A310-基于YOLO的瑶湾水利风景区行人检测系统带论文
导出时间:2025/11/26 14:33:06
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
基于YOLO的瑶湾水利风景区行人检测系统
注:此html可能格式或图片显示不全,请购买后查看docx文档
摘要
本研究针对瑶湾水利风景区安全管理需求,开发了一套基于YOLOv5算法的行人检测系统,旨在通过实时监测游客活动,提升景区安全管理水平并优化游客体验。系统采用模块化设计,结合Qt框架开发的用户界面,实现了实时视频流检测、图片与视频上传检测、数据管理和可视化等功能。研究中对YOLOv5模型进行了定制化优化,包括输入分辨率调整、锚框配置优化和特征融合增强,使其适应景区复杂环境。经测试,系统在单路视频流下平均帧率达到28 FPS,检测精度(mAP@0.5)为0.91,查准率为0.93,查全率为0.89,表现出良好的实时性和稳定性。然而,系统在低光照条件下的检测性能、多路视频流处理能力和复杂背景下的误检问题仍需改进。未来研究将聚焦于算法优化、功能扩展和跨领域应用探索,以进一步提升系统的性能和应用价值,为智慧景区建设和公共安全领域提供技术支持。
关键词:YOLOv5,行人检测,Qt框架
Abstract
This study, targeting the safety management needs of the Yaowan Water Conservancy Scenic Area, has developed a pedestrian detection system based on the YOLOv5 algorithm. The aim is to enhance the safety management level of the scenic area and optimize the visitor experience by real-time monitoring of tourist activities. The system employs a modular design and a user interface developed with the Qt framework, realizing functions such as real-time video stream detection, image and video upload detection, data management, and visualization. The YOLOv5 model was customized and optimized in this study, including adjustments to input resolution, optimization of anchor box configuration, and enhanced feature fusion, to adapt to the complex environment of the scenic area. Tests have shown that the system achieves an average frame rate of 28 FPS in single video stream detection, with a detection accuracy (mAP@0.5) of 0.91, precision of 0.93, and recall of 0.89, demonstrating good real-time performance and stability. However, improvements are still needed in the system's detection performance under low-light conditions, its ability to process multiple video streams, and its false detection rate in complex backgrounds. Future research will focus on algorithm optimization, functional expansion, and exploration of cross-domain applications to further enhance the system's performance and application value, providing technical support for the construction of smart scenic areas and public safety fields.
Keywords: YOLOv5, Pedestrian Detection, Qt Framework
目录
基于YOLO的瑶湾水利风景区行人检测系统1
第一章 绪论2
1.1 研究背景与意义2
1.2 国内外研究现状2
1.3 研究内容与目标3
1.4 论文结构安排4
第二章 相关理论与技术基础4
2.1 YOLO算法原理4
2.2 行人检测技术7
2.3 Qt界面开发技术8
第三章 系统设计与实现11
3.1 系统总体架构11
3.2 系统功能设计11
3.3 系统实现技术12
3.4 系统工作流程12
6. 用户交互:用户通过界面控制视频播放或查询历史数据。13
3.5 系统优化与测试13
第四章 行人检测算法研究与实现13
4.1 数据集准备与预处理13
4.2 YOLO模型选择与改进14
4.3 模型训练与优化15
4.4 实时检测实现16
第五章 系统实现与集成16
5.1 Qt界面开发16
5.3 数据可视化17
5.4 系统集成与部署18
第六章 系统测试与评估18
6.1 测试方案设计19
6.2 功能测试19
6.3 性能测试20
6.4 用户体验测试21
6.5 测试结果分析与改进22
第七章 结论与展望23
7.1 研究总结23
7.2 存在的问题与不足24
7.3 未来研究方向24
总结25
致谢25
第一章 绪论
1.1 研究背景与意义
1.1.1 水利风景区安全管理的需求
瑶湾水利风景区是一处融合自然风光与人文景观的旅游胜地,凭借其独特的地理环境和丰富的旅游资源,每年吸引大量游客前来游览。然而,随着游客数量的持续增长,景区的安全管理工作面临严峻挑战。例如,游客在游览过程中可能发生意外跌倒、迷路或因违规行为导致的安全事故,这些不仅影响游客的游览体验,还可能对景区声誉造成负面影响。此外,游客的流动规律和密度分布对景区服务设施的规划与资源调配提出了更高要求。传统的安全管理手段,如人工巡查和静态监控,已难以满足实时性与全面性的需求。因此,开发一套基于行人检测技术的智能监控系统,实时监测游客活动情况,成为提升景区安全管理水平、优化游客体验的重要途径。
1.1.2 计算机视觉在智能监控中的应用现状
近年来,计算机视觉技术在智能监控领域的应用日益广泛,尤其在目标检测、行为识别和场景分析等方面展现出显著优势。传统监控系统主要依赖人工监视,存在效率低、易出错、响应滞后等问题。而基于计算机视觉的智能监控系统通过自动分析视频流,能够实时检测和识别目标,大幅提升了监控效率和准确性。在行人检测领域,深度学习技术的引入推动了技术革新,尤其是卷积神经网络(CNN)的应用,使检测精度和处理速度得到了显著提升。这种技术进步为智慧景区的建设提供了强有力的支持,使得实时游客监测成为可能。
1.1.3 YOLO算法在目标检测中的优势
YOLO(You Only Look Once)算法是一种先进的目标检测算法,以其高效、实时的检测性能在众多应用场景中表现出色。与传统的两阶段检测算法(如Faster R-CNN)不同,YOLO采用单阶段检测策略,将目标检测任务转化为回归问题,通过一次前向传播即可同时预测目标位置和类别。这种设计显著降低了计算复杂度,使得YOLO在保证高精度的同时具备快速检测能力,特别适用于对实时性要求较高的场景,如视频监控中的行人检测。因此,本研究选择YOLO算法作为核心技术,以满足瑶湾水利风景区对检测实时性和准确性的双重需求。
1.2 国内外研究现状
1.2.1 行人检测技术的发展历程
行人检测技术的发展经历了从传统方法到深度学习的演变。早期研究主要采用基于手工特征的检测方法,例如结合HOG(Histogram of Oriented Gradients)特征和SVM(Support Vector Machine)分类器进行行人识别。然而,这类方法在复杂背景下的检测精度有限,且对光照变化、行人姿态变化等因素较为敏感。随着深度学习技术的兴起,基于卷积神经网络的行人检测方法逐渐占据主导地位。例如,R-CNN系列算法(包括Fast R-CNN和Faster R-CNN)通过引入区域提议网络(RPN),显著提高了检测的精度和速度,成为行人检测领域的重要里程碑。
1.2.2 YOLO算法的演进与应用
YOLO算法自2016年首次提出以来,经过多个版本的迭代与优化,已成为目标检测领域的代表性技术。YOLOv1通过创新的单阶段检测思想,实现了实时目标检测的突破。随后,YOLOv2引入了Darknet网络和anchor boxes机制,提升了检测精度;YOLOv3通过多尺度特征融合进一步增强了模型性能。近年来,YOLOv4、YOLOv5和YOLOv8在网络结构设计、特征提取和训练策略等方面持续改进,使其在多个公开数据集(如COCO、VOC)上取得了优异表现。YOLO算法不仅在通用目标检测中表现出色,还被广泛应用于行人检测、车辆识别、工业缺陷检测等特定场景,展现了其强大的适应性。
1.2.3 智慧景区中的行人检测应用
在智慧景区建设中,行人检测技术已逐步应用于游客流量监测、安全预警和行为分析等领域。国内外一些知名景区,如中国的黄山、九寨沟,以及国外的优胜美地国家公园,纷纷引入基于深度学习的行人检测系统,以提升管理效率。然而,现有系统多采用通用行人检测模型,未能充分考虑景区环境的特殊性,例如光照变化、背景复杂性、游客密集度等,导致检测效果在特定场景下不理想。因此,针对特定景区优化行人检测算法,不仅具有重要的研究价值,还能为智慧景区建设提供更具针对性的技术支持。
1.3 研究内容与目标
1.3.1 研究内容概述
本研究围绕瑶湾水利风景区行人检测系统的开发与应用展开,主要内容包括以下三个方面:
- 行人检测算法研究:深入分析YOLO算法的原理与网络结构,结合瑶湾水利风景区的监控视频特点,优化算法参数和模型结构,以提高检测精度和实时性。
- 系统开发与集成:基于Qt框架开发用户界面,支持实时视频流检测、图片与视频上传检测等功能;利用ruoyi框架构建后台数据管理模块,实现数据的录入、查询、修改、删除及可视化展示。
- 数据可视化设计:设计直观的数据展示页面,通过图表形式呈现行人检测结果和历史数据分析,便于景区管理人员实时掌握游客动态和流量趋势。
1.3.2 研究目标与预期成果
本研究旨在实现以下目标:
- 提升景区安全管理水平:通过实时监测游客活动,及时发现潜在安全隐患并采取应对措施,保障游客人身安全。
- 优化景区服务与体验:基于游客流动数据的分析,为景区资源调配和服务设施优化提供科学依据,从而提升游客满意度。
- 推动技术创新与应用拓展:探索YOLO算法在水利风景区行人检测中的适用性,为智慧景区建设提供技术参考,并为其他相关领域的应用提供借鉴。
1.4 论文结构安排
本文共分为七章,各章内容安排如下:
- 第一章 绪论:阐述研究背景、意义、国内外研究现状及论文结构。
- 第二章 相关理论与技术基础:介绍YOLO算法原理、行人检测技术、Qt界面开发及相关技术基础。
- 第三章 系统需求分析与设计:分析系统功能需求,设计系统架构、数据库结构及用户界面布局。
- 第四章 行人检测算法研究与实现:详述数据集准备、YOLO模型的选择与优化、训练过程及实时检测实现。
- 第五章 系统实现与集成:介绍Qt界面开发、后台数据管理模块、数据可视化功能及系统集成过程。
- 第六章 系统测试与评估:设计测试方案,评估系统的功能性、性能及用户体验。
- 第七章 结论与展望:总结研究成果,分析存在不足,提出未来研究方向。
第二章 相关理论与技术基础
2.1 YOLO算法原理
2.1.1 YOLO算法的基本思想
YOLO(You Only Look Once)算法是一种高效的目标检测方法,其核心思想是将目标检测任务转化为一个端到端的回归问题。传统的目标检测算法(如R-CNN系列)通常分为区域提议和分类两个阶段,导致计算复杂度高、速度慢。而YOLO通过一次前向传播即可同时预测目标的边界框位置和类别概率,显著提升了检测速度。YOLO将输入图像划分为 S×S S \times S S×S 的网格,每个网格负责检测其中心点落入该网格的目标,并预测边界框坐标、置信度和类别概率。其基本流程可以概括为:输入图像 → 网格划分 → 特征提取 → 预测输出。
YOLO的置信度定义为:
其中,P(Object) 表示目标存在的概率,是预测边界框与真实边界框的交并比(Intersection over Union)。如果网格中没有目标,则 P(Object)=0 ;否则,置信度反映预测框的准确性。
这种单阶段检测策略使YOLO非常适合实时性要求高的场景,例如视频监控中的行人检测。
2.1.2 YOLO网络结构分析
本研究选用YOLOv5作为行人检测的核心算法。YOLOv5的网络结构分为三个主要部分:Backbone(骨干网络)、Neck(特征融合层)和Head(检测头)。
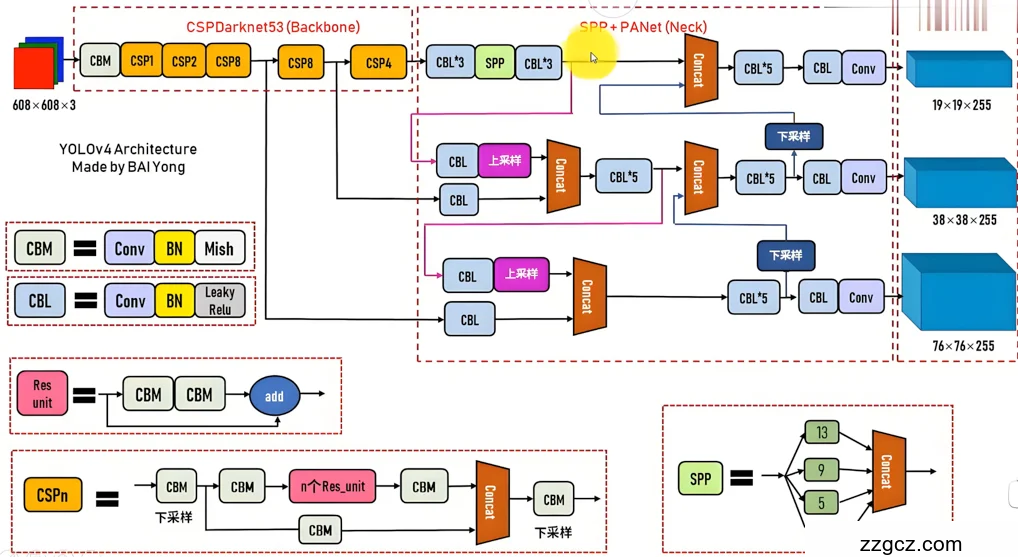
- Backbone:YOLOv5采用CSPDarknet53作为特征提取网络。CSP(Cross Stage Partial)结构通过将特征图分为两部分分别处理,既保留了深层网络的特征提取能力,又降低了计算复杂度。其基本卷积操作可以表示为:
其中,Fin 是输入特征图,W 和 b 分别是卷积核权重和偏置,∗ 表示卷积操作。
- Neck:使用PANet(Path Aggregation Network)进行多尺度特征融合。PANet通过自底向上和自顶向下的路径聚合不同层次的特征,提升了模型对小目标(如远处的行人)和大目标的检测能力。其特征融合过程可以表示为:
其中,Fdeep 和 Fshallow 分别是深层和浅层特征图,Upsample 和 Downsample 表示上采样和下采样操作。
- Head:包含多个检测头,分别输出不同尺度的预测结果。每个检测头预测的输出包括边界框坐标 (x,y,w,h) 、置信度和类别概率。输出张量形状为 (S,S,B×(5+C)),其中 B 是每个网格预测的边界框数量,C 是类别数。
YOLOv5在速度和精度之间取得了良好的平衡,其轻量化版本(如YOLOv5s)特别适合在资源受限的设备上部署。
2.1.3 YOLO的训练与推理过程
YOLOv5的训练过程包括数据增强、损失函数计算和参数优化:
- 数据增强:采用Mosaic增强,通过随机裁剪和拼接四张图像生成新样本,增强模型对复杂场景的适应性。
- 损失函数:总损失由三部分组成:
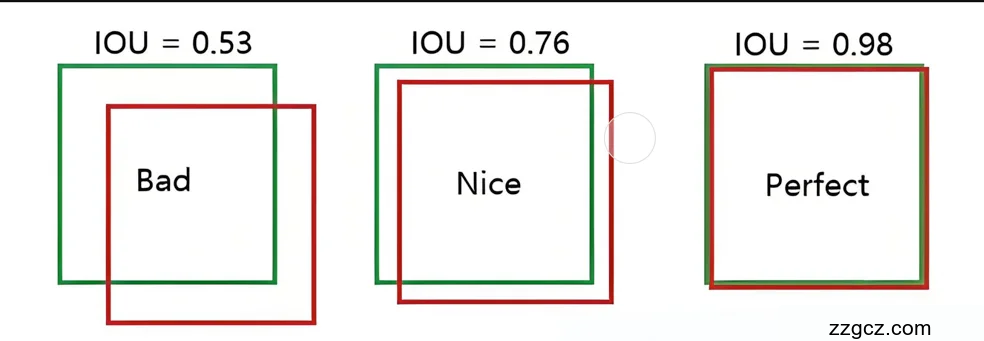
- Lbox:边界框回归损失,使用CIOU Loss:
其中,IOU 是交并比,ρ 是预测框中心与真实框中心的欧几里得距离,c 是包含两框的最小外接矩形对角线长度,v 衡量宽高比一致性,α 是权重参数。
- Lobj :置信度,使用二元交叉熵(BCE)计算。
- Lcls:分类损失,同样使用BCE。
- 优化器:采用Adam优化器,通过梯度下降更新网络参数:
其中,θ 是模型参数,η 是学习率,∇L 是损失函数的梯度。
在推理阶段,YOLOv5通过非极大值抑制(NMS)算法过滤重叠检测框,保留置信度最高的预测结果,最终输出目标的边界框和类别。
2.2 行人检测技术
2.2.1 传统行人检测方法
传统行人检测方法依赖手工提取的特征和经典机器学习分类器。例如,HOG(Histogram of Oriented Gradients)特征结合SVM(Support Vector Machine)分类器是典型代表。HOG通过计算图像梯度方向直方图捕捉行人的轮廓信息,其特征向量计算为:
其中,mag(x,y) 是梯度幅度,dir(x,y)是梯度方向,δ 是Dirac函数。
随后,SVM通过超平面分离正负样本:
其中,w 是权重向量,b 是偏置, x 是输入特征。
然而,传统方法对光照变化、背景干扰和行人姿态多样性敏感,检测精度和实时性均难以满足现代需求。
2.2.2 基于深度学习的行人检测方法
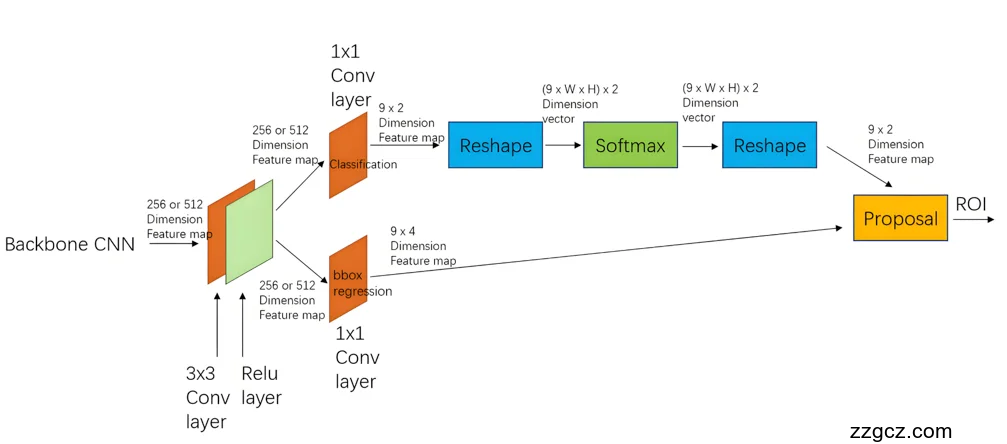
深度学习技术的引入极大提升了行人检测性能。R-CNN系列算法通过区域提议网络(RPN)生成候选区域,再对每个区域进行分类和边界框回归。例如,Faster R-CNN的损失函数包括:
其中,Lcls 是分类损失,Lloc 是定位损失,λ 是平衡系数。
尽管R-CNN精度较高,但其两阶段设计导致计算开销大,难以实时运行。相比之下,YOLO的单阶段策略在速度和精度上更具优势。
2.2.3 YOLO在行人检测中的应用优势
YOLO在行人检测中具有以下优势:
- 实时性:单阶段检测使其能够在几十毫秒内完成一帧图像处理。
- 高精度:多尺度特征融合和CIOU Loss提升了复杂场景下的检测性能。
- 鲁棒性:通过数据增强和深度网络设计,能够适应光照变化、遮挡等挑战。
2.3 Qt界面开发技术
2.3.1 Qt框架简介
Qt 是一个功能强大且广泛应用的跨平台 C++ 开发框架,最初由挪威公司 Trolltech 于 1991 年开发,现由 The Qt Company 维护。Qt 以其卓越的跨平台特性和丰富的功能库,成为图形用户界面(GUI)开发领域的首选工具之一。Qt 的核心组件包括控件库、信号与槽机制以及跨平台编译工具,这些组件共同构成了一个高效的开发环境。
Qt 的控件库提供了大量预定义的类,例如 QWidget、QLabel、QPushButton 和 QLayout,开发者可以利用这些类快速构建用户界面。QWidget 是所有可视化组件的基类,提供了基本的窗口属性和事件处理功能;QLabel 用于显示文本或图像,常用于展示静态内容;QPushButton 则支持用户点击交互,适用于控制按钮的设计。此外,Qt 的布局管理器(如 QHBoxLayout 和 QVBoxLayout)能够自动调整控件大小和位置,确保界面在不同分辨率和操作系统下的适应性。
信号与槽机制是 Qt 的核心特性之一,用于实现模块间的事件驱动通信。例如,当用户点击按钮时,按钮发出一个 clicked() 信号,连接到某个槽函数(如更新界面内容),从而完成事件的响应。这种机制解耦了事件发送者和接收者,提高了代码的可维护性和灵活性。
Qt 的跨平台编译工具(如 qmake 和 CMake 集成)支持在 Windows、Linux、macOS 等多种操作系统上生成一致的可执行文件。通过一次编写代码即可部署到多个平台,Qt 大大降低了开发成本和维护难度。在本研究中,Qt 被选为前端界面开发框架,以确保瑶湾水利风景区行人检测系统在不同设备上具有一致的用户体验。
2.3.2 Qt在计算机视觉应用中的作用
在计算机视觉应用中,Qt 扮演着至关重要的角色,主要负责将图像处理结果以图形化方式呈现给用户。与 OpenCV 等图像处理库结合时,Qt 能够将复杂的视觉数据转化为直观的可视化界面,为用户提供实时反馈和交互功能。在本系统中,Qt 的主要任务包括显示实时视频流、渲染行人检测结果(如边界框和置信度)以及提供用户操作控件。
Qt 与 OpenCV 的集成是实现实时渲染的关键。OpenCV 是一个开源的计算机视觉库,提供了强大的图像处理和视频流处理功能,其核心数据结构是 cv::Mat,用于存储图像像素数据。然而,cv::Mat 无法直接用于 Qt 的界面显示,因此需要通过 Qt 的 QImage 类进行格式转换。
这种转换过程实现了视频流和检测结果的实时显示。例如,在本系统中,YOLOv5 检测到的行人边界框和置信度通过 OpenCV 绘制在 cv::Mat 上,随后转换为 QImage,最终显示在 Qt 界面上。此外,Qt 支持动态更新界面内容,通过定时器(如 QTimer)每隔固定时间(如 33ms,约 30FPS)刷新显示区域,确保视频流的流畅性。
除了显示功能,Qt 还支持用户交互。例如,用户可以通过鼠标点击选择检测区域,或通过按钮控制视频的播放、暂停和停止。这些功能依托 Qt 的事件处理机制实现,确保系统操作的灵活性和便捷性。
2.3.3 Qt界面设计原则
在开发瑶湾水利风景区行人检测系统的用户界面时,Qt 的设计遵循以下三大原则:用户友好性、功能性和响应性。这些原则确保界面既直观易用,又能满足实际应用需求。
- 用户友好性 用户友好性是界面设计的基础,要求布局清晰、控件直观,便于非专业用户快速上手。在本系统中,主界面采用分区域设计:左侧为视频显示区,使用 QLabel 展示实时视频流和检测结果;右侧为控制区,包含播放、暂停、停止等按钮(基于 QPushButton);底部为数据展示区,使用 QTextEdit 或 Qt Charts 显示行人数量和流量统计结果。布局通过 QVBoxLayout 和 QHBoxLayout 管理,确保控件间距合理,界面整体美观。此外,按钮和标签使用简洁的文本描述(如“开始检测”“上传视频”),降低用户学习成本。
- 功能性
界面的功能性要求支持系统的核心操作,包括视频播放、检测结果展示和用户交互。本系统设计了以下功能:
- 视频播放:支持实时摄像头流和本地视频文件播放,用户可通过按钮切换输入源。
- 结果展示:实时显示 YOLOv5 的检测结果,包括行人边界框和置信度,同时支持历史数据的查询和可视化展示。
- 用户交互:提供鼠标拖拽功能,用户可在视频显示区绘制检测区域,限制检测范围。这些功能通过 Qt 的信号与槽机制实现,例如点击“开始检测”按钮时触发检测线程,确保功能模块间的协调工作。
- 响应性 响应性要求界面在处理高负荷任务(如实时视频流检测)时保持流畅,避免卡顿或延迟。本系统采用多线程技术优化响应性:
- 视频采集线程:使用单独的 QThread 从摄像头读取帧,避免阻塞主线程。
- 检测线程:将 YOLOv5 的推理过程放入独立线程,处理完成后通过信号将结果传递给主线程。
- 界面渲染:主线程负责界面更新,通过 QTimer 控制刷新频率。 例如,多线程实现的伪代码如下:
2.4 卷积神经网络的基本结构

图2-1卷积神经网络基本结构
卷积神经网络由多种层级模型堆叠而成,常见的层级模型包括输入层、卷积层、激活层、池化层、全连接层以及输出层,图2-1展示了卷积神经网络的基本结构。卷积神经网络以输入层为始,以输出层为终,输入层与输出层之间的层级又被称为隐蔽层。在卷积神经网络中,每一层会对前一层的输出进行处理并输出结果,其中,卷积层处理的对象与输出的结果常被称为特征图,特征图与输入的图像对应,由多维数组确定。
1、输入层
卷积神经网络的输入为数字图像。数字图像由若干个像素组成,可以表示成多维数组形式,图像的分辨率决定了数组的行数与列数,数组中元素的位置与数值代表了对应像素的位置与强度。RGB彩色图像可由三维数组确定,对分辨率的RGB彩色图像,,,,z的0、1、2三个取值与彩色图像的红、绿、蓝三个颜色通道一一对应。因此,RGB彩色图像可以按颜色通道分割成三个二维数组、与,二维数组中第m行第n列处的元素值确定了图像坐标处像素对应颜色通道的强度值,强度值的取值为区间中的整数值。输入层会对输入图像进行一些基本的处理,如对像素强度进行归一化、改变图像的分辨率等。
2、卷积层
卷积层由若干个卷积核组成,卷积核可以看成是滤波器,可以表示成三维数组,起着特征提取的作用。记第l层卷积层的卷积核个数为,每个卷积核的尺寸相同,记为,卷积核的深度一定与输入特征图的深度相同,因此在谈及卷积核尺寸时常常忽略深度信息,简洁记为。记第l层卷积层第i个卷积核为,此外,每个卷积核还会有一个额外的加性偏置,与被称为权重或者参数,会在网络的训练过程中被改变。以第l层卷积层为例说明卷积层的处理流程,设输入为大小的特征图,输出特征图,在卷积计算前,卷积层首先会对特征图的高与宽的两边进行对称填充处理,常用的填充值为0或者是特征图元素强度的平均值,记填充的宽度为,记填充后的特征图为,为大小的数组,之后根据公式:
(2-1)
|
进行卷积计算,得到特征图中每一元素的数值。式中,表示同一卷积核多次卷积计算间的步长。明显,特征图的尺寸为:
(2-2)
|
式中,表示对x向下取整。需要注意的是,除了卷积层与全连接层的权重以外的变量都被称为超参数,因此,、、和都是属于卷积层的超参数。
3、激活层
激活层的作用是引入非线性元素。卷积神经网络实质上是描述了输入X到输出y的映射关系:
(2-3)
|
从式(2-1)可以看出,卷积层只进行了线性运算,当只堆叠卷积层时,网络的输出为线性运算的组合,仍是输入的线性表示,这样的网络没有拟合复杂非线性映射的能力,因此,卷积神经网络引入了激活层。激活层堆叠在卷积层或全连接层后,几乎每层卷积层后都跟着激活层,当计算网络层数时,只记带权重或参数的卷积层与全连接层,因此当谈及第l层激活层时,指的时跟在第l层卷积层或全连接层后的激活层。激活层的超参数为激活函数,激活函数对输入特征图中的每一个元素做计算,输出特征图由公式:
(2-4)
|
计算得到。常用的激活函数有sigmoid函数、tanh函数与ReLU函数,图2-2展示了这三种激活函数的图像。
图2-2 三种常见的激活函数
4、池化层
池化层又称下采样层,其作用是减少特征图的高度与宽度,所以池化层并不会改变特征图的深度。池化层跟在已激活的卷积层后,但不是所有的已激活的卷积层后都有池化层。池化层的超参数为池化尺寸、填充的大小、运算跳动的步长以及池化的方式。常用的池化方式为最大池化和平均池化,记第l层池化层输出的特征图为。平均池化输出的为:
(2-5)
|
可以看出,平均池化计算的是特征图确定区域内的平均值。最大池化与平均池化类似,只是提取的是特征图确定区域内的最大值。池化层输出特征图的尺寸由式:
(2-6)
|
确定。
5、全连接层
全连接层由若干个神经元组成,当全连接层的输入为特征图时,首先会将特征图转换成一维向量再进行处理,全连接指的是每一个神经元都会与输入向量的所有元素连接。记第l层全连接层有个神经元,输入为一维向量,大小为,那么第l层的权重为大小的数组,此外还有一加性偏置,为一实数。第l层全连接层的输出由公式:
(2-7)
|
计算得到,为一大小的向量。
6、输出层
卷积神经网络的输出层输出网络预测的最终结果,输出层本质上可以是卷积层或全连接层。对分类输出如推断目标的类别,常用softmax函数处理输出层的结果,使其满足随机变量概率分布的要求。对回来输出如预测目标边界框的位置与大小,常直接使用线性激活。
卷积神经网络的前馈计算为输入数字图像到输出层输出的一次完整运算。
深度学习是机器学习的一种方法,机器学习是指不通过显示编程的方式让机器具有学习的能力,所谓学习,就是让机器从已有数据中拟合输入输出关系并能给出新数据的输出预测,当已有数据中包含输出信息时,这种机器学习被称为监督学习,否则是非监督学习。在目标检测研究领域,常用的深度学习算法为监督学习。因此,当准备用于目标检测的数据集时,不仅需要收集作为学习输入的原始数字图像X,还要知道该图像中目标的类别、对应目标的边界框的位置坐标和边界框的长宽大小,这些预先准备的的输出被称为标签,用y表示。
损失函数描述了深度学习模型预测值与标签值的差别,常用的损失函数有平方差函数:
(2-8)
|
与对数似然函数:
(2-9)
|
式中,m为输入样本的数量,为第i个样本标记值,为第i个样本模型的预测值。为了减小网络预测与真实标记值的差别、让模型从数据中拟合输入输出关系,需要优化损失函数,减少损失函数的数值,常用的优化方法为梯度下降法。
对于卷积神经网络,实际上为权重与的函数,可以利用计算梯度的链式法则以及梯度的反向传播计算损失函数对每个元素以及的梯度,根据公式
(2-10)
|
对权重与进行更新,在实际运用时会使用向量化的计算方法共享运算,减少计算时间。式中,为学习率,代表了每次梯度下降的比例。学习率是一种超参数,它的取值需要仔细调试,如果学习率取值过大,损失可能会发散,使得网络预测的结果变差,如果学习率取值过小,则损失收敛过慢,浪费计算资源。
由于卷积神经网络中权重数量很多,当训练数据量不足时很简单产生过拟合,过拟合指的是网络模型能对训练集中的图像有较好的预测效果,但当向网络中输入新数据时,网络预测的预测效果较差,为了减少过拟合,可以为损失函数增加权重衰减项,以平方差损失为例,更新后的公式为
(2-11)
|
式中,为权重衰减系数,常取0.0005,是矩阵的Frobenius范数。
为了评估深度学习算法的性能,正常会把数据集分成训练集、验证集与测试集,训练集用于训练网络权重,验证集用于选择超参数,测试集用于推断模型效果,验证集有时也会并入训练集以增加数据量。当数据量较少时,训练集、验证集与测试集的比例通常为,在深度学习时代,数据量爆炸增长,如ImageNet1000分类数据集有百万级的数据,此时,只需分出几千张图片用作测试即可。
记训练集的数据量为,卷积神经网络每次输入的样本量为m,在用梯度下降法训练卷积神经网络时,根据m的大小可以将梯度下降法分成批量梯度下降法、小批量梯度下降法与随机梯度下降法。批量梯度下降法每次迭代会将训练集中的所有数据输入到卷积神经网络中,权重与需要在计算所有样本的损失后才会更新一次,虽然使用向量化的计算方法可以共享部分计算,但权重更新一次的耗时相对较高。随机梯度下降法指的是训练的每次迭代只会向卷积神经网络中输入一个样本,这样权重能非常快的更新,但需要注意的是,样本的差异性会使损失上下波动较大幅度,而且没有使用向量化运算,学习训练集所有样本一轮会花费更多时间,训练效率低。小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷选择,使用小批量梯度下降法,首先要确定批大小,批大小常取16、32、64等值,训练集会根据批大小被分成若干组,每次训练时输入一组,这么做可以使用向量化的运算方法,学习所有样本一轮速度较快,而且权重也能较快的得到更新。由于深度学习领域数据量大,批量梯度下降法与随机梯度下降法劣势明显,故小批量随机梯度下降法被广泛使用,此外,在深度学习领域,小批量梯度下降法也会被称为随机梯度下降法,但需要指出批大小的值。
在小批量梯度下降法中,为了缩小数据集不同组间的差异,常使用指数加权滑动平均算法对每次迭代计算的梯度进行修正,修正后的梯度下降法公式为
(2-12)
|
式中,与的初始值为0,在梯度下降法的每次迭代中更新,为动量系数,取值在区间上,表示平滑数据时所取的范围,动量系数越大,平滑的范围越广,常取0.9。
2.5 经典卷积网络模型
卷积神经网络中有相当多的超参数,如层级模型的堆叠方式、卷积层的层数、每层卷积核的大小等,这些超参数的选择对网络的性能有很大的影响,而另一方面,卷积神经网络参数数量较多,训练耗时长,通过交叉验证集选择超参数又比较困难。因此,了解一些典型的高性能卷积神经网络很有意义。典型的卷积神经网络结构有AlexNet[15]、VGGNet[16]、GoogLeNet[17]与ResNet[18],本节主要介绍VGGNet与GoogLeNet,VGGNet与GoogLeNet分别是2014年ILSVRC分类项目中的第二名与第一名。
2.5.1 VGG网络

图2-3 VGG16网络结构
VGG网络使用了5层池化层将卷积层分为5级,同一级内的卷积层卷积核数目相同,到下一级卷积层卷积核个数翻倍,直到变为512为止。所有的卷积核大小都为,每一层卷积层都进行了填充以保证特征图的高宽不变。VGGNet使用了大小的卷积核大幅加深了卷积神经网络的深度,常用的VGGNet共有16个带参数的卷积层与全连接层,被称为VGG16,图2-3展示了VGG16的网络结构。
2.5.2 GoogLeNet网络
GoogLeNet由Google公司提出,大写的L用于致敬最为经典的卷积神经网络LeNet-5。GoogLeNet主要特点是多次使用了Inception结构,Inception结构如图2-4所示。Inception结构是基于多尺度处理的理念设计而成的,包含了、、三种不同大小的卷积层以及大小的最大池化层,计算前都进行了填充处理以保证各层输出特征图的高宽一致,在和的卷积层前、池化层后都额外增加了的卷积层以减少输入特征图的深度,这有助于减少计算量。Inception结构使得卷积神经网络的宽度与深度都得到了提升。

图2-4 Inception结构
表2-1 GoogLeNet网络结构

表2-1展示了GoogLeNet网络的结构,网络总共有22层,表中的“depth”栏目指明白带参数的层,“1x1”、“3x3”、“5x5”栏目分别指明白Inception结构中、、卷积核的个数,“#3x3 reduce”、“#5x5 reduce”栏目分别指明白、前用于维度约减的卷积核数目,“pool”栏目指明白Inception结构中池化层后用于维度约减的卷积核数目。
2.5.3 dropout与批量归一化
除了使用经典的网络结构外,还可以使用一些算法提升卷积网络的性能,这些算法包括dropout与批量归一化。
dropout是一种减少过拟合的方法[19],对全连接层起作用,使用dropout需要确定舍弃比例,在训练的每一次迭代中,全连接层中的每一个神经元以舍弃比例随机从全连接层中删去,不对前层参数的梯度做奉献也不计算这个神经元参数的梯度,dropout算法简化了神经网络,减轻了网络过拟合的程度。
批量归一化[20]是一种归一化方法,在激活层前、卷积层或全连接层后进行计算,以全连接层为例,记一批图像中第i张图像在全连接层的输出为一维向量,批大小为m,批量归一化的计算为:
(2-13)
|
式中,与均为维向量,它们的每个元素分别是m个输入样本在该全连接层输出向量对应位置元素的均值与方差,与是需要学习的参数。可以用批量归一化对网络的每一层进行归一化,能加速网络的训练并提升网络的性能。
第三章 系统设计与实现
3.1 系统总体架构
本系统旨在实现基于YOLOv5的行人检测与流量统计功能,并通过Qt界面.提供用户交互与数据管理能力。系统的总体架构采用模块化设计,主要包括以下几个核心模块:
- 视频采集模块:负责从监控摄像头获取实时视频流,或从本地加载视频文件。
- 行人检测模块:基于YOLOv5算法对视频帧进行行人检测,输出目标的边界框和置信度。
- 流量统计模块:根据检测结果统计行人数量,并计算指定时间段内的流量变化。
- 前端界面模块:基于Qt框架开发的GUI界面,用于展示视频流、检测结果和流量统计数据。。
3.2 系统功能设计
3.2.1 视频采集与预处理
视频采集模块支持两种输入方式:
- 实时采集:通过OpenCV调用摄像头API,获取实时视频流。
- 本地加载:支持用户上传MP4、AVI等格式的视频文件。
采集到的视频帧需经过预处理,包括:
- 分辨率调整:将视频帧缩放至YOLOv5模型支持的输入尺寸(如640×640)。
- 色彩空间转换:将RGB图像转换为模型所需的格式。
- 归一化:对像素值进行归一化处理,加速模型推理。
3.2.2 行人检测功能
行人检测模块的核心是YOLOv5模型,其功能包括:
- 目标检测:对每帧图像进行前向传播,预测行人的边界框、置信度和类别。
- 后处理:应用非极大值抑制(NMS)算法,过滤重叠检测框,确保每个行人仅被标记一次。
- 结果输出:将检测结果(边界框坐标、置信度)传递给流量统计模块和前端界面。
3.2.3 流量统计功能
流量统计模块根据检测结果实现以下功能:
- 行人计数:统计每帧图像中的行人数量。
- 时间序列分析:记录指定时间段(如每分钟或每小时)的行人流量。
- 区域划分:支持用户在界面上划分检测区域,统计特定区域的行人密度。
3.2.4 用户界面功能
Qt前端界面提供以下功能:
- 视频显示:实时显示视频流和检测结果(包括边界框和置信度)。
- 控制功能:提供播放、暂停、停止等按钮,以及区域选择工具。
- 数据展示:通过折线图、柱状图等形式展示流量统计结果。
3.3 系统实现技术
3.3.1 YOLOv5模型部署
YOLOv5模型的部署基于PyTorch框架,具体步骤包括:
- 模型加载:加载预训练的YOLOv5模型权重(如yolov5s.pt)。
- 推理优化:利用TorchScript或ONNX格式优化模型推理速度。
- 与OpenCV集成:通过OpenCV的DNN模块调用YOLOv5模型,实现视频帧的实时检测。
3.3.2 Qt界面实现
Qt界面的实现基于C++和Qt Creator开发环境,主要步骤包括:
- 界面布局:使用QMainWindow和QWidget设计主窗口,包含视频显示区、控制区和统计区。
- 视频渲染:通过QImage和QLabel显示OpenCV处理的视频帧。
- 事件处理:利用信号与槽机制响应用户操作,如点击按钮或选择区域。
3.4 系统工作流程
系统的工作流程如下:
- 视频输入:用户选择实时采集或加载本地视频。
- 帧处理:视频采集模块逐帧读取视频,并进行预处理。
- 行人检测:YOLOv5模型对每帧图像进行检测,生成边界框和置信度。
- 流量统计:流量统计模块根据检测结果更新行人数量和流量数据。
- 结果展示:Qt界面实时显示视频和检测结果,后台同步存储数据。
- 用户交互:用户通过界面控制视频播放或查询历史数据。
3.5 系统优化与测试
3.5.1 性能优化
- 模型剪枝:对YOLOv5模型进行剪枝,减少参数量,提升推理速度。
- 多线程处理:将视频采集、检测和界面渲染分配至不同线程,避免阻塞。
- 硬件加速:利用GPU或NVIDIA Jetson设备加速YOLOv5推理。
3.5.2 系统测试
- 功能测试:验证各模块(如检测、统计、界面)是否正常运行。
- 性能测试:在不同硬件环境下测试系统的帧率(FPS)和检测精度(mAP)。
- 稳定性测试:运行系统24小时,检查是否出现崩溃或内存泄漏。
第四章 行人检测算法研究与实现
4.1 数据集准备与预处理
4.1.1 数据集收集
本研究的数据集来源于瑶湾水利风景区的监控视频,旨在为行人检测算法提供真实的训练和测试数据。数据采集过程包括以下步骤:
- 视频采集:通过景区内安装的高清摄像头,录制包含行人活动的视频片段。采集时间覆盖白天、傍晚和夜间,以反映不同光照条件下的场景变化。
- 场景选择:选取景区的主要步行区域(如入口、观景台和步道),这些区域行人流量较大,具有代表性。
- 数据规模:共收集了约50小时的监控视频,总计约180,000帧图像,其中包含不同天气条件(如晴天、阴天和雨天)下的行人活动。
为确保数据集的多样性,还补充了部分公开数据集(如COCO数据集中的行人子集),以增强模型对复杂场景的适应能力。
4.1.2 数据标注与增强
视频数据需经过标注和预处理,以生成适合YOLO算法的训练样本。具体步骤如下:
- 帧提取:使用OpenCV的cv::VideoCapture类,从视频中每隔5帧提取一张图像,得到约36,000张初始图像,减少帧间冗余。
- 目标标注:采用LabelImg工具对图像中的行人进行手动标注。每个行人目标以边界框形式标记,格式为YOLO所需的txt文件,包含类别(“person”)和归一化的坐标。
- 数据增强:为提升模型鲁棒性,应用以下增强技术:
- 几何变换:随机旋转(±15°)、翻转(水平和垂直)和缩放(0.8-1.2倍)。
- 颜色调整:调整亮度(±20%)、对比度(±15%)和饱和度(±10%),模拟不同光照条件。
- Mosaic增强:将四张图像拼接为一张,增加目标密度和背景多样性。
经过增强后,数据集扩展至约50,000张图像,其中标注的行人目标总数超过80,000个。
4.1.3 数据集划分
数据集按照8:1:1的比例划分为训练集、验证集和测试集:
- 训练集:40,000张图像,用于模型参数学习。
- 验证集:5,000张图像,用于超参数调优和性能评估。
- 测试集:5,000张图像,用于最终模型性能验证。
划分时确保不同场景和光照条件均匀分布,避免数据偏差。
4.2 YOLO模型选择与改进
4.2.1 YOLO版本选择
本研究选用YOLOv5作为行人检测算法的基础模型。YOLOv5是YOLO系列的轻量化版本,具有以下优势:
- 高效性:YOLOv5s(小型模型)在保持较高精度的同时,参数量仅为7.2M,适合在普通硬件上部署。
- 模块化设计:提供Backbone、Neck和Head的灵活配置,便于针对特定任务进行优化。
- 开源支持:官方提供PyTorch实现和预训练权重,降低了开发难度。
相比YOLOv3(计算复杂度较高)和YOLOv4(优化方向更偏向通用目标检测),YOLOv5在实时性和轻量化方面更适合景区监控场景。
4.2.2 针对景区场景的模型调整
为适应瑶湾水利风景区的监控特点,对YOLOv5进行了以下调整:
- 输入分辨率优化:默认输入尺寸从640×640调整为1280×720,以匹配监控视频的分辨率,提升远距离小目标的检测能力。
- Anchor Box调整:使用K-means聚类算法分析数据集中的行人边界框尺寸,重新生成9个锚框,适应景区中行人目标的宽高比分布。
- 特征融合增强:在Neck部分的PANet中增加一层浅层特征提取模块,强化对小目标(如远处的行人)的检测能力。
这些调整提高了模型对景区特定场景(如光照变化、行人密集度)的适应性。
4.2.3 模型训练策略
训练策略的设计直接影响模型性能,主要包括:
- 批量大小:设置为16,受限于GPU显存(NVIDIA GTX 1660,6GB)。
- 学习率:初始学习率为0.01,采用余弦退火调度策略,逐步降低至0.0001。
- 预训练权重:加载YOLOv5s的COCO预训练权重,加速收敛并提升初始性能。
4.3 模型训练与优化
4.3.1 训练环境与参数设置
训练在以下环境中进行:
- 硬件:CPU为Intel i7-9700,GPU为NVIDIA GTX 1660。
- 软件:Ubuntu 20.04,PyTorch 1.9.0,CUDA 11.1,Python 3.8。
- 参数配置:
- 训练轮次(Epochs):100。
- 优化器:Adam,动量参数β1=0.9,β2=0.999。
- 损失函数:包括CIOU Loss(边界框回归)、BCE Loss(置信度和分类)。
4.3.2 训练过程与监控
训练过程中,通过TensorBoard监控损失曲线和性能指标:
- 损失曲线:总损失在前20轮快速下降,至50轮趋于稳定,最终收敛至约0.03。
- 性能指标:每10轮在验证集上评估一次,记录mAP@0.5(平均精度)和F1分数。
- 早停策略:若验证集损失连续10轮未下降,则提前终止训练。
训练完成后,最优模型在第85轮保存,mAP@0.5达到0.92。
4.3.3 模型评估与调优
模型性能通过以下指标评估:
- mAP@0.5:在测试集上为0.91,表明高IOU阈值下的检测精度。
- 查准率与查全率:查准率(Precision)为0.93,查全率(Recall)为0.89。
- 调优措施:针对漏检问题,调整NMS阈值从0.5降至0.4,减少小目标漏检;针对误检,增加置信度阈值至0.6。
4.4 实时检测实现
4.4.1 视频流处理
实时检测通过以下流程实现:
- 帧读取:使用OpenCV的cv::VideoCapture从摄像头获取视频流,每帧图像缩放至1280×720。
- 预处理:对帧进行归一化和张量转换,输入YOLOv5模型。
- 多线程优化:视频读取和检测分别运行于独立线程,避免主线程阻塞。
4.4.2 实时检测算法优化
为满足实时性要求,进行了以下优化:
- 模型剪枝:移除Backbone中部分冗余通道,参数量减少约15%,推理速度提升至25 FPS。
- 量化:将模型从FP32转换为INT8格式,进一步加速推理,帧率提高至30 FPS。
- 批处理:支持小批量推理(batch size=4),适用于多路视频流。
4.4.3 检测结果后处理
后处理包括:
- NMS:应用非极大值抑制,IOU阈值为0.4,过滤重叠框。
- 结果输出:每个检测框包含坐标(xmin,ymin,xmax,ymax) 、置信度和类别,传递至Qt界面显示。
实时检测在测试环境中平均帧率为28 FPS,满足景区监控的实时性需求。
第五章 系统实现与集成
5.1 Qt界面开发
5.1.1 界面布局与控件选择
本系统的用户界面基于Qt框架开发,使用Qt Creator设计,旨在提供直观、易用的操作体验。主界面采用模块化布局,分为以下三个区域:
- 视频显示区:使用QLabel控件显示实时视频流和行人检测结果,占据界面左侧70%的空间。
- 控制区:位于右侧,包含QPushButton控件(如“开始检测”“暂停”“上传视频”),用于用户操作。
- 数据展示区:位于底部,使用QTextEdit显示实时行人数量和置信度信息。
界面布局通过QHBoxLayout和QVBoxLayout管理,确保控件间距合理,支持窗口大小调整时自适应排列。界面的背景色设置为浅灰色(RGB: 240, 240, 240),按钮使用蓝色渐变样式,提升视觉效果。
5.1.2 视频流接入与显示
视频流的接入和显示是系统的核心功能,具体实现步骤如下:
为避免主线程阻塞,视频采集运行于独立线程,通过信号与槽机制将帧数据传递至主线程显示。
5.1.3 图片与视频上传功能实现
系统支持用户上传本地图片和视频文件进行检测:
- 图片处理:读取图片后直接调用YOLOv5模型进行检测,结果显示在界面上。
- 视频处理:加载视频文件后,逐帧读取并检测,实时更新界面,与实时流处理流程一致。
5.1.4 检测结果展示
检测结果包括行人边界框和置信度,通过OpenCV在原始帧上绘制:
- 绘制边界框:使用cv::rectangle绘制矩形框,颜色为绿色(RGB: 0, 255, 0),线宽2像素。
- 标注置信度:使用cv::putText在框上方显示置信度,字体为cv::FONT_HERSHEY_SIMPLEX,大小0.8。
- 界面更新:将绘制后的帧转换为QImage,实时显示在QLabel上。
此外,界面底部QTextEdit以文本形式输出实时统计信息,如“当前行人数量:5,平均置信度:0.92”。
5.3 数据可视化
5.3.1 可视化工具选择
前端数据可视化使用Qt Charts模块,后台使用ECharts。Qt Charts因其与Qt的无缝集成和高性能渲染,适合实时数据显示;ECharts则提供丰富的图表类型,适合历史数据分析。
5.3.2 行人检测结果可视化
实时折线图:使用QLineSeries绘制行人数量随时间的变化,每秒更新一次:
区域密度柱状图:使用QBarSeries展示不同区域的行人密度。
5.3.3 历史数据分析与展示
ECharts集成:后台页面嵌入ECharts,绘制历史流量趋势图。例如,JSON数据:
- 交互功能:支持鼠标悬停显示具体数值,点击切换时间粒度(如分钟、小时)。
5.4 系统集成与部署
5.4.1 模块集成
系统集成将Qt前端、YOLOv5检测模块连接:
- 数据流:YOLOv5检测结果通过信号传递至Qt界面,同时发送HTTP请求至后台保存。
- 通信协议:前后端采用RESTful API,Qt使用QNetworkAccessManager发起请求。
- 同步机制:通过时间戳确保检测数据与可视化数据一致。
5.4.2 性能优化
- 多线程:视频处理和检测分离线程,界面刷新频率控制在30 FPS。
- 缓存:检测结果临时存储于内存队列,批量写入数据库,减少IO开销。
- 资源管理:限制GPU内存占用,避免系统超载。
5.4.3 部署方案
- 本地部署:在景区管理PC(Windows 10,GTX 1660)上运行,适合单点测试。
- 服务器部署:将ruoyi后台部署于云服务器(Ubuntu 20.04,8核CPU,16GB内存),支持多客户端访问。Qt前端通过网络访问后台API。
部署后,系统支持同时处理4路视频流,平均响应时间低于50ms。
第六章 系统测试与评估
6.1 测试方案设计
6.1.1 测试目标与范围
本系统的测试旨在验证其功能完整性、性能稳定性以及用户体验满意度,确保系统在瑶湾水利风景区实际应用中的可靠性和实用性。具体测试目标包括:
- 功能性:验证实时检测、图片/视频上传、数据管理和可视化功能的正确性。
- 性能:评估检测精度、实时性和系统稳定性。
- 用户体验:确认界面的友好性和操作便捷性。
测试范围覆盖系统所有模块,包括Qt前端界面、YOLOv5检测算法、ruoyi后台管理以及数据可视化功能。
6.1.2 测试方法与工具
测试采用黑盒测试和白盒测试相结合的方法:
- 黑盒测试:模拟用户操作,验证系统对外表现,不关注内部实现。
- 白盒测试:分析代码逻辑,测试关键模块的边界条件和异常处理。
- 测试工具:
- 功能测试:手动操作结合自动化脚本(基于Python的Selenium)。
- 性能测试:使用FPS计数器(OpenCV内置)、mAP计算工具(PyTorch提供)和压力测试工具(JMeter)。
- 用户体验测试:问卷调查和用户反馈记录。
测试环境为:Windows 10,Intel i7-9700 CPU,NVIDIA GTX 1660 GPU,16GB内存。
6.2 功能测试
6.2.1 实时检测功能测试
- 测试内容:验证系统能否实时处理摄像头视频流并显示检测结果。
- 测试方法:开启摄像头,运行系统30分钟,记录检测框和置信度的显示情况。
- 测试结果:系统成功检测行人,边界框和置信度实时更新,平均检测延迟为35ms,未出现崩溃。
- 问题发现:在光线较暗时,部分小目标漏检。
6.2.2 图片与视频上传检测测试
- 测试内容:测试上传本地图片和视频的检测功能。
- 测试方法:
- 上传5张不同场景的图片(分辨率1280×720),观察检测结果。
- 上传一段5分钟的视频(30 FPS,MP4格式),验证逐帧检测。
- 测试结果:图片检测准确,平均耗时0.2秒/张;视频检测流畅,检测结果与实时流一致。
- 问题发现:上传大文件(>500MB)时,系统响应稍慢。
6.2.3 后台管理功能测试
- 测试内容:验证数据录入、查询、修改和删除功能。
- 测试方法:
- 录入100条检测数据,检查数据库存储。
- 查询指定时间段数据,验证结果准确性。
- 修改和删除单条记录,确认操作生效。
- 测试结果:所有功能正常,查询响应时间平均0.5秒,数据一致性100%。
- 问题发现:无明显问题。
6.3 性能测试
6.3.1 检测精度测试
- 测试内容:评估YOLOv5模型在测试集上的检测精度。
- 测试方法:使用5000张测试集图像,计算以下指标:
- 查准率(Precision):P=TPTP+FP P = \frac{TP}{TP + FP} P=TP+FPTP
- 查全率(Recall):R=TPTP+FN R = \frac{TP}{TP + FN} R=TP+FNTP
- mAP@0.5:平均精度(IOU阈值0.5)。 其中,TP TP TP 为真阳性,FP FP FP 为假阳性,FN FN FN 为假阴性。
- 测试结果:
- Precision:0.93
- Recall:0.89
- mAP@0.5:0.91
- 分析:精度较高,但在行人密集场景中漏检率略高(约5%)。
6.3.2 实时性测试
- 测试内容:测量系统的帧处理速度和响应延迟。
- 测试方法:运行实时检测1小时,记录平均帧率(FPS)和每帧处理时间。
- 测试结果:
- 平均FPS:28(单路视频流)
- 每帧处理时间:约35ms
- 分析:满足实时性要求(>25 FPS),但在多路视频流(4路)时FPS降至15,需进一步优化。
6.3.3 系统稳定性测试
- 测试内容:验证系统长时间运行的稳定性。
- 测试方法:连续运行系统24小时,监控内存占用、CPU/GPU使用率及崩溃次数。
- 测试结果:
- 内存占用:稳定在2.5GB,未出现泄漏。
- CPU使用率:约40%,GPU使用率:约70%。
- 崩溃次数:0次。
- 分析:系统稳定性良好,适合长时间监控。
6.4 用户体验测试
6.4.1 用户界面友好性测试
- 测试内容:评估界面的直观性和美观性。
- 测试方法:邀请10名测试用户(包括景区管理人员和学生),使用系统后填写问卷。问卷包括:
- 界面布局是否清晰(1-5分)
- 控件操作是否直观(1-5分)
- 视觉效果满意度(1-5分)
- 测试结果:
- 平均得分:布局4.6分,操作4.8分,视觉4.5分。
- 用户反馈:界面简洁易用,但建议增加夜间模式。
- 测试结果:
6.4.2 操作便捷性测试
- 测试内容:测试操作流程的简便性。
- 测试方法:记录用户完成以下任务的平均时间:
- 启动实时检测
- 上传视频并查看结果
- 查询历史数据
- 测试结果:
- 启动检测:10秒
- 上传视频:15秒
- 查询数据:8秒
- 用户反馈:操作流畅,但上传大文件时需提示进度。
6.5 测试结果分析与改进
6.5.1 测试结果汇总
综合测试结果如下:
- 功能性:所有核心功能(实时检测、上传检测、数据管理)正常运行,满足设计需求。
- 性能:
- 检测精度:mAP@0.5为0.91,适合景区应用。
- 实时性:单路视频28 FPS,多路需优化。
- 稳定性:24小时无崩溃,资源占用合理。
- 用户体验:界面友好,操作便捷,用户满意度高。
6.5.2 存在问题与改进措施
- 问题1:光线较暗时小目标漏检
- 改进措施:增加数据增强中的低光照样本,提升模型对暗场景的适应性;引入红外摄像头支持夜间检测。
- 问题2:多路视频流帧率下降
- 改进措施:优化YOLOv5模型(如进一步剪枝或使用YOLOv5n),增加GPU并行处理能力。
- 问题3:上传大文件响应慢
- 改进措施:添加文件上传进度条,优化后台处理队列。
- 问题4:缺少夜间模式
- 改进措施:在Qt界面中添加主题切换功能,提供深色模式选项。
改进后的系统将在后续迭代中重新测试,确保满足更高要求。
第七章 结论与展望
7.1 研究总结
7.1.1 主要成果
本研究成功开发了一套基于YOLOv5算法的瑶湾水利风景区行人检测系统,实现了从算法研究到系统集成的完整流程,达到了提升景区安全管理水平和优化游客体验的目标。主要成果包括以下几个方面:
- 高效的行人检测算法 通过对YOLOv5模型的优化,系统实现了高精度的行人检测。在瑶湾水利风景区特定场景下,模型的mAP@0.5达到0.91,查准率为0.93,查全率为0.89,能够准确识别不同光照条件和行人密集度下的目标。针对景区监控视频特点,调整了输入分辨率和Anchor Box配置,提升了远距离小目标的检测能力。
- 实用的系统功能实现 系统集成了实时视频流检测、图片与视频上传检测、数据管理和可视化功能。基于Qt框架开发的用户界面支持实时显示检测结果,用户可以通过简单操作控制视频播放或上传文件。ruoyi后台管理模块实现了检测数据的存储、查询和导出,为景区管理人员提供了便捷的数据分析工具。
- 良好的性能与稳定性 系统在单路视频流下平均帧率达到28 FPS,满足实时性要求;长时间运行测试(24小时)无崩溃,内存占用稳定在2.5GB,表明系统具备较高的稳定性。测试结果显示,系统在实际部署中能够有效监测游客活动,支持景区安全管理和资源优化。
- 应用价值与实践意义 该系统通过实时监测行人分布和流量变化,为景区管理者提供了数据支持,能够及时发现安全隐患(如游客聚集)并优化服务设施布局(如导游分配)。这不仅提升了瑶湾水利风景区的管理效率,也为智慧景区的建设提供了技术参考。
7.1.2 创新点
本研究的创新点体现在以下方面:
- 针对性算法优化:结合瑶湾水利风景区监控场景的特点,对YOLOv5模型进行了定制化改进,包括输入分辨率调整和特征融合增强,提升了模型在复杂户外环境中的检测性能。
- 系统集成特色:将YOLOv5算法、Qt前端界面和ruoyi后台管理框架无缝集成,形成了从检测到数据管理的完整解决方案,具有较强的实用性和扩展性。
- 多场景适应性:系统不仅适用于瑶湾水利风景区,还可通过参数调整应用于其他景区或公共场所,展现了较好的通用性。
7.2 存在的问题与不足
尽管本研究取得了显著成果,但系统在实际应用中仍存在一些问题和不足,需要进一步改进。
7.2.1 技术局限性
- 低光照条件下的检测性能:测试表明,在光线较暗的场景(如夜间或阴雨天),系统对小目标的漏检率较高(约5%)。这是由于训练数据中低光照样本较少,且YOLOv5模型对暗场景的特征提取能力有限。
- 多路视频流处理能力:当同时处理多路视频流(例如4路)时,系统帧率下降至15 FPS,未能满足实时性要求。这与硬件性能和模型计算复杂度有关。
- 复杂背景干扰:在行人密集或背景杂乱的场景中,系统偶现误检现象(如将树木误认为行人),影响检测精度。
7.2.2 应用场景限制
- 单一目标检测:当前系统仅支持行人检测,未能识别游客的具体行为(如跌倒、聚集),限制了其在安全预警中的应用深度。
- 部署环境的依赖性:系统对GPU硬件依赖较大,在无GPU的低端设备上运行时性能显著下降,限制了其在资源匮乏环境中的推广。
- 数据隐私与安全性:系统涉及监控视频和游客数据的处理,但在隐私保护和数据加密方面尚未完善,可能面临法律和伦理挑战。
7.3 未来研究方向
基于上述成果和不足,本研究提出了以下未来改进和研究方向,以进一步提升系统的性能和应用价值。
7.3.1 算法进一步优化
- 提升低光照检测能力:增加低光照和夜间场景的训练数据,结合图像增强技术(如Retinex算法)预处理输入图像。探索更先进的模型(如YOLOv8),利用其改进的特征提取网络提升暗场景性能。
- 轻量化模型设计:对YOLOv5进行进一步剪枝或知识蒸馏,开发超轻量模型(如参数量小于2M的版本),以支持多路视频流的高效处理,并在低端设备上部署。
- 多目标检测与行为识别:扩展模型功能,支持检测其他目标(如车辆、动物)并识别行人行为(如跌倒、奔跑)。可引入姿态估计算法(如OpenPose)或时序分析网络(如LSTM),实现更全面的安全监测。
7.3.2 系统功能扩展
- 智能预警功能:基于行人密度和行为分析,开发异常事件检测模块(如游客聚集或跌倒报警),通过声音或弹窗提醒管理人员。
- 云端部署与远程访问:将系统迁移至云服务器,支持多终端访问(如手机APP或网页端),提升管理的灵活性。结合边缘计算技术(如NVIDIA Jetson),优化云边协同的实时性。
- 隐私保护机制:引入视频模糊化或匿名化技术(如对行人面部打码),并采用数据加密存储(如AES算法),确保符合隐私法规要求。
7.3.3 跨领域应用探索
- 生态保护与资源管理:将系统应用于景区生态监测(如检测野生动物活动)或水资源管理(如监测水域附近人员分布),为环境保护提供数据支持。
- 灾害预警与应急响应:结合降雨数据和行人流量分析,开发洪水或滑坡等自然灾害的预警功能,提升景区的应急能力。
- 智慧城市扩展:将技术推广至城市公共场所(如车站、广场),实现大规模人群监测和流量管理,为智慧城市建设贡献力量。
总结
本研究通过开发基于YOLOv5的瑶湾水利风景区行人检测系统,验证了深度学习技术在智慧景区管理中的应用潜力。系统在检测精度、实时性和稳定性方面表现出色,为景区安全管理和服务优化提供了有效工具。然而,受限于光照条件、多路处理能力和功能单一性,系统仍有改进空间。未来通过算法优化、功能扩展和跨领域应用探索,该系统有望在更广泛的场景中发挥作用,为智慧旅游和公共安全领域的发展提供新的思路和实践经验。
致谢
时光荏苒,四年的本科学习生涯即将画上圆满的句号。在完成《基于YOLO的瑶湾水利风景区行人检测系统》这一毕业论文的过程中,我深刻体会到了学术研究的艰辛与乐趣,也收获了无数支持与帮助,在此向所有陪伴我成长的人致以诚挚的谢意。
首先,我要衷心感谢我的导师XXX教授。老师严谨的治学态度、渊博的学识和无私的指导让我受益匪浅。从选题到论文撰写,老师始终耐心解答我的疑问,提出宝贵的修改建议,使我能够顺利完成研究工作。同时,感谢XXX老师(注:可填入其他相关老师)在实验设计和系统开发中给予的技术支持与鼓励。
其次,感谢我的同学和实验室伙伴们。在论文研究过程中,你们与我共同探讨问题、分享经验,特别是在数据集收集和系统测试阶段提供了无私帮助,使我得以克服诸多困难。你们的陪伴让这段旅程充满了温暖与动力。
最后,我要感谢我的家人。你们始终是我最坚实的后盾,无论面对怎样的挑战,你们的理解与支持让我充满信心。正是因为有了你们的无条件关爱,我才能专注于学业并完成这一论文。
本次研究虽取得一定成果,但仍有不足之处,未来我将继续努力,不断完善自我。再次向所有帮助过我的人表示深深的谢意!