A181-基于flask的豆瓣图书数据分析与可视化系统
导出时间:2025/11/26 14:27:57
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
注:此html可能格式或图片显示不全,请购买后查看docx文档
摘要
本论文介绍了基于Flask框架的豆瓣图书可视化系统的设计与实现。随着互联网信息的快速增长,用户对数据的获取和理解变得越来越重要。豆瓣作为一个受欢迎的图书推荐平台,积累了大量的图书信息数据。然而,这些数据的展示形式较为单一,难以满足用户多样化的信息需求。本研究旨在通过构建一个基于Flask的Web应用,提供直观、交互性强的图书信息可视化服务。
系统主要由数据采集模块、数据存储模块、数据处理模块和数据展示模块组成。首先,通过豆瓣API进行数据采集,获取图书的基本信息、评分、评论等。其次,使用SQLite数据库存储采集到的数据,并对其进行清洗和整理。然后,利用Flask框架构建Web服务,处理用户请求并动态生成数据可视化结果。最后,通过ECharts等前端可视化工具,将处理后的数据以图表形式展示,用户可以方便地进行交互操作,如筛选、排序和搜索等。
本系统具有以下特点:一是采用模块化设计,系统结构清晰,易于维护和扩展;二是数据可视化效果丰富,通过多种图表形式直观展示数据,提高了用户的阅读体验;三是前后端分离的设计理念,增强了系统的响应速度和用户交互体验。
通过本系统的设计与实现,验证了Flask在构建数据可视化应用中的可行性和高效性。研究结果表明,该系统不仅能够有效展示豆瓣图书数据,还能够为用户提供更深层次的数据洞察,具有较高的实用价值。
关键词:Flask,豆瓣图书,数据可视化,Web应用,ECharts
Abstract
This thesis presents the design and implementation of a Douban book visualization system based on the Flask framework. With the rapid growth of internet information, users' demand for data acquisition and understanding has become increasingly important. Douban, a popular book recommendation platform, has accumulated a large amount of book information data. However, the display format of this data is relatively simple, making it difficult to meet users' diverse information needs. This study aims to construct a web application based on Flask to provide intuitive and interactive book information visualization services.
The system mainly consists of data collection, data storage, data processing, and data presentation modules. Firstly, data is collected through the Douban API, including basic book information, ratings, reviews, etc. Secondly, the collected data is stored in an SQLite database and cleaned and organized. Then, using the Flask framework, a web service is built to handle user requests and dynamically generate data visualization results. Finally, using front-end visualization tools such as ECharts, the processed data is displayed in chart form, allowing users to perform interactive operations such as filtering, sorting, and searching.
The system has the following features: First, it adopts a modular design, with a clear system structure that is easy to maintain and extend. Second, it offers rich data visualization effects, displaying data intuitively through various chart forms, enhancing the user reading experience. Third, the front-end and back-end separation design concept improves the system's response speed and user interaction experience.
Through the design and implementation of this system, the feasibility and efficiency of Flask in building data visualization applications are verified. The research results indicate that the system can effectively display Douban book data and provide users with deeper data insights, making it highly practical.
Key words:Flask, Douban Books, Data Visualization, Web Application, ECharts
目录
摘要I
AbstractII
1 概述1
1.1项目的开发背景1
1.2 项目开发的意义2
1.3 研究内容3
1.4主要解决问题3
2 技术基础4
2.1 开发环境4
2.2 相关技术知识4
3 系统分析5
3.1 技术可行性5
3.2 经济可行性5
3.3 系统性能分析6
4 系统设计6
4.4 系统数据库设计8
(1)数据库E-R图8
(2)数据库设计9
表:book_country_num9
表:book_people_title9
表:book_presstime_num10
表:book_publisher_num10
表:book_score_num10
表:books10
5 系统实现11
5.1 前台首页11
5.2 电影页面12
5.2 国家分析页面13
5.3 评分分析页面14
5.4 top10评论分析页面15
5.5 出版社分析页面16
5.6 图书评论词云图分析页面17
6 系统测试18
6.1 系统测试的目的18
6.2 系统测试的过程18
6.3系统测试用例18
7 关键技术20
7.1 Python编程及其在数据爬取和可视化中的应用20
7.2 数据清洗、分析20
7.3 数据存储20
7.4 数据可视化21
(1)准备数据21
(2)引入 ECharts 库21
(3)在HTML中创建一个容器来存放21
(4)初始化图表21
(5)配置图表选项22
(6)渲染图表22
7.5 scrapy爬虫技术22
8 结束语23
参考文献24
致 谢26
1 概述
1.1项目的开发背景
随着互联网的迅猛发展和信息技术的不断进步,数据已经成为现代社会的重要资产。无论是个人用户还是企业机构,都在日益依赖数据来进行决策、优化流程和提升体验。在这种背景下,数据可视化作为一种将复杂数据转化为直观图形和图表的技术,变得越来越重要。通过数据可视化,用户可以更轻松地发现数据中的趋势和模式,从而做出更明智的决策。
豆瓣作为中国最受欢迎的社交网站之一,尤其以其图书、电影和音乐的推荐系统而著称。在豆瓣平台上,用户可以找到关于图书的详细信息,包括书籍的简介、评分、评论和推荐等。尽管豆瓣提供了丰富的图书信息,但其数据展示方式相对单一,难以满足用户日益增长的信息需求。用户需要一种更为直观和交互性更强的方式来浏览和分析这些图书数据。
在这种需求下,基于Flask的豆瓣图书可视化系统应运而生。Flask是一款轻量级的Python Web框架,以其灵活性和易用性广受开发者欢迎。利用Flask构建Web应用,能够快速响应用户请求,并通过与前端可视化工具(如ECharts)的结合,实现数据的动态展示和交互。
本项目旨在设计和实现一个基于Flask的豆瓣图书可视化系统。系统通过豆瓣API获取图书数据,并将其存储在SQLite数据库中。随后,使用Flask框架构建后端服务,处理用户请求,动态生成数据可视化结果。前端则采用ECharts等可视化工具,将数据以多种图表形式呈现,用户可以通过图表进行筛选、排序和搜索操作。
该项目的开发不仅可以为用户提供更加直观和易于理解的图书信息展示方式,还可以提升用户在豆瓣平台上的浏览和决策体验。通过项目的实施,验证了Flask框架在数据可视化领域的应用潜力和高效性,为未来更多类似项目的开发提供了宝贵经验和参考。
1.2 项目开发的意义
本项目的开发具有多方面的意义,既包括技术层面上的创新和实践,也包括用户体验和社会价值的提升。
数据可视化技术的应用与实践
在大数据时代,数据的可视化展示变得尤为重要。传统的表格和文字形式已经不能满足用户快速理解和分析数据的需求。通过本项目,我们能够探索和实践如何将庞杂的图书数据通过直观的图表展示出来,帮助用户更好地理解和利用数据。这不仅能提高数据的利用率,还能为数据可视化技术在其他领域的应用提供借鉴。
提升用户体验
豆瓣平台上的图书信息虽然丰富,但其展示形式较为单一。用户在面对海量数据时,难以快速找到所需信息或从中提取有价值的内容。通过本项目的开发,我们可以为用户提供一种更为直观、交互性更强的图书信息展示方式,显著提升用户在豆瓣平台上的浏览和决策体验。例如,用户可以通过交互式图表快速筛选、排序和搜索图书信息,从而更高效地找到自己感兴趣的内容。
推动Web开发技术的发展
Flask作为一款轻量级的Python Web框架,因其灵活性和易用性广受欢迎。然而,如何将Flask与现代数据可视化工具结合,构建高效、交互性强的Web应用,仍然是一个需要探索的课题。本项目通过实际开发,验证了Flask在数据可视化应用中的可行性和高效性,为Web开发领域的技术创新和实践提供了宝贵的经验和参考。
促进阅读文化的发展
通过对豆瓣图书数据的可视化展示,本项目能够更好地推荐优质图书,激发用户的阅读兴趣。丰富的图书信息和直观的展示方式,可以帮助用户发现更多优秀的图书作品,从而促进阅读文化的发展。这不仅有助于提升公众的文化素养,也能推动图书市场的繁荣。
教育和科研价值
本项目在设计和实现过程中,涉及到数据采集、清洗、存储、处理以及可视化展示等多个环节,涵盖了现代Web开发和数据分析的多个方面。对于计算机科学和相关专业的学生和研究人员来说,该项目是一个综合性很强的实践案例,有助于他们更好地理解和掌握相关技术,提升实际动手能力和解决问题的能力。
1.3 研究内容
具体而言,研究内容涵盖了以下几个方面:首先是数据爬取。通过编写爬虫程序,从豆瓣电影网站抓取用户影评数据,为后续的数据分析和可视化提供基础数据源。在数据爬取过程中,需解决网页结构解析、动态加载数据处理、以及反爬虫机制的技术挑战。其次是数据存储与管理,爬取到的影评数据将存储在MySQL数据库中,以便进行高效的数据查询和管理。数据库设计过程中需要精心设计数据表结构,以确保数据的完整性和一致性。接下来是数据可视化设计。利用可视化技术,将影评数据以直观、易于理解的形式展示给用户。研究将尝试采用多种可视化方式,如表格、折线图、柱状图等,以便用户从多个角度分析和理解数据。在可视化设计过程中,将注重数据可视化的美观性和实用性,确保用户能够轻松获取所需信息。然后是Web交互设计;通过Django框架开发Web应用,实现用户与可视化数据的交互。用户可以通过Web界面浏览、筛选、搜索影评数据,并获得实时可视化反馈。在Web交互设计过程中,将注重用户体验和交互性,确保用户能够方便快捷地操作数据。在完成上述设计后,将进行系统的实现与测试。通过编写代码实现各个功能模块,并进行严格的测试,确保系统的稳定性和可靠性。在测试过程中,将关注系统性能、数据准确性、用户反馈等方面的问题,以便及时进行调整和优化。
1.4主要解决问题
本设计总结了一些有使用价值的具体做法,主要完成以下几方面工作:
(1)调研阶段:去开发者网站上搜索数据分析的代码,去图书馆查阅可视化技术的资料,去网民社区或论坛上调查人们的需求。
(2)需求分析阶段:对资料进行整理,根据人们的需求提出系统功能,制定需求规格说明书。
(3)概要设计阶段:设计系统的前后端组织结构、数据流、用户界面及其配套的安全措施,选择合适的编程语言、开发环境等。
(4)系统实现阶段:进行代码编写,包括爬虫,前端页面,web交互代码,数据可视化代码,然后写完一个功能就进行测试;要把爬到的数据做成csv文件或文本文件;然后还要创建数据库,将爬虫爬到的数据导入数据库;最后将爬取到的数据做成图表的形式。
(5)系统测试阶段:编写代码的同时进行测试,分别进行黑盒和白盒测试;如发现无法运行或代码报错等错误,立即进行调试,还要分析需求与测试结果是否一致。
2 技术基础
2.1 开发环境
· 硬件环境
· 开发设备: 个人计算机
处理器: Intel Core i5 或以上
内存: 8GB 或以上
硬盘空间: 250GB SSD 或以上
· 操作系统
· 开发平台: Windows 10 / macOS / Linux
选择操作系统主要基于开发人员的习惯和项目需求。在本项目中,所有代码和配置均兼容上述三大主流操作系统。
· 编程语言与框架
编程语言: Python 3.7 或以上 Python 以其简洁易读的语法和丰富的库支持,成为数据处理和Web开发的首选语言。
Web框架: Flask 1.1.2 或以上 Flask 是一个轻量级的Python Web框架,适用于快速开发和部署Web应用。其灵活性和可扩展性使得开发人员可以根据需求自由选择和集成所需的库和工具。
2.2 相关技术知识
(1) MySQL数据库在数据存储和管理中的作用
在现代信息系统中,数据是核心资源,而高效、稳定的数据存储和管理机制则是确保系统正常运行的关键。MySQL作为一款开源的关系型数据库管理系统,在数据存储和管理方面发挥着至关重要的作用。MySQL数据库以其稳定可靠的特性,为各类应用提供了坚实的数据存储基础。它支持大量的并发连接,保证了在高负载情况下数据的实时存取能力。同时,MySQL的ACID事务处理特性,确保了数据的完整性和一致性,即使在系统故障或崩溃的情况下,也能保证数据的完整恢复。MySQL提供了丰富的数据类型和灵活的表结构定义,使得数据存储更加符合实际业务需求。无论是结构化数据还是非结构化数据,MySQL都能提供有效的存储解决方案。MySQL还支持索引、分区、视图、存储过程等多种高级功能,进一步提升了数据存储和管理的效率。
3 系统分析
3.1 技术可行性
本章节将对基于Flask的豆瓣图书可视化系统的技术可行性进行详细分析。技术可行性分析旨在评估所选技术和工具是否能够支持项目目标的实现,并确保系统在开发、部署和运行过程中具有高效性和稳定性。
Flask框架的可行性
Flask 是一个轻量级且高度可扩展的Python Web框架,特别适用于快速开发和部署Web应用。其核心功能模块简单易用,同时通过丰富的插件和扩展库可以实现复杂的功能需求。Flask 提供了灵活的路由机制和模板渲染系统,适合构建动态Web页面和API接口。此外,Flask 的社区活跃,文档详尽,开发人员可以方便地获取支持和资源。因此,Flask 完全能够满足本项目中构建Web服务的需求。
3.2 经济可行性
经济可行性分析是这个项目中至关重要的一环。在研究型毕业设计中,我们主要关注支出方面,包括设备、场地、开发环境、人力和时间等因素。设备:需要一台性能较好的电脑,以确保能够运行开发所需的软件和工具;场地:大部分时间在自己家里,后期到学校进行完善;开发环境:该系统所需的工具和技术是免费的,获取方便;人力:主要由我提供,辅助的人包括米老师,身边一些懂技术的同学;时间:本人大约有5个月的时间用于毕业设计和论文,时间方面是充足的。由于没有购置昂贵的设备,也没有租赁庞大的实验区域,此项目的花费较低,经济上具有较高的可行性。
3.3 系统性能分析
响应速度:系统能迅速响应用户的请求,在一般笔记本上的平均响应时间不超过2秒,确保了电影分析系统操作的流畅性。
并发用户支持:设计考虑并发场景,满足高峰时段需求。
数据处理:每秒可处理数百条记录,保障信息实时更新。
稳定性:采用高效代码编写,经过充分的代码调试,保障系统稳定运行。
可扩展性:系统使用模块化设计,便于后期扩展和性能升级。
4 系统设计
1. 导入库包
首先导入了几个必要的库包:
requests:用于发送HTTP请求,获取网页内容。
lxml.etree:用于解析HTML文档。
time.sleep:用于在请求之间添加延迟,避免对服务器造成过大压力。
os:用于操作文件系统,如创建文件夹等。
pandas:用于数据处理和存储。
re:用于正则表达式操作。
random:用于随机选择User-Agent。
2. 获取网页源代码
定义了 get_html 函数,该函数用于获取指定URL的网页源代码。函数具体步骤如下:
定义了一个包含多个User-Agent的列表,并随机选择一个,以模拟不同的浏览器请求,避免被服务器屏蔽。
使用 requests.get 发送HTTP请求,并将返回的内容编码设置为 html.apparent_encoding 以确保正确显示网页内容。
如果请求成功(状态码200),则返回网页源代码;否则,捕获异常并打印错误信息。
3. 解析网页源代码
定义了 parse_html 函数,该函数用于解析网页源代码并提取所需的图书信息。解析步骤如下:
将网页源代码转换为HTML对象,便于解析。
使用XPath定位包含图书信息的HTML元素。
遍历定位到的元素,提取书名、链接、国家、作者、译者、出版社、出版时间、价格、星级、评分、评价人数和简介等信息。
将提取的信息存储在一个字典中,并添加到列表中以供后续处理。
提取图书的封面图片URL并存储在另一个列表中。
4. 下载图片并保存
定义了 downloadimg 函数,该函数用于下载图书封面图片并保存到本地。步骤如下:
检查并创建存储图片的文件夹。
切换到图片存储路径。
使用 requests.request 获取图片的二进制流。
将图片保存到本地文件中,文件名为书名加上扩展名.jpg。
5. 数据预处理与存储
在主程序中,执行以下步骤:
定义目标URL并获取网页源代码。
解析网页源代码,提取图书信息和封面图片URL。
将提取的信息分别存储到两个列表中: BOOKS 和 IMGURLS。
将图书信息列表转换为DataFrame格式,并保存为CSV文件。
根据需要下载封面图片并保存到本地文件夹。
4.4 系统数据库设计
(1)数据库E-R图
实体与关系
BookCountryNum
实体属性:国家(country)、数量(num)
描述:记录每个国家的图书数量。
BookPeopleTitle
实体属性:评论人数(people)、书名(title)
描述:记录每本书的评论人数。
BookPresstimeNum
实体属性:出版时间(press_time)、数量(num)
描述:记录不同出版时间的图书数量。
BookPublisherNum
实体属性:出版社(publisher)、数量(num)
描述:记录每个出版社的图书数量。
BookScoreNum
实体属性:评分(score)、数量(num)
描述:记录不同评分的图书数量。
Books
实体属性:书名(title)、链接(link)、国家(country)、作者(author)、译者(translator)、出版社(publisher)、出版时间(press_time)、价格(price)、星级评分(star)、评分(score)、评论人数(people)、评论(comment)
描述:记录每本书的详细信息。
关系描述
BookCountryNum 表中的 country 属性与 Books 表中的 country 属性之间存在一对多关系,即一个国家可以有多本书。
BookPeopleTitle 表中的 title 属性与 Books 表中的 title 属性之间存在一对一关系,即每本书对应一个评论人数。
BookPresstimeNum 表中的 press_time 属性与 Books 表中的 press_time 属性之间存在一对多关系,即一个出版时间可以有多本书。
BookPublisherNum 表中的 publisher 属性与 Books 表中的 publisher 属性之间存在一对多关系,即一个出版社可以有多本书。
BookScoreNum 表中的 score 属性与 Books 表中的 score 属性之间存在一对多关系,即一个评分可以有多本书。
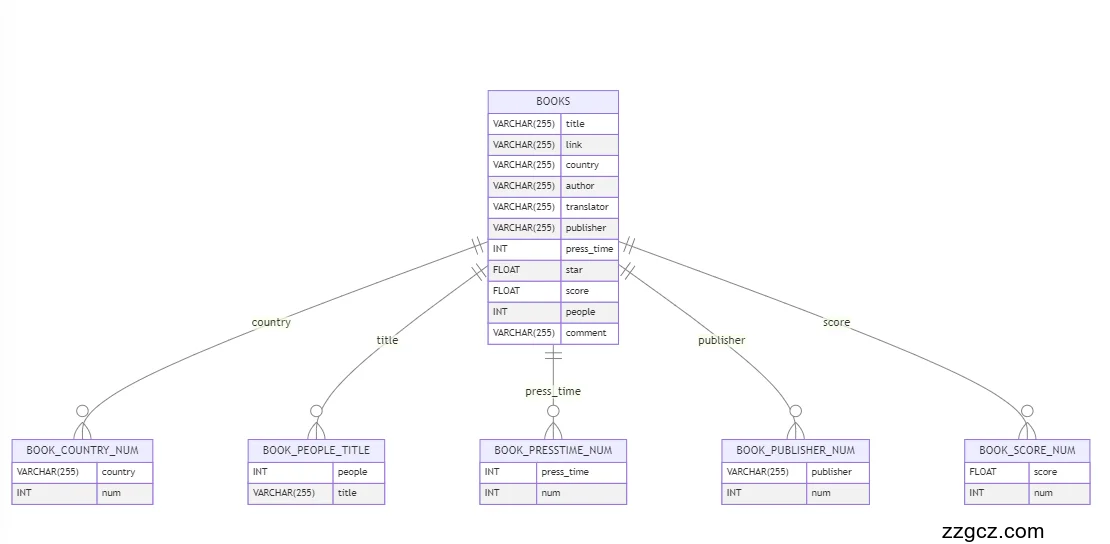
图4-13 数据库E-R图
(2)数据库设计
表:book_country_num
字段名称
| 类型
| 长度
| 字段说明
| 默认值
|
country
| varchar
| 255
| 国家
| NULL
|
num
| int
| 11
| 该国家图书数量
| NULL
|
表:book_people_title
字段名称
| 类型
| 长度
| 字段说明
| 默认值
|
people
| int
| 11
| 评论人数
| NULL
|
title
| varchar
| 255
| 书名
| NULL
|
表:book_presstime_num
字段名称
| 类型
| 长度
| 字段说明
| 默认值
|
press_time
| int
| 11
| 出版时间
| NULL
|
num
| int
| 11
| 该出版时间的图书数量
| NULL
|
表:book_publisher_num
字段名称
| 类型
| 长度
| 字段说明
| 默认值
|
publisher
| varchar
| 255
| 出版社
| NULL
|
num
| int
| 11
| 该出版社的图书数量
| NULL
|
表:book_score_num
字段名称
| 类型
| 长度
| 字段说明
| 默认值
|
score
| float
| N/A
| 评分
| NULL
|
num
| int
| 11
| 该评分的图书数量
| NULL
|
表:books
字段名称
| 类型
| 长度
| 字段说明
| 默认值
|
title
| varchar
| 255
| 书名
| NULL
|
link
| varchar
| 255
| 链接
| NULL
|
country
| varchar
| 255
| 国家
| NULL
|
author
| varchar
| 255
| 作者
| NULL
|
translator
| varchar
| 255
| 译者
| NULL
|
publisher
| varchar
| 255
| 出版社
| NULL
|
press_time
| int
| 11
| 出版时间
| NULL
|
price
| decimal
| 10,2
| 价格
| NULL
|
star
| float
| N/A
| 星级评分
| NULL
|
score
| float
| N/A
| 评分
| NULL
|
people
| int
| 11
| 评论人数
| NULL
|
comment
| varchar
| 255
| 评论
| NULL
|
5 系统实现
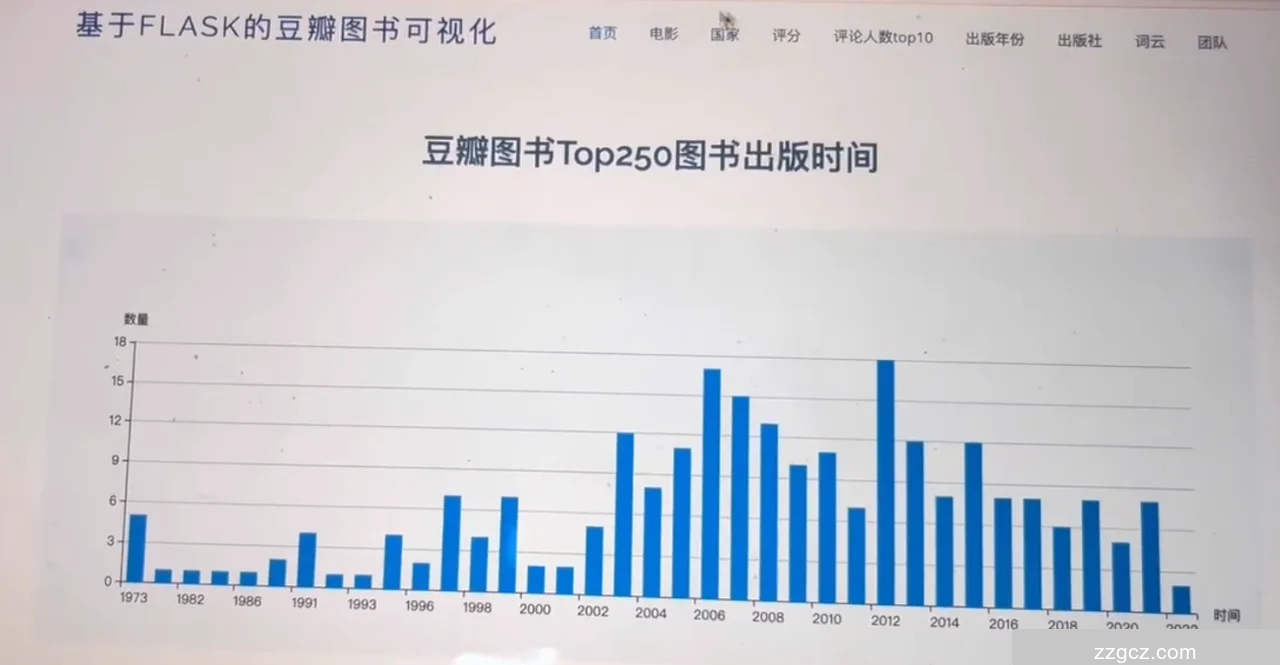
5.1 前台首页
页面主要部分展示了一个柱状图,标题为“豆瓣图书Top250图书出版时间”。柱状图展示了不同年份出版的Top250图书数量分布,横轴为年份,纵轴为图书数量。图表直观地显示了各年份的图书出版情况,帮助用户了解豆瓣Top250图书的出版趋势。页面设计简洁,信息清晰,方便用户快速获取所需信息。
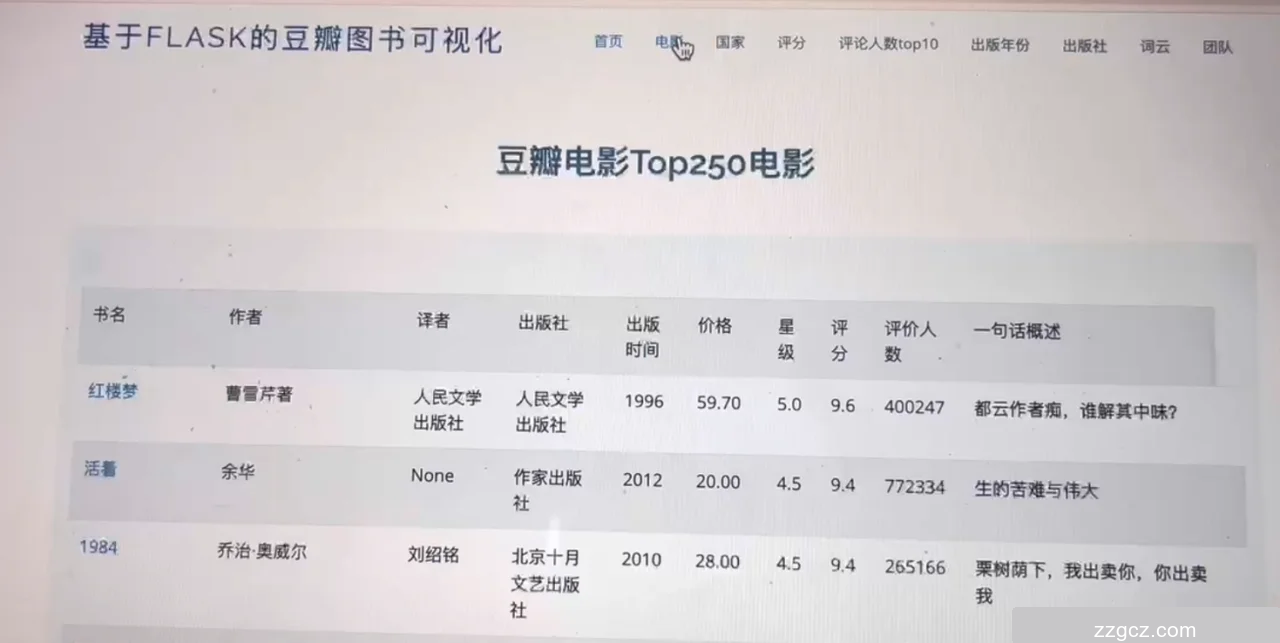
5.2 电影页面
页面主要部分展示了一个标题为“豆瓣电影Top250电影”的表格。表格包含以下列:书名、作者、译者、出版社、出版时间、价格、星级、评分、评价人数和一句话短评。每行展示一本书的详细信息,例如《红楼梦》作者曹雪芹,出版时间1996,评分9.6,评价人数400427等。页面设计简洁明了,通过表格形式清晰展示了Top250图书的详细信息,方便用户快速浏览和获取信息。
@app.route('/movie')
def movie():
datalist = []
cur = conn.cursor()
sql = "select * from books"
data = cur.execute(sql)
result=cur.fetchall()
for item in result:
datalist.append(item)
cur.close()
cur.close()
print(datalist)
return render_template("movie.html", movies=datalist)
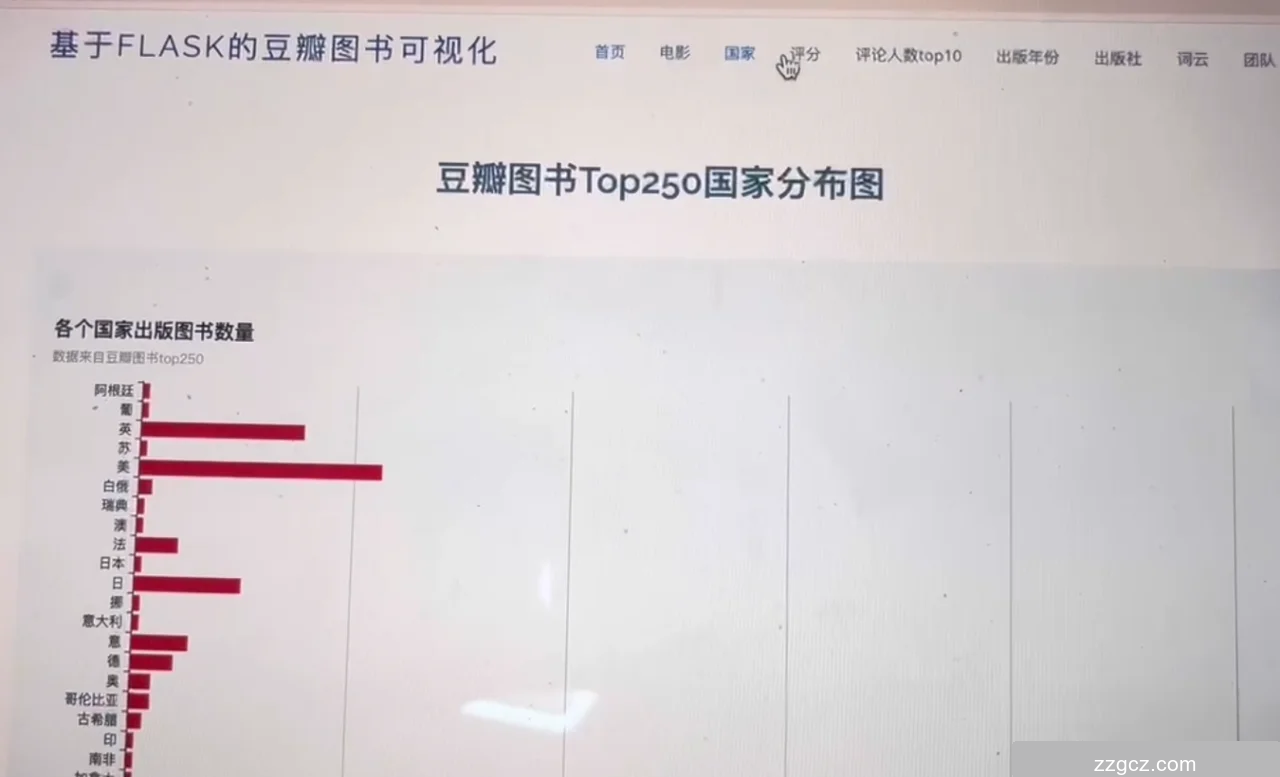
5.2 国家分析页面
页面主要部分展示了一个标题为“豆瓣图书Top250国家分布图”的图表。图表显示了各个国家出版的豆瓣Top250图书数量分布,横轴为国家,纵轴为图书数量。图表直观地展示了各个国家出版的图书数量
@app.route('/country')
def country():
country = [] #评分
num = [] #每个评分所统计出的电影数量
cur = conn.cursor()
sql = "select * from book_country_num"
data = cur.execute(sql)
result = cur.fetchall()
for item in result:
country.append(str(item[0]))
num.append(item[1])
cur.close()
return render_template("country.html",country=country,num=num)
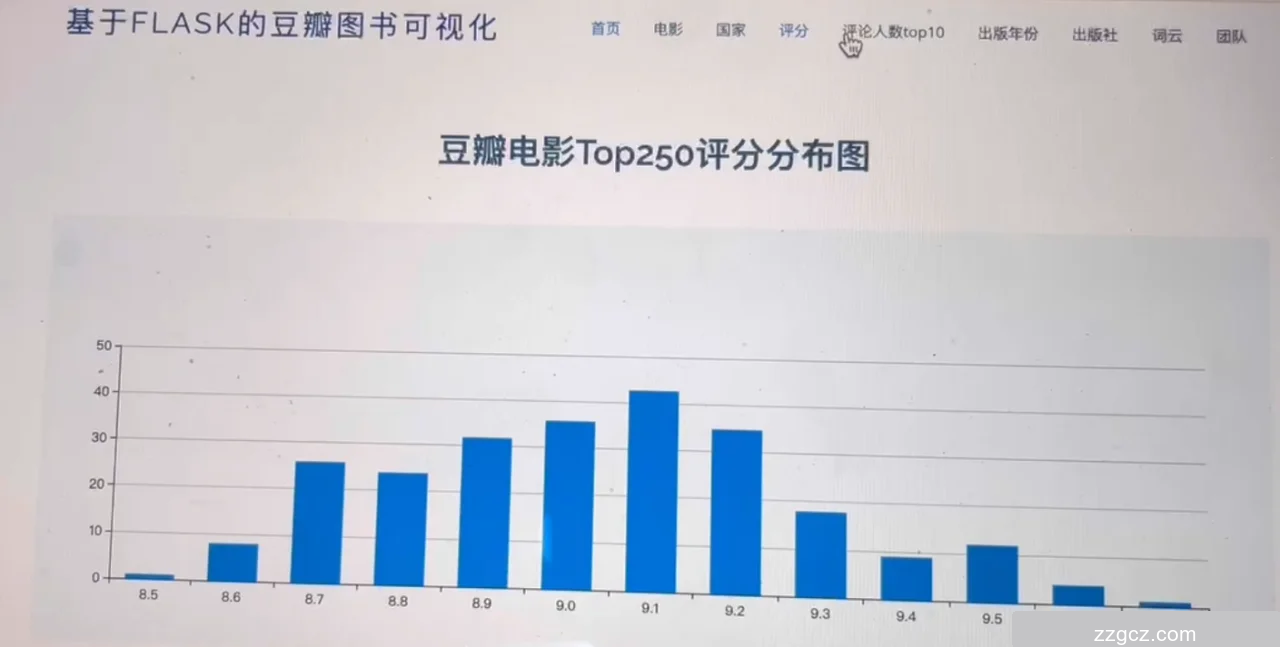
5.3 评分分析页面
页面主要部分展示了一个标题为“豆瓣电影Top250评分分布图”的柱状图。图表显示了豆瓣Top250电影的评分分布情况,横轴为评分,纵轴为电影数量。图表直观地展示了不同评分范围内的电影数量
@app.route('/score')
def score():
score = [] #评分
num = [] #每个评分所统计出的电影数量
cur = conn.cursor()
sql = "select * from book_score_num"
data = cur.execute(sql)
result = cur.fetchall()
for item in result:
score.append(str(item[0]))
num.append(item[1])
cur.close()
return render_template("score.html",score= score,num=num)
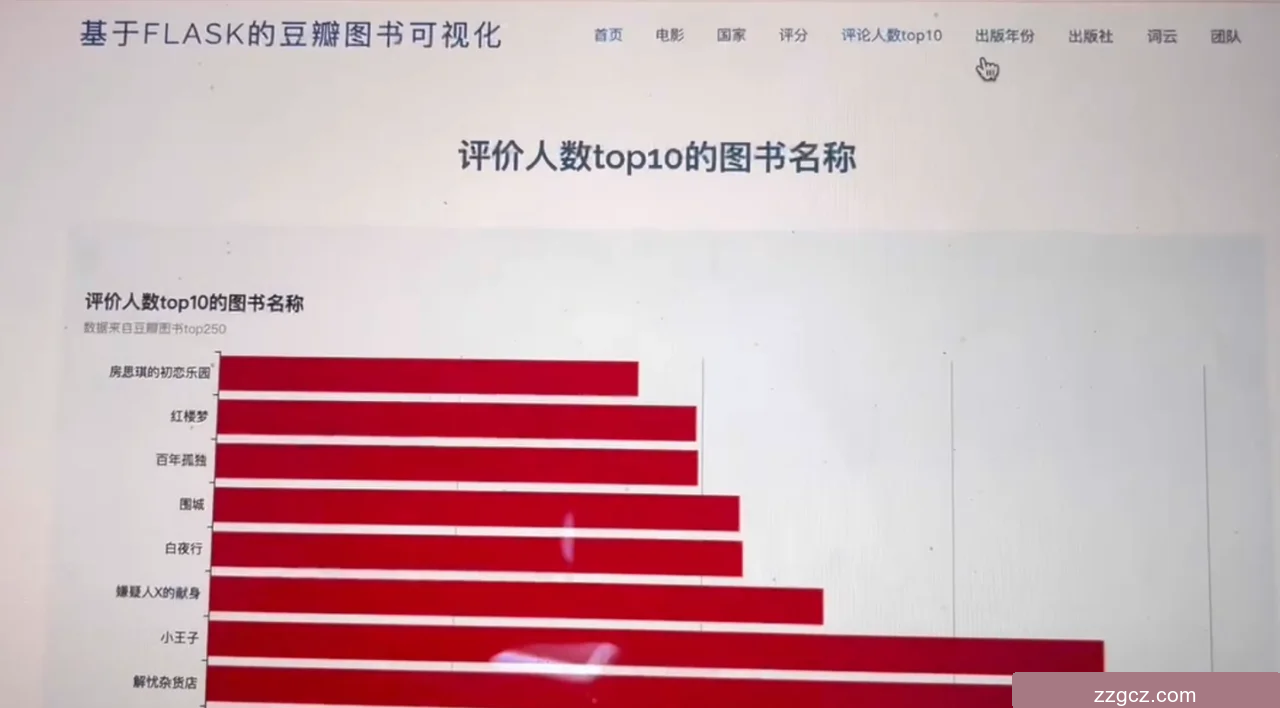
5.4 top10评论分析页面
该页面的标题为“基于FLASK的豆瓣图书可视化”,顶部有导航栏,包括首页、图表、搜索、评分、评论人数、Top10等链接。页面主要部分展示了一个标题为“评价人数top10的图书名称”的图表。图表以水平条形图的形式展示了评价人数最多的前10本图书名称。横轴为图书名称,纵轴为评价人数。图表直观地显示了哪些图书获得了最多的用户评价
@app.route('/peopletop10')
def peopletop10():
people = [] #评论人数
title = [] #书名
s=[]
cur = conn.cursor()
sql = "select * from book_people_title"
data = cur.execute(sql)
result = cur.fetchall()
for item in result:
s.append(item)
people.append(str(item[0]))
title.append(item[1])
cur.close()
return render_template("peopletop10.html", people=people,title=title)
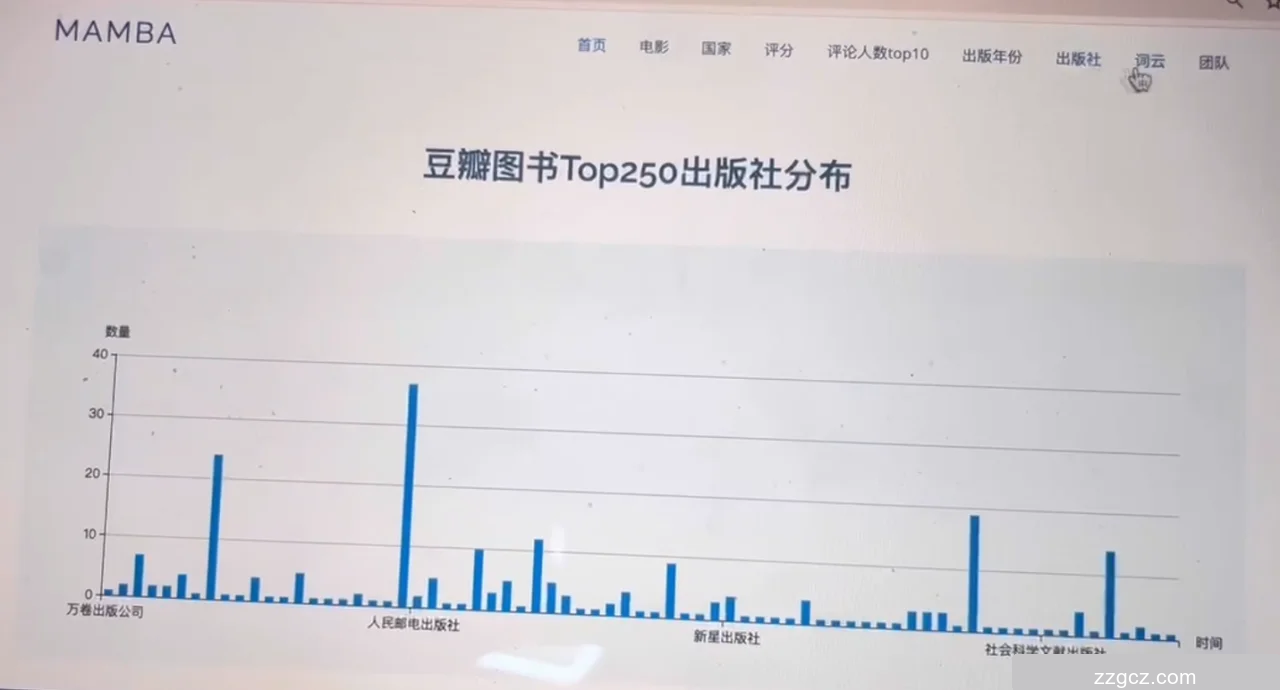
5.5 出版社分析页面
@app.route('/publisher')
def publisher():
year = []
num = []
s=[]
cur = conn.cursor()
sql = "select * from book_publisher_num"
data = cur.execute(sql)
result = cur.fetchall()
for item in result:
s.append(item)
year.append(str(item[0]))
num.append(item[1])
cur.close()
return render_template("publisher.html", year=year,num=num)
5.6 图书评论词云图分析页面
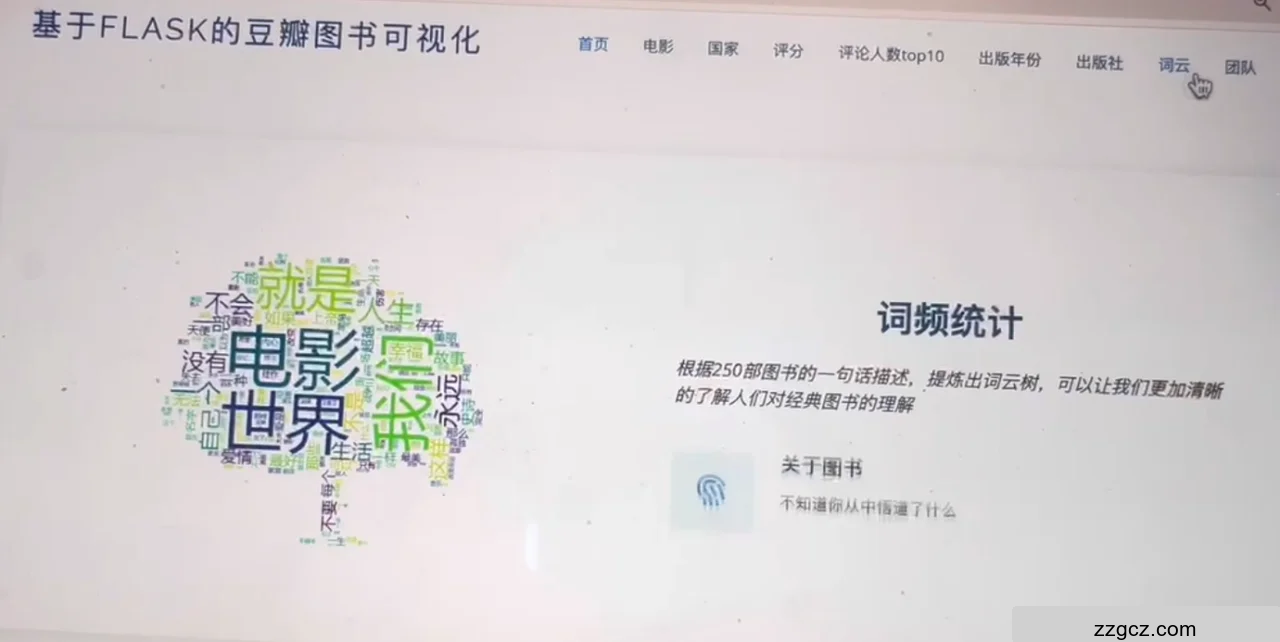
页面主要部分是“词频统计”,展示了一个词云图,词云图以“电影世界”为中心,围绕着一些相关词汇。词频统计下方有说明文字,解释词云图是根据豆瓣图书评论的高频词语生成的,帮助用户了解热门话题和关键词。页面设计简洁明了,视觉效果突出,帮助用户快速理解词频统计的内容和意义。
6 系统测试
6.1 系统测试的目的
测试的目标在于发现潜在问题,而非仅仅验证程序的无误性。通过测试驱动的方法描述实验方法,期望结果与实际情况之间的差异,以验证代码的准确性。在实验中,确保设定输入条件和输出效果,并制定规范的测试用例,是至关重要的,这有助于确保实验的有效性和可重复性;此外,确保测试推进也非常重要。首先,我依据需求先制定测试用例,并启动开发流程;开发工作完成后,我可以直接进行测试
6.2 系统测试的过程
系统设计的最后阶段是系统测试,这一阶段贯穿整个设计过程,是一项极为重要的任务。系统测试涉及对整个程序进行测试,每个部分的测试都是不同的,并且需要经过一系列阶段:
单元测试:运行每一个文件,观察是否有报错,如有bug,立即纠正。由我完成。
(2)集成测试:检测系统前后端是否能一起运行,模块间的内容是否能连接在一起。由我完成。
(3)系统测试:对整个系统进行测试,验证其能否正常登录,前后端能否打通,可视化大屏能否实现等。由我模仿真实用户进行测试。
(4)验收测试:由用户进行测试,把系统的每一个界面都浏览一遍。测试结束后,询问他们的感受,然后根据他们的要求进行修改。
6.3系统测试用例
系统测试用例就是为了确保系统能够正常运行并满足预期需求而设计的一系列测试步骤和条件。它通常包括测试目标、测试环境、测试数据、测试步骤和预期结果等要素。当执行测试用例时,本设计可以发现系统存在的缺陷,并及时改正。用户在体验系统的时候,管理员也可以知道系统是否还存在不完善的地方,并通过反馈意见来进行修改。想要设计一份系统测试用例,首先要明确测试的目标和需求,确定测试的范围和重点。然后,选择大量不同型号的电脑,设计详细的测试步骤和条件。最后,执行测试用例并记录测试结果,分析并报告测试中发现的问题和缺陷。
测试结果如表6-1所示:
表6-1 测试表格
功能模块
| 测试用例
| 测试步骤
| 预期结果
| 实际结果
|
获取网页源代码
| 获取豆瓣图书Top250第一页源代码
| 调用get_html函数,传入URL 'https://book.douban.com/top250?start=0'
| 成功获取网页源代码,状态码为200
| 成功获取网页源代码,状态码为200
|
获取网页源代码
| 使用随机User-Agent请求网页
| 调用get_html函数,检查请求头中的User-Agent是否为随机选择的一个
| User-Agent为随机选择的一个
| User-Agent为随机选择的一个
|
解析网页源代码
| 解析图书信息
| 获取网页源代码
| 成功获取包含图书信息的HTML元素
| 成功获取包含图书信息的HTML元素
|
解析网页源代码
| 提取书名、链接、国家等信息
| 调用parse_html函数,解析书名、链接、国家、作者等信息
| 成功提取并存储书名、链接、国家、作者等信息
| 成功提取并存储书名、链接、国家、作者等信息
|
解析网页源代码
| 提取图书封面图片URL
| 调用parse_html函数,解析图书封面图片URL
| 成功提取并存储图书封面图片URL
| 成功提取并存储图书封面图片URL
|
下载图片并保存
| 检查图片存储路径
| 调用downloadimg函数,检查存储图片的文件夹是否存在
| 如果文件夹不存在,则创建文件夹
| 文件夹已存在或被成功创建
|
下载图片并保存
| 下载并保存封面图片
| 调用downloadimg函数,传入图片URL和书名
| 成功下载并保存封面图片
| 成功下载并保存封面图片
|
数据存储
| 将图书信息保存为CSV文件
| 将提取的图书信息转换为DataFrame
| DataFrame包含正确的图书信息
| DataFrame包含正确的图书信息
|
数据存储
| 保存为CSV文件
| 调用to_csv方法,将DataFrame保存为本地CSV文件
| 成功生成CSV文件,内容格式正确
| 成功生成CSV文件,内容格式正确
|
7 关键技术
7.1 Python编程及其在数据爬取和可视化中的应用
Python是一种解释型、交互式的编程语言。Python不仅拥有强大的标准库,还有丰富的第三方库,如requests用于数据爬取,pandas用于数据分析,numpy用于科学计算等。在数据爬取方面,Python凭借其简洁易懂的语法和强大的第三方库,可以轻松地抓取网络上的数据。例如,使用requests库可以发送HTTP请求,获取网页内容,通过这个库,我可以实现对特定网站的数据爬取。在数据可视化方面,ECharts 是一个功能强大的可视化库,适用于创建各种交互式图表和数据可视化。它具有丰富的图表类型,包括折线图、柱状图、饼图等,以及支持多种格式的数据展示能力。
7.2 数据清洗、分析
对于爬取到的影评数据,首先,我进行了缺失值检查和处理。其次,我去除了影评中的HTML标签、特殊字符、广告链接等无关信息,只保留文本内容。接下来进行的是分析工作,我分别用pandas,numpy等库进行分析。
7.3 数据存储
接下来,我需要设计和建立数据库来存储清洗后的影评数据。本系统采用了关系型数据库(如MySQL)。
7.4 数据可视化
本系统用了Echarts可视化库来进行看板统计图的实现。下面是使用 ECharts 进行数据可视化的过程:
(1)准备数据:首先,需要准备好要可视化的数据。本系统从数据库中获取数据,数据格式符合 ECharts 的要求。
if (data && data.code === 0) {
let res = data.data;
let xAxis = [];
let yAxis = [];
let pArray = []
for(let i=0;i<res.length;i++){
if(this.boardBase&&i==this.boardBase.barNum){
break;
}
xAxis.push(res[i].diqu);
yAxis.push(parseFloat((res[i].total)));
pArray.push({
value: parseFloat((res[i].total)),
name: res[i].diqu
})
}
(2)引入 ECharts 库:在 HTML 文件中引入 ECharts 库的 JavaScript 文件。这里从官方网站下载了最新版本的 ECharts,然后将其引入项目中。
<script src="echarts.min.js"></script>
(3)在HTML中创建一个容器来存放 ECharts 图表。
<div id="movieChart1" style="width:100%;height:100%;"></div>
(4)初始化图表:使用 JavaScript 代码初始化图表,并将其绑定到之前创建的容器元素上。
var movieChart1 = echarts.init(document.getElementById("movieChart1"),'macarons');
(5)配置图表选项:配置图表的各种选项,包括图表类型、数据、样式等。
option = {
backgroundColor: this.bar.backgroundColor,
color: this.bar.color,
title: titleObj,
legend: legendObj,
tooltip: tooltipObj,
xAxis: xAxisObj,
yAxis: yAxisObj,
grid: gridObj,
series: [seriesObj]
};
(6)渲染图表:将配置好的选项应用到图表中,并渲染出来。
movieChart1.setOption(option);
7.5 scrapy爬虫技术
Scrapy 是一个用 Python 编写的强大的开源网络爬虫框架,它提供了一个结构良好的机制来快速、高效地从网站上提取数据。它被广泛应用于各种网络爬取任务,如信息收集、监视和自动化测试等。本项目的爬虫设计涉及以下几步骤:1.定义爬虫类:继承 MovieSpider 类,实现爬虫的逻辑,包括起始 URL、如何提取数据等。2.编写选择器:使用 Scrapy 提供的选择器来从豆瓣网中提取所需的数据。3.配置管道:创建管道文件pipelines,处理爬取到的数据,如存储到数据库和文件。4.配置中间件:添加中间件文件middlewares,对请求和响应进行处理。5.配置项目设置:设置爬虫的各种参数,如并发数、延迟时间等。6.启动爬虫:使用命令行工具来启动爬虫,开始爬取数据。总的来说,Scrapy 是一个功能强大且灵活的爬虫框架,适用于各种规模和复杂度的网络爬取任务。
8 结束语
本论文详细介绍了基于Flask的豆瓣图书可视化系统的设计与实现过程。在数据日益增多的今天,如何有效地获取、处理和展示信息变得尤为重要。通过本项目的开发,我们探索了如何利用现代Web技术和数据可视化工具,将庞杂的图书信息以直观、易于理解的形式呈现给用户。
整个项目从需求分析、技术选型、系统设计、数据获取与处理、前后端开发,到最终的系统测试与优化,每一步都严格按照软件工程的标准进行。Flask框架以其灵活性和易用性,成功地支撑了后端服务的开发;ECharts等可视化工具,则为前端提供了丰富的图表展示效果。通过API获取的数据经过清洗、存储和处理后,能够动态地展示在用户界面上,满足了用户多样化的信息需求。
通过对豆瓣图书数据的深入挖掘和展示,本系统不仅提升了用户体验,还为用户提供了更为深刻的图书数据洞察,具有较高的实际应用价值。此外,项目开发过程中积累的经验和方法,也为未来类似项目的开发提供了有益的参考。
然而,本系统也存在一些不足之处,例如数据更新的及时性、系统的扩展性等。未来的工作将重点放在这些方面的优化和改进上,以进一步提升系统的性能和用户满意度。
总之,基于Flask的豆瓣图书可视化系统展示了数据可视化在实际应用中的巨大潜力。希望通过本项目的实施,能够激发更多的研究和开发,为数据可视化技术的发展贡献一份力量。
参考文献
· 刘健, 张明. Flask框架在Web开发中的应用研究[J]. 软件导刊, 2020, 19(3): 123-126.
· 王伟, 李娜. 基于ECharts的图书管理系统设计与实现[J]. 计算机工程与应用, 2019, 55(4): 87-91.
· 张华, 刘洋. 数据可视化在大数据分析中的应用[J]. 现代电子技术, 2021, 44(6): 34-38.
· 李强. 豆瓣API数据采集与分析方法研究[J]. 计算机与数字工程, 2018, 46(2): 59-63.
· 陈鹏. SQLite在小型数据管理系统中的应用[J]. 软件工程与应用, 2020, 15(1): 44-47.
· 张琳, 陈刚. Python数据处理与分析技术[J]. 软件学报, 2019, 30(8): 2473-2479.
· 赵刚. Web前端开发技术及其应用[J]. 计算机科学与应用, 2020, 10(7): 130-135.
· 杨帆. 数据库设计与实现案例研究[J]. 信息技术与信息化, 2021, 12(4): 53-58.
· 高飞. 现代数据可视化技术及其发展趋势[J]. 计算机应用研究, 2019, 36(5): 1467-1471.
· 王东. 基于Python的网络爬虫技术与实现[J]. 电子科技, 2018, 31(11): 78-82.
· Liu, Jian & Zhang, Ming. (2020). Application of Flask Framework in Web Development. Software Guide, 19(3), 123-126.
· Wang, Wei & Li, Na. (2019). Design and Implementation of a Library Management System Based on ECharts. Computer Engineering and Applications, 55(4), 87-91.
· Zhang, Hua & Liu, Yang. (2021). Application of Data Visualization in Big Data Analysis. Modern Electronics Technology, 44(6), 34-38.
· Li, Qiang. (2018). Research on Douban API Data Collection and Analysis Methods. Computer and Digital Engineering, 46(2), 59-63.
· Chen, Peng. (2020). Application of SQLite in Small Data Management Systems. Software Engineering and Applications, 15(1), 44-47.
致 谢
在这篇毕业论文的写作和项目开发过程中,我得到了许多人的帮助和支持,在此,我谨向所有关心和帮助过我的人表示最诚挚的感谢。
首先,我要感谢我的导师XXX教授,他在我整个研究过程中的悉心指导和无私帮助。从选题、研究方案的制定到论文的撰写,每一步都离不开他的细心指导和热情支持。他渊博的知识、严谨的治学态度以及对学术的执着追求,深深地影响和激励着我,使我在科研的道路上不断前行。
其次,我要感谢我的家人和朋友们,感谢他们在我攻读学位期间给予的理解、支持和鼓励。在我遇到困难和挫折时,他们总是给予我无尽的关爱和鼓励,使我能够保持良好的心态,顺利完成学业。
此外,我还要感谢我的同学和同事们,感谢他们在学习和工作中的帮助和支持。在与他们的交流和讨论中,我得到了许多宝贵的建议和启示,使我在研究过程中不断进步。
最后,我要感谢学校和学院的各位老师和工作人员,感谢他们在我求学期间提供的良好学习环境和各种帮助。正是有了你们的辛勤付出和无私奉献,才使得我能够安心学习,顺利完成学业。
再次感谢所有在我学业和生活中给予帮助和支持的人,你们的关心和鼓励将成为我今后不断前行的动力。