A285-LeNet-5模型实现手写数字识别实时画板手写预测
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
项目说明文档
概述
本项目由两个主要文件组成:huatu.py 和 train_lenet5_mnist.py。其中,train_lenet5_mnist.py 用于训练一个 LeNet-5 神经网络模型来识别手写数字,而 huatu.py 提供了一个图形化界面,允许用户在画布上手写数字并通过训练好的模型识别该数字。
文件一:train_lenet5_mnist.py
目标
该脚本用于训练 LeNet-5 模型来进行手写数字识别,数据来源于 MNIST 数据集。
关键组件
-
LeNet-5 模型定义
-
LeNet-5 是一个经典的卷积神经网络(CNN),用于处理手写数字识别任务。模型包含:
-
两个卷积层,分别通过 ReLU 激活函数与池化操作处理输入数据。
-
三个全连接层,其中最后一个全连接层的输出为 10 个类,对应数字 0 到 9。
-
-
数据预处理
-
输入图像经过调整大小(32x32)、转换为张量以及标准化处理,符合 LeNet-5 的输入要求。
-
训练过程
-
使用 MNIST 数据集的训练集进行模型训练,并使用 Adam 优化器和交叉熵损失函数。
-
每个 epoch 后,评估模型在测试集上的表现,并输出准确率。
-
训练过程中输出每 100 个批次的损失值,方便观察训练进展。
-
保存模型
-
在训练完成后,保存训练好的模型参数到文件
lenet5_mnist.pth,用于后续的推理任务。
文件二:huatu.py
目标
该脚本实现了一个图形化界面,允许用户通过手写数字进行绘制,并使用训练好的 LeNet-5 模型进行数字识别。
关键组件
-
LeNet-5 模型加载
-
在程序启动时,加载训练好的模型
lenet5_mnist.pth,以便用于推理任务。 -
图形界面
-
使用
Tkinter创建了一个简单的图形化界面,包括一个 200x200 像素的画布,用户可以在该画布上绘制手写数字。 -
用户绘制时,系统会在画布上显示黑色圆点模拟笔画。
-
提供了两个按钮:
识别按钮用于调用模型进行数字识别,清空按钮用于清空画布。 -
图像预处理
-
用户绘制的手写数字会被转换为灰度图像,反转颜色(从黑底白字转换为白底黑字),并进行大小调整至 32x32,符合 LeNet-5 模型的输入要求。
-
数字识别
-
使用加载的 LeNet-5 模型进行预测,输出预测的数字,并在界面上通过弹窗展示识别结果。
-
错误处理
-
如果加载模型失败,程序会弹出错误提示并退出。
依赖项
-
torch和torchvision:用于定义和训练 LeNet-5 模型,进行推理。 -
PIL(Python Imaging Library):用于处理图像的绘制和预处理。 -
Tkinter:用于创建图形化用户界面,处理用户输入。
总结
本项目实现了一个简单的手写数字识别应用,包括训练和推理两个部分。train_lenet5_mnist.py 通过训练 LeNet-5 网络来识别 MNIST 手写数字,而 huatu.py 提供了一个直观的界面,允许用户手绘数字并使用训练好的模型进行识别。此项目适用于初学者了解卷积神经网络(CNN)和 PyTorch 框架的使用,以及如何将机器学习模型部署到实际应用中。
《实验报告》
| 实践项目名称:使用Lenet-5模型实现手写数字识别 | |
|---|---|
| 姓 名: | 学 号: |
| 项目背景和目的:随着人工智能技术的快速发展,深度学习在计算机视觉领域取得了显著的成果,尤其是在图像识别任务中表现出色。手写数字识别作为计算机视觉的经典问题之一,具有广泛的应用场景,如邮政编码识别、银行支票处理、表单数据录入等。LeNet-5 是由 Yann LeCun 等人提出的经典卷积神经网络(CNN)结构,专门用于高效的手写数字识别,并在 MNIST 数据集上取得了优异的表现。本项目基于 PyTorch 框架,实现了 LeNet-5 模型的训练与部署,并结合图形化界面(GUI)构建了一个交互式手写数字识别系统。通过该应用,用户可以在画布上自由绘制数字,并实时获取模型的识别结果。这不仅有助于理解 CNN 的工作原理,还能直观地展示深度学习模型的实际应用效果。项目目的与意义技术实践与学习通过实现 LeNet-5 模型,深入理解卷积神经网络的结构及其在图像分类任务中的应用。掌握 PyTorch 框架的使用方法,包括数据加载、模型训练、评估与保存。学习如何将训练好的模型部署到实际应用中,并结合 GUI 提升用户体验。 应用价值提供一个直观的手写数字识别工具,可用于教育演示或简单的数字输入场景。为后续更复杂的图像识别任务(如手写汉字识别、物体检测等)奠定基础。教育与研究意义适合机器学习初学者了解 CNN 的基本原理和实现流程。可作为课程实验、毕业设计或科研项目的参考案例,帮助学习者快速上手深度学习项目开发。本项目的核心目标是构建一个端到端的手写数字识别系统,从模型训练到实际应用,完整展示深度学习项目的开发流程,同时为用户提供一个简单易用的交互工具。 | |
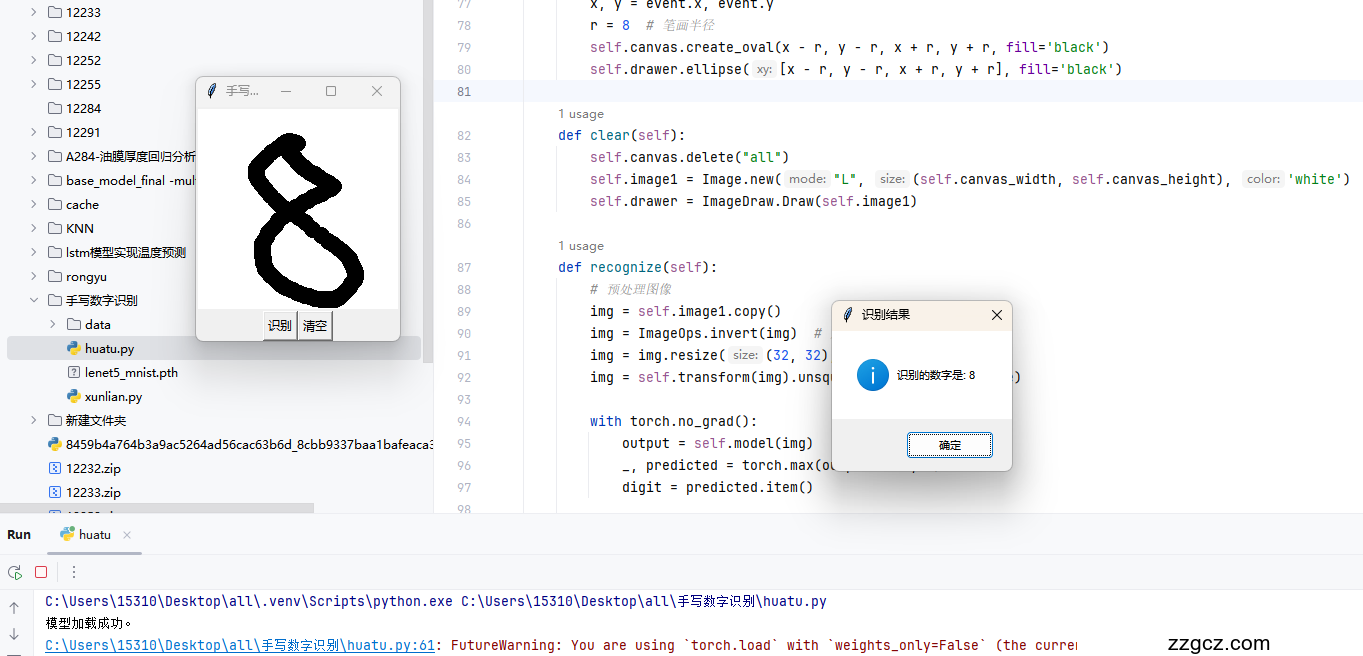
项目原理:LeNet-5 是由 Yann LeCun 在 1998 年提出的经典 CNN 结构,主要用于手写数字识别(MNIST 数据集)。其结构如下:核心特点:卷积层(Conv1, Conv2):提取局部特征(如边缘、角点)。池化层(MaxPool):降低计算量,增强平移不变性。全连接层(FC1, FC2, FC3):整合特征,输出分类概率。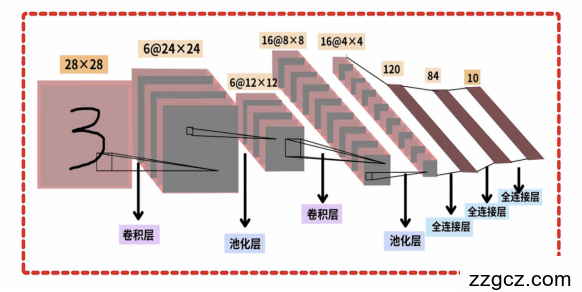 LeNet-5的卷积神经网络 LeNet-5的卷积神经网络 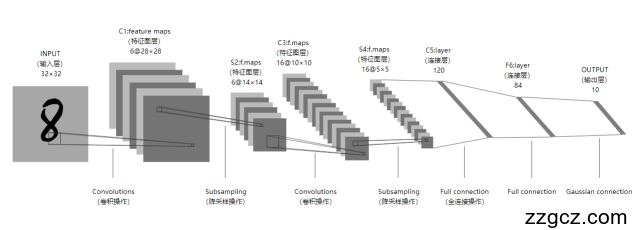 LeNet-5的网络结构相关算法介绍:1.卷积层是 CNN 的核心组成部分,通过卷积核(也称为滤波器)在输入数据上进行滑动卷积操作,提取数据的局部特征。2.池化层主要用于对特征图进行下采样,降低数据维度,减少计算量,同时在一定程度上增强模型的鲁棒性。3.全连接层将经过卷积和池化操作提取到的特征进行整合,并映射到输出空间。在全连接层中,每个神经元与上一层的所有神经元都有连接,通过权重矩阵和偏置项进行线性变换,再经过激活函数(如 Softmax 函数用于分类任务)得到最终的输出。 LeNet-5的网络结构相关算法介绍:1.卷积层是 CNN 的核心组成部分,通过卷积核(也称为滤波器)在输入数据上进行滑动卷积操作,提取数据的局部特征。2.池化层主要用于对特征图进行下采样,降低数据维度,减少计算量,同时在一定程度上增强模型的鲁棒性。3.全连接层将经过卷积和池化操作提取到的特征进行整合,并映射到输出空间。在全连接层中,每个神经元与上一层的所有神经元都有连接,通过权重矩阵和偏置项进行线性变换,再经过激活函数(如 Softmax 函数用于分类任务)得到最终的输出。 |
|
项目内容:本项目基于LeNet-5模型实现藏文手写数字识别任务,旨在验证经典卷积神经网络在藏文数字识别中的有效性,并通过优化模型结构和参数提升性能。以下是项目的详细内容:1.数据准备与预处理MNIST 数据集(6万训练 + 1万测试)调整图像尺寸至 32×32(LeNet-5 输入要求)归一化(像素值缩放到 [0,1])转换为 PyTorch Tensor2.模型构建本项目采用LeNet-5作为基础模型,其结构如下:模型结构图: 3.模型训练过程优化器:Adam(自适应学习率)损失函数:交叉熵损失(CrossEntropyLoss)训练策略:前向传播 → 计算损失 → 反向传播 → 更新权重每个 epoch 后计算测试集准确率模型保存:训练完成后保存为 lenet5_mnist.pth 3.模型训练过程优化器:Adam(自适应学习率)损失函数:交叉熵损失(CrossEntropyLoss)训练策略:前向传播 → 计算损失 → 反向传播 → 更新权重每个 epoch 后计算测试集准确率模型保存:训练完成后保存为 lenet5_mnist.pth 通过上述流程,本项目实现了对手写数字的高效识别,验证了LeNet-5模型在简单图像分类任务中的有效性。 通过上述流程,本项目实现了对手写数字的高效识别,验证了LeNet-5模型在简单图像分类任务中的有效性。 4.可视化结果使用Matplotlib绘制训练过程中的损失曲线和准确率曲线。可视化部分测试样本的预测结果,展示模型的分类效果。 3. 交互式识别(huatu.py)(1) 图形界面(Tkinter)画布(200×200 像素):用户鼠标绘制数字按钮: 识别 → 调用模型预测清空 → 重置画布 (2) 图像预处理获取画布图像(200×200 像素)转换为灰度图(PIL.Image → L 模式)反色处理(黑底白字 → 白底黑字,与 MNIST 一致)调整尺寸 → 32×32(匹配 LeNet-5 输入)归一化 & 张量转换 (3) 模型推理加载 lenet5_mnist.pth前向传播 → 输出 10 维概率向量取最大值 → 预测数字(0-9) 4.可视化结果使用Matplotlib绘制训练过程中的损失曲线和准确率曲线。可视化部分测试样本的预测结果,展示模型的分类效果。 3. 交互式识别(huatu.py)(1) 图形界面(Tkinter)画布(200×200 像素):用户鼠标绘制数字按钮: 识别 → 调用模型预测清空 → 重置画布 (2) 图像预处理获取画布图像(200×200 像素)转换为灰度图(PIL.Image → L 模式)反色处理(黑底白字 → 白底黑字,与 MNIST 一致)调整尺寸 → 32×32(匹配 LeNet-5 输入)归一化 & 张量转换 (3) 模型推理加载 lenet5_mnist.pth前向传播 → 输出 10 维概率向量取最大值 → 预测数字(0-9) |
|
实验结果与分析:1.实验环境·CPU:Intel Core i7-10750H·GPU:NVIDIA GeForce RTX 2060(用于加速训练)·内存:16GB·操作系统:Windows 11·深度学习框架:PyTorch 2.0 + CUDA 11.7·编程语言:Python 3.9·辅助工具:Matplotlib(可视化)、NumPy(数据处理)2.实验数据·训练集:8,884张(50%)·测试集:8,884张(50%)·图像归一化(像素值缩放到[0, 1])·尺寸统一调整为28×28像素·数据增强(随机旋转±10°,平移±2像素)3.评价指标·准确率(Accuracy):分类正确的样本占总样本的比例。·损失值(Loss):交叉熵损失,反映模型预测与真实标签的差异。·混淆矩阵:可视化各类别的分类情况,分析模型错误模式。 4.实验结果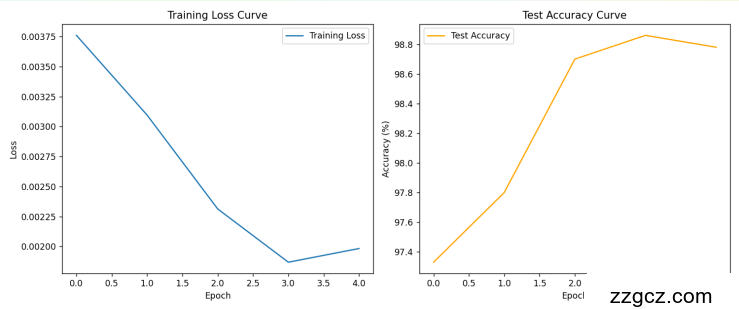 左侧图表:Training Loss Curve(训练损失曲线) 蓝色线条(Training Loss,训练损失):颜色特征: 以蓝色呈现,清晰绘制出训练损失随训练轮次(Epoch)变化的趋势。趋势解读:图中显示训练损失从初始值(大约0.0037)快速下降,前期的下降斜率较大,说明模型在训练初期对训练集数据的拟合能力迅速提升。随着训练轮次增加,下降速度逐渐放缓,在4轮训练后,训练损失进一步降低至接近0.002的水平,呈现出良好的收敛趋势。这种趋势表明模型在训练集上的损失持续减少,显示出良好的学习效果。 右侧图表:Test Accuracy Curve(测试准确率曲线) 橙色线条(Test Accuracy,测试准确率):颜色特征: 以橙色呈现,显著标识模型在测试集上的预测准确率变化趋势。趋势解读:测试准确率的初始值较高(约为97.4%),表明模型从一开始在测试集上已有一定预测能力。随着训练轮次增加,测试准确率迅速升高,在第3轮时达到峰值(约98.8%),凸显出模型对测试集数据的预测能力不断提升。在第3轮之后,准确率略微下降至98.6%左右,可能是由于数据分布的轻微波动或过度拟合的早期迹象。整体来看,模型在测试集上的准确率波动较小,仍旧维持在较高水平,说明模型在测试集上的表现具有稳定性和一定泛化能力。 左侧图表:Training Loss Curve(训练损失曲线) 蓝色线条(Training Loss,训练损失):颜色特征: 以蓝色呈现,清晰绘制出训练损失随训练轮次(Epoch)变化的趋势。趋势解读:图中显示训练损失从初始值(大约0.0037)快速下降,前期的下降斜率较大,说明模型在训练初期对训练集数据的拟合能力迅速提升。随着训练轮次增加,下降速度逐渐放缓,在4轮训练后,训练损失进一步降低至接近0.002的水平,呈现出良好的收敛趋势。这种趋势表明模型在训练集上的损失持续减少,显示出良好的学习效果。 右侧图表:Test Accuracy Curve(测试准确率曲线) 橙色线条(Test Accuracy,测试准确率):颜色特征: 以橙色呈现,显著标识模型在测试集上的预测准确率变化趋势。趋势解读:测试准确率的初始值较高(约为97.4%),表明模型从一开始在测试集上已有一定预测能力。随着训练轮次增加,测试准确率迅速升高,在第3轮时达到峰值(约98.8%),凸显出模型对测试集数据的预测能力不断提升。在第3轮之后,准确率略微下降至98.6%左右,可能是由于数据分布的轻微波动或过度拟合的早期迹象。整体来看,模型在测试集上的准确率波动较小,仍旧维持在较高水平,说明模型在测试集上的表现具有稳定性和一定泛化能力。 |
|
| 总结:从图表分析可以看出,模型的训练过程表现良好,且在训练和测试数据上的表现具有一定稳定性和泛化能力: 训练损失:训练损失在初期快速下降,并逐渐趋于平稳,最终稳定在较低水平,表明模型对训练集数据具有较好的拟合能力,且训练已基本收敛。 测试准确率:测试准确率从初始较高水平逐步提升,在模型训练达到一定程度后,准确率接近峰值并保持在较高的范围内,说明模型在测试集上的预测性能较为优秀。同时,尽管后期准确率略微下降,但整体变化幅度较小,表明泛化能力较为稳定。 总体来看,模型在训练集上的拟合效果和在测试集上的泛化表现均表现出色,未明显出现过拟合现象,但后续需要对提升泛化能力进行持续关注和优化。 | |
| 附件1 代码:import torchimport torch.nn as nnimport torch.optim as optimimport torch.nn.functional as Ffrom torchvision import datasets, transformsfrom torch.utils.data import DataLoader # 定义LeNet-5模型class LeNet5(nn.Module): def __init__(self): super(LeNet5, self).__init__() self.conv1 = nn.Conv2d(1, 6, kernel_size=5) # 输入通道1,输出通道6,卷积核大小5x5 self.pool = nn.AvgPool2d(2, 2) # 平均池化,窗口2x2 self.conv2 = nn.Conv2d(6, 16, kernel_size=5) # 输入通道6,输出通道16,卷积核大小5x5 self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层1,修正输入维度 self.fc2 = nn.Linear(120, 84) # 全连接层2 self.fc3 = nn.Linear(84, 10) # 输出层 def forward(self, x): x = self.pool(F.relu(self.conv1(x))) # 卷积1 -> ReLU -> 池化 x = self.pool(F.relu(self.conv2(x))) # 卷积2 -> ReLU -> 池化 x = x.view(-1, 16 * 5 * 5) # 展平特征图,修正展平维度 x = F.relu(self.fc1(x)) # 全连接1 -> ReLU x = F.relu(self.fc2(x)) # 全连接2 -> ReLU x = self.fc3(x) # 输出层 return x def train(): # 设置设备 device = torch.device("cuda" if torch.cuda.is_available() else "cpu") print(f"使用设备: {device}") # 数据预处理 transform = transforms.Compose([ transforms.Resize((32, 32)), # LeNet-5 输入尺寸是32x32 transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,)) ]) # 加载训练和测试数据 train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform) test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform) train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=1000, shuffle=False) # 初始化模型、损失函数和优化器 model = LeNet5().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(model.parameters(), lr=0.001) # 训练模型 epochs = 30 for epoch in range(1, epochs + 1): model.train() running_loss = 0.0 for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() outputs = model(data) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 100 == 99: print(f"Epoch [{epoch}/{epochs}], Step [{batch_idx +1}/{len(train_loader)}], Loss: {running_loss / 100:.4f}") running_loss = 0.0 # 在测试集上验证 model.eval() correct = 0 total = 0 with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) outputs = model(data) _, predicted = torch.max(outputs.data, 1) total += target.size(0) correct += (predicted == target).sum().item() print(f"Epoch [{epoch}/{epochs}] 测试集准确率: {100 * correct / total:.2f}%") # 保存模型 torch.save(model.state_dict(), 'lenet5_mnist.pth') print("模型已保存为 lenet5_mnist.pth") if __name__ == "__main__": train()# huatu.py '''pip install pillow==9.1.0 torchvision== 0.19.1''' import torchimport torch.nn as nnfrom torchvision import transformsfrom PIL import Image, ImageDraw, ImageOpsimport tkinter as tkfrom tkinter import messagebox # 定义LeNet-5模型(与训练时一致)class LeNet5(nn.Module): def __init__(self): super(LeNet5, self).__init__() self.conv1 = nn.Conv2d(1, 6, kernel_size=5) self.pool = nn.AvgPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, kernel_size=5) self.fc1 = nn.Linear(16 * 5 * 5, 120) # 修正输入维度为16*5*5=400 self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(torch.relu(self.conv1(x))) x = self.pool(torch.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) # 修正展平特征图维度 x = torch.relu(self.fc1(x)) x = torch.relu(self.fc2(x)) x = self.fc3(x) return x class App: def __init__(self, master): self.master = master master.title("手写数字识别") self.canvas_width = 200 self.canvas_height = 200 self.canvas = tk.Canvas(master, width=self.canvas_width, height=self.canvas_height, bg='white') self.canvas.pack() self.button_frame = tk.Frame(master) self.button_frame.pack() self.recognize_button = tk.Button(self.button_frame, text="识别", command=self.recognize) self.recognize_button.pack(side=tk.LEFT) self.clear_button = tk.Button(self.button_frame, text="清空", command=self.clear) self.clear_button.pack(side=tk.LEFT) # 绑定鼠标事件 self.canvas.bind("\ |