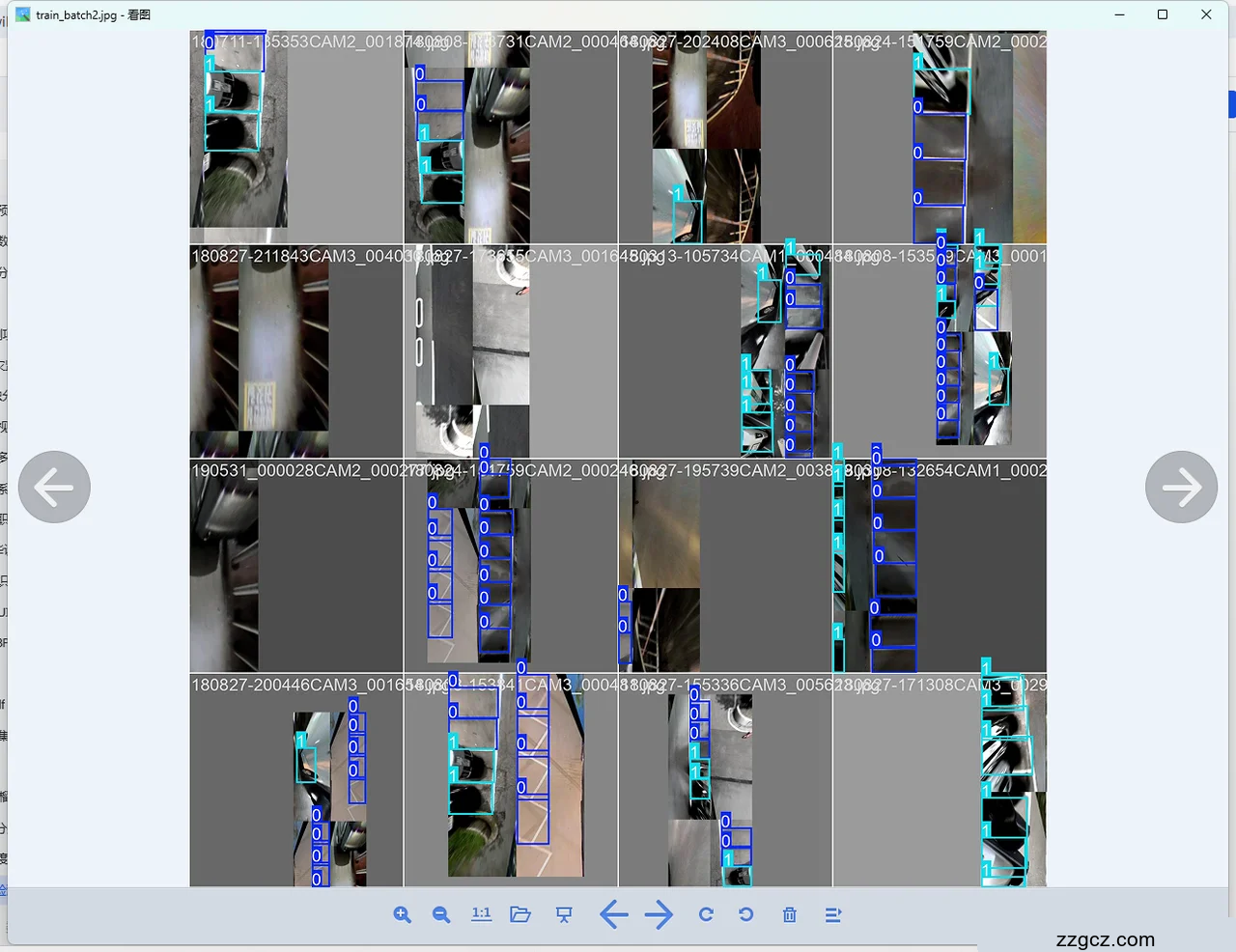
A247-多个yolo模型对比融合创新CBAM注意力集成GhostNet实验停车位线识别检测
导出时间:2025/12/5 11:39:49
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
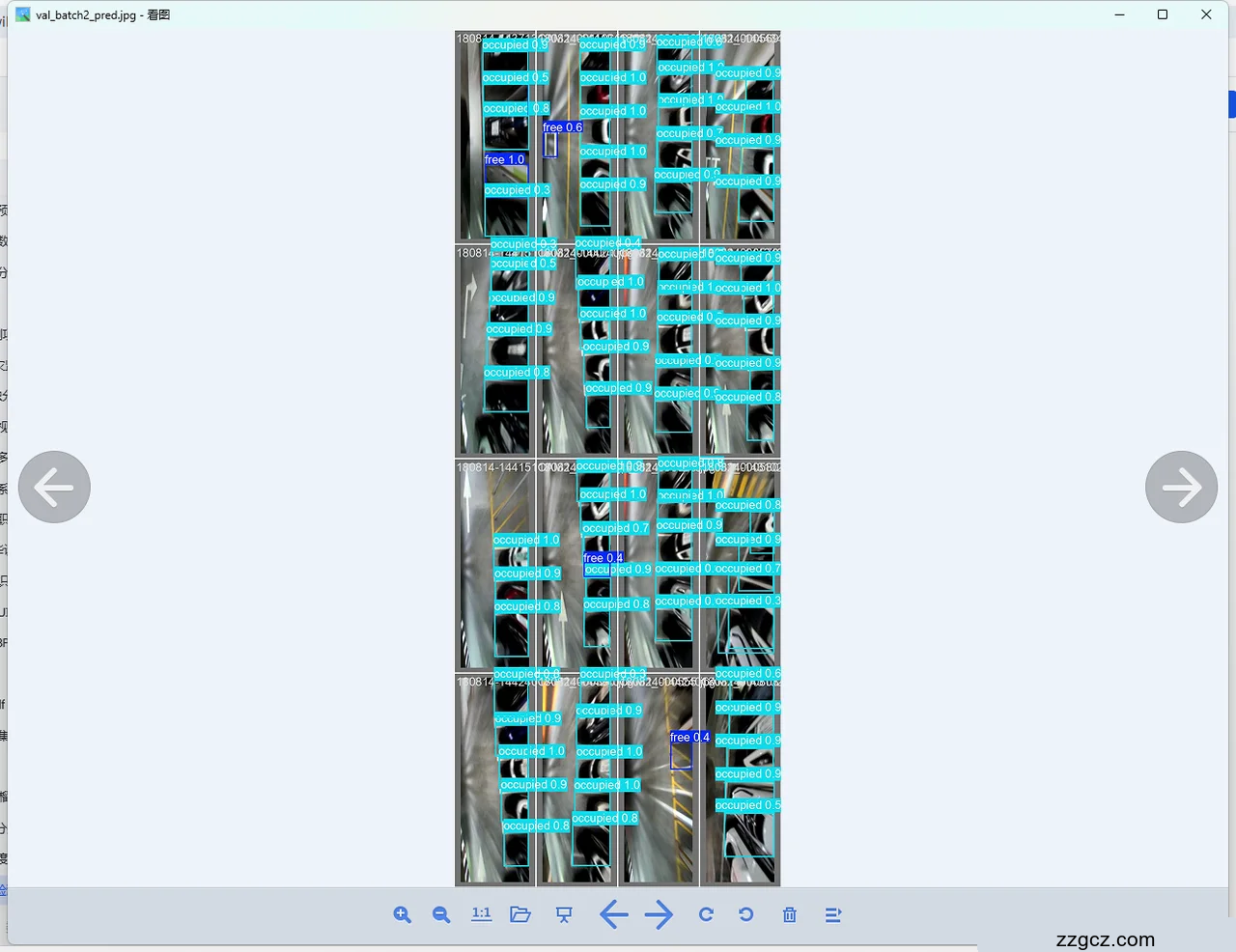
车位线的准确和快速识别是自动泊车系统实现的关键。然而,由于车位类型多样、光照条件多变、车位标线部分损坏或模糊以及障碍物遮挡等因素的影响,现有车位线识别方法在复杂环境下识别率较低,计算开销大,误差较大,主流方法的识别准确率仅为70%-85%。此外,现有方法识别速度较慢,基本未能达到30 FPS的实时检测标准,严重影响了自动泊车系统的推广应用。
本研究旨在开发一种轻量化深度学习模型,用于实时识别车位线。借鉴YOLO11主干网络的高效多尺度特征融合结构,特别是在复杂场景下,模型能更好地处理不同尺寸的目标,同时保持高效的推理性能。因此我们将车位角点、车位线和车位占用情况等多种特征相结合,并将车位线抽象为角点间的线段,以避免车位线形态的影响,从而在复杂环境下实现高准确性且支持多目标检测的车位线识别。同时,基于轻量化设计原则,我们对深度学习模型的网络结构进行优化,引入Convolutional Block Attention Module(CBAM)注意力机制模块,优化损失函数,提高车位识别精度,引入GhostNet通过生成更为紧凑的‘幽灵特征’(Ghost Features),减少冗余计算,减少模型的算力消耗。
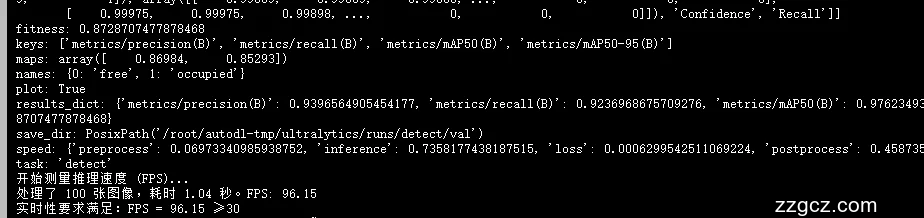
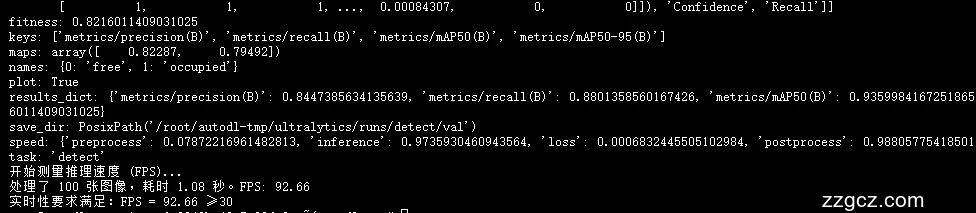
实验结果表明,所设计模型在保证高准确率的同时,显著降低了计算开销,能够在车载计算平台上以30FPS以上的速度实时车位识别。该研究为自动泊车系统在复杂环境下的应用提供了有效的技术方案,并为车位识别任务的轻量化与高效性提供了新的思路。
 |  |
实验方案
基线模型训练:分别训练YOLOv5、YOLOv8、YOLOv9、YOLOv11模型,记录各自的训练时间、推理速度和检测精度。
YOLOv11网络结构优化
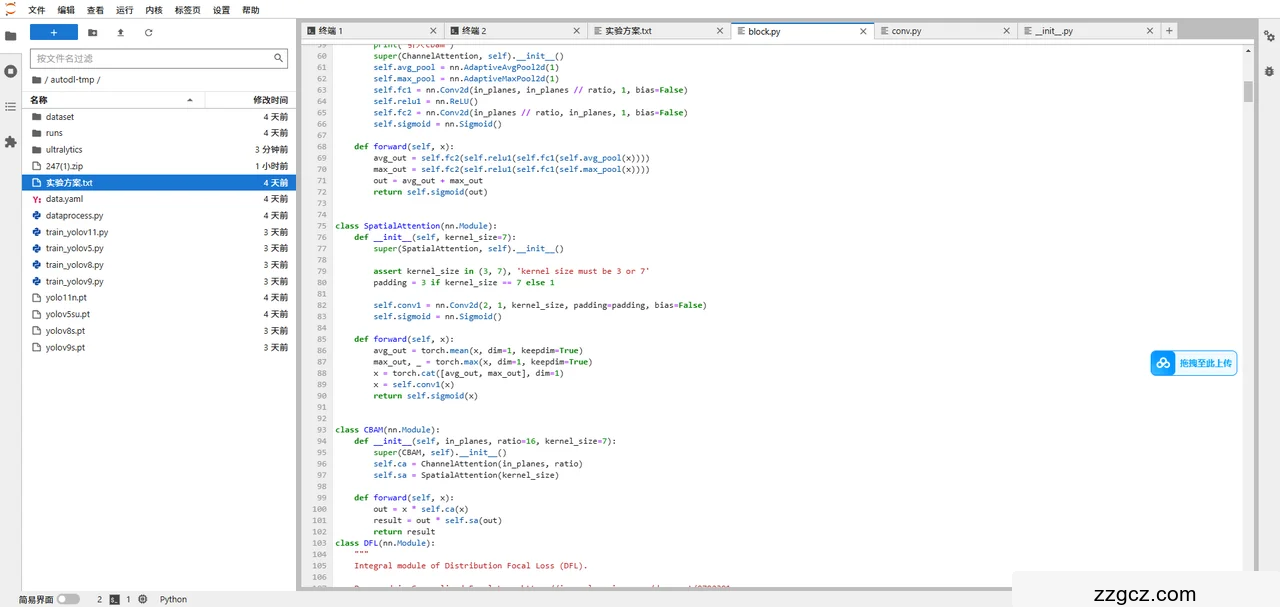
1)引入CBAM注意力机制:在主干网络中添加CBAM模块,增强模型对关键特征的关注,提高检测精度。
核心代码
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
"""Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet."""
def __init__(self, channels: int) -> None:
"""Initializes the class and sets the basic configurations and instance variables required."""
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Applies forward pass using activation on convolutions of the input, optionally using batch normalization."""
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
"""Spatial-attention module."""
def __init__(self, kernel_size=7):
"""Initialize Spatial-attention module with kernel size argument."""
super().__init__()
assert kernel_size in (3, 7), "kernel size must be 3 or 7"
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
"""Apply channel and spatial attention on input for feature recalibration."""
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
"""Convolutional Block Attention Module."""
def __init__(self, c1, kernel_size=7):
"""Initialize CBAM with given input channel (c1) and kernel size."""
super().__init__()
self.channel_attention = ChannelAttention(c1)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
"""Applies the forward pass through C1 module."""
return self.spatial_attention(self.channel_attention(x))
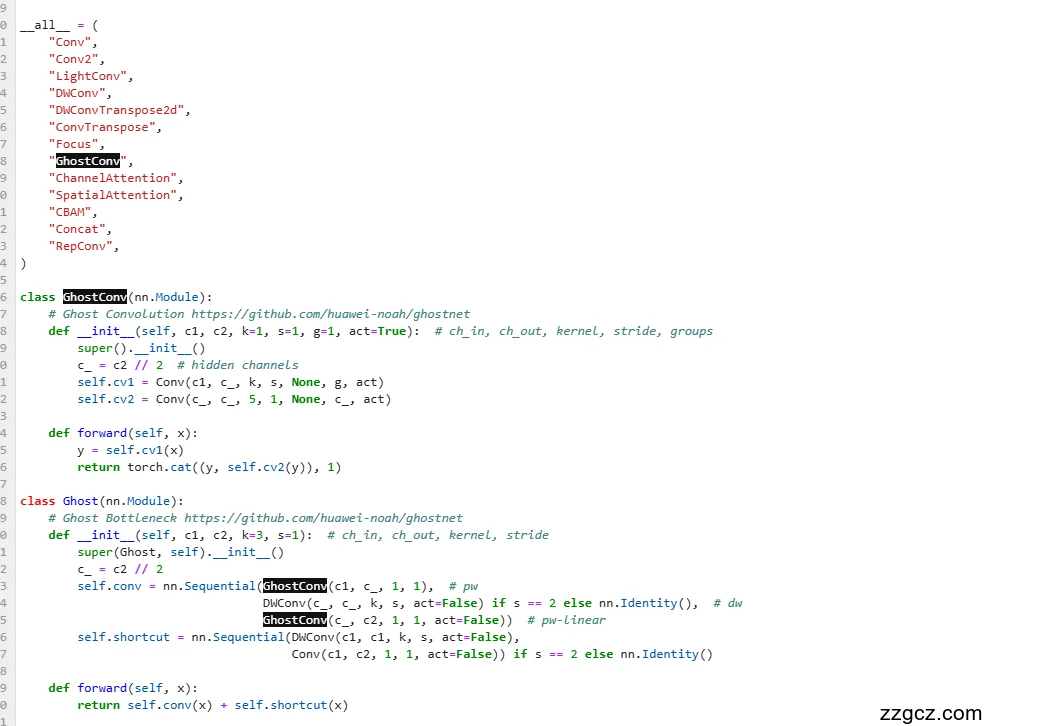
2)集成GhostNet:替换部分卷积层为Ghost模块,生成紧凑的“幽灵特征”,减少计算量,提高推理速度。
代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules.conv import Conv
import math
class GhostModule(nn.Module):
def __init__(self, c1, c2, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = c2
init_channels = math.ceil(c2 / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(c1, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
对比分析:比较不同YOLO版本及优化后的YOLOv11在准确性、速度和计算开销上的表现。
评价指标
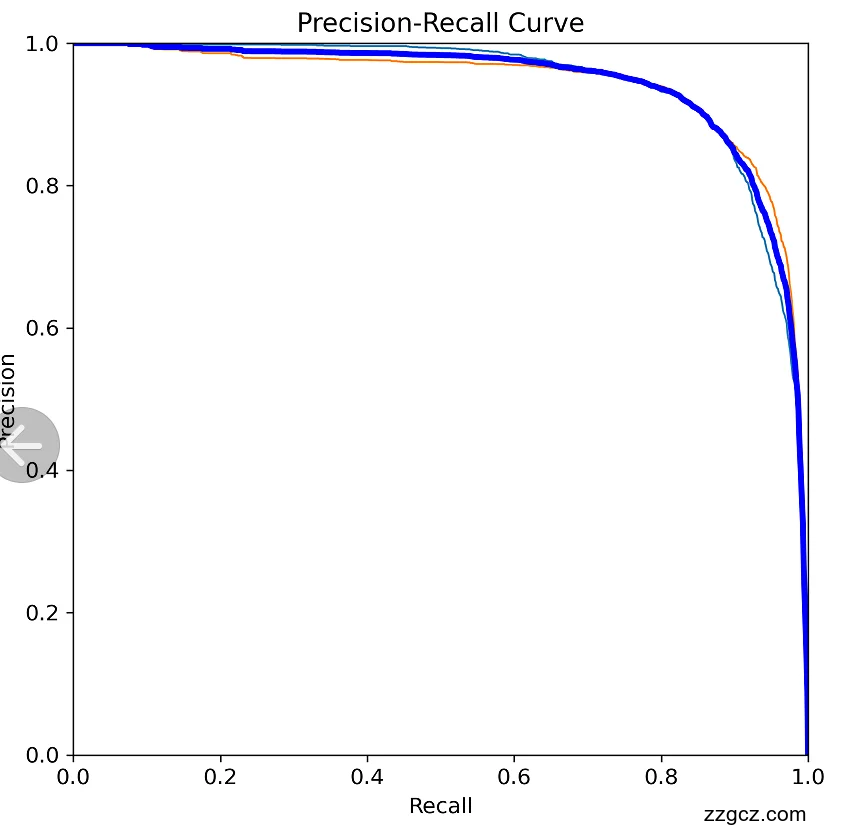
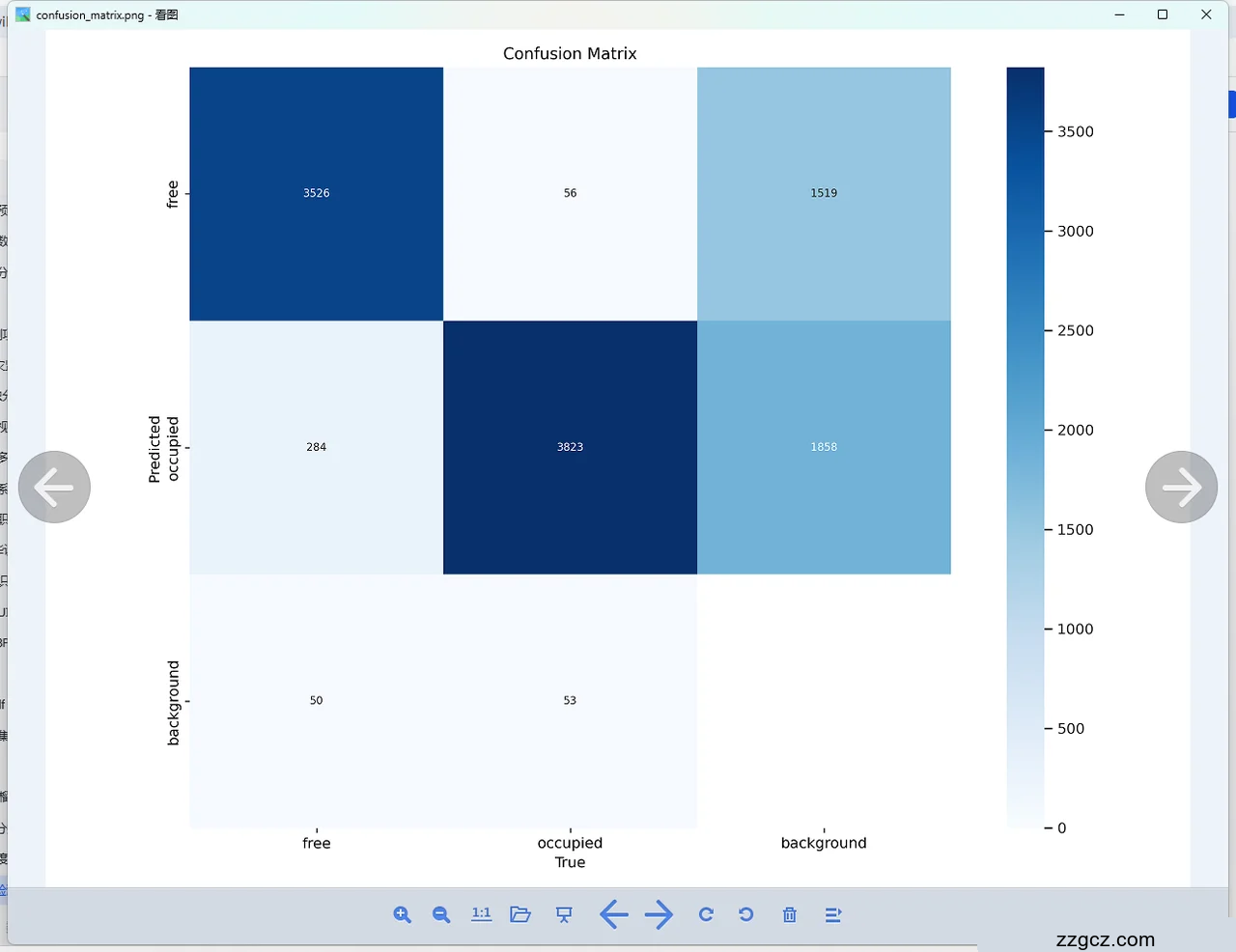
检测准确率:包括平均精度均值(mAP)、召回率、F1分数。
推理速度:每秒帧数(FPS)。
计算开销:模型参数量、浮点运算次数(FLOPs)。
实时性:是否满足≥30 FPS的实时检测要求。
模型修改点:
其他相关结果图片: