度学习弱监督学习的图像分割的总体流程图,主要算法分别是AN和SegNet,然后介绍了AN的基本构造,分别包括CAM算法生成像素种子,生成语义相似度标签,使用AN网络训练图像标签,利用AN网络修改CAM,最后介绍了训练语义分割网络,使用的骨干网络是resnet38,通过各种实验证明了resnet38网络的可行性。
3 实验结果与分析
3.1 实验系统开发环境与平台
随着人工智能、5G、大数据、深度学习等高新技术行业的快速发展,计算领域正面临这天翻地覆的变化,深度学习、图像识别逐渐走入到人们视线,这使得人们越来越重视计算机的运算性能以及显卡要求。图像识别的深度学习的训练和推理离不开NVIDIA GPU加速,同时NVIDIA公司出了专门用于图像处理的CUDA平台,并提供了CUDNN的神经网络加速库。因此本文决定选用NVIDIA的GPU,其中实验所需具体的软硬件配备详细信息如下:
CPU:Intel Core i7-7700HQ
内存:16GB DDR4
硬盘:256GB
GPU:NVIDIA GeForce GTX 1060
开发软件:Pycharm & pyorch
本系统在window10操作平台进行开发。开发软件为Pycharm,使用的版本为2018a版,开发语言为python语言。当前开源的框架中,没有哪一个框架能够在灵活性、易用性、速度这三个方面有两个能同时超过PyTorch,pytorch的安装方式如下图3.1所示,pyorch的使用如图3.2所示。

图3.1 pytorch的安装方式
图3.2 pytorch的使用
3.2 VOC训练数据集
PASCAL VOC为广大热衷于图像识别和分类的用户提供了一整套标准化的数据集,并且该公司从2005年其已经举办了七届图像识别挑战赛,每届挑战赛都有非常丰富的奖金,以此来刺激用户对图像识别进行研究。
 |  |
图3.3 voc数据集和标注文件
3.3 AN网络训练
本节将介绍在该框架结构中采用的DNN架构的详细信息。本文所介绍的方法可以通过使用现有的其他DNN实现相同的目的。网络框架中的三个DNN都是建立在相同的骨干网络上。其主干为模型ResNet38,该模型为具有38个宽通道的卷积层。骨干网络的获取步骤如下:首先去除原始模型的最终GAP和全连接层;然后在此基础上将最后三个级别的卷积层替换为具有公共输入步幅1的带孔卷积,并且调整它们的扩张率以使得骨干网络将返回步幅8的特征图。已知带孔卷积提高分割质量的方式是通过扩大自身感受视野,在这个过程中也不会牺牲特征图的分辨率。经过多次实验本文发现当将这种方法用于弱监督模型CAM和AN中时会提高模型的清晰程度和准确程度。
- 网络计算CAM
本文通过在骨干网络顶部按顺序添加卷积层、平均池化层、全连接层来获得此模型。其中卷积层具有512个3×3通道,其作用为更好地适应目标任务,池化层主要用于特征映射聚,而全连接层在整个网络中用于分类操作。
- AN
AN用于聚合骨干网络的多级特征映射,通过多级特征映射后,后续相似度计算时可以从不同视野中提取语义信息进行参考。因此本文选择骨干网络的最后三个级别输出的特征映射。在聚合之前,对于第一,第二和第三特征图,它们的信道维度分别减少到128,256和512,分别由单个1×1卷积层。然后将特征映射连接成具有896个通道的单个特征映射。本文最终在顶部添加了一个1×1卷积层和896个通道用于自适应。
- 分割模型
本文构建分割网络resnet38时严格遵守其相关设计规则。在基础的骨干网络上层还增加了两个更为复杂的卷积层。其通道数量分别为512和21,扩张率均为12。生成的网络在下一节中称为“Ours-ResNet38”。
- 反向传播微调
本文DNN的骨干网络在ImageNet上进行了预训练。 然后,Adam在PASCAL VOC 2012上对整个网络参数进行了微调。一般情况下在训练DNN时使用水平翻转、随机裁剪、颜色抖动等数据增强技术[16]。此外,对于除AN之外的网络,本文在训练期间随机缩放输入图像,这对于在网络上施加比例不变性是有用的。
- 参数设置
公式(2.2)中的α默认为16,并分别变为4和24以放大和减弱背景激活值。 本文设置等式(2.3)中的γ为5。此外,在等式(2.7)中的tt固定为256。对于dCRF,本文使用原始代码中给出的默认参数。
3.4 图像分割关键算法评价标准
Mean Intersection over Union(MIoU,均交并比),为语义分割的标准度量。其计算两个集合的交集和并集之比,在语义分割问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。这个比例可以变形为TP(交集)比上TP、FP、FN之和(并集)。在每个类上计算IoU,然后取平均。
(3.1)
其中,pij表示真实值为i,被预测为j的数量。
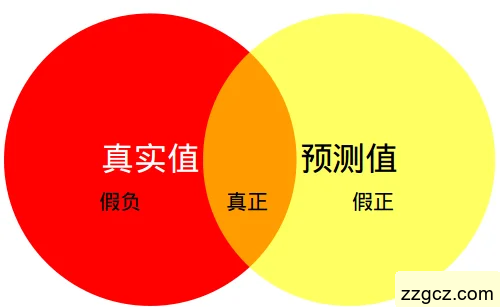
图3.4 MIOU5示例
3.5 AN网络图像分割实验
3.5.1 本文算法实验结果与分析
本文测量标签合成方法性能时采用mIoU技术,测量主要是在在真实分割情况和生成的分割标签之间进行的。对于模块研究,本文的方法分为三个部分:CAM,RW&AN和dCRF。为了证明所提出的方法的优势,本文还报告了超像素池化网络(SPN)的得分,其将CAM与超像素结合作为用于生成具有图像级标签监督的分割标签的附加线索。如表3.1所示,即使本文的CAM在生成的分割标签的准确度方面比Kwal的CAM和SPN都高,当本文使用CAM+RW时,分割标签的准确度与本文自己单单使用CAM相比明显提高了很多,通过随机游走和学习的语义相似度分割标注的质量得到显着提高,证明了AN的有效性。最后,dCRF进一步略微提高了分割标签的准确度,本文使用最后一个版本作为学习分割网络的监督。
表3.1 mIoU中合成分割标签的准确度
Kwak et al.[16]
| ours
| |||
CAM
| SPN
| CAM
| CAM+RW
| CAM+RW+dCRF
|
30.5
| 43.8
| 48.0
| 58.1
| 59.7
|
图3.5中显示了合成分割标签的例子,其中可以看到AN的随机游走有效地处理CAM中的错误和缺失区域。为了说明AN在此过程中的作用,本文还通过检测特征图fafffaff上的边缘来可视化图像的预测语义相似度,并观察到AN具有检测语义边界的能力,尽管它是使用图像级标签进行训练的。由于这样的边界惩罚语义上不同的对象之间的随机游走传播,所以合成的分割标签可以恢复准确的对象形状。

图3.5 合成分割标签
其中(a)图为输入原图,(b)图为语义分割标注的groundtruth,(c)图为目标分类的CAM标签,(d)图为AN预测的语义标签,黑色区域表示边界,白色表示内部,(e)图将语义标签叠加到原图上面。
3.5.2 AN算法与其他算法的比较
图3.6显示了Ours-ResNet38的定性结果,并将它们与CrawlSeg [17]的定性结果进行了比较,后者是使用图像级监督的当前最新方法。 本文的方法仅依赖于图像级标签监督,即使CrawlSeg利用额外的视频数据来合成分割标签,也可以产生更准确的结果。

图3.6 PASCAL VOC 2012验证集的定性结果
其中(a)为输入图像,(b)为真实分割,(c)为CrawlSeg获得的结果,(d)为本文的结果-ResNet38。
与CrawlSeg相比,CrawlSeg是基于图像级标签监督的当前最先进的模型,本文的方法更好地捕获更大的对象区域并且更不容易遗漏对象。本文的结果的对象边界比CrawlSeg的对象边界更平滑,因为本文不将dCRF应用于最终结果。 在补充材料中可以找到更多结果。
3.6 本章小结
本章针对本文设计的算法,首先介绍训练深度学习网络的开发环境和网络框架,然后介绍了训练的voc数据集,将voc数据集放入深度学习网络框架中进行训练,通过设置不同的参数使网络泛化能力达到最优,其次介绍了评价深度学习网络性能的指标,最后通过指标发现本文算法在正确率上表现超越比已有的算法,经过MIOU指标评估后本文研究模型在弱监督学习的语义分割上面具备更好的泛化能力。
4 总结与展望
4.1 总结
分割标签的不足是在自然环境中使用语义分割的主要障碍之一,为了解决这个问题,本文提出了一种新颖的框架,可以根据图像级别的标签生成图像的分割标签。在这种弱监督的环境中,已知训练的模型将局部鉴别部分而不是整个对象区域分割。本文的解决方案是将这种定位响应传播到属于同一语义实体的附近区域。在本文中,本文提出了一种基于AN组件的DNN框架,该框架可以通过原始图像预测出相邻坐标之间的语义相似度。其无需外部额外的监督便可以补偿物体形状的缺失信息。其具体流程如下:
1 根据所需要处理的图像构建该图像的邻域图,在构建邻域时,需要参考图像和其相对应的激活映射关系。需要将像素内部及像素周边设定半径范围内像素进行连接。连接的语义相似度可以通过AN进行估算。
2.对于单个的类而言,CAM中的稀疏激活是随着图上的随机游走将稀疏激活传递到周边语义相同的区域,边缘相似度对鼓励语义相似区域进行稀疏激活传播,同时也对边缘不相似区域惩罚稀疏激活传播。这种传播规则会一定程度的对CAM进行修改,通过修改CAM可以恢复图像的形状。
3. 上述系列过程作为一个集合,并将大量的类似集合作为训练集进行图像训练。这样一来可以获得分析大量像素处修改的CAM的最大激活相关联的类标签,进而可以进一步合成分割标签。然后通过将大量训练生成的分割标签通过SegNet网络进行二次训练,进而得出用于测试的图像分割模型。
最后通过实验证明了本文算法在正确率上表现超越比已有的算法,本文的单CAM图像分割标签准确率可以达到48%,CAM+RW的准确率可以达到58.1%,CAM+RW+dCRF的准确率可以达到59.7%远高于Kwak的CAM30.5的准确率和SPN43.8的准确率经,因此本文研究模型在弱监督学习的语义分割上面具备更好的泛化能力。
4.2 展望
弱监督语义分割的难点在于其标签提供的语义分割的信息并不完善,弱标签只能提供部分用于语义分割的监督信息。弱标签无法提供物体具体的形状和位置信息,因而单单依靠弱标签进行预测分割掩码是不可行的。因此,为了利用弱标注数据训练分割模型,应当在训练期间预测每个像素的标注信息并同时学习分割网络的模型参数。未来的弱监督学习的语义分割会集中于两个方面的研究:
1)同时的弱监督物体检测和语义分割,这两个任务可能会相互促进;
2) 半监督的物体检测和语义分割。
虽然现在的弱监督方法取得了一定的成绩,但是和全监督方法还有一定的差距。本文希望通过结合更多弱监督的标注样本和现有的少量的标注样本通过半监督的方式训练出性能更好的语义分割模型。
参考文献
- Shelhamer E , Long J , Darrell T . Fully Convolutional Networks for Semantic Segmentation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 39(4):1-1.
[2]Papandreou G , Chen L C , Murphy K , et al. Weakly- and Semi-Supervised Learning of a DCNN for Semantic Image Segmentation[J]. Computer Vision and Pattern Recognition, 2015:432-455.
[3]Zhou B , Khosla A , Lapedriza A , et al. Learning Deep Features for Discriminative Localization[J]. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016:2921-2929.
[4]Kolesnikov A , Lampert C H . Seed, Expand and Constrain: Three Principles for Weakly-Supervised Image Segmentation [J]. European Conference on Computer Vision, 2016:695-711.
[5]Oh S J , Benenson R , Khoreva A , et al. Exploiting saliency for object segmentation from image level labels[J]. Computer Vision and Pattern Recognition, 2017:4410-4419.
[6]Shimoda W , Yanai K . Distinct Class-Specific Saliency Maps for Weakly Supervised Semantic Segmentation [C]. Proceedings of European Conference on Computer Vision, 2016:218-234.
[7]Pinheiro P O , Collobert R . From Image-level to Pixel-level Labeling with Convolutional Networks [J]. Proceedings of European Conference on Computer Vision and Pattern Recognition, 2015:1713-1721.
[8]Kwak S, Hong S, Han B. Weakly Supervised Semantic Segmentation Using Superpixel Pooling Network [C]. Proceedings of AAAI conference on Artifical Intelligence, 2017:4111-4117.
[9]Pathak D, Krähenbühl, Philipp, Darrell T . Constrained Convolutional Neural Networks for Weakly Supervised Segmentation [J]. Proceedings of IEEE International Conference on Computer Visio, 2015:1742-1750.
[10]Bearman A , Russakovsky O , Ferrari V , et al. What's the Point: Semantic Segmentation with Point Supervision [J]. Proceedings of European Conference on Computer Vision, 2016:549-565.
[11]Oh S J , Benenson R , Khoreva A , et al. Exploiting saliency for object segmentation from image level labels[J]. Computer Vision and Pattern Recognition, 2017:4410-4419.
[12]Wei Y , Liang X , Chen Y , et al. STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017, 39(11):2314-2320.
[13]Dai J , He K , Sun J . BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation [J]. Proceedings of IEEE International Conference on Computer Visio, 2015:1635-1643.
[14]Saleh F , Aliakbarian M S , Salzmann M , et al. Built-in Foreground/Background Prior for Weakly-Supervised Semantic Segmentation [J]. Proceedings of European Conference on Computer Vision, 2016:413-432.
[15]Kolesnikov A , Lampert C H . Improving Weakly-Supervised Object Localization By Micro-Annotation [J]. Proceedings of the British Machine Vision Conference. 2016:92.
[16]S. Kwak, S. Hong, and B. Han. Weakly supervised semantic segmentation using superpixel pooling network [C]. In Proceedings of the AAAI Conference on Artificial Intelligence(AAAI), 2017:4111–4117.
[17]S. Hong, D. Yeo, S. Kwak, H. Lee, and B. Han. Weakly supervised semantic segmentation using web-crawled videos [C].In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR),2017: 7322–7330.