A307-基于深度学习的汉蒙翻译系统
导出时间:2025/11/26 14:32:07
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
注:此html可能格式或图片显示不全,请购买后查看docx文档
- 课题来源及研究的目的和意义
1.课题来源
王斯日古楞教授提供。
2.研究目的和意义
在当今这个信息爆炸的时代,语言作为沟通的桥梁,其重要性不言而喻。机器翻译技术,尤其是基于深度学习的神经网络机器翻译,已经成为连接不同语言和文化的强有力工具。随着技术的不断进步,机器翻译正逐渐从辅助工具转变为主流的信息传递方式。其翻译速度和质量的提升,正在逐步满足现代社会对即时、高效翻译的需求。蒙古语作为内蒙古自治区和蒙古国的官方语言,具有跨国、跨地区的特点,是连接不同民族和文化的纽带。深度学习技术的进步,尤其是在构建基于神经网络的机器翻译模型方面,已经显著提升了翻译的准确性和流畅性。这些模型强大的学习能力减少了对大量标注语料的依赖。此外,深度学习在自然语言处理领域的广泛应用也证明了其在处理语言复杂性和多样性方面的优势。
随着全球化的不断深化,不同语言之间的沟通障碍成为了人们交流的主要阻碍之一。对于使用蒙语的地区来说蒙汉神经机器翻译系统的研究显得尤为重要。它不仅能够加强汉族与蒙古族之间的交流沟通,促进民族文化的传播和发展,还能够在现代化进程中保护和传承蒙古族文化,维护民族团结进步。蒙汉机器翻译系统的研究,对于其他低资源语言的翻译工作也具有一定的推动作用,能够为这些语言的翻译提供借鉴和经验。基于深度学习的汉蒙神经机器翻译系统通过结合深度学习技术大大提高了翻译质量和效率。该系统的研究不仅能提升翻译质量与效率,还能在文化传承、民族团结和教育辅助等方面发挥关键作用。这一研究的发展有助于消除语言障碍,增进不同民族的相互理解与尊重,对社会的全面进步具有重要价值。
二. 国内外在该方向的研究现状及分析
在国内,汉蒙机器翻译领域的研究呈现出蓬勃发展的态势。众多高校的语言学、计算机科学等专业的科研团队以及专门的语言技术研究机构积极投身于这一领域的探索。从技术路径来看,传统的基于规则的汉蒙机器翻译[1]方法在早期发挥了重要作用,研究人员通过深入分析汉蒙两种语言的语法结构、词汇特点等,构建了较为精细的翻译规则体系,为后续研究奠定了基础。随着统计机器翻译技术的兴起,大规模汉蒙双语语料库的建设[2]成为关键。通过对语料的统计分析,提取语言模式和翻译概率,显著提高了翻译的准确性和效率。国内学者开始尝试使用统计模型来进行汉蒙翻译[3]。例如,内蒙古大学的李等人[4]利用Transformer来对蒙汉机器翻译进行研究,并取得了初步成果。深度学习技术在汉蒙机器翻译中展现出强大的优势。深度神经网络能够自动学习语言的深层次特征和语义表示,有效克服了传统方法的局限性。基于神经网络的机器翻译(Neural Machine Translation, NMT)逐渐成为主流方法。内蒙古师范大学的一项研究表明[5][6],采用层次短语的翻译模型结合后处理技术可以在一定程度上改善汉蒙翻译的质量。
国际上,汉蒙机器翻译的研究相对较少,但也有一些学者和机构关注到多语言翻译中的汉蒙翻译问题。国际知名的机器翻译研究团队[7]在进行大规模多语言翻译系统开发时,会将汉蒙语言对纳入其中,不过通常不是重点研究对象。国际上的一些语言技术会议和学术期刊上也偶尔会出现关于汉蒙机器翻译的研究成果交流[8]。随着NMT技术的发展,其在译后编辑中的应用成为研究热点,显示出NMT在提高翻译效率方面的潜力。例如,Naveen 等人[9]探索了基于实例的机器翻译方法在汉蒙翻译中的应用。这种方法通过对大量实例的学习和分析,找到与输入文本相似的实例,并根据实例的翻译结果进行翻译。此外,Ren 等人[10]的研究证明了基于 LSTM 的模型能够有效捕捉蒙古语的语义信息。他们通过引入局部注意力机制,进一步提高了翻译的准确性。这种注意力机制能够让模型更加关注文本中的关键信息,从而更好地理解和翻译语言。
- 主要研究内容
该毕业设计项目旨在开发一个包含前端简洁界面和后端深度学习模型的汉蒙翻译系统,通过需求分析、数据处理、技术选型、模型训练及系统集成等步骤,最终实现正确的翻译功能。
1. 系统前端
在系统前端方面,汉蒙神经机器翻译系统需要构建一个用户友好的界面,允许用户输入源语言文本,并展示翻译结果。前端设计需要考虑以下要点:
用户界面设计:简洁直观的用户界面,支持文本输入和结果显示。
交互功能:提供清晰的输入指示和翻译按钮,以及复制和分享翻译结果的功能。
2. 系统后端
系统后端主要负责处理用户请求,与深度学习模型交互,并返回翻译结果。后端的关键技术点包括:
请求处理:确保接口能够处理HTTP请求和响应,包括POST请求发送文本数据和GET请求检索翻译结果,使得前端可以与后端服务进行通信,进行必要的预处理。
模型交互:与深度学习模型进行交互,发送请求并接收翻译结果。
数据存储和管理:存储用户翻译记录和账户信息,提供数据备份。
3. 深度学习
深度学习是汉蒙神经机器翻译系统的核心,涉及到模型的训练、优化和部署。主要研究内容包括:
对汉蒙平行语料进行简单的预处理,包括去除重复句对、语言错误句等。
基于Transformer的神经机器翻译模型架构,包括编码器、解码器和注意力机制。
训练Transformer模型,使用汉蒙语料库进行端到端训练,以生成高质量的翻译结果。
- 研究方案
该系统开发计划概述了从前端界面设计到后端开发及汉蒙翻译模型训练的全过程,以确保用户可以方便地输入汉文文本并获得相应的蒙古语翻译结果。
| 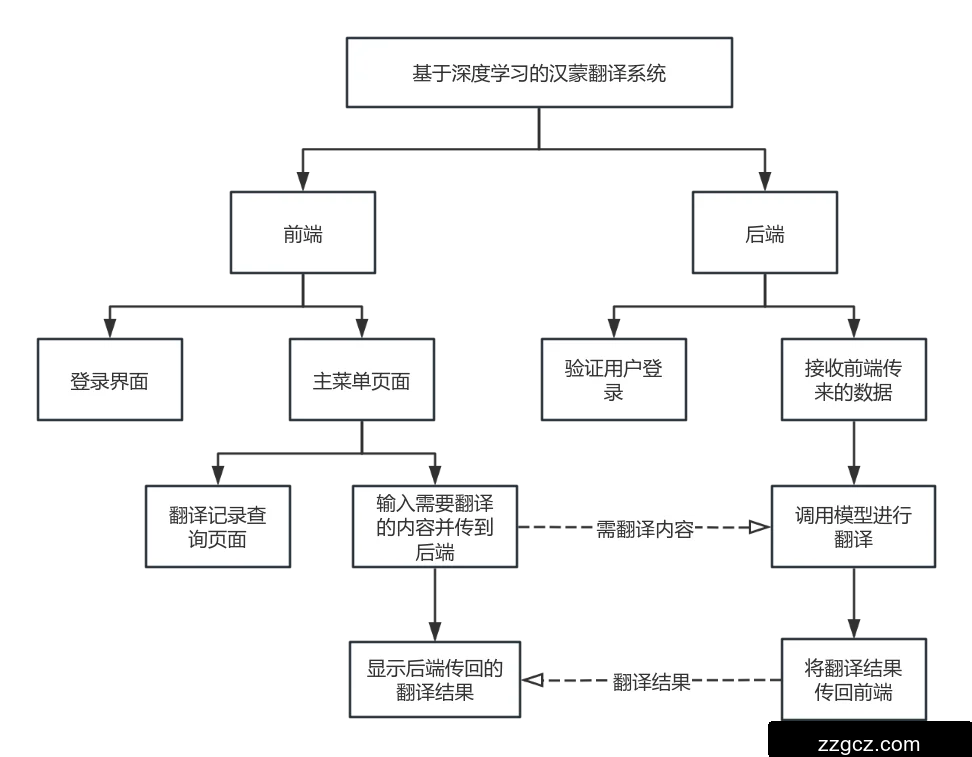 |
图1 翻译系统功能图
1、前端界面设计:
设计用户友好的界面,允许用户输汉语文本。
实现界面功能,支持用户输入的汉语文本发送到后端进行翻译。
设计界面以显示翻译后的蒙语文本,并提供一个按钮或自动流程将汉语文本发送到后端进行下一步翻译。
显示最终翻译的蒙语文本,并确保文本清晰可读。
2、后端开发:
选择适合高并发处理的后端框架,如Spring Boot或Django等。选择合适的数据库系统(如MySQL、MongoDB等)并设计数据模型,以存储用户信息、翻译记录等。
实现HTTP接口,包括POST接口用于接收翻译请求,GET接口用于检索翻译结果。设计错误处理机制,返回规范的错误信息给前端。
实现与深度学习模型的接口调用,包括请求发送和结果接收。对接收到的翻译结果进行后处理,如格式化和编码转换。
3、汉蒙翻译模型:
预处理汉蒙平行语料库,包括分词、去除停用词、标准化等。
基于Transformer的神经机器翻译模型架构,包括编码器、解码器和注意力机制。
训练Transformer模型,使用汉蒙语料库进行端到端训练,以生成高质量的翻译结果。
将训练好的汉蒙翻译模型集成到后端服务中。
进行系统级测试,确保前端、后端和翻译模型之间的无缝集成。
测试系统在不同设备和浏览器上的兼容性和响应性。
- 进度安排,预期达到的目标
起讫时间
| 各工作阶段的要求
| 检查方式
| 检查情况
|
2024.09.10-2024.10.20
| 进行需求分析与设计
| 答辩
| |
2024.10.20-2024.12.20
| 进行初步的框架和基础功能的编写
| ||
2024.12.20-2025.01.20
| 完善系统
| ||
2025.01.20-2025.02.20
| 中期检查,毕业设计
| ||
2025.02.20-2025.04.20
| 最后测试、撰写论文
| ||
2025.04.20-2025.05.10
| 完善毕业论文,准备毕业论文答辩
|
- 课题已具备和所需的条件、经费
对相关文献进行阅读和学习,对简单的Transformer模型进行运行并进行训练,进行初步的前端搭建。
专业知识与团队:教师和研究生提供专业知识和实践指导。
技术资源:开源的系统和老师提供数据库及文献资源。
实验设备与场地:教师提供了实验场地,并并定期进行指导。
- 研究过程中可能遇到的困难和问题,解决的措施
问题:
- 用户界面设计需满足不同用户需求和习惯,同时避免过于复杂或缺乏高级功能。
- 前端需兼容不同操作系统、浏览器和设备,可能出现显示异常和功能失效问题。
- 处理长序列时可能面临计算效率下降和内存不足问题。
解决方法:
- 进行用户需求调研,设计简洁明了的界面并为专业用户提供高级功能,提供操作指引。
- 进行广泛兼容性测试,针对不同环境优化,采用响应式设计。
- 采用分段处理长序列或改进模型结构提高处理能力。
- 主要参考文献
[1]乌丹牧其尔.统计与规则相结合的蒙汉机器翻译研究[D].内蒙古师范大学,2017.
[2]何乌云.基于神经网络的蒙古文词切分方法及其应用[D].内蒙古师范大学,2022.DOI:10.27230/d.cnki.gnmsu.2022.001031.
[3]孙晓骞,苏依拉,赵亚平,等.基于编码器-解码器重构框架的蒙汉神经机器翻译[J].计算机应用与软件,2020,37(04):150-155+163.
[4]李浩然.基于Transformer的篇章级汉蒙机器翻译研究[D].内蒙古大学,2022.DOI:10.27224/d.cnki.gnmdu.2022.001017.
[5]王春荣.基于层次短语的汉蒙统计机器翻译后处理研究[D].内蒙古师范大学,2013.
[6]陈美兰.基于实体泛化策略的蒙汉神经机器翻译研究[D].内蒙古师范大学,2023.DOI:10.27230/d.cnki.gnmsu.2023.000776.
[7]WANG C ,WANG S ,BAO M , et al.The research on automatic translation Chinese-Mongolian numerals[C]//IEEE Beijing Section,China,Hunan University of Humanities,Science and Technology,China.Proceedings of 2012 IEEE International Conference on Computer Science and Automation Engineering(CSAE 2012) VOL01.[出版者不详],2012:5.
[8]WANG C ,WANG S ,BAO M , et al.The research on automatic translation Chinese-Mongolian numerals[C]//IEEE Beijing Section,China,Hunan University of Humanities,Science and Technology,China.Proceedings of 2012 IEEE International Conference on Computer Science and Automation Engineering(CSAE 2012) VOL01.[出版者不详],2012:5.
[9]Naveen P ,Trojovský P .Overview and challenges of machine translation for contextually appropriate translations[J].iScience,2024,27(10):110878-110878.
[10]Qing-dao-er-ji R ,Su L Y ,Liu W W .Research on the LSTM Mongolian and Chinese machine translation based on morpheme encoding[J].Neural Computing and Applications,2020,32(5):41-49.