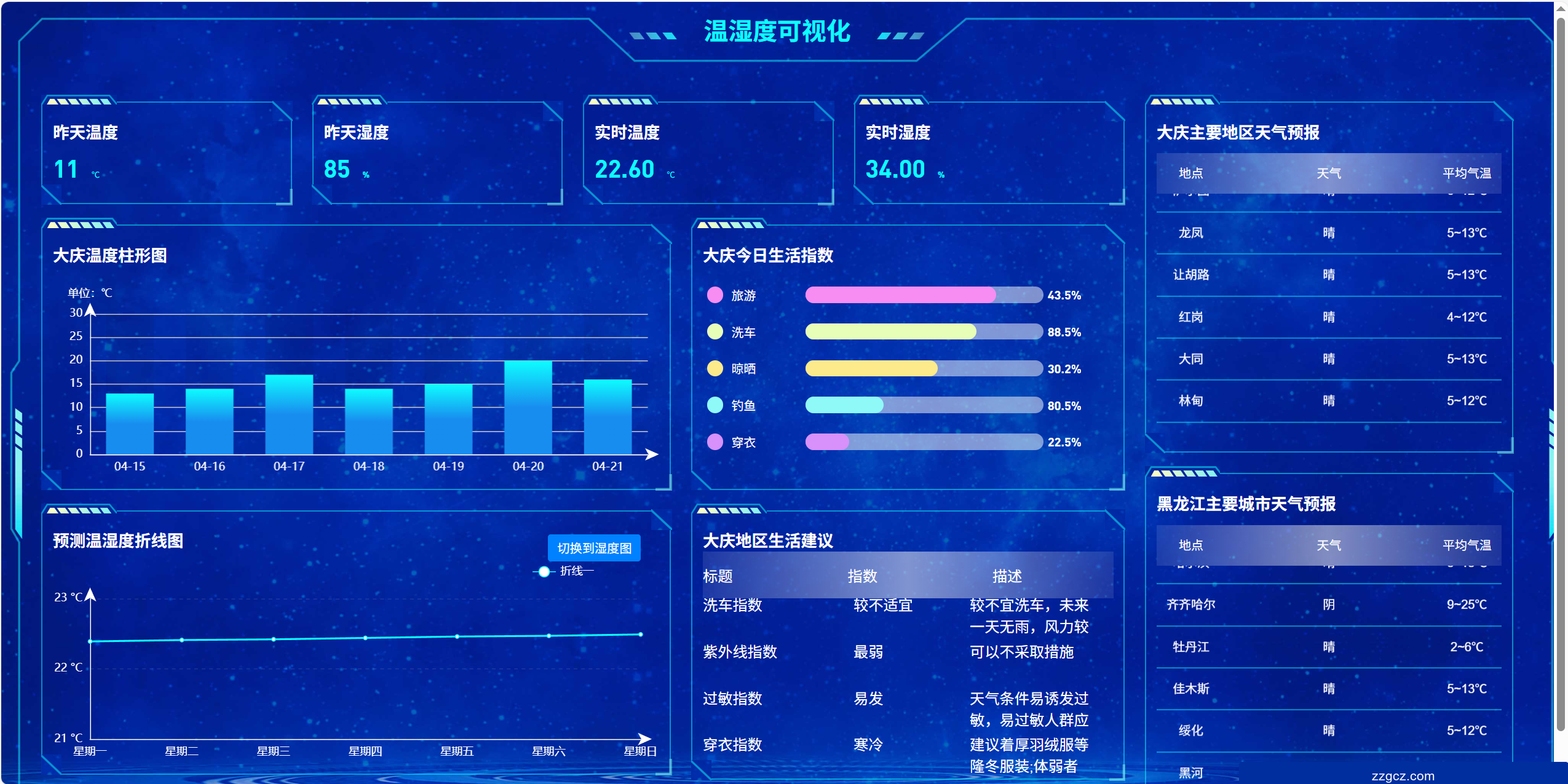
A348-基于深度学习和机器学习的传感器温度和湿度预测分析可视化大屏
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
# 温度与湿度预测模型文档
## 概述
本文档描述了一个统一的管道,用于使用传统机器学习模型(样条-岭回归和随机森林)以及现代长短期记忆(LSTM)神经网络预测温度和湿度。该管道处理时间序列数据,训练模型,评估性能,可视化结果,并保存训练好的模型以供后续使用。
- **版本**:1.0
- **日期**:2025-04-29
- **测试环境**:PyTorch 2.2,scikit-learn 1.4
- **输入数据**:`ss_tem.csv`(列包括:`date`、`time`、`temperature`、`humidity`)
- **输出**:
- 可视化结果:`figures/*.png`
- 模型参数:`models/*.{pkl,pth}`
## 管道结构
管道包括六个主要步骤:
1. **数据加载与预处理**
2. **传统模型训练(样条-岭回归和随机森林)**
3. **LSTM 模型训练**
4. **时间序列可视化**
5. **性能评估与比较**
6. **模型保存**
## 1. 数据加载与预处理
### 输入
- **文件**:`ss_tem.csv`
- **必需列**:
- `date`:日期,格式为 `DD/MM/YYYY`
- `time`:时间,格式为 `HH:MM:SS`
- `temperature`:温度(°C,浮点数)
- `humidity`:相对湿度(%,浮点数)
### 预处理步骤
- **日期时间转换**:使用 `pd.to_datetime` 将 `date` 和 `time` 合并为 `datetime` 列。
- **数据清洗**:将 `temperature` 和 `humidity` 转换为浮点数,删除包含缺失值的行。
- **特征工程**:
- 从 `datetime` 中提取 `hour`、`minute`、`second`。
- 计算 `time_seconds` 为 `hour*3600 + minute*60 + second`,表示连续时间。
- **输出**:一个包含附加时间特征的清洗后 DataFrame。
## 2. 传统模型训练
为温度和湿度分别训练两个传统模型:
- **样条-岭回归**:
- **管道**:
- `StandardScaler`:标准化输入特征。
- `SplineTransformer`:应用 B 样条变换(60 个节点,3 次,基于分位数的节点)。
- `RidgeCV`:岭回归,使用交叉验证选择 alpha(`alphas=np.logspace(-4,4,17)`)。
- **输入**:`time_seconds`
- **输出**:预测的温度/湿度。
- **随机森林**:
- **模型**:`RandomForestRegressor`,100 个估计器,`random_state=42`。
- **输入**:`time_seconds`
- **输出**:预测的温度/湿度。
- **数据划分**:80% 训练,20% 测试(`random_state=42`)。
- **评估指标**:
- 均方误差(MSE)
- R² 分数
## 3. LSTM 模型训练
使用 LSTM 模型捕捉时间依赖关系,采用深度学习方法。
### 超参数
- **序列长度**:24 个时间步
- **批次大小**:64
- **学习率**:0.001
- **训练轮数**:150
- **早停耐心**:15
- **隐藏层大小**:64
- **层数**:2
### 模型架构
- **LSTM 层**:`nn.LSTM`,输入大小为 1,隐藏层大小为 64,2 层,batch-first。
- **全连接层**:`nn.Linear`,将隐藏层大小映射到输出大小 1。
- **前向传播**:处理序列并输出下一个时间步的预测。
### 训练过程
- **数据准备**:
- 使用 `MinMaxScaler` 缩放数据。
- 通过滑动窗口创建长度为 24 的序列。
- 将数据转换为 PyTorch 张量。
- **优化**:
- 优化器:Adam(`lr=0.001`)
- 损失函数:均方误差(`nn.MSELoss`)
- 梯度裁剪:范数限制为 1.0。
- **早停**:如果验证损失在 15 个轮次内没有改善,则停止训练。
- **输出**:训练好的模型、预测值、MSE 和 R²(针对全序列)。
## 4. 时间序列可视化
可视化比较所有模型的实际值与预测值:
- **样条-岭回归**:温度和湿度的图表。
- **随机森林**:温度和湿度的图表。
- **LSTM**:温度和湿度的图表,包括全序列拟合。
- **格式**:折线图,实际值(蓝色)与预测值(橙色)。
- **输出文件**:
- `figures/temp_timeseries_lr.png`
- `figures/temp_timeseries_rf.png`
- `figures/temp_timeseries_lstm.png`
- `figures/humidity_timeseries_lr.png`
```markdown
- `figures/humidity_timeseries_rf.png`
- `figures/humidity_timeseries_lstm.png`
- `figures/full_temperature_fit.png`
- `figures/full_humidity_fit.png`
## 5. 性能评估与比较
### 指标
- **均方误差(MSE)**:衡量预测误差。
- **R² 分数**:衡量解释方差。
- **比较模型**:
- 样条-岭回归
- 随机森林
- LSTM
### 可视化
- **柱状图**:比较温度和湿度在各模型上的 MSE 和 R²。
- **输出文件**:`figures/model_comparison.png`
### 打印输出
- 每个模型和目标变量(温度和湿度)的 MSE 和 R²。
## 6. 模型保存
所有训练好的模型和缩放器都保存以便重现:
- **样条-岭回归**:`models/lr_temp.pkl`, `models/lr_hum.pkl`
- **随机森林**:`models/rf_temp.pkl`, `models/rf_hum.pkl`
- **LSTM**:`models/lstm_temperature.pth`, `models/lstm_humidity.pth`
- **缩放器**:`models/scaler_temperature.pkl`, `models/scaler_humidity.pkl`
## 依赖
- **Python**:3.x
- **库**:
- `numpy`
- `pandas`
- `matplotlib`
- `torch` (PyTorch 2.2)
- `scikit-learn` (1.4)
- **可选**:
- Matplotlib 的中文字体支持(`SimHei`, `Microsoft YaHei` 等)。
## 运行管道
```bash
python unified_pipeline.py