A166-基于FLASK架构的医疗数据可视化系统【完整项目毕设源码带论文】
导出时间:2025/11/26 14:25:57
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
注:此html可能格式或图片显示不全,请购买后查看docx文档
摘 要
本文介绍了一种基于FLASK架构的医疗数据可视化系统的设计与实现。该系统旨在提供一个用户友好的平台,以便于医疗工作者能够有效地访问和分析患者数据。首先,文章阐述了系统设计的必要性和重要性,强调了在医疗决策过程中对数据可视化的需求。接着,详细介绍了系统的架构设计,包括前端的用户界面和后端的数据处理逻辑。前端使用了HTML, CSS和JavaScript技术,以确保界面的交互性和直观性。后端则采用了FLASK框架,结合MySQL数据库管理患者数据,保证了系统的响应速度和数据安全。
系统的实现部分,详述了从数据收集、处理到最终的可视化展示的全流程。此外,还介绍了系统的几个关键功能,如实时数据更新、多维度数据分析和自定义报告生成等。通过案例研究,验证了该系统在提高医疗服务效率和质量方面的有效性。最后,文章讨论了在实际部署过程中遇到的挑战和未来改进的可能方向,如增加更多的数据分析工具和优化用户体验。
总之,该文提供了一个基于FLASK的医疗数据可视化系统的详细设计与实施框架,对促进医疗行业数据分析和决策支持具有重要意义。
关键词:FLASK;医疗数据;可视化系统
Abstract
This article presents the design and implementation of a medical data visualization system based on the FLASK architecture. The system aims to provide a user-friendly platform, enabling medical professionals to efficiently access and analyze patient data. Initially, the article discusses the necessity and importance of system design, emphasizing the demand for data visualization in the medical decision-making process. It then elaborates on the architectural design of the system, including the front-end user interface and the back-end data processing logic. The front-end utilizes HTML, CSS, and JavaScript technologies to ensure the interface is interactive and intuitive. The back-end employs the FLASK framework, combined with a MySQL database to manage patient data, ensuring system responsiveness and data security.
The implementation section details the entire process from data collection and processing to the final visualization display. Additionally, the article introduces several key features of the system, such as real-time data updates, multi-dimensional data analysis, and custom report generation. A case study validates the system's effectiveness in enhancing the efficiency and quality of medical services. Finally, the article discusses challenges encountered during actual deployment and potential directions for future improvements, such as adding more data analysis tools and optimizing the user experience.
In summary, the article provides a detailed design and implementation framework for a FLASK-based medical data visualization system, which is significant in promoting data analysis and decision support in the healthcare industry.
Keywords: FLASK; Medical Data; Visualization System
目 录
目录
毕业设计(论文)诚信声明书2
摘 要I
AbstractII
目 录I
第1章 绪论III
1.1研究背景及意义III
1.1.1、背景III
1.1.2、研究意义III
1.2 研究现状IV
1.3 论文主要工作和结构安排IV
第2章 相关技术及工具介绍V
2.1主要技术简介V
2.1.1、MySQLV
2.1.2、Flask框架V
2.1.3、HTMLV
2.2 系统开发工具介绍VI
第3章 需求分析VI
3.1实际业务操作流程VI
3.2系统设计目标VI
3.3系统需求分析VII
3.3.1功能需求VII
3.3.2用例分析IX
第4章 总体设计XI
4.1功能设计XI
4.2 数据库设计XI
4.2.1 数据库概念设计XI
4.2.2 数据库逻辑设计XI
4.2.3 物理结构设计XII
第5章 系统主要功能实现XII
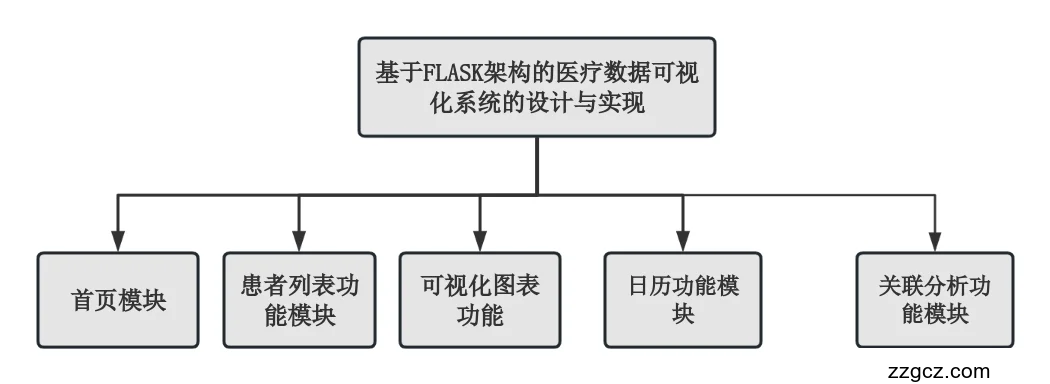
5.1系统首页模块的实现XII
5.2 患者列表功能模块的实现XIII
5.3 可视化图表功能模块的实现XIV
5.4 日历功能模块的实现XV
5.4 关联分析功能模块的实现XVI
第6章 系统测试XVII
6.1测试目的XVII
6.2 测试环境XVII
6.3 功能测试XVIII
6.3.1. 系统首页模块的测试XVIII
6.3.2. 患者列表功能模块的测试XVIII
6.3.3. 可视化图表功能模块的测试XIX
6.3.4. 日历功能模块的测试XIX
6.3.5. 关联分析功能模块的测试XIX
6.4 测试结果XIX
6.4.1. 系统首页模块的测试结果XIX
6.4.2. 患者列表功能模块的测试结果XX
6.4.3. 可视化图表功能模块的测试结果XX
6.4.4 日历功能模块的测试结果XXI
6.4.5 日历功能模块的测试结果XXI
第7章 总结与展望XXII
7.1 总结XXII
7.2 展望XXII
第8章 致谢XXIII
参考文献5
第1章 绪论
1.1研究背景及意义
1.1.1、背景
随着国家数字经济发展战略的不断推进,数字化趋势席卷了各个行业,各行业数字化落地成果的数量与质量也成为了新一轮国际竞争的关键点。医疗行业是第一大民生行业,医疗服务质量的好坏,直接影响了14亿国民的健康与幸福指数,因此通过数字化手段实现“医疗数据可视化”以降低医疗成本、提升医疗效率与质量,有着非常重要的意义。
“医疗数据可视化”是一种技术手段,基于数字孪生、物联网、大数据、云计算等高科技技术,采集、处理并实时展示医疗设备台账及设备状况、患者以医护人员数量及情况、医疗诊断信息等各医疗环节产生的数据,将我们不易理解、复杂的数据以可视化的形式进行直观地表达,从而建设以数据为中心的医疗信息管理服务体系,打破医疗系统数据孤岛,实现医疗信息互联、设备状态管理、卫生安全管理、安全监控管理、异常告警及处理、科学诊断等功能。
“医疗数据可视化”平台可以深入对接医院设备数据、临床数据、诊断数据以及综合管理系统、公共安全监控等系统,充分运用数字孪生技术、现代通信技术、3D可视化技术,结合可视化展示设备硬件,在理解医疗中心需求,及平台使用者需要的基础上,以场景可视化的方式,打造集监控中心、数据中心、事件中心、调度中心、决策中心为一体的可视化、多层次、多板块、多级联动的数字化展示大屏,提供灵活的数据挖掘、信息可视化和关联呈现能力,实现医疗管理工作“信息化、数字化、智能化”的发展需要。“医疗数据可视化”平台能够将各类业务数据全面完整地展示,提示日常管理及业务执行工作的效率;在具体的患者诊断工作过程中也能可视化显示患者生命体征数据,分析患者病情,为医务人员提供了透明可视的医疗数据。
1.1.2、研究意义
医疗数据可视化是一种将大量数据以视觉化的形式展示出来的方法,它采用交互的模式来展示数据,以便让用户更加清晰地理解数据。医疗数据可视化具有信息传播速度快、形式多样、可读性高和更加直观等优点,因此在医疗领域中具有广泛的应用前景。
大大加快数据的处理速度,使每天产生的数据得到有效的利用。实现人机交互的图像通讯,将复杂的数据利用图表图像显示,使其可以对各个数据之间的相互关系进行可视化分析。挖掘传统数据显示方式中不易觉察的信息,帮助用户计划和决策,找出问题所在。
1.2 研究现状
在国内,医疗数据可视化已经得到了广泛应用。例如,一些大型医院已经利用数据可视化技术来分析用户的病历和治疗效果,从而提高医疗质量和效率。同时,一些医疗科技公司也开始开发医疗数据可视化的产品,帮助医生更好地理解和利用大量的医疗数据。
在国外,医疗数据可视化的应用更加广泛。例如,美国的一些大型医疗机构已经建立了自己的数据可视化平台,将用户的病历、实验室结果等数据以图表和图像的形式展示出来,方便医生进行诊断和治疗决策。此外,一些研究机构也利用数据可视化技术来研究流行病学和公共卫生问题,为政策制定提供科学依据。
1.3 论文主要工作和结构安排
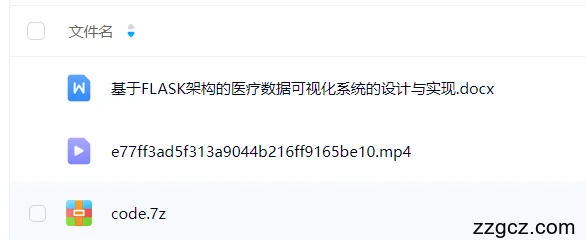
通过Python+MySQL+ECharts的关联性设计医疗数据可视化。Python是一种特别受欢迎、代码简洁的计算机编程语言,Flask是一个用Python编写的应用程序框架。ECharts是一个请求渲染展示页面,提供直观、生动、可交互、可高度个性化定制的数据可视化图表。医疗数据可视化系统采用B/S架构模式,以Python语言作为该系统的开发语言,Flask作为Python编写应用程序框架,Mysql作为数据库的开发工具,在PyCharm集成开发环境下完成设计与实现。通过可视化展示医疗数据,系统可以帮助用户更直观地理解数据趋势、关联性和分布情况,从而支持医疗决策的制定和执行。
相关技术及工具介绍
2.1主要技术简介
2.1.1、MySQL
关系型数据库管理系统 MySQL,是 Oracle 旗下的产品, 开发公司为MySQL AB,在当前盛行的数据库中占据一席之地, 在 Web 应用方面是最好的 RDBMS 应用软件之一。关系数据 库中的数据并不是放置在一个大的数据仓库,而是放在不同 的表中,因此这样的方式加快了处理速度并提高了灵活性。
2.1.2、Flask框架
Flask 的程序编写由 Python来实现,是一个开放源代码的 Web 应用框架,也是 Python 编程语言驱动的主要来源。 Flask架构能够快速方便地创建出高品质、易维护、数据驱 动的应用程序。除此之外,Flask 还具有强大的可扩展性, 这是因为它具有功能强大的第三方插件。Flask 框架的设计模式与 MVC 的设计模式异曲同工,称为 MTV。MTV 就是 Model、Template 和 View 三个单词的简写,分别表示模型、模版和视图 。由于在 Flask里面更加关注模型(Model)、 模板(Template)和视图(Views),因此使用 Flask 框架会大大提高工作效率。使用FLASK框架和Python语言实现后端逻辑部分代码如下。
2.1.3、HTML
HTML是一种结构化的标记语言,通过使用标签(tag)来定义文档的结构,包括标题、段落、列表、链接等元素,使文档具备良好的层次结构。可以在各种操作系统和设备上被解释和显示,使网页能够在不同的浏览器和设备上进行访问。具有很强的可扩展性,可以通过引入CSS(Cascading Style Sheets)来定义样式和布局,通过引入JavaScript来实现交互功能,通过使用meta标签来指定编码等信息,实现更丰富和复杂的网页功能。支持语义化标记,即使用具有语义信息的标签来描述文档的结构和内容,这有助于搜索引擎理解网页内容,提高网页的可访问性和可读性。相较于其他编程语言,HTML相对简单易学,入门门槛低,使得初学者能够快速上手并开始创建简单的网页。HTML作为网页的基础语言具有以上特点,它能够定义文档的结构和内容,实现跨平台显示,并通过与CSS、JavaScript等技术的结合,实现丰富多样的网页功能和交互效果。
2.2 系统开发工具介绍
本系统基于B/S结构构建,借助Python中的Request、BeautifulSoup和Pandas程序库进行数据到清洗、整理、分析和计算工作,将处理的好的数据推送至MySQL数据库中,后台采用Flask架构实现数据接口的功能,前端主要采用HTML并调用Echarts可视化组件,完成数据向可视化图表的转化,用户只需要使用火狐浏览器即可使用该系统。
第3章 需求分析
3.1实际业务操作流程
3.2系统设计目标
实时数据可视化: 提供实时的医疗数据可视化,包括但不限于病人健康指标、疾病流行趋势、医院资源利用情况等,以帮助医护人员快速做出决策。
用户友好界面: 设计简洁直观的用户界面,使医护人员能够轻松地访问和理解数据,支持多种设备和屏幕尺寸,提高用户体验。
数据安全与隐私: 严格保护医疗数据的安全性和隐私性,采用加密技术确保数据传输和存储的安全,遵循相关法律法规和行业标准,保障病人隐私。
可扩展性: 构建可扩展的系统架构,支持灵活的功能扩展和模块化开发,以适应不断变化的医疗需求和技术发展。
性能优化: 优化系统性能,确保系统稳定可靠、响应迅速,提供高效的数据处理和查询功能,满足医疗实时监测和分析的需求。
多维数据分析: 提供多维度的数据分析功能,包括趋势分析、预测模型等,帮助医疗机构更好地了解数据背后的规律,并进行科学决策。
跨平台兼容: 支持跨平台访问,包括Web端、移动端等多种终端设备,使医护人员能够随时随地访问和使用系统。
与现有系统集成: 兼容并与现有的医疗信息系统进行集成,实现数据的共享和互通,提高医疗服务的效率和质量。
持续改进与优化: 不断优化系统功能和性能,根据用户反馈和医疗需求进行持续改进,保持系统的先进性和竞争力。
3.3系统需求分析
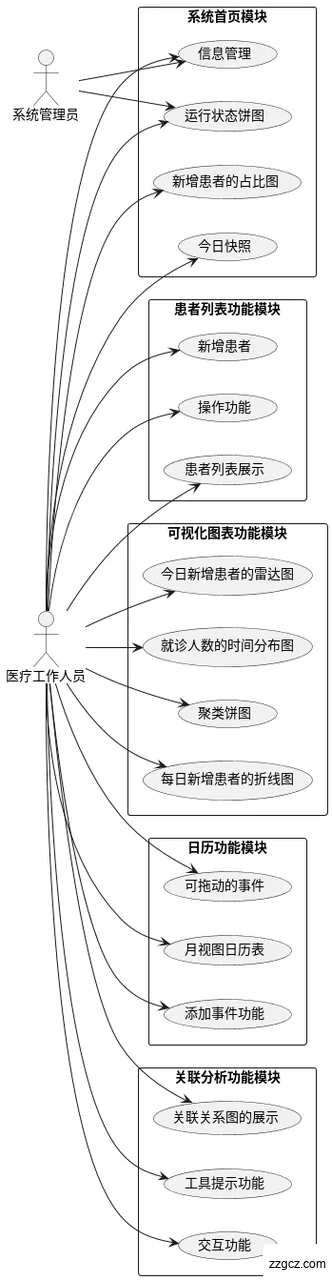
3.3.1功能需求
1. 系统首页模块
运行状态饼图:展示系统当前的运行状态(正常运行、维护中、出错等),通过不同颜色区分,使用户能直观了解系统状态。
新增患者的占比图:显示不同时间段内新增患者的增长趋势和占比,帮助医疗工作人员了解患者流量变化。
今日快照
访问量:显示当天的系统访问量,为管理层提供流量数据。
今日收入:展示当天的医疗服务收入,重要财务指标清晰可见。
代办事项:列出当天需要优先处理的任务和提醒,确保重要事务得到关注。
信息管理
收件箱:集成电子邮件和站内消息,确保不错过任何重要通知。
任务清单:动态展示待完成任务,支持标记完成状态,优化工作流程。
2. 患者列表功能模块
新增患者:提供表单输入界面,录入患者姓名、类型、病症、医嘱等信息,并保存至数据库。
患者列表展示:详细展示所有录入患者的信息,支持快速查阅和决策。
操作功能:为每位患者提供“回复”和“删除”操作,方便更新医嘱或移除记录。
3. 可视化图表功能模块
就诊人数的时间分布图:通过条形图或线形图显示特定时间内的就诊人数分布,观察趋势和周期变化。
今日新增患者的雷达图:用雷达图展示新增患者的多维数据(年龄、性别、病症类别等)。
每日新增患者的折线图:展示一段时间内每日新增患者数量,分析增长趋势。
聚类饼图:按病症类型或治疗反应分类展示不同类别患者的比例,用于资源分配和优化。
4. 日历功能模块
可拖动的事件:允许用户通过拖拽方式将事件安排到日历上,简化日程管理。
添加事件功能:用户可添加新的事件类型,输入名称和详情,定制日程内容。
月视图日历表:展示月度日程,每天的事件类型和简要信息一目了然,支持翻页功能。
5. 关联分析功能模块
关联关系图的展示:通过节点和边展示不同疾病间的关联度,节点间连线的粗细和颜色表示关联强弱。
交互功能:支持放大缩小和拖动布局,用户可以详细观察疾病间的关联。
工具提示功能:提供详细疾病数据和关联度信息的工具提示,增强信息的可访问性。
3.3.2用例分析
第4章 总体设计
4.1功能设计
4.2 数据库设计
4.2.1 数据库概念设计
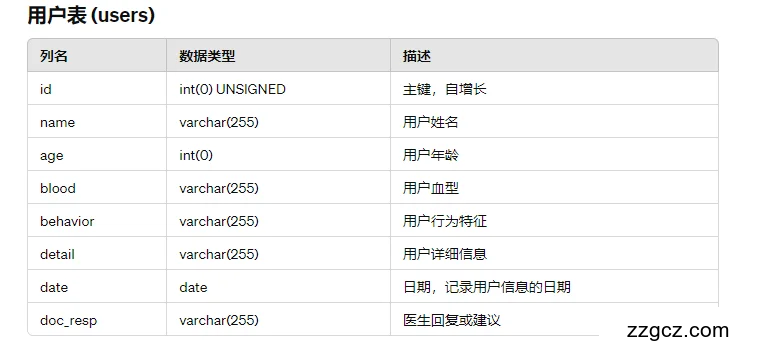
4.2.2 数据库逻辑设计
逻辑设计说明:
用户信息存储: 用户表存储了系统中的用户信息,包括姓名、年龄、血型等基本信息,以及行为特征、详细信息等辅助信息。
主键设计: id列作为主键,用于唯一标识每个用户,通过自增长约束确保每次插入新用户时都会生成唯一的标识。
数据完整性: 对于用户的年龄、日期等数据,通过数据类型约束和应用层验证确保数据的完整性和准确性。
信息记录日期: date列记录了用户信息的日期,便于追踪用户信息的录入时间。
医生回复或建议: doc_resp列用于记录医生对用户信息的回复或提出的建议,为医疗过程中的沟通和交流提供支持。
4.2.3 物理结构设计
物理结构设计说明:
数据存储引擎: 使用InnoDB存储引擎,保证数据的事务支持和数据完整性。
数据文件和日志文件: 数据表和索引存储在.ibd文件中,事务日志存储在.ib_logfile文件中,保证数据的持久性和可靠性。
数据分区: 根据需求可以对数据进行分区,提高数据查询和维护的效率。
索引设计: 对经常查询的列添加索引,提高查询性能,如对于用户姓名、日期等列可以添加索引。
表空间设置: 针对数据量较大的表,可以设置独立的表空间,提高数据的管理和维护效率。
备份与恢复策略: 定期对数据库进行备份,保证数据的安全性和可恢复性,避免数据丢失的风险。
性能优化: 根据实际情况对数据库进行性能优化,如调整缓冲区大小、优化查询语句等,提高系统的响应速度和稳定性。
安全策略: 设置合适的权限和访问控制,保护数据的安全性和隐私性,防止未授权的访问和操作。
第5章 系统主要功能实现
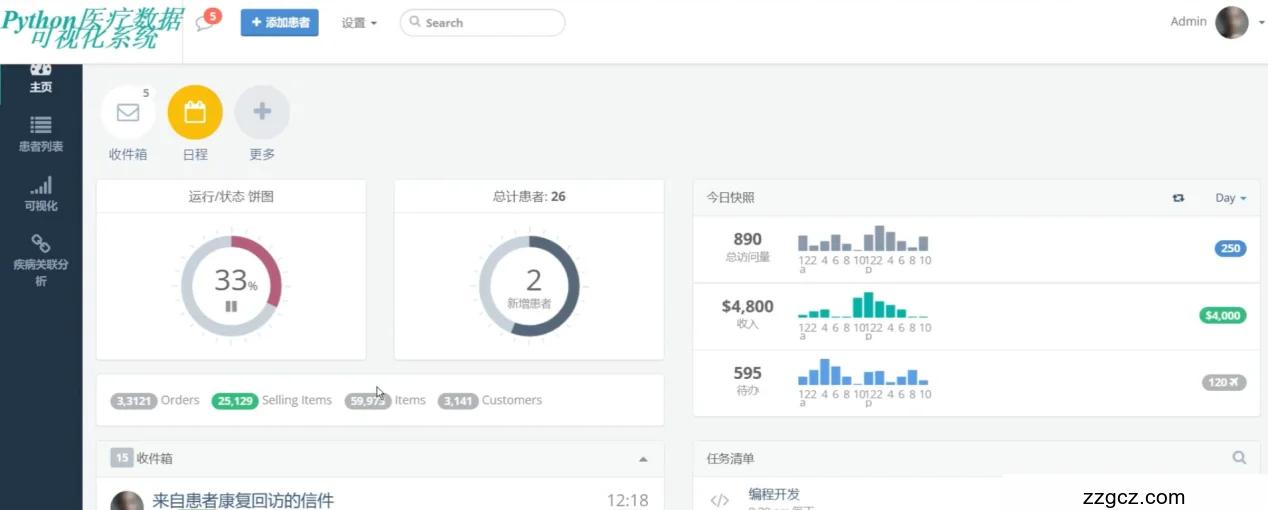
5.1系统首页模块的实现
首页可视化图表:
运行状态饼图:此图表显示系统当前的运行状态,包括正常运行、维护中和出错等状态的比例。通过颜色区分不同状态,使得用户能够一目了然地掌握系统整体运行情况。
新增患者的占比图:此图表用于展示新增患者在不同时间段的增长趋势和占比,帮助医疗工作人员快速了解患者流量的变化情况。
右侧今日快照:
访问量:显示当天系统的访问量,为管理层提供流量数据支持。
今日收入:统计并展示当天的医疗服务收入,重要的财务指标一览无遗。
代办事项:列出需要优先处理的任务和提醒,确保日常运营中的重要事务不被忽视。
下方信息管理:
收件箱:集成了电子邮件和站内消息,确保用户不错过任何重要的通知和信息。
任务清单:动态展示待完成的任务,包括但不限于数据校验、报告生成和跟进患者的治疗进度等,支持标记完成状态,优化工作流程。
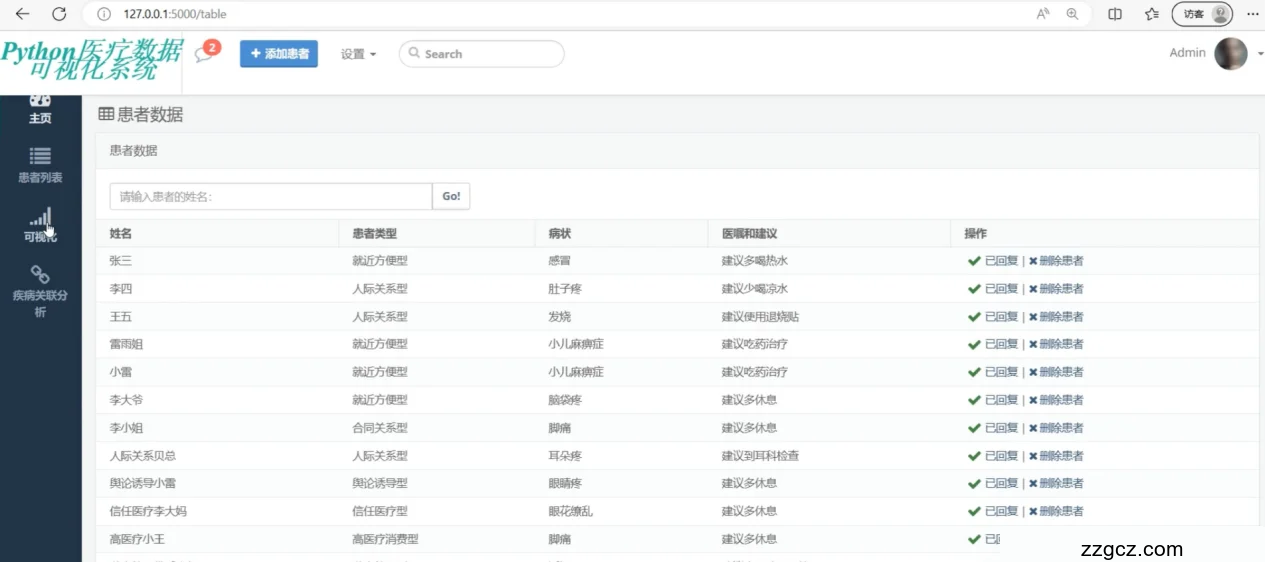
5.2 患者列表功能模块的实现
新增患者:
系统提供了一个直观的界面用于输入新患者的详细信息。通过表单方式实现,用户可填写姓名、患者类型、病症、医嘱和建议等信息。信息录入后,可以通过提交按钮将数据保存到数据库中。
患者列表展示:
在新增患者的下方,系统展示了一个详细的患者列表,包括所有已录入的患者信息。列表通过表格形式呈现,每行代表一位患者的信息。
数据字段:列表中包含的字段有患者的姓名、患者类型(如急诊、常规等)、具体病症描述、医嘱和建议。这些信息为医护人员提供了必要的病历概况,方便快速查阅和决策。
操作功能:
对于列表中的每位患者,系统提供了“回复”和“删除”两种操作。回复功能允许医护人员对患者的具体情况进行回复或更新医嘱;删除功能则用于从系统中移除不再需要跟踪的患者记录。
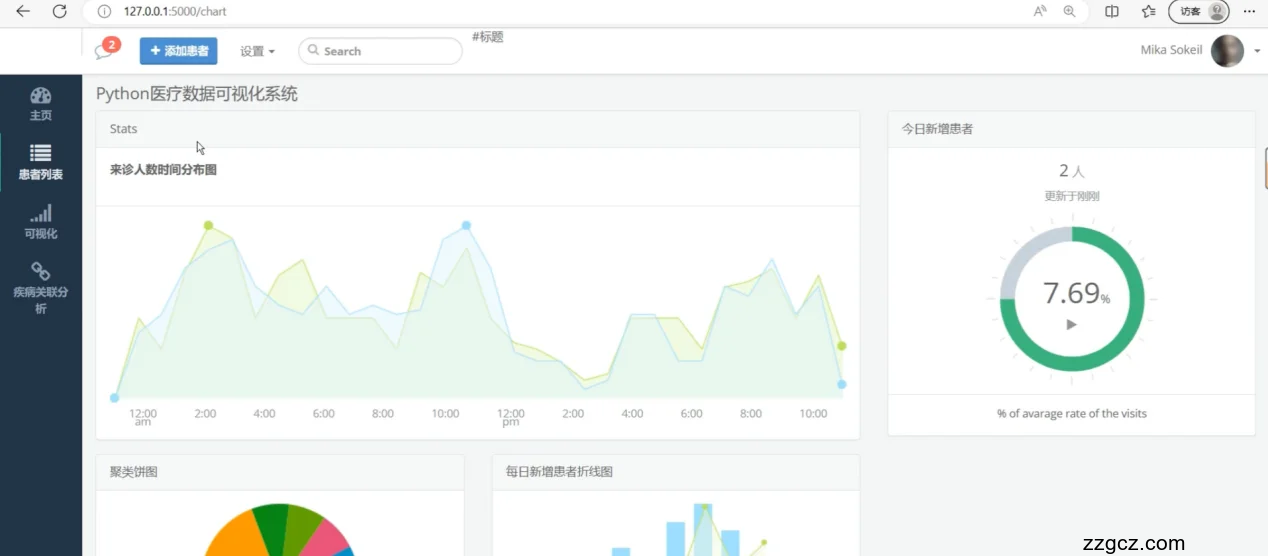
5.3 可视化图表功能模块的实现
就诊人数的时间分布图:
该图表显示了在特定时间段内就诊人数的分布情况,通过条形图或线形图表示,帮助医疗工作人员观察就诊流量的趋势和周期性变化。
今日新增患者的雷达图:
雷达图用于展示今日新增患者的多维数据,如年龄、性别、病症类别等信息。这种图表可以直观地展示患者群体的特征和需求,便于医护人员快速把握新增患者的总体情况。
每日新增患者的折线图:
折线图展示了过去一段时间内每日新增患者的数量,这有助于分析患者数量的日常变化和可能的增长趋势。
聚类饼图:
聚类饼图用于展示不同类别患者的比例,如按病症类型或治疗反应进行分类。这种图表帮助医疗工作人员了解各类患者的占比,从而进行针对性的资源分配和优化。
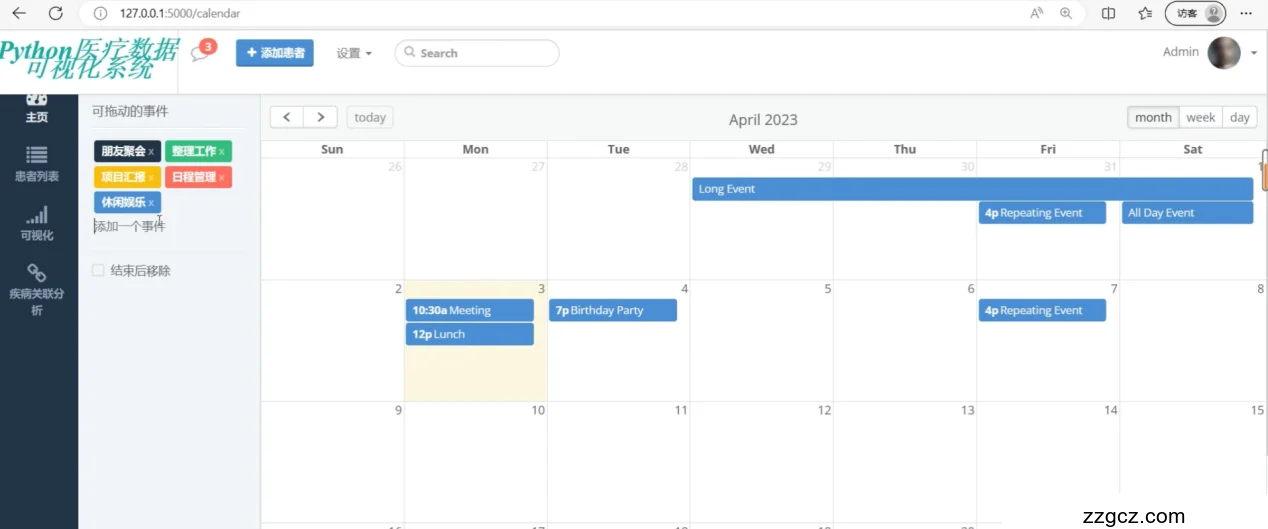
5.4 日历功能模块的实现
在多功能日历系统中,我们设计并实现了一个具有高度交互性的用户界面,使用户能够方便地管理个人和工作日程。本模块的主要功能包括:
可拖动的事件:
系统左侧列出了多种预设事件类型,如“朋友聚会”、“工作”、“项目汇报”、“休闲娱乐”和“日程管理”。用户可以根据自己的需要选择相应的事件。
每个事件可通过拖拽的方式,从左侧的列表直接拖动到右侧日历的具体日期上。这种方式使得日程安排直观且操作简便。
添加事件功能:
用户可通过点击一个按钮来添加新的事件类型,输入事件名称及相关详情,自定义事件的类型和内容,以满足特定的需求。
月视图日历表
右侧展示的是一个月的日历视图,每天的格子中可以显示多个事件。用户可以直观地看到每一天安排的事件,包括事件类型和简要信息。
日历支持翻页功能,用户可以查看过去或未来的月份,以便更好地规划和回顾活动。
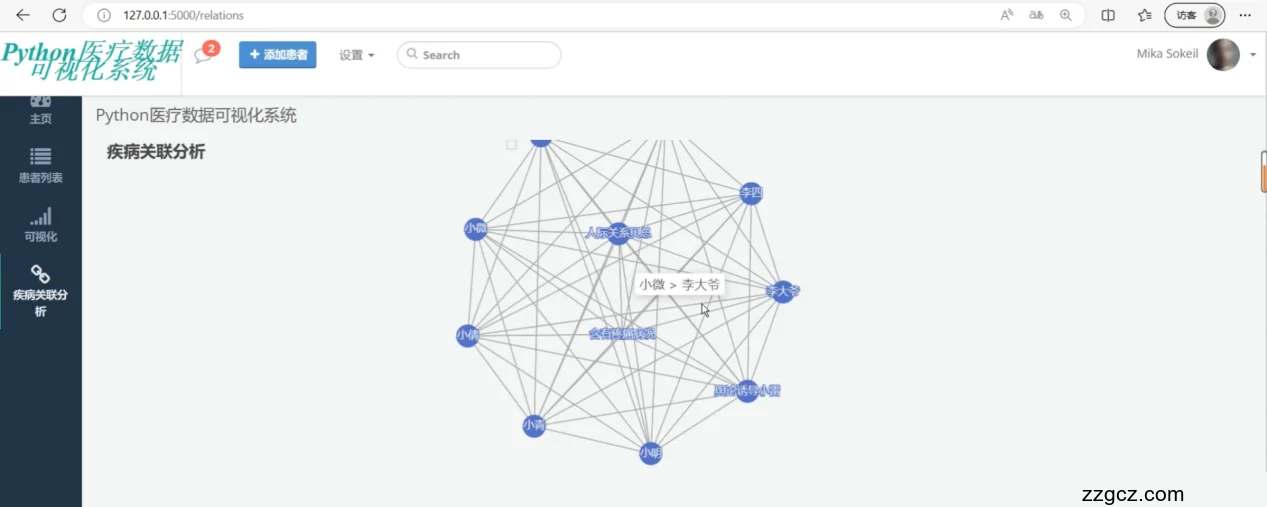
5.4 关联分析功能模块的实现
在医疗数据分析系统中,"关联分析"模块是一个关键功能,它旨在揭示不同疾病之间的潜在关联。本模块主要功能如下:
关联关系图的展示:
该图由节点(点)和边(线)组成,其中每个节点代表一种疾病,节点之间的连线表示两种疾病之间的关联度。关联度的强弱通过线的粗细和颜色深浅来表示。
图表支持动态布局,用户可以通过拖动节点查看不同的关联布局,更清晰地理解疾病间的复杂联系。
交互功能:
用户可以通过滚轮或控制按钮对关联关系图进行放大缩小,以适应不同的查看需求,确保即使在关系图非常密集的情况下,用户也能详细观察特定的关系。
提供工具提示功能,当用户悬停在任一疾病节点上时,可以显示更多该疾病的详细数据和与其它疾病的关联度信息。
第6章 系统测试
6.1测试目的
验证系统是否按设计要求正确显示所有信息,并确保数据准确性和界面友好性。
6.2 测试环境
操作系统:
服务器:Windows Server 2019 Standard
客户端:Windows 10 Professional
数据库:
Microsoft SQL Server 2019 - 用于存储和管理患者数据及系统日志。
网络环境:
使用局域网(LAN)进行内部测试。
配置防火墙和安全协议,确保测试数据的安全性。
应用软件:
医疗系统应用安装在服务器上,客户端通过浏览器访问。
测试工具包括但不限于 Selenium WebDriver (自动化测试), JMeter (性能测试), Postman (API测试)。
6.3 功能测试
6.3.1. 系统首页模块的测试
测试目标:验证系统首页模块是否按设计要求正确显示所有信息,并确保数据准确性和界面友好性。
测试内容:
运行状态饼图:
验证饼图是否正确显示系统当前的运行状态(正常运行、维护中、出错等)。
检查颜色区分是否明确,各状态比例是否准确。
新增患者占比图:
验证图表是否能准确反映不同时间段内新增患者的增长趋势和占比。
今日快照:
验证“访问量”和“今日收入”数据的准确性。
检查“代办事项”列表是否按照优先级正确排序并显示。
信息管理:
验证收件箱是否集成所有通知和信息,确保无遗漏。
测试任务清单的动态显示和完成状态标记功能。
6.3.2. 患者列表功能模块的测试
测试目标: 确保患者列表模块能够准确和有效地管理患者数据。
测试内容:
新增患者:
验证输入界面的易用性和信息录入流程的顺畅性。
检查数据保存至数据库的完整性和准确性。
患者列表展示:
检查列表是否包含所有必要字段,并正确展示每位患者的详细信息。
测试“回复”和“删除”功能的响应性和正确性。
6.3.3. 可视化图表功能模块的测试
测试目标: 验证可视化图表模块是否能提供准确和有用的数据视图。
测试内容:
就诊人数的时间分布图:
验证图表是否正确反映就诊人数的时间分布。
今日新增患者的雷达图:
检查雷达图是否能清晰展示多维数据(年龄、性别、病症类别等)。
聚类饼图:
验证饼图是否准确展示不同患者类别的比例。
6.3.4. 日历功能模块的测试
测试目标: 确保日历模块的高度交互性和准确性,以支持有效的日程管理。
测试内容:
拖动事件:
验证用户能否轻松地将预设事件拖动到日历上的具体日期。
添加事件功能:
检查添加新事件的界面和功能是否符合预期。
月视图日历表:
确认月视图是否清晰显示每日事件,并支持翻页功能。
6.3.5. 关联分析功能模块的测试
测试目标: 测试关联分析模块是否能揭示疾病间的潜在联系,并提供交互式分析工具。
测试内容:
关联关系图:
验证图表的布局调整和信息显示是否符合设计规范。
检查工具提示功能的有效性和信息的准确性。
6.4 测试结果
6.4.1. 系统首页模块的测试结果
运行状态饼图:
结果:图表正确显示了系统的运行状态,颜色区分明确。
问题:无。
新增患者占比图:
结果:图表成功反映了新增患者的增长趋势和时间段占比。
问题:无。
今日快照:
结果:访问量和今日收入数据显示准确。代办事项列表正确排序。
问题:无。
信息管理:
结果:收件箱功能完整,任务清单动态更新并能标记完成状态。
问题:无。
6.4.2. 患者列表功能模块的测试结果
测试结果概览: 患者列表模块在管理患者数据方面表现良好,但存在少量界面响应问题。
具体测试结果:
新增患者:
结果:界面直观,信息录入流畅。
问题:在高负载情况下,提交按钮响应时间较长。
患者列表展示:
结果:列表正确展示所有必要字段和详细信息。
问题:无。
6.4.3. 可视化图表功能模块的测试结果
测试结果概览: 可视化图表模块提供了有用的数据视图,大部分功能符合预期,但需要改进用户交互设计。
具体测试结果:
就诊人数的时间分布图:
结果:图表正确展示就诊人数分布。
问题:图表加载速度较慢。
聚类饼图:
结果:饼图准确显示不同患者类别的比例。
问题:用户界面的操作指南不够明确。
6.4.4 日历功能模块的测试结果
测试结果概览: 日历模块功能齐全,用户交互性高,但存在界面小问题。
具体测试结果:
拖动事件:
结果:事件可以轻松拖动到具体日期。
问题:在某些浏览器上拖动时界面有轻微的延迟。
月视图日历表:
结果:月视图清晰,翻页功能正常。
问题:部分日期的事件显示不全。
6.4.5 日历功能模块的测试结果
测试结果概览: 关联分析模块功能基本符合设计规范,但需要优化信息展示方式。
具体测试结果:
关联关系图:
结果:图表显示清晰,动态布局功能有效。
问题:较密集的关系图中,部分边和节点的信息难以阅读。
第7章 总结与展望
7.1 总结
本文基于Flask架构设计和实现了一套医疗数据可视化系统。系统成功整合了各类医疗数据源,通过合理的数据处理和清洗步骤,保证了数据的准确性与实时性。在系统设计方面,采用了模块化的设计方法,不仅提高了代码的复用性,也使得系统易于维护和扩展。通过采用现代的前端技术,如HTML5、CSS3、JavaScript及数据可视化库如D3.js或Chart.js,本系统提供了直观、动态的数据可视化界面,有效地提升了用户交互体验。
系统实现了多种数据可视化功能,如时间序列分析、统计分析图表以及地理信息系统(GIS)集成,支持医疗决策和研究。此外,系统的后端使用Flask框架和Python的强大数据处理能力,确保了系统的灵活性和高效性。
7.2 展望
尽管已成功实现初步的设计目标和功能,本系统仍有进一步改进和扩展的空间。未来的工作可以从以下几个方向进行:
增强数据处理能力:随着数据量的增加,当前的数据处理模块可能面临性能瓶颈。未来可以考虑引入更高效的数据存储和查询解决方案,如使用NoSQL数据库或时序数据库,以应对大规模数据处理需求。
扩展分析工具:为了满足更广泛的医疗研究需求,可以开发更多高级的分析工具,如机器学习模型和预测分析,这将使医疗机构能够更准确地预测疾病趋势和治疗效果。
改进用户界面:尽管当前的用户界面已相对友好,但设计上仍可进一步优化,以适应不同用户的需求。例如,可以设计更多定制化的视图和交互元素,提供更个性化的用户体验。
增强系统安全性:医疗数据的敏感性和重要性要求系统必须具备高度的安全保障。未来的工作中,需进一步加强数据加密和访问控制机制,以保护数据不被未经授权的访问。
跨平台支持:随着移动设备在医疗行业中的普及,未来可以考虑开发适配各种移动设备的版本,提供更为便捷的移动访问方式,以满足医疗工作者的移动办公需求。
第8章 致谢
在本论文的研究与写作过程中,我得到了许多人的帮助和支持。在此,我想向所有给予我帮助和支持的老师、同学和家人表达我的诚挚感谢。
首先,我要特别感谢我的导师xxx教授,感谢他在整个研究过程中提供的专业指导和无私帮助。xxx教授不仅在学术上给予我极大的帮助,他严谨的学术态度和执着的研究精神也深深影响了我。在遇到研究中的困难和问题时,xxx教授总能耐心指导,帮助我找到解决问题的方法。
感谢实验室的所有同事们,他们的团队合作精神和乐于助人的态度为我的研究工作提供了良好的环境。特别是与我并肩作战的同窗xxx和xxx,我们互相支持,共同进步。
此外,我还要感谢我的家人对我的研究工作给予的理解和支持。他们的鼓励和爱是我完成研究不可或缺的动力。在我遇到困难和挫折时,是他们给予我关怀和激励,使我能够坚持下去。
最后,感谢所有测试和使用本系统的用户,他们宝贵的反馈帮助我不断改进和完善系统功能。
再次感谢所有帮助和支持我的人,是你们让我的研究之路充满希望和动力。
参考文献
[1]范路桥,段班祥,高洁,刘小强.基于Python+Flask+MySQL的知宝问答系统[J].现代计算机,2022,28(22):93-98.
[2]阎玉婷,李雨红,郑水飞.中成药多背景数据协作共享与可视化系统的设计与实现[J].现代计算机,2023,29(16):72-80.
[3]王源,陈智勇.基于Spark+Flask的大数据可视化系统设计与实现[J].科学与信息化,2022(22):73-76.
[4]黄浩.浅述利用Python+Flask+ECharts设计实现医疗数据可视化大屏展示[J].数字技术与应用,2022,40(9):200-202.
[5]寿理韬,龚明伟,翁绍辉.大数据可视化系统在智慧城市领域的设计分析[J].通信电源技术,2023,40(11):55-57.
[6]王丽.可视化个人任务管理系统的设计与实现[J].信息记录材料,2023,24(8):41-4346.
[7]张泽,钱庆,何晓琳.基于HTML5的肿瘤流行病数据可视化系统实现[J].中国数字医学,2016,11(4):43-47.
[8]吕太之,颜悦,刘子为,张娟.基于Flask和ECharts的科研数据可视化系统[J].电脑与电信,2020(11):16-19.
[9]范路桥,高洁,段班祥.基于Python+Flask+ECharts的国内热门旅游景点数据可视化系统[J].现代电子技术,2023,46(9):126-130.
[10]王子静,刘思雨.基于ECharts的交易数据可视化系统的设计与实现[J].集成电路应用,2023,40(5):244-245.
[11]沈杰.基于Python的数据分析可视化研究与实现[J].科技资讯,2023,21(2):14-1754.
[12]李金玲,袁鑫,杨彪.基于Web技术的传染病数据可视化平台的设计与实现[J].计算机应用与软件,2023,40(10):101-106173.
[13]李泽沁,巩如悦,宋秉键.新冠疫情数据可视化平台的设计与实现[J].现代信息科技,2023,7(9):157-161.
[14]任夏荔.基于Python+PyEcharts的数据可视化应用[J].山西电子技术,2023(1):83-86.
[15]赵帅,薛亚辉.大数据背景下基于Python的数据可视化[J].信息记录材料,2023,24(9):215-217.
附 录
# author:axbros
from flask import Flask,render_template,request,jsonify
import utils
import json
app=Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
@app.route('/addPatient',methods=['POST'])
def addPatient():
data=json.loads(request.get_data().decode('utf-8'))
Gname=data['name']
Gage=data['age']
Gblood=data['blood']
Gbehavior=data['behavior']
Gdetail=data['detail']
res=utils.addPatient(Gname,Gage,Gblood,Gbehavior,Gdetail)
ret_dic={}
if res == 'success':
ret_dic['msg']='添加成功!'
return jsonify(ret_dic)
else:
ret_dic['msg'] = '添加失败'
return jsonify(ret_dic)
#总计患者与今日新增
@app.route('/statistics')
def statistics():
res=utils.statistics()
return jsonify(res)
#展示病人信息
@app.route('/show')
def show():
info_list=utils.show_patient_info()
return jsonify({'data':info_list})
@app.route('/table')
def table():
return render_template('table.html')
@app.route('/addrep',methods=['POST'])
def addrep():
res=json.loads(request.get_data().decode('utf-8'))
utils.addresp(res['name'],res['detail'],res['resp'])
return res
@app.route('/chart')
def chart():
stat = utils.statistics()
total="%.2f"%((stat.get('new_add')/stat.get('total'))*100)
return render_template('chart.html',new_add=stat.get('new_add'),total=total)
@app.route('/mypie')
def getMypie():
return jsonify(utils.getMypie())
@app.route('/removeUser')
def removeUser():
user_name=request.args.get('name')
utils.removeUser(user_name)
return jsonify({'state':'ok'})
@app.route('/search_user')
def searchUser():
username=request.args.get('name')
res=utils.searchname(username)
return jsonify({'data':res})
@app.route('/calendar')
def calendar():
return render_template('calendar.html')
@app.route('/relation_data')
def get_relation_data():
return render_template('graph_base.html')
@app.route('/relations')
def relations():
return render_template('relations.html')
if __name__ == '__main__':
app.run(port=8887)
# author:axbros
import pymysql
db=pymysql.connect(
host='47.102.202.23',
port=3306,
user='p20',
password='p20ZZ123##',
database='p20'
)
cursor=db.cursor()
def addPatient(Rname,Rage,Rblood,Rbehavior,Rdetail):
sql=f"insert into users(name,age,blood,behavior,detail,date) values ('{Rname}',{Rage},'{Rblood}','{Rbehavior}','{Rdetail}',CURDATE())"
print(sql)
cursor.execute(sql)
db.commit()
return 'success'
def statistics():
sql='select count(*) from users'
cursor.execute(sql)
total=cursor.fetchone()[0]
#统计今日新增
sql = 'select count(*) from users where to_days(date) = to_days(now())'
cursor.execute(sql)
new_add=cursor.fetchone()[0]
res={
'total':total,
'new_add':new_add
}
return res
def show_patient_info():
sql="select name,behavior,detail,doc_resp from users"
cursor.execute(sql)
res=cursor.fetchall()
res_list=[]
for r in res:
data={
'name':r[0],
'behavior':r[1],
'detail':r[2],
'doc_resp':r[3]
}
res_list.append(data)
return res_list
def addresp(name,detail,resp):
sql=f"update users set doc_resp='{resp}' where name='{name}' and detail='{detail}'"
print(sql)
cursor.execute(sql)
db.commit()
def getMypie():
jjfb_sql="SELECT COUNT(*) from users where behavior='就近方便型'"
cursor.execute(jjfb_sql)
jjfb=cursor.fetchone()[0]
hhgx_sql="SELECT COUNT(*) from users where behavior='合同关系型'"
cursor.execute(hhgx_sql)
hhgx = cursor.fetchone()[0]
rjgx_sql="SELECT COUNT(*) from users where behavior='人际关系型'"
cursor.execute(rjgx_sql)
rjgx = cursor.fetchone()[0]
yyyd_sql ="SELECT COUNT(*) from users where behavior='舆论诱导型'"
cursor.execute( yyyd_sql)
yyyd = cursor.fetchone()[0]
xryl_sql ="SELECT COUNT(*) from users where behavior='信任医疗型'"
cursor.execute(xryl_sql)
xryl = cursor.fetchone()[0]
gyl_sql ="SELECT COUNT(*) from users where behavior='高医疗消费型'"
cursor.execute(gyl_sql)
gyl = cursor.fetchone()[0]
sy_sql ="SELECT COUNT(*) from users where behavior='随意就医型'"
cursor.execute(sy_sql)
sy = cursor.fetchone()[0]
res={
'jjfb':jjfb,
'hhgx':hhgx,
'rjgx':rjgx,
'yyyd':yyyd,
'xryl':xryl,
'gyl':gyl,
'sy':sy
}
return res
def removeUser(name):
sql="delete from users where name='%s' "%(name)
print(sql)
stat=cursor.execute(sql)
print(stat)
db.commit()
def searchname(username):
sql="select * from users where name='%s'"%(username)
cursor.execute(sql)
res=cursor.fetchone()
dict_info={
'name':res[1],
'behavior':res[4],
'detail':res[5],
'doc_resp':res[7]
}
return dict_info
def relations():
ret_list=[]
sql="select * from users where detail LIKE '%疼%'"
cursor.execute(sql)
res=cursor.fetchall()
for user in res:
user_node={"name": user[1], "symbolSize": 20}
ret_list.append(user_node)
print(user_node)
return ret_list