A198-基于英雄联盟数据集的LightGBM的分类预测
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
1.1 LightGBM原理简介
LightGBM是2017年由微软推出的可扩展机器学习系统,是微软旗下DMKT的一个开源项目,它是一款基于GBDT(梯度提升决策树)算法的分布式梯度提升框架,为了满足缩短模型计算时间的需求,LightGBM的设计思路主要集中在减小数据对内存与计算性能的使用,以及减少多机器并行计算时的通讯代价。
LightGBM可以看作是XGBoost的升级豪华版,在获得与XGBoost近似精度的同时,又提供了更快的训练速度与更少的内存消耗。正如其名字中的Light所蕴含的那样,LightGBM在大规模数据集上跑起来更加优雅轻盈,一经推出便成为各种数据竞赛中刷榜夺冠的神兵利器。
LightGBM底层实现了GBDT算法,并且添加了一系列的新特性:
-
基于直方图算法进行优化,使数据存储更加方便、运算更快、鲁棒性强、模型更加稳定等。
-
提出了带深度限制的 Leaf-wise 算法,抛弃了大多数GBDT工具使用的按层生长 (level-wise) 的决策树生长策略,而使用了带有深度限制的按叶子生长策略,可以降低误差,得到更好的精度。
-
提出了单边梯度采样算法,排除大部分小梯度的样本,仅用剩下的样本计算信息增益,它是一种在减少数据量和保证精度上平衡的算法。
-
提出了互斥特征捆绑算法,高维度的数据往往是稀疏的,这种稀疏性启发我们设计一种无损的方法来减少特征的维度。通常被捆绑的特征都是互斥的(即特征不会同时为非零值,像one-hot),这样两个特征捆绑起来就不会丢失信息。
LightGBM是基于CART树的集成模型,它的思想是串联多个决策树模型共同进行决策。
那么如何串联呢?LightGBM采用迭代预测误差的方法串联。举个通俗的例子,我们现在需要预测一辆车价值3000元。我们构建决策树1训练后预测为2600元,我们发现有400元的误差,那么决策树2的训练目标为400元,但决策树2的预测结果为350元,还存在50元的误差就交给第三棵树……以此类推,每一颗树用来估计之前所有树的误差,最后所有树预测结果的求和就是最终预测结果!
LightGBM的基模型是CART回归树,它有两个特点:(1)CART树,是一颗二叉树。(2)回归树,最后拟合结果是连续值。
LightGBM模型可以表示为以下形式,我们约定ft(x)ft(x)表示前tt颗树的和,ht(x)ht(x)表示第tt颗决策树,模型定义如下:
ft(x)=∑Tt=1ht(x)ft(x)=∑t=1Tht(x)
由于模型递归生成,第tt步的模型由第t−1t−1步的模型形成,可以写成:
ft(x)=ft−1(x)+ht(x)ft(x)=ft−1(x)+ht(x)
每次需要加上的树ht(x)ht(x)是之前树求和的误差:
rt,i=yi−fm−1(xi)rt,i=yi−fm−1(xi)
我们每一步只要拟合一颗输出为rt,irt,i的CART树加到ft−1(x)ft−1(x)就可以了。
1.2 LightGBM的应用
LightGBM在机器学习与数据挖掘领域有着极为广泛的应用。据统计LightGBM模型自2016到2019年在Kaggle平台上累积获得数据竞赛前三名三十余次,其中包括CIKM2017 AnalytiCup、IEEE Fraud Detection等知名竞赛。这些竞赛来源于各行各业的真实业务,这些竞赛成绩表明LightGBM具有很好的可扩展性,在各类不同问题上都可以取得非常好的效果。
同时,LightGBM还被成功应用在工业界与学术界的各种问题中。例如金融风控、购买行为识别、交通流量预测、环境声音分类、基因分类、生物成分分析等诸多领域。虽然领域相关的数据分析和特性工程在这些解决方案中也发挥了重要作用,但学习者与实践者对LightGBM的一致选择表明了这一软件包的影响力与重要性。
2.相关流程
-
了解 LightGBM 的参数与相关知识
-
掌握 LightGBM 的Python调用并将其运用到英雄联盟游戏胜负预测数据集上
Part1 基于英雄联盟数据集的LightGBM分类实践
-
Step1: 库函数导入
-
Step2: 数据读取/载入
-
Step3: 数据信息简单查看
-
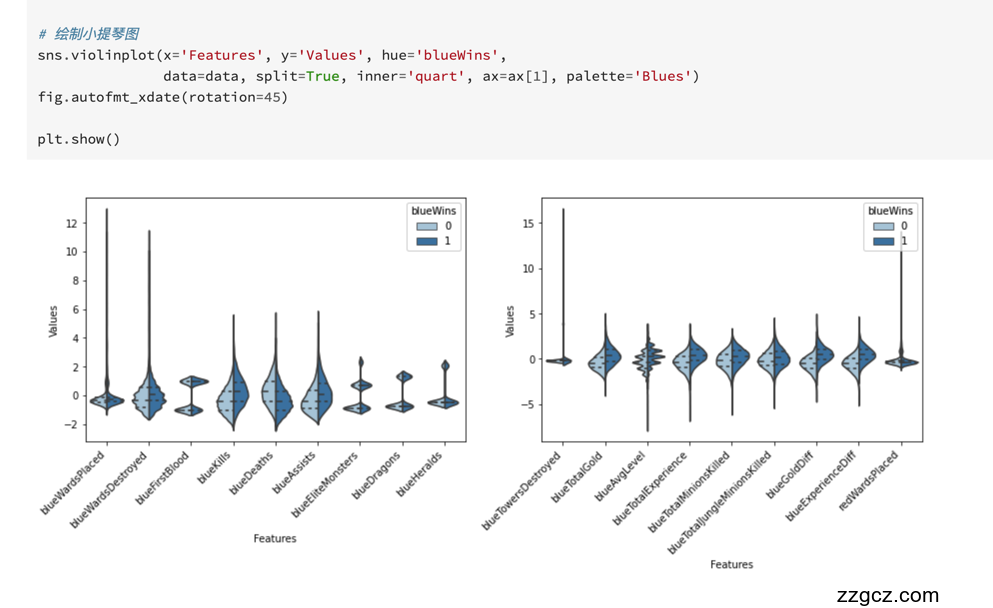
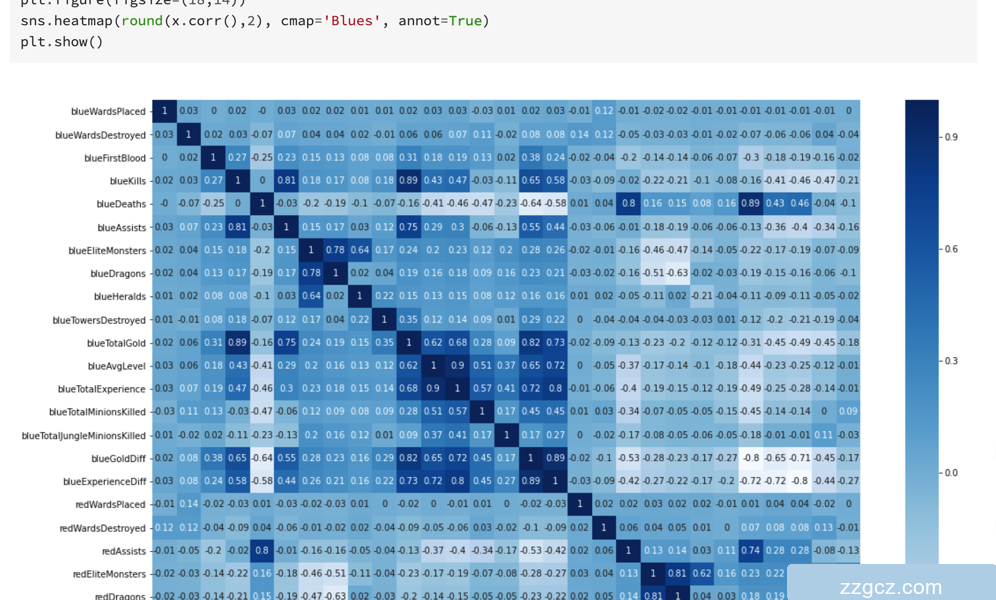
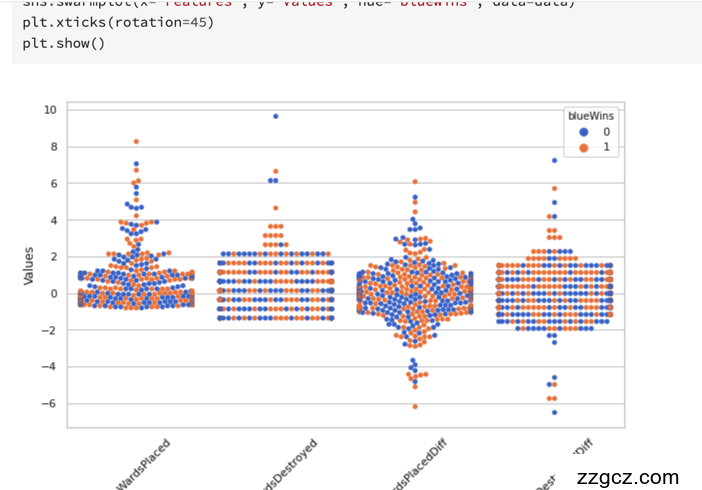
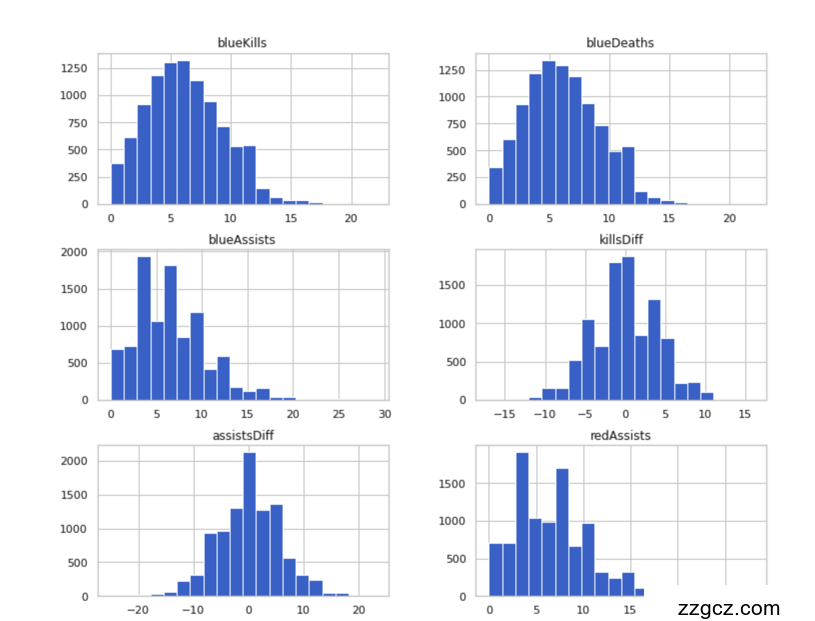
Step4: 可视化描述
-
Step5: 利用 LightGBM 进行训练与预测
-
Step6: 利用 LightGBM 进行特征选择
-
Step7: 通过调整参数获得更好的效果
3.基于英雄联盟数据集的LightGBM分类实战
评论
在实践的最开始,我们首先需要导入一些基础的函数库包括:numpy (Python进行科学计算的基础软件包),pandas(pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具),matplotlib和seaborn绘图。
英雄联盟韩服钻石段位以上的排位比赛数据 下载
背景描述
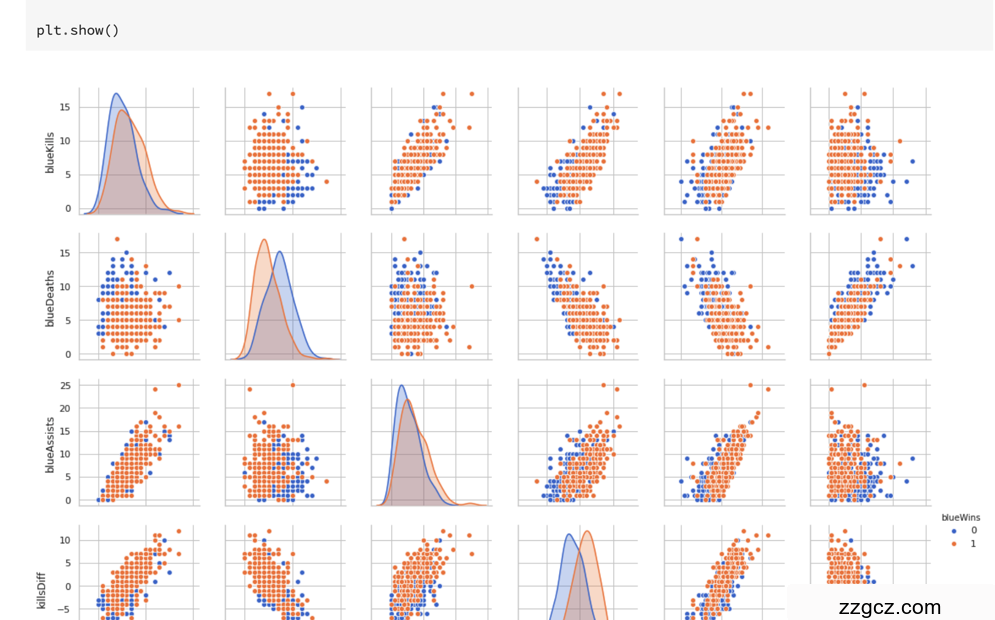
本次我们选择英雄联盟数据集进行LightGBM的场景体验。英雄联盟是2009年美国拳头游戏开发的MOBA竞技网游,在每局比赛中蓝队与红队在同一个地图进行作战,游戏的目标是破坏敌方队伍的防御塔,进而摧毁敌方的水晶枢纽,拿下比赛的胜利。
现在共有9881场英雄联盟韩服钻石段位以上的排位比赛数据,数据提供了在十分钟时的游戏状态,包括击杀数、死亡数、金币数量、经验值、等级……等信息。列blueWins是数据的标签,代表了本场比赛是否为蓝队获胜。
数据说明