A114-基于ConvNeXt和resnet模型对比的矿石种类识别
【购买前必看】
1、关于我们:
我们是全职的技术团队,跟闲鱼上大部分兼职都不一样,所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
2、关于业务
我们只做python,尤其擅长sklearn机器学习/torch深度学习/django/flask/vue全栈开发。注意:号称java/c/php啥都会的那100%是骗人的,淘宝上这种虚假宣传特别多!。
3、关于项目:
我们从2018年开始,就专注于毕设、数学建模、会议期刊论文,已有6年,积累了数百个项目,案例官网:www.zzgcz.com。更多私密项目无法展示,联系微信定制:zzgcz_com。
4、关于售后
1)敢承诺100%项目均在本地运行通过,包远程运行安装。
2)所有项目都是我们自己写的,二次修改起来非常容易。
5、关于定制
我们定制开发90%来源于老客户推荐。淘宝上基本被中介垄断了,抽成高达50%以上。他们的模式是:填资料拉群找兼职技术,诱骗你下单,要么技术摆烂最后一天说做不了全退,要么给你一堆烂代码让你退一半,退款率在80%以上。
我们全职定制1-2天可完成,没有中介费!远程验收满意后再付全款
1. 项目简介
本文提出了一种基于深度学习的矿石种类识别方法,通过对比 ConvNeXt 和 ResNet50 两种卷积神经网络模型的性能,探索其在矿石分类任务中的表现差异。实验使用自定义矿石图像数据集,包含7种矿石类别,数据集通过预处理(如图像缩放、标准化)后分为训练集和测试集。
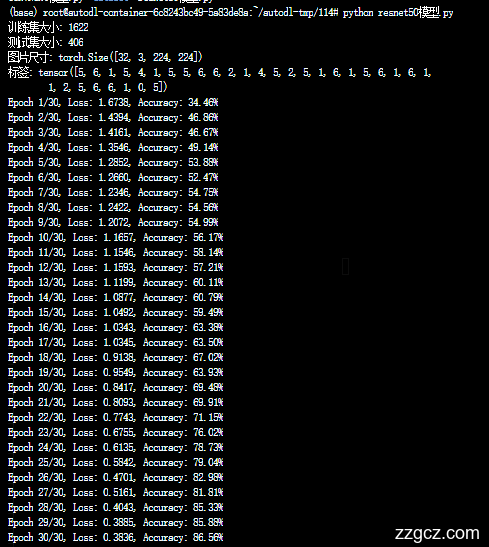
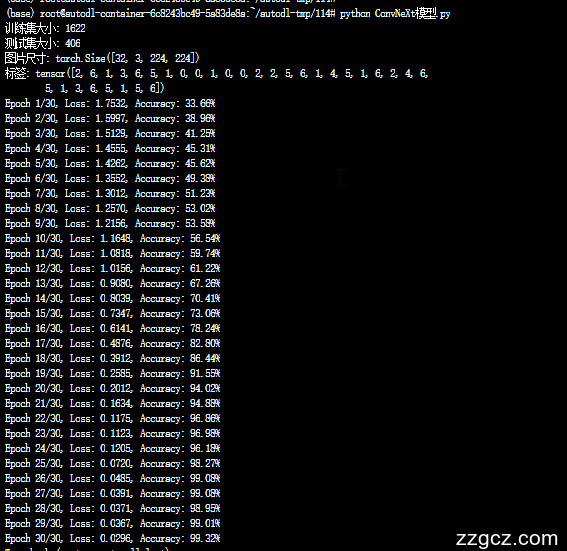
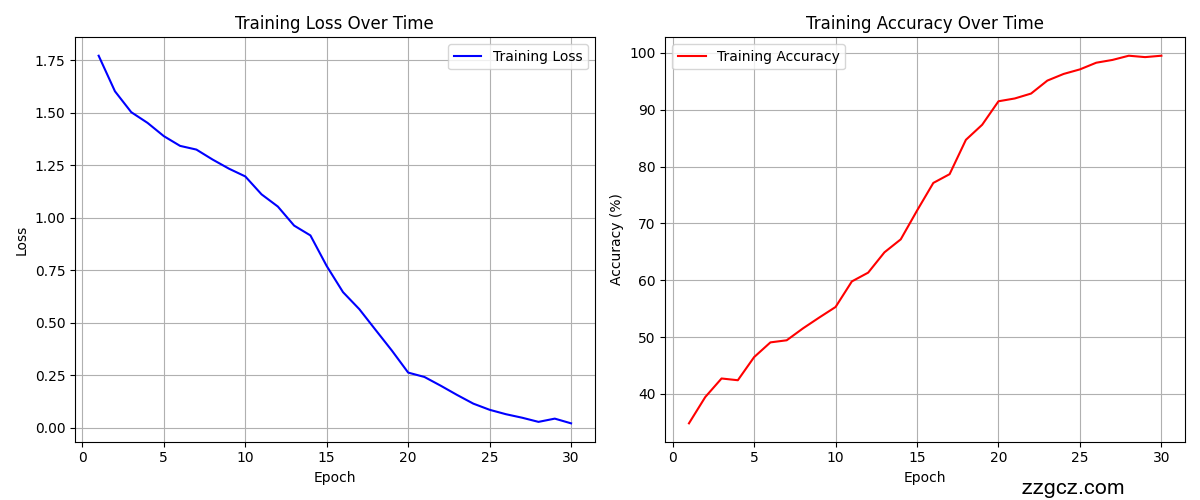
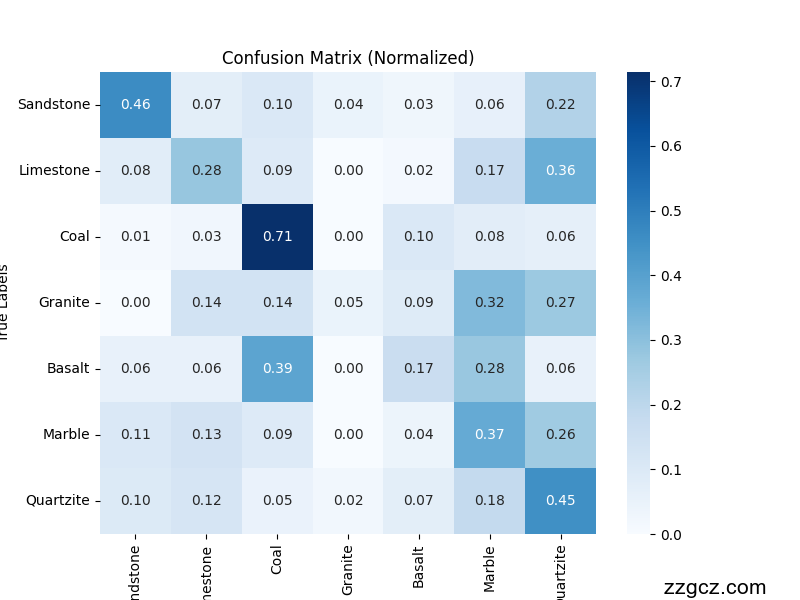
运行结果对比左resnet。右convnext【此为全量数据从头训练结果可直接引用,如需增加对比模型或者修改自定义数据,请联系:zzgcz_com】
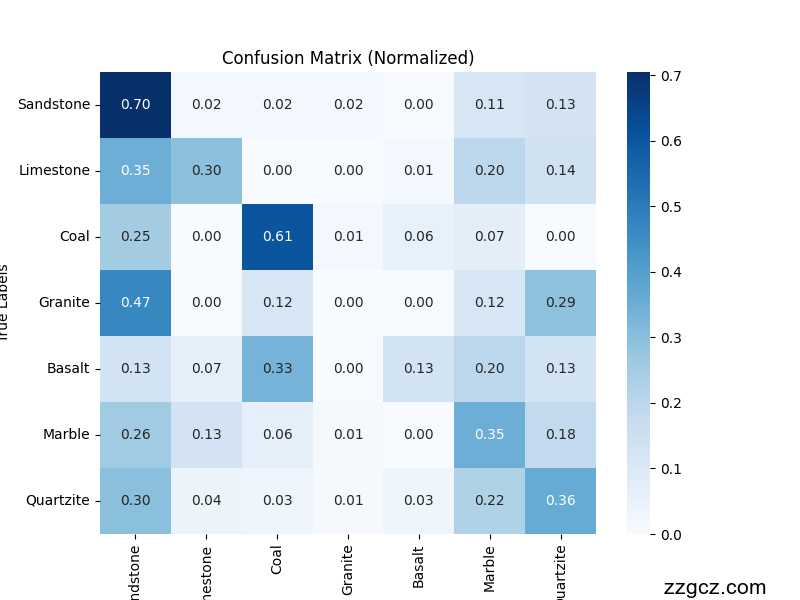
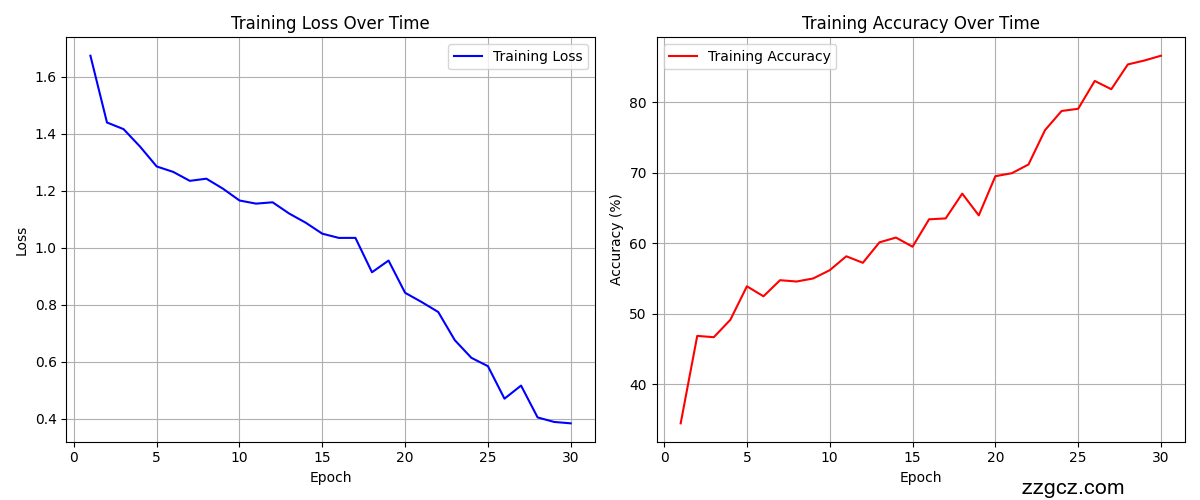
3. 数据集与预处理
本项目使用的矿石种类识别数据集主要由不同种类的矿石图像组成,这些图像用于训练、验证和测试模型。数据集的特点在于其包含了多样化的矿石外观,如不同的纹理、形状和颜色,从而模拟真实环境中的识别任务。通过这些多样化的数据,模型可以更好地学习如何识别复杂的视觉模式,提高在实际应用场景中的泛化能力。
在数据预处理方面,本项目实现了从原始数据到模型可用格式的完整流程。首先,图像数据被读取并转换为适合模型输入的标准格式。为了增强模型的鲁棒性,项目使用了paddle.vision.transforms库进行一系列数据增强操作,包括随机裁剪、旋转、水平翻转和颜色抖动等。这些数据增强技术通过增加训练数据的多样性来减少模型过拟合的风险,使其更能适应不同环境中的图像输入。
数据归一化也是预处理的重要步骤,将每个图像像素值缩放至模型要求的范围(如0到1或-1到1)。此操作确保数据在输入时具有一致的尺度,从而帮助模型在训练过程中更快收敛,提高训练稳定性。此外,项目在数据加载阶段实现了批量处理和数据打乱,这样可以确保训练时的样本随机性,提高模型学习的有效性。
虽然该项目的主要关注点是深度学习模型的训练,但其数据预处理部分通过系统化的步骤和模块化的设计,确保了数据清洁、格式标准化及数据增强策略的执行。通过这些预处理措施,模型得以从更丰富和更有代表性的数据中学习,从而提升最终的分类性能和应用效果。


4. 模型介绍
ConvNeXt 模型结构:一种现代卷积神经网络的演进
- 引言与背景
随着深度学习在计算机视觉领域的快速发展,卷积神经网络(Convolutional Neural Networks, CNNs)长期占据主导地位。从 AlexNet(2012)到 ResNet(2015),再到 EfficientNet(2019),CNN 架构通过引入残差连接、更高效的模块设计和自动搜索技术不断提升性能。然而,2020 年 Vision Transformer(ViT)的出现打破了这一格局,其基于自注意力机制的设计在 ImageNet 等基准数据集上表现出色,挑战了 CNN 的统治地位。尽管如此,ViT 的计算复杂度和对大规模数据的依赖也暴露了其局限性,促使研究者重新审视 CNN 的潜力。
ConvNeXt 是由 Facebook AI Research(FAIR)团队于 2022 年提出的新型卷积神经网络,旨在结合 CNN 的固有优势和 Transformer 的现代设计思想,打造一种高效、强大的视觉模型。论文《A ConvNet for the 2020s》(Zhuang Liu et al., 2022)详细阐述了其设计过程,强调从经典 ResNet 出发,通过逐步引入 Transformer 的关键特性,最终构建出性能媲美甚至超越 ViT 的卷积网络。ConvNeXt 的核心理念是“现代化” CNN,使其适应当前视觉任务的需求,同时保留 CNN 的计算效率和局部特征提取能力。
- ConvNeXt 的设计理念
ConvNeXt 的设计并非从零开始,而是以 ResNet-50 和 ResNet-200 为基准,通过一系列系统性的改进逐步演化而来。其目标是回答两个问题:
-
CNN 是否仍然具有竞争力? 在 Transformer 主导的时代,CNN 是否可以通过架构优化重新夺回性能优势?
-
如何从 Transformer 中汲取灵感? ViT 的成功归功于大核卷积、全局感受野和层归一化等特性,这些是否可以移植到 CNN 中?
设计过程中,作者采用了“现代化”策略,即从经典的 ResNet 出发,逐步引入以下关键特性:
-
更大的卷积核:从 3×3 升级到 7×7,增强感受野。
-
倒挂瓶颈结构(Inverted Bottleneck):借鉴 Transformer 的 MLP 设计。
-
层归一化(LayerNorm):替代传统的批量归一化(BatchNorm)。
-
深度卷积(Depthwise Convolution):降低计算复杂度。
-
微调激活函数和正则化:优化训练动态。
这些改进并非随意堆砌,而是通过大量实验验证,确保每一步都能提升性能,最终形成一个统一的 ConvNeXt 家族,包括 Tiny、Small、Base 和 Large 等变体。
- ConvNeXt 的整体架构
ConvNeXt 采用层次化的多阶段(stage)设计,类似于 ResNet 和 ViT,输入图像通过一系列下采样和特征提取模块逐步处理,最终输出分类结果。其架构可以分为以下几个主要部分:
3.1 输入与 Stem 层
-
输入: ConvNeXt 接受标准 RGB 图像输入(如 224×224×3)。
-
Stem 层: 传统的 ResNet 使用 7×7 卷积(步幅 2)加最大池化进行初始下采样,而 ConvNeXt 改为 4×4 卷积(步幅 4),直接将空间分辨率降低 4 倍,输出通道数根据模型变体设定(如 ConvNeXt-T 为 96)。随后接一个 LayerNorm 层(channels-first 格式),用于稳定特征分布。
-
设计意义: 这种简化的 Stem 层减少了计算量,同时与 Transformer 的 patchify 操作(将图像切分为固定大小的 patch)有异曲同工之妙。
3.2 主干网络(Stages)
ConvNeXt 的主干由 4 个 stage 组成,每个 stage 包含多个 Block(基本构建模块)和一个下采样层。特征图的空间分辨率在每个 stage 开始时通过下采样降低(通常为 2 倍),通道数逐步增加。以下是具体配置(以 ConvNeXt-Base 为例):
-
Stage 1: 输入 56×56×96,包含 3 个 Block,输出通道 96。
-
Stage 2: 输入 28×28×192,包含 3 个 Block,输出通道 192。
-
Stage 3: 输入 14×14×384,包含 27 个 Block,输出通道 384。
-
Stage 4: 输入 7×7×768,包含 3 个 Block,输出通道 768。
下采样层: 除 Stem 外,其他 stage 间的下采样由 LayerNorm 加 2×2 卷积(步幅 2)实现,通道数翻倍。这种设计比 ResNet 的 1×1 卷积加池化更简洁,同时保持了特征提取的稳定性。
3.3 Block 模块
Block 是 ConvNeXt 的核心创新点,其结构受到 Transformer 的 MLP 模块和 ResNet 的 Bottleneck 启发。每个 Block 包含以下组件:
-
深度卷积(Depthwise Convolution):
-
使用 7×7 卷积核,步幅 1,padding 3,组数等于输入通道数(即逐通道卷积)。
-
作用:提取空间局部特征,同时大幅降低参数量和计算复杂度。
-
LayerNorm:
-
应用于 channels-last 格式(N, H, W, C),对通道维度进行归一化。
-
优势:相比 BatchNorm,LayerNorm 不依赖批量大小,更适合小批量训练和推理。
-
Pointwise Convolution(1×1 卷积):
-
实现倒挂瓶颈结构:先通过 1×1 卷积将通道数扩展 4 倍(例如 768→3072),经过 GELU 激活,再通过 1×1 卷积压缩回原始通道数(3072→768)。
-
作用:增强特征的非线性表达能力,类似 Transformer 的 MLP。
-
Layer Scale:
-
在 Pointwise Convolution 后引入可学习的缩放参数(初始化为 1e-6),逐通道调整特征幅度。
-
意义:提高训练稳定性,防止深层网络退化。
-
DropPath:
-
随机丢弃路径的正则化技术,丢弃概率随深度递增(例如 0 到 0.1)。
-
作用:类似 Dropout,增强模型泛化能力。
-
残差连接:
-
输入通过 shortcut 与 Block 输出相加,形成残差结构。
Block 前向传播:
x = dwconv(x)# (N, C, H, W)x = x.permute(0, 2, 3, 1)# (N, H, W, C)x = norm(x)
x = pwconv1(x)# 扩展通道x = gelu(x)
x = pwconv2(x)# 压缩通道x = gamma * x# Layer Scalex = x.permute(0, 3, 1, 2)# (N, C, H, W)x = shortcut + drop_path(x)
3.4 分类头
-
全局池化: 将最后一个 stage 的输出(例如 7×7×768)进行全局平均池化,得到 (N, 768) 的特征向量。
-
LayerNorm: 对特征向量再次归一化。
-
全连接层: 通过线性层映射到分类数(例如 1000 类),权重和偏置初始化时乘以缩放因子(默认 1.0)。
-
ConvNeXt 的关键创新点
ConvNeXt 的成功离不开以下几个创新设计:
4.1 大核卷积
-
从 3×3 到 7×7: ResNet 普遍使用 3×3 卷积,而 ConvNeXt 采用 7×7 深度卷积,显著扩大感受野。这种设计借鉴了 Transformer 的全局建模能力,同时保留 CNN 的局部归纳偏置。
-
实验验证: 论文中对比了 3×3、5×5、7×7 和 11×11 核,发现 7×7 在性能和效率间取得最佳平衡。
4.2 倒挂瓶颈结构
-
传统 Bottleneck: ResNet 的 Bottleneck 先降维(1×1 卷积)、卷积(3×3)、升维(1×1 卷积)。
-
倒挂设计: ConvNeXt 先进行深度卷积,再通过 1×1 卷积扩展通道(4 倍),最后压缩。这种结构与 Transformer 的 MLP(扩展-压缩)类似,增强了特征表达能力。
4.3 LayerNorm 的引入
- BatchNorm 的局限在于依赖批量统计信息,而 LayerNorm 对每个样本独立归一化,更灵活。ConvNeXt 在 channels-first 和 channels-last 格式下灵活切换 LayerNorm,确保计算效率和稳定性。
4.4 深度卷积与参数效率
- 深度卷积将参数量从 Cin×Cout×k2,显著减少计算负担,同时保留空间信息提取能力。
4.5 训练策略优化
-
ConvNeXt 在训练时采用了现代化的超参数设置(如 AdamW 优化器、cosine 学习率调度、数据增强等),这些与 ViT 一致,确保性能最大化。
-
ConvNeXt 变体与性能
ConvNeXt 提供了多个变体,适应不同计算资源和任务需求:
-
ConvNeXt-T: 通道数 [96, 192, 384, 768],Block 数 [3, 3, 9, 3],参数量 28M,FLOPs 4.5G。
-
ConvNeXt-S: 通道数同上,Block 数 [3, 3, 27, 3],参数量 50M,FLOPs 8.7G。
-
ConvNeXt-B: 同上,参数量 89M,FLOPs 15.4G。
-
ConvNeXt-L: 通道数 [192, 384, 768, 1536],参数量 198M,FLOPs 34.4G。
在 ImageNet-1K 上,ConvNeXt-B 达到 83.8% 的 Top-1 准确率,超越 Swin Transformer(83.0%),同时保持更高的吞吐量(每秒处理图像数)。
-
与 ResNet 和 ViT 的对比
-
与 ResNet: ConvNeXt 保留了残差结构,但通过大核卷积、LayerNorm 和倒挂瓶颈显著提升性能,同时减少冗余计算。
-
与 ViT: ConvNeXt 无需自注意力机制,计算复杂度更低(O(HW) 而非 O(HW²)),更适合中小规模数据集,同时在推理速度上占优。
-
应用与局限性
ConvNeXt 在分类、检测和分割任务中表现出色,尤其在需要高效推理的场景下。然而,其从头训练性能依赖数据集规模,若无预训练权重,可能不如 ResNet 快速收敛。此外,大核卷积在低分辨率特征图上可能导致过拟合,需要仔细调参。
- 结论
ConvNeXt 代表了 CNN 现代化的一次成功尝试,通过融合 Transformer 的设计思想,重塑了卷积网络的竞争力。其模块化设计和高效性使其成为未来视觉任务的重要基石,为研究者和工程师提供了强大的工具。