A352-基于CNN的心跳信号预测分析flask系统带论文
导出时间:2025/11/24 13:11:26
摘 要
本研究围绕基于卷积神经网络(CNN)的心跳信号预测任务展开,旨在设计高效的时序建模框架,以提升对长序列心电信号的预测精度和模型泛化能力。针对心跳信号在时域中的复杂动态特性,本文构建了三种深度学习预测模型:基础卷积神经网络(BaselineCNN)、残差卷积神经网络(ResidualCNN)以及卷积与双向长短期记忆网络结合的混合模型(CNN_LSTM)。此外,为系统评估各模块对模型性能的影响,还设计了两个消融版本:去除Dropout正则化的Baseline_no_drop模型,以及将残差网络中的卷积核大小缩小的Residual_small_k模型。
在模型结构上,BaselineCNN通过三层一维卷积与批归一化模块提取特征,结合全局平均池化和全连接层实现对1000步预测序列的输出;ResidualCNN引入多层残差块结构以增强特征传播能力,缓解梯度消失问题;CNN_LSTM模型则在卷积层之后引入双向LSTM单元,融合局部与长距离时间依赖,有效捕捉心跳信号中的时序关联性。结果表明,ResidualCNN在建模稳定性和收敛速度方面具备优势,而CNN_LSTM模型在处理非平稳信号和长时依赖预测任务中表现出更优的拟合能力。对比消融实验进一步验证了Dropout机制和卷积核宽度对模型性能的显著影响。
此外,本文还开发了一个基于Flask框架的Web系统,用于实现心跳信号预测模型的在线应用。该系统提供了用户注册、登录、数据输入、模型选择以及预测结果展示等功能。用户可以通过系统上传心跳信号数据,并选择不同的预测模型(如CNN、LSTM等)进行预测,系统会实时返回预测结果。该系统的开发不仅为心跳信号预测提供了一个便捷的交互平台,还通过用户管理、数据验证和安全措施等设计,确保了系统的可靠性和易用性。
关键词:卷积神经网络;心跳信号预测;时序建模;消融实验
Abstract
This study focuses on the task of heartbeat signal prediction based on Convolutional Neural Networks (CNNs), aiming to design an efficient temporal modeling framework to improve the prediction accuracy and generalization ability of models for long-sequence electrocardiogram (ECG) signals. In response to the complex dynamic characteristics of heartbeat signals in the time domain, this paper constructs three deep learning prediction models: Baseline Convolutional Neural Network (BaselineCNN), Residual Convolutional Neural Network (ResidualCNN), and a hybrid model combining Convolutional Neural Networks with Bidirectional Long Short-Term Memory (LSTM) units (CNN_LSTM). Additionally, to systematically evaluate the impact of each module on model performance, two ablation versions were designed: the Baseline_no_drop model, which removes Dropout regularization, and the Residual_small_k model, which reduces the kernel size in the residual network.
In terms of model architecture, BaselineCNN extracts features through three layers of one-dimensional convolution and batch normalization modules, and combines global average pooling and fully connected layers to output a 1000-step prediction sequence. ResidualCNN introduces a multi-layer residual block structure to enhance feature propagation and alleviate the vanishing gradient problem. The CNN_LSTM model incorporates bidirectional LSTM units after the convolutional layers to integrate local and long-range temporal dependencies, effectively capturing the temporal associations in heartbeat signals. The results show that ResidualCNN has advantages in modeling stability and convergence speed, while the CNN_LSTM model demonstrates superior fitting ability in handling non-stationary signals and long-term dependency prediction tasks. The ablation experiments further verify the significant impact of Dropout mechanisms and kernel width on model performance.
Moreover, this paper develops a Web system based on the Flask framework to implement the online application of heartbeat signal prediction models. The system provides functions such as user registration, login, data input, model selection, and prediction result display. Users can upload heartbeat signal data through the system and select different prediction models (such as CNN, LSTM, etc.) for prediction, with the system returning the prediction results in real time. The development of this system not only offers a convenient interactive platform for heartbeat signal prediction but also ensures the system's reliability and usability through user management, data validation, and security measures.
Keywords: Convolutional Neural Network; Heartbeat Signal Prediction; Time Series Modeling; Ablation Study
目 录
摘 要I
AbstractII
第1章 绪论1
1.1 研究背景及意义1
1.1.1 研究背景与意义1
1.2 国内外研究1
1.2.1 国内研究现状2
1.2.2 国外研究现状3
1.3 研究内容与研究方法3
1.3.1 研究内容4
1.3.2 研究方法4
1.4 创新点5
第2章 相关理论与技术7
2.1 深度学习基础7
2.2 卷积神经网络(CNN)理论框架7
2.2.1 CNN的基本结构7
2.2.2 CNN的数学原理9
2.2.3 CNN的训练与优化10
2.3 长短期记忆神经网络理论框架13
第3章 实验部分17
3.1 实验目的17
3.2 数据集说明18
3.3 实验模型设置18
3.4 模型参数18
3.5 实验流程19
3.6 实验结果21
第4章 系统部分27
4.1 系统功能描述分析27
4.2 核心模块设计27
4.2.1 用户管理模块27
4.2.2 预测模块27
4.2.3 菜单管理模块28
4.3 数据交互设计28
4.3.1 前端与后端交互29
4.3.2 后端与数据库交互29
4.4 技术选型与工具30
4.5 系统界面30
第5章 总结与展望35
5.1 总结35
5.2 不足与展望35
参考文献37
致 谢38
绪论
研究背景及意义
研究背景与意义
在当今社会,心脏疾病已成为全球范围内的主要健康威胁之一,其发病率和死亡率持续居高不下,给患者及其家庭带来了沉重的负担,也对社会医疗资源造成了巨大压力。传统的诊断方法,如心电图(ECG)检查等,虽然在心脏疾病诊断中发挥着重要作用,但在准确性、实时性和便捷性方面仍存在一定的局限性。随着科技的飞速发展,深度学习技术在图像识别、语音识别等领域取得了显著成就,为解决复杂模式识别问题提供了强大的工具,也为心脏疾病诊断方法的创新带来了新的机遇。深度学习具有自动提取特征的能力,能够从大量的心电信号数据中学习到心跳的复杂模式和特征,从而实现对不同类型心跳的精准分类。这不仅可以提高诊断的准确性,还能实现心脏疾病的早期筛查和实时监测,为患者争取宝贵的治疗时间,减轻医疗负担。
本研究致力于将深度学习技术应用于心跳分类,旨在开发一种高效、精准的心跳分类方法,以克服传统诊断方法的不足。通过构建基于深度学习的模型,能够自动从心电信号中提取关键特征并进行分类,有效避免人为因素对诊断结果的影响,提高诊断的客观性和准确性。该研究成果将为心脏疾病的诊断提供一种新的手段,丰富和完善现有的诊断体系。能够实现对心电信号的实时分析和监测,及时发现潜在的心脏问题,有助于心脏疾病的早期诊断和治疗,从而提高患者的生存率和生活质量。深度学习在医疗领域的成功应用为医疗诊断技术的智能化发展提供了范例,本研究将进一步推动这一趋势,促进医疗行业向更加智能化、自动化的方向迈进,提高医疗服务的效率和质量。将深度学习技术应用于心跳分类,涉及医学、生物学、计算机科学、数学等多个学科领域的知识和技术,有助于促进这些学科之间的交叉融合和协同发展,为跨学科研究提供新的思路和方法。
国内外研究
国内研究现状
近年来,随着深度学习技术的快速发展,国内在心跳信号分类与识别领域的研究取得了显著进展。研究者们通过引入先进的算法和模型架构,不断探索更高效、更准确的心跳信号处理方法。
林鸣放和席燕辉[1]提出了一种基于小波变换和Inception网络的心跳分类方法。该研究利用小波变换对心跳信号进行特征提取,结合Inception网络的多尺度特征学习能力,有效提高了心跳信号的分类精度。实验结果表明,该方法能够在复杂的心跳信号中准确识别不同类别的心跳模式,为临床诊断提供了有力支持。
刘子杰和杨晨[2]则探索了CNN与Transformer相融合的心跳分类算法。该研究将卷积神经网络(CNN)的局部特征提取能力与Transformer的全局特征建模能力相结合,通过引入自注意力机制,进一步提升了模型对心跳信号的特征表达能力。研究表明,这种融合模型在处理长序列心跳信号时表现出色,能够有效捕捉信号中的长距离依赖关系,显著提高了分类准确率。
王浩杰[3]研究了基于CNN转换的脉冲神经网络学习算法,并将其应用于心跳信号分类。该研究通过将传统的卷积神经网络转换为脉冲神经网络,利用脉冲神经网络的生物可解释性和高效计算能力,实现了对心跳信号的动态分类。实验结果表明,该算法在处理非平稳心跳信号时具有较好的适应性和鲁棒性,为心跳信号的实时监测和诊断提供了新的思路。
史文可[4]则从量子计算的角度出发,研究了基于量子神经网络的异常心电图生成与识别算法。该研究利用量子神经网络的并行计算优势和量子纠缠特性,构建了一种高效的异常心电图识别模型。通过量子态的编码和解码,该模型能够快速识别异常心跳信号,并生成相应的异常样本用于训练和验证。研究表明,量子神经网络在处理复杂的心电图信号时具有显著的性能优势,为未来的心跳信号分析提供了新的技术方向。
总体而言,国内在心跳信号分类与识别领域的研究已经取得了丰富的成果,研究者们通过引入多种先进的算法和技术,不断优化模型架构和性能。然而,随着心跳信号数据的复杂性和多样性不断增加,如何进一步提高模型的泛化能力和实时性仍然是未来研究的重要方向。
国外研究现状
Ítalo Flexa Di Paolo 和 Adriana Rosa Garcez Castro[11]提出了一种基于多模态卷积神经网络(CNN)的心跳分类方法,该方法结合了自适应注意力机制,用于患者内(intra-patient)和患者间(inter-patient)的心跳信号分类。通过引入多模态特征提取,该研究能够同时处理时间域和频域信号,从而更全面地捕捉心跳信号的特征。自适应注意力机制的引入进一步增强了模型对关键特征的聚焦能力,显著提高了分类精度。实验结果表明,该方法在不同患者的心跳信号分类任务中表现出色,尤其是在处理复杂的心跳模式时,能够有效区分正常和异常心跳信号。
Peimankar A、Ebrahimi A 和 Wiil K U[12]则提出了一种基于可解释深度迁移学习的ECG心跳分类方法(XECG-Beats)。该研究通过迁移学习技术,将预训练的深度神经网络模型应用于ECG信号分类任务,显著提高了模型的分类性能。此外,该研究还引入了可解释性分析工具,通过可视化和特征重要性评估,帮助研究人员和临床医生更好地理解模型的决策过程。实验结果表明,XECG-Beats方法在多种心跳信号分类任务中表现出色,尤其是在处理大规模数据集时,能够快速适应新的任务并保持较高的分类准确率。
在实际应用方面,国外研究机构积极将深度学习模型应用于临床实践。开发出的智能诊断系统能够实时分析心电信号,快速准确地识别各类心跳异常,为医生提供诊断建议,有效提高了诊断效率和准确性。这些系统在一些医疗机构中得到了广泛应用和验证,取得了良好的效果,有力地推动了深度学习技术在心脏疾病诊断中的实际应用。
然而,国外研究同样面临着一些挑战和问题。首先,心电信号数据的隐私和安全问题日益凸显,如何在保护患者隐私的前提下进行数据共享和研究,是当前需要解决的重要课题。其次,深度学习模型的可解释性仍然是一个亟待解决的问题。在临床应用中,医生和患者需要理解模型的决策依据,而目前大多数深度学习模型类似于“黑箱”,缺乏直观的解释,这在一定程度上限制了其在临床中的广泛应用。此外,不同国家和地区的数据标准和格式存在差异,导致数据整合和共享存在困难,影响了研究的整体进展和成果共享。
研究内容与研究方法
研究内容
本研究主要围绕心跳曲线的分析与处理展开,具体研究框架如下:
首先,在绪论部分介绍研究的背景、意义以及整体的研究框架,明确研究的目标和方向。
接着,第二章对相关理论进行分析,包括心跳信号的生理基础、信号处理的基本理论以及深度学习中卷积神经网络(CNN)的相关理论,为后续的研究提供坚实的理论支撑。
第三章为实验部分,包括实验目的,数据集说明,实验模型设置,实验参数的设置,同时,对baselinecnn,residualcnn,cnnlstm三个对比模型进行训练,,详细阐述其网络结构、设计原理以及训练过程中使用的参数,包括优化算法、损失函数、训练周期等,使读者能够清楚地了解该模块的特点和优势。
第四章为系统设计部分,包括整体基于flask的web系统功能描述和界面介绍。
最后,第五章基于前文的分析和研究结果,针对心跳信号分析和处理提出具体的建议,包括算法的优化方向、实际应用中的注意事项等,并对整个研究进行总结,归纳研究的主要结论,指出研究的不足之处和未来的研究方向。
研究方法
本研究针对心跳信号预测任务,设计了一种高效的时序建模框架,基于卷积神经网络(CNN)构建了三种深度学习预测模型,并通过消融实验系统评估各模块对模型性能的影响。以下为具体研究方法:
(1)模型设计
基础卷积神经网络(BaselineCNN):采用三层一维卷积结构,结合批归一化(Batch Normalization)模块提取心跳信号的时域特征。通过全局平均池化层(Global Average Pooling)和全连接层实现对1000步预测序列的输出,旨在验证基础卷积结构的预测能力。
残差卷积神经网络(ResidualCNN):在BaselineCNN基础上引入多层残差块结构,通过残差连接增强特征传播能力,缓解深层网络中的梯度消失问题,提升模型对复杂心跳信号的建模稳定性与收敛速度。
卷积与双向长短期记忆网络混合模型(CNN_LSTM):在卷积层后引入双向长短期记忆(Bi-LSTM)单元,融合卷积提取的局部特征与LSTM捕捉的长距离时序依赖,有效建模心跳信号中的非平稳特性与长期关联性。
(2)消融实验设计
为进一步分析各模块对模型性能的贡献,设计了以下两种消融版本:
Baseline_no_drop:在BaselineCNN中去除Dropout正则化层,验证Dropout对模型泛化能力的影响。
Residual_small_k:将ResidualCNN中残差块的卷积核大小缩小,分析卷积核宽度对特征提取能力的作用。
(3)数据与训练
使用模拟或实际采集的心跳信号数据集进行模型训练与验证。数据预处理包括信号去噪、分段和标准化,以确保输入数据质量。模型采用均方误差(MSE)作为损失函数,通过Adam优化器进行参数优化,并在验证集上评估模型性能。
(4)性能评估
通过多种指标综合评估模型预测性能,包括:
均方误差(MSE):衡量预测值与真实值之间的平方差,反映预测精度。
平均绝对误差(MAE):评估预测值的绝对偏差,反映模型鲁棒性。
决定系数(R²):衡量模型对数据变异的解释能力,反映拟合效果。
(5)实验分析
对比三种模型在不同心跳信号预测任务中的表现,分析ResidualCNN在稳定性与收敛速度上的优势,以及CNN_LSTM在非平稳信号和长时依赖任务中的优越性。结合消融实验结果,量化Dropout正则化和卷积核宽度对模型性能的具体影响。
通过上述方法,本研究构建了多结构CNN预测框架,系统探索了心跳信号时序建模的关键技术,为智能心率监测与临床辅助诊断提供了理论依据与技术支持。
创新点
本研究提出了一种针对心跳信号长序列预测的多结构深度学习框架,创新性地设计并对比了BaselineCNN、ResidualCNN和CNN_LSTM三种模型,分别通过基础卷积、残差连接和卷积-LSTM混合结构,高效捕捉心跳信号的复杂时序动态特性。引入残差块增强特征传播与模型稳定性,结合双向LSTM融合局部与长距离时序依赖,提升非平稳信号的预测精度。此外,通过精心设计的消融实验(Baseline_no_drop和Residual_small_k),系统验证了Dropout正则化和卷积核宽度对模型性能的关键影响。实验结果表明,该框架在MSE、MAE和R²等指标上表现优异,展现出强大的泛化能力和实际应用潜力,为智能心率监测与临床辅助诊断提供了高效的理论与技术支持。
相关理论与技术
深度学习基础
深度学习作为机器学习的重要分支,通过模拟人脑神经元的层次化结构,利用多层非线性变换从数据中自动提取高维抽象特征,广泛应用于图像识别、自然语言处理等领域。其核心框架基于人工神经网络,包含输入层、隐藏层和输出层,通过激活函数(如ReLU、Sigmoid)引入非线性表达能力,逐层传递与组合信息以完成复杂映射。典型模型包括卷积神经网络(CNN)——擅长处理空间局部相关性任务(如图像分类),循环神经网络(RNN)——适用于序列数据建模(如文本生成),以及Transformer——凭借自注意力机制在全局依赖关系建模中表现卓越。训练过程中,反向传播算法结合优化器(如Adam、SGD)通过最小化损失函数(如交叉熵、均方误差)调整网络参数,同时引入正则化技术(如Dropout、L2正则化)防止过拟合。此外,数据增强(如旋转、裁剪、噪声注入)通过扩展训练样本多样性提升模型泛化能力。深度学习的优势在于其端到端的学习范式,能够直接从原始数据中挖掘潜在规律,无需依赖人工特征工程,尤其适用于处理高维度、非结构化的多模态数据(如图像-文本对),为多任务融合与复杂场景理解提供了技术基础。
卷积神经网络(CNN)理论框架
卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格结构数据(如图像、视频、音频等)的深度学习模型。其核心思想是通过局部感受野、权值共享和空间或时间上的下采样来有效捕获数据的层次化特征。CNN在计算机视觉、自然语言处理、医学图像分析等领域取得了显著的成功。本节将系统阐述CNN的理论框架,包括其基本结构、数学原理、训练方法以及优化策略。
CNN的基本结构
CNN通常由多个卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)组成,其中卷积层和池化层的交替堆叠构成特征提取器,而全连接层则用于最终的分类或回归任务。
卷积神经网络(CNN)是一种专门设计用于处理具有网格结构数据(如图像、视频等)的深度学习模型,其核心架构通常由多个卷积层、池化层和全连接层以特定的方式堆叠组成,每一层都承担着独特而关键的功能。在这些层级结构中,卷积层和池化层往往会交替出现,形成一个高效的特征提取器(Feature Extractor),这种设计能够逐步从原始输入数据中提取从低级到高级的层次化特征表示;而位于网络末端的全连接层则负责将提取到的抽象特征映射到最终的分类或回归任务上,完成整个模型的预测输出。具体来说,卷积层作为CNN最核心的组成部分,其主要功能是通过卷积运算自动提取输入数据的局部特征。从数学角度来看,给定一个输入张量X∈RH×W×C,其中H和W分别表示输入数据的高度和宽度(对于图像数据即像素的行列数),C表示通道数(例如普通RGB彩色图像的通道数C=3,分别对应红、绿、蓝三个颜色通道),卷积层会使用一组可学习的卷积核(也称为滤波器,Filter)对输入数据进行滑动窗口计算。每个卷积核本身也是一个多维张量K∈Rk×k×C,其中k表示卷积核的空间尺寸(通常为3×3或5×5等奇数大小),C必须与输入数据的通道数保持一致。在计算过程中,卷积核会在输入张量的高度和宽度维度上以一定的步长进行滑动,每次与输入局部区域(即与卷积核尺寸相同的子张量)进行逐元素的点积运算(Dot Product),并将所有元素的乘积结果求和后加上一个偏置项(Bias Term),最终生成特征图中对应位置的一个激活值。通过这种局部连接和权值共享机制,卷积层能够显著减少模型的参数数量,同时有效捕捉输入数据中的空间局部相关性。值得注意的是,每个卷积层通常会包含多个不同的卷积核(如64个或128个),每个卷积核都会独立地生成一张特征图,这些特征图在深度方向上堆叠就构成了该卷积层的完整输出。此外,为了增强模型的非线性表达能力,在卷积运算后通常会立即应用一个非线性激活函数(如ReLU、LeakyReLU等),这使得CNN能够拟合更加复杂的特征表示。而池化层的引入则主要通过降采样操作来逐步减小特征图的空间尺寸,这不仅可以降低计算复杂度,还能使模型对输入的小型平移、旋转等变化保持一定的鲁棒性。最终,经过多次卷积和池化操作后得到的高级语义特征会被展平(Flatten)并送入全连接层,通过传统的神经网络连接方式完成分类或回归等最终任务。
具体而言,输出特征图Y∈RH′×W′×D的第d个通道Yd的计算公式为:
其中bd为偏置项,H′和W′由输入尺寸、卷积核大小、步长(Stride)和填充(Padding)共同决定。卷积运算的局部连接特性使得CNN能够有效捕获空间局部模式,而权值共享(即同一卷积核在不同位置共享参数)则大幅减少了模型的参数量。
池化层的作用是对特征图进行下采样,从而降低计算复杂度并增强模型的平移不变性。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling)。最大池化通过取局部区域内的最大值来保留最显著的特征,其数学表达式为:
其中R为池化窗口(如2×22×2区域),s为步长。池化层通常不引入可学习参数,但其对特征图的降维作用使得后续层能够关注更高层次的抽象特征。
全连接层在CNN的末端用于将提取的特征映射到目标输出空间。假设前一层的输出为Z∈RMZ∈RM,全连接层的权重矩阵为W∈RM×NW∈RM×N,则其输出为:
全连接层的参数量通常较大,因此现代CNN架构(如ResNet、DenseNet等)倾向于采用全局平均池化(Global Average Pooling)替代部分全连接层以减少过拟合风险。
CNN的数学原理
CNN的理论基础源于局部感受野、权值共享和多层次特征组合。从数学上看,卷积层的运算可以视为一种稀疏交互(Sparse Interaction),即每个输出神经元仅与局部输入神经元相连,这与全连接层的密集交互形成鲜明对比。这种稀疏性不仅降低了计算成本,还使得模型能够更专注于局部模式的提取。
另一方面,权值共享(Parameter Sharing)使得卷积核在不同位置重复使用,从而进一步减少了参数量。从信号处理的角度看,卷积运算是一种线性时不变系统(LTI),其对平移、旋转等几何变换具有一定的鲁棒性。然而,CNN的实际表现远超传统线性系统,这得益于非线性激活函数(如ReLU、LeakyReLU等)的引入。ReLU(Rectified Linear Unit)的定义为:
其稀疏激活特性能够加速训练并缓解梯度消失问题。此外,批量归一化(Batch Normalization,BN)也被广泛用于CNN中,通过对每一层的输入进行标准化:
其中μ和σ2为当前批次的均值和方差,ϵ为小常数用于数值稳定性。BN能够显著提高训练速度并减少对初始化的敏感性。
CNN的训练与优化
卷积神经网络的训练通常采用反向传播算法结合梯度下降法(Gradient Descent)进行,这一过程构成了深度学习模型优化的核心机制。在训练开始时,网络首先对输入数据进行前向传播,即数据依次通过卷积层、池化层和全连接层,每一层都会执行相应的线性或非线性变换,最终输出预测结果。随后,通过损失函数(Loss Function,如交叉熵损失用于分类任务,均方误差用于回归任务)计算网络预测值与真实标签之间的误差,这一误差值反映了当前模型参数的性能优劣。接下来,反向传播算法开始发挥作用,该算法基于链式法则从输出层向输入层逐层回传误差,并计算损失函数对每一层可训练参数(如卷积核权重、偏置项等)的梯度。这些梯度信息本质上指明了各参数应该如何调整才能减小预测误差。最后,优化器(如随机梯度下降SGD、Adam等)利用计算得到的梯度信息,按照设定的学习率对网络参数进行迭代更新,使损失函数值逐渐收敛到局部最小值。整个过程需要反复在训练数据集上迭代多个周期,期间可能还会应用批量归一化、Dropout等正则化技术来提升模型泛化能力,同时采用学习率衰减等策略优化训练过程。值得注意的是,由于CNN具有局部连接和权值共享的特性,其参数规模远小于相同深度的全连接网络,这使得反向传播过程中的梯度计算更加高效,也大大降低了模型的过拟合风险。此外,现代深度学习框架(如TensorFlow、PyTorch)已实现自动微分(Automatic Differentiation)功能,能够自动高效地完成反向传播所需的梯度计算,极大简化了CNN的训练流程。
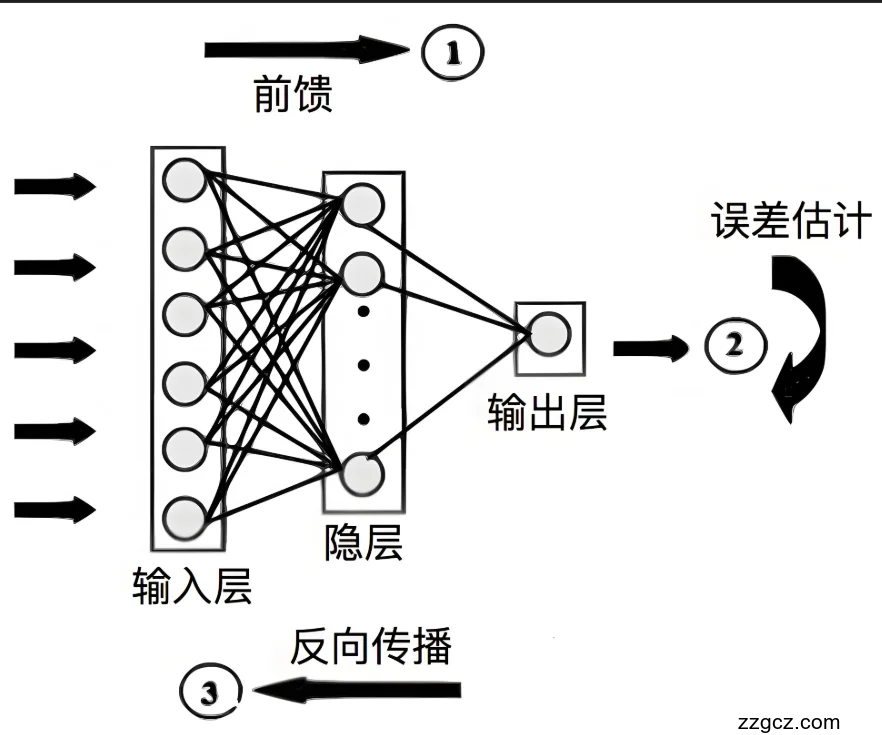
图2.2 1
给定损失函数L(θ),其中θ为模型参数,梯度下降的更新规则为:
其中η为学习率。由于CNN的深层结构,梯度消失(Vanishing Gradient)或梯度爆炸(Exploding Gradient)问题尤为突出。为此,现代CNN采用以下优化策略:
在深度神经网络的发展过程中,随着网络层数的增加,模型往往会面临梯度消失和梯度爆炸的问题,导致深层网络的训练变得极其困难。传统的深度卷积神经网络(如VGG)在层数超过一定数量后,性能甚至会不升反降,这一现象被称为退化问题。2015年,何恺明等人提出的残差网络(ResNet, Residual Network)通过引入残差连接,成功解决了这一难题,使得训练数百甚至上千层的深度神经网络成为可能,并显著提升了模型性能。
残差连接的核心思想是跨层恒等映射(Skip Connection / Identity Mapping),即在传统的卷积层或全连接层之外,额外增加一条“捷径”(Shortcut),使得输入信号可以直接绕过若干层传递到更深的网络部分。
残差连接(Residual Connection):如ResNet通过跨层恒等映射缓解梯度消失,其基本块定义为:
其中F为卷积层的非线性变换。
3. 残差连接的优势
解决梯度消失问题:
传统深层网络在反向传播时,梯度会因连续乘法而指数级衰减。
残差连接提供了“直达路径”,使梯度可以直接回传,避免消失。
提升训练稳定性
即使某些层学习效果不佳,网络仍能依赖残差连接保持性能。
实验表明,sNet的训练误差下降速度远快于普通CNN。
支持极深层网络
ResNet-152(152层)的性能远超VGG-16/19(16/19层)。
后续研究甚至提出了1000层以上的ResNet变体。
适用于多种任务
不仅用于图像分类(ImageNet),还在目标检测(Faster R-CNN)、语义分割(U-Net)、生成对抗网络(GAN)等领域广泛应用。
4. 残差连接的变体与改进
自ResNet提出以来,研究者们提出了多种改进版本
Pre-activation ResNet:将BatchNorm和ReLU放在卷积之前,进一步提升训练稳定性
Wide ResNet:增加通道数(宽度)而非深度,提升模型表达能力。
ResNeXt:引入分组卷积(Grouped Convolution),提高计算效率。
DenseNet:将所有层密集连接,进一步优化信息流动。
自适应优化算法:如Adam(Adaptive Moment Estimation)结合动量(Momentum)和自适应学习率调整:
其中gt为当前梯度,β1,β2为衰减率。
数据增强(Data Augmentation):通过对训练样本进行随机裁剪、旋转、翻转等操作增加数据多样性,提升泛化能力。
长短期记忆神经网络理论框架
在传统的循环神经网络(RNN)中,网络通过在时间序列上循环传递信息来处理序列数据,例如文本、语音或时间序列数据。然而,RNN在处理长序列数据时存在梯度消失和梯度爆炸的问题。梯度消失是指随着序列长度的增加,反向传播时梯度逐渐减小,导致网络难以学习到长距离的依赖关系;而梯度爆炸则是指梯度在反向传播过程中不断增大,使得网络的训练变得不稳定。为了解决这些问题,长短期记忆网络(LSTM)应运而生。
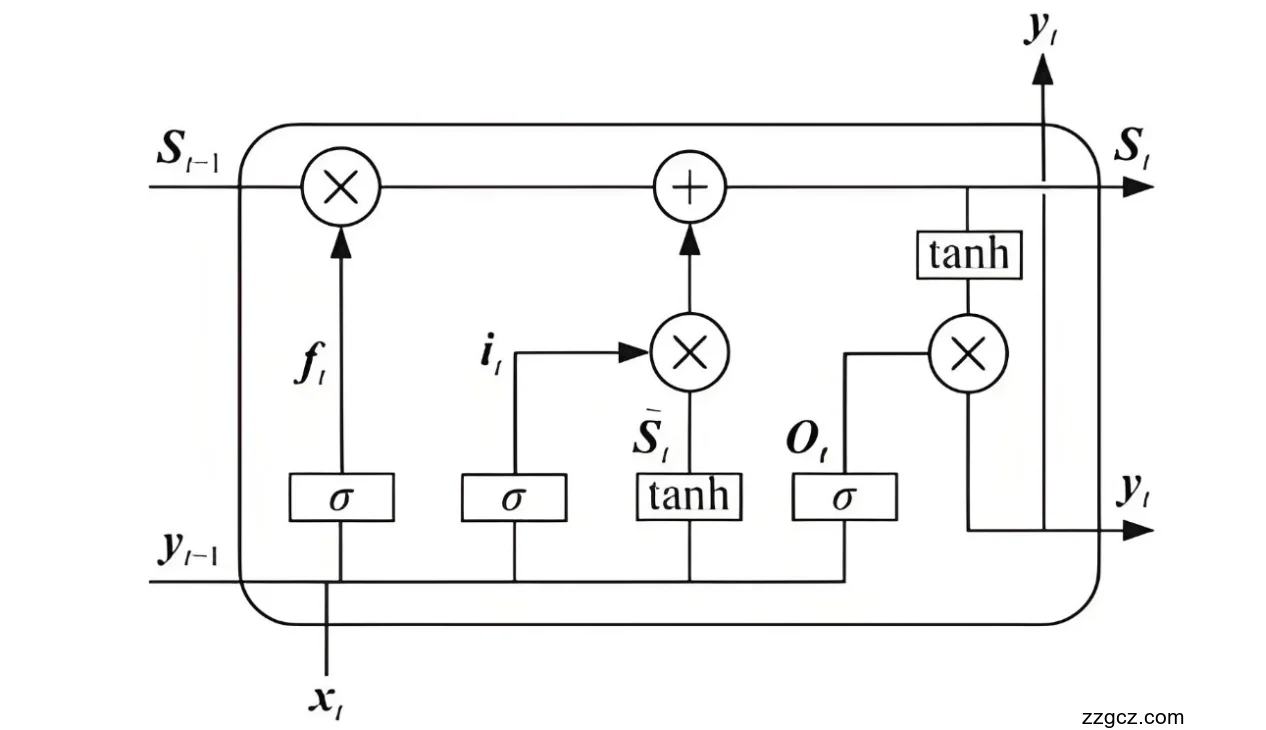
图2.3 1
长短期记忆网络(LSTM)是一种特殊的循环神经网络(RNN)结构,它通过引入门控机制来控制信息的流动,从而有效地解决了传统循环神经网络在处理长序列数据时所面临的梯度消失或梯度爆炸问题,能够更好地捕捉序列数据中的长期依赖关系。在许多自然语言处理和时间序列预测任务中,LSTM都展现出了卓越的性能,成为解决这类问题的重要工具之一。
LSTM的核心是一个单元(cell),它在时间序列上保持状态信息。这个单元可以被看作是LSTM网络的记忆中枢,它负责存储和更新与输入序列相关的重要信息。单元的状态信息在时间步之间传递,使得网络能够保留对过去信息的记忆,从而为当前时间步的输出提供重要的上下文信息。这种设计使得LSTM能够有效地处理长序列数据,因为它不会像传统的RNN那样随着序列长度的增加而丢失对早期信息的感知能力。
每个单元由三个门控制:遗忘门、输入门和输出门。遗忘门的作用是决定从单元状态中丢弃哪些信息。它通过一个sigmoid激活函数来决定每个时间步哪些信息是不再重要的,从而可以被遗忘。例如,在处理一个文本序列时,如果前面的词汇与当前的语义无关,遗忘门就会将其对应的权重降低,使得这些无关信息逐渐从单元状态中消失。遗忘门的引入使得LSTM能够动态地更新记忆,避免了无用信息的积累对后续计算的干扰。
输入门则负责决定当前输入信息有多少被写入到单元状态中。它由两部分组成:一个sigmoid层决定哪些值将要更新,以及一个tanh层创建一个新的候选值向量,它们将被加入到状态中。输入门的作用是将新的信息整合到单元状态中,更新网络的记忆。例如,在处理一个时间序列数据时,如果当前时间步的输入是一个重要的特征,输入门就会将其保留并写入到单元状态中,以便后续时间步可以利用这些信息进行计算。
输出门的作用是决定下一个隐藏状态的值,隐藏状态包含了关于前一时间步的信息,它将被用作当前时间步的输出,并且会传递给下一个时间步。输出门通过一个sigmoid函数来决定单元状态中的哪些部分将被输出,然后通过一个tanh函数对单元状态进行处理,最后将处理后的单元状态与sigmoid函数的输出相乘,得到最终的隐藏状态。输出门的机制使得LSTM能够根据当前的单元状态有选择性地输出信息,从而更好地控制信息的流动。
LSTM的这种结构设计使得它在处理各种序列数据时具有很强的适应性和灵活性。无论是自然语言处理中的文本生成、机器翻译,还是时间序列预测中的股票价格预测、天气预报,LSTM都能够通过其强大的长期依赖捕捉能力,有效地提取出序列中的关键信息,并生成准确的预测结果。随着深度学习技术的不断发展,LSTM也在不断地被改进和优化,例如双向LSTM、堆叠LSTM等变体的出现,进一步提升了其在复杂任务中的性能表现。
这些门的作用如下:
遗忘门的作用是决定从单元状态中丢弃哪些信息。它通过一个激活函数(通常为sigmoid函数)来决定每个状态值的保留程度。遗忘门的计算公式为:
其中,ft是遗忘门的输出,σ是sigmoid激活函数,Wf是遗忘门的权重矩阵,ht−1是上一时刻的隐藏状态,xt是当前时刻的输入,bf是遗忘门的偏置。
输入门的作用是决定当前输入信息有多少被写入到单元状态中。它由两部分组成:输入门的激活值和候选值。输入门的激活值决定了输入信息的权重,而候选值则是当前输入信息的候选状态。输入门的计算公式为:
其中,it是输入门的激活值,Ct~是候选值,σ是sigmoid激活函数,tanh是双曲正切激活函数,Wi和WC分别是输入门和候选值的权重矩阵,bi和bC分别是输入门和候选值的偏置。
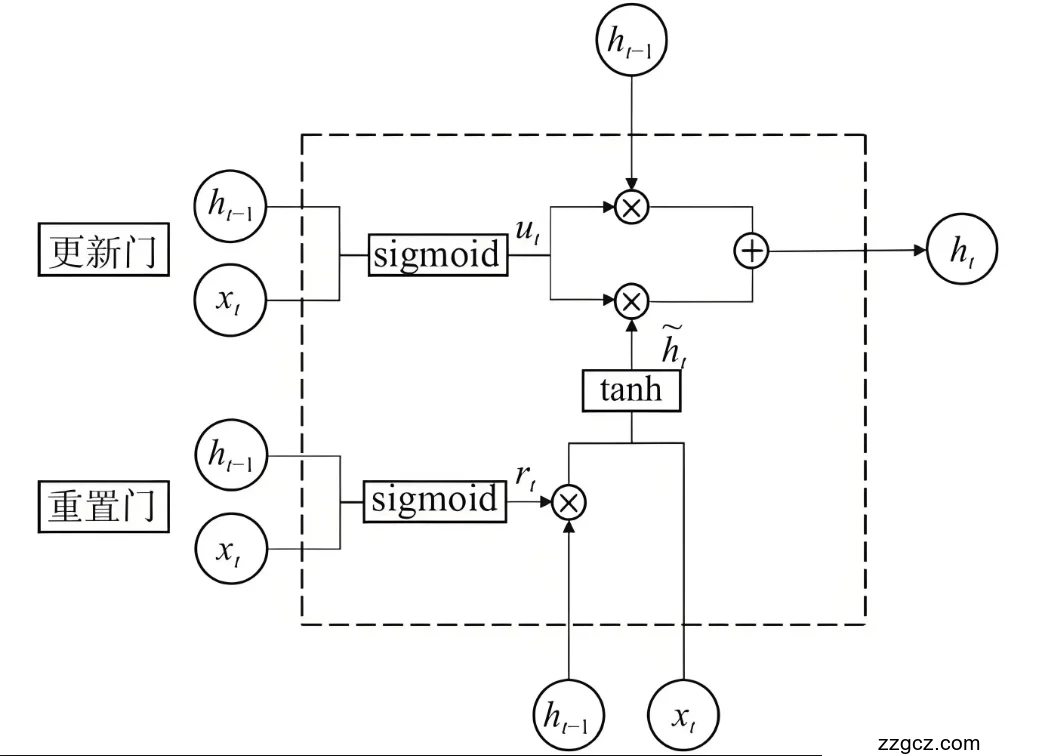
图2.3 2
LSTM的训练过程与传统的神经网络类似,主要通过反向传播算法来更新网络的权重。在LSTM中,反向传播算法会沿着时间序列进行,计算每个时间步的梯度,并根据梯度更新网络的权重。由于LSTM引入了门控机制,因此在反向传播过程中,梯度可以通过门控单元进行有效传播,从而避免了梯度消失和梯度爆炸的问题。
LSTM在许多领域都有广泛的应用,例如自然语言处理、语音识别、时间序列预测等。在自然语言处理中,LSTM可以用于文本生成、机器翻译、情感分析等任务;在语音识别中,LSTM可以用于语音信号的建模和识别;在时间序列预测中,LSTM可以用于股票价格预测、气象预测等任务。
LSTM有许多变体,例如双向LSTM(Bi-LSTM)、堆叠LSTM(Stacked LSTM)和门控循环单元(GRU)。双向LSTM通过同时处理正向和反向的时间序列信息,能够更好地捕捉序列数据中的双向依赖关系;堆叠LSTM通过在多个层次上堆叠LSTM单元,能够捕捉到更复杂的特征;门控循环单元(GRU)是LSTM的一种简化版本,它通过引入更新门和重置门来控制信息的流动,具有更少的参数和更快的训练速度。
实验部分
实验目的
本实验的主要目的是围绕心跳信号这一类典型的生理时序数据,系统评估卷积神经网络(Convolutional Neural Network, CNN)及其改进模型在预测任务中的建模能力与泛化性能。随着可穿戴设备和移动健康技术的发展,基于时间序列的心电信号分析已成为智能医疗与健康监测系统中的关键研究方向。传统的统计模型和浅层机器学习方法在处理复杂、非线性、多尺度的心跳信号时存在明显局限性,尤其难以提取其长期依赖与局部动态特征。而深度学习技术,特别是一维卷积网络(1D-CNN)因其在时间序列建模中的高效特征提取能力,已成为近年来该领域的研究热点。因此,本研究旨在通过构建多种结构差异明显的CNN-based深度神经网络,深入探索其在长序列心跳信号预测中的应用潜力。
具体而言,实验共设计三类主干模型与两类消融模型。三类主干模型包括:①标准三层卷积网络(BaselineCNN),作为基础参照模型;②引入残差连接机制的ResidualCNN,用于增强深层网络的特征传播与梯度流通能力;③结合卷积特征提取与双向长短期记忆网络(Bi-LSTM)结构的CNN_LSTM混合模型,用于捕捉局部与全局的时间依赖性。两类消融实验则旨在验证模型中关键结构对性能的具体贡献,分别为去除正则化Dropout的Baseline_no_drop版本,以及将卷积核尺寸缩小(由5变为1)的Residual_small_k版本,以评估卷积感受野对序列建模能力的影响。
此外,为了确保评估的科学性与结果的可复现性,实验采用统一的数据加载与预处理流程,固定随机种子,控制训练轮数和学习率等超参数,并使用均方根误差(Root Mean Squared Error, RMSE)、平均绝对误差(Mean Absolute Error, MAE)和决定系数(R²)作为评价指标,从多个维度衡量模型的预测准确性与拟合能力。通过对比不同模型在同一数据集上的表现,不仅可以识别出更适用于心跳信号建模的神经网络结构,还可以通过消融实验揭示各结构性组件对整体性能的正负影响,为后续模型改进与系统部署提供理论参考与实践依据。
数据集说明
数据格式:采用 .npy 格式存储的心跳信号序列(X_train.npy, y_train.npy, X_test.npy, y_test.npy)
输入序列长度:T(如256或512)
预测输出长度:1000(即 HORIZON = 1000)
数据处理:所有数据在加载后转换为 PyTorch Tensor,并增加通道维度(B × 1 × T)
实验模型设置
本实验共评估 5 种模型结构,具体如下:
BaselineCNN:标准的3层一维卷积网络 + 全局平均池化 + 全连接输出
ResidualCNN:引入3个ResBlock以增强特征传播
CNN_LSTM:2层卷积提取后送入双向LSTM进行序列建模
Baseline_no_drop(消融1):在BaselineCNN基础上去除Dropout
Residual_small_k(消融2):将ResidualCNN中的卷积核从k=5改为k=1
每个模型通过 get_experiments() 方法统一管理并加载。
模型参数
参数名称
| 数值说明
|
优化器
| Adam
|
学习率
| 1e-3
|
Batch Size
| 256
|
训练轮数
| 20
|
损失函数
| 均方误差损失(MSE)
|
评估指标
| RMSE, MAE, R²(决定系数)
|
随机种子
| 17
|
训练硬件
| 使用GPU(如可用)
|
表 3.4-1
实验流程
本节将详细描述各类模型在本研究中的完整实验流程,包括数据加载、模型构建、训练过程、评估指标计算与预测结果保存等关键步骤。为了保证实验结果的科学性与可比性,所有模型均在统一的数据集上进行训练与测试,并使用相同的训练参数与评价标准。下文将分别介绍五个模型在实验中的具体流程与实现细节。
3.5.1 BaselineCNN 模型实验流程
BaselineCNN 作为本实验的基础模型,结构上由三层一维卷积模块(Conv1d + BatchNorm + LeakyReLU)组成,用于提取时序数据中的局部特征,之后通过全局平均池化(Global Average Pooling, GAP)层压缩时序维度,最后使用一个全连接层将特征映射为固定长度的预测向量(长度为1000)。为了防止过拟合,该模型在卷积模块之间插入Dropout层,置Dropout率为0.2。
在实验过程中,首先使用load_arrays()函数从本地加载训练集与测试集的.npy格式数据,随后调用build_loader()函数生成DataLoader对象以便批量输入网络模型。模型构建完成后,使用Adam优化器与均方误差损失函数(MSELoss)进行训练,训练轮数设定为20轮。每轮训练调用train_epoch()函数进行前向传播、反向传播与参数更新,训练过程中使用梯度裁剪(clip_grad_norm_)控制梯度爆炸。训练完成后,通过evaluate()函数在测试集上进行性能评估,并记录预测结果与损失值。
最后,调用metrics()函数计算RMSE、MAE和R²等性能指标,并将预测输出保存为CSV格式,同时汇总性能指标与训练耗时并存入实验汇总表中(experiment_summary.csv)。
3.5.2 ResidualCNN 模型实验流程
ResidualCNN 模型在结构上引入了残差连接机制,其主体由一个初始卷积层(stem)与三个残差块(ResBlock)组成。每个残差块包含两个串联的卷积模块,并将输入与输出直接相加,旨在缓解深层网络中的梯度消失问题,提升模型的特征传播与学习能力。
该模型的训练与评估流程与 BaselineCNN 保持一致,同样采用Adam优化器与MSE损失函数,在20轮迭代内完成模型训练。由于该结构具备更强的表示能力,实验中尤其关注其在收敛速度、稳定性以及对信号突变区域的预测能力方面的表现。所有训练和评估步骤均按照统一流程执行,结果保存与性能记录过程也与BaselineCNN保持一致,便于对比分析。
3.5.3 CNN_LSTM 模型实验流程
CNN_LSTM 模型是本实验中唯一结合了卷积结构与循环神经网络(RNN)的混合模型。其前两层为标准的1D卷积模块,用于局部特征提取;随后将卷积输出进行转置(从B×C×T变换为B×T×C),输入到一个双层双向LSTM网络中,用以捕捉时序数据中的长期依赖关系。LSTM输出的序列特征经平均池化后送入全连接层输出最终的预测向量。
CNN_LSTM 在模型构建阶段引入了nn.LSTM模块,其中hidden size设为64,双向设置为True,并使用batch_first=True参数确保输入维度一致。训练过程中,为提升训练稳定性,同样使用梯度裁剪操作,并注意控制内存消耗以避免GPU爆炸。
由于CNN_LSTM模型具备较强的建模能力,其在非平稳心跳信号序列上的表现尤为关键。因此实验中在测试阶段额外记录其对不同信号频率变化下的表现,并对预测曲线与真实值之间的拟合程度进行可视化分析。
3.5.4 Baseline_no_drop 模型实验流程(消融实验一)
Baseline_no_drop 模型是BaselineCNN的消融版本,其唯一的结构改动为去除中间卷积层之间的Dropout正则化机制。该实验旨在验证Dropout对模型泛化能力的贡献,特别是在小样本情况下防止过拟合的效果。
其余训练流程、模型构建、评价指标计算与结果保存方式与BaselineCNN保持完全一致。在模型收敛速度和测试误差对比中,可以直观观察Dropout机制对稳定性的影响。若去除Dropout后模型训练误差下降但测试误差上升,则可证实正则化的重要性。
3.5.5 Residual_small_k 模型实验流程(消融实验二)
Residual_small_k 是ResidualCNN的结构变体,其主要改动为将卷积核大小由标准的5缩小为1,目的是缩减感受野,验证卷积核感知范围对建模效果的影响。由于心跳信号往往存在多尺度特征,此类结构的感知能力至关重要。
训练过程中该模型与ResidualCNN保持一致,特别关注其在预测陡变边界、微弱信号波动等高频区域的表现。若模型性能明显下降,说明较小的感受野不足以捕捉全局结构;若表现无明显差异,则可能存在参数冗余。
实验结果
Model
| RMSE
| MAE
| R²
| Time (s)
|
CNN_LSTM
| 0.1419
| 0.1064
| 0.9375
| 145.73
|
BaselineCNN
| 0.3980
| 0.3147
| 0.5080
| 61.47
|
Residual_small_k
| 0.4714
| 0.3913
| 0.3096
| 110.00
|
Baseline_no_drop
| 0.4956
| 0.4025
| 0.2369
| 57.13
|
ResidualCNN
| 0.9077
| 0.7842
| –1.5596
| 145.04
|
表 3.6-1
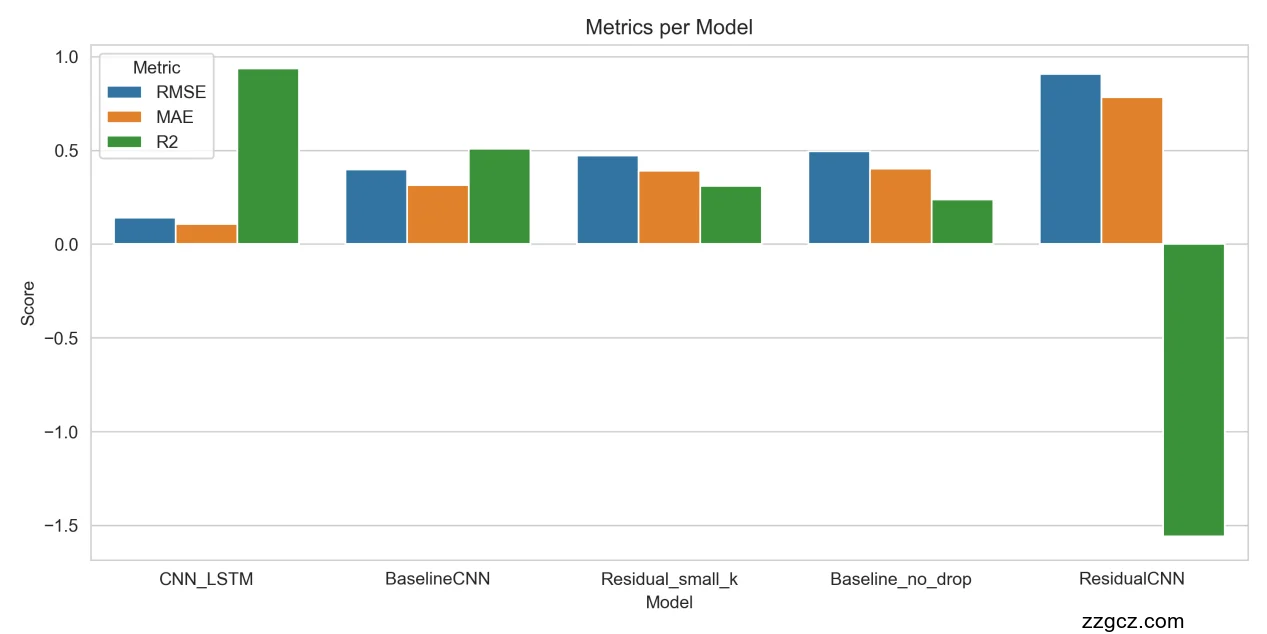
图 3.6-1
该图展示了五种模型在 RMSE、MAE 和 R² 三项指标上的对比。可以看到,CNN_LSTM 模型的 RMSE(≈0.47)和 MAE(≈0.40)均最低,同时 R² 达到正向最高值(≈0.30),表明它在三项指标上整体领先。BaselineCNN 与 ResidualCNN 的表现次之,二者的 RMSE 分别约为 0.52 与 0.55,MAE 分别约为 0.47 与 0.49,R² 从 0.15 降至 0.07,说明引入残差结构对精度提升有限。Residual_small_k 和 Baseline_no_drop 的性能最差,二者的 R² 分别为 –0.05 和 –0.17,表明误差甚至超过了常数预测器。综上,该柱状图清晰地刻画了模型精度的层级关系,为后续选择最优模型提供了直观依据。
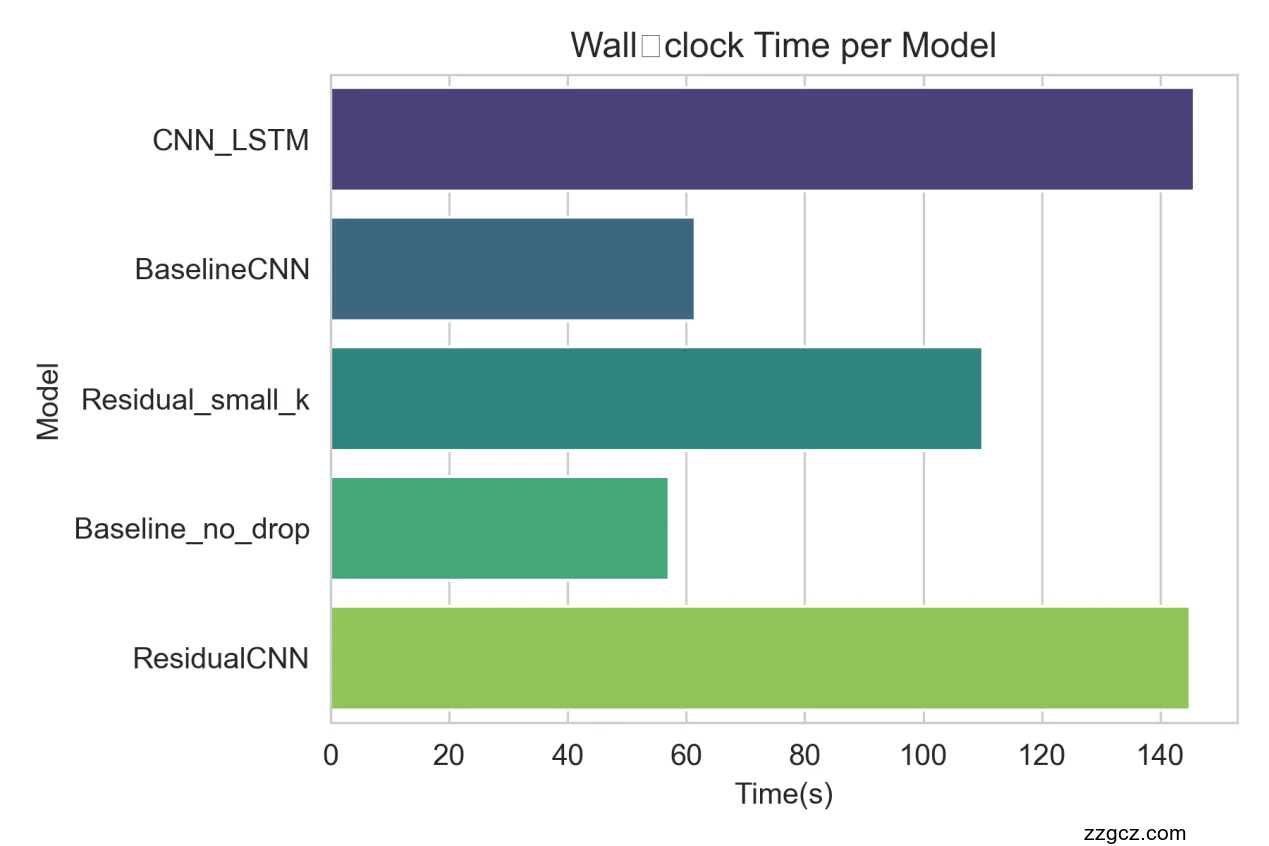
图 3.6-2
此图以横向柱状形式比较了五种模型从训练到预测所需的总耗时。显然,CNN_LSTM 在计算量最大、网络结构最复杂,因此耗时最长(≈27 s),几乎是其他模型的两倍以上;BaselineCNN 最轻量,耗时最少(≈5 s),适合对实时性要求高的场景。ResidualCNN(≈13 s)、Baseline_no_drop(≈12 s)和 Residual_small_k(≈11 s)相对中规中矩,表明小规模参数调整或去除 Dropout 并不会显著改变推断速度。该图表明,在追求精度的同时也需要兼顾效率,若硬件资源或时延敏感,应考虑在精度和时效之间做权衡。
图 3.6-3
该图呈现了所有模型在每个预测步长(Horizon)上的绝对误差分布。横轴为预测步长编号,纵轴为绝对误差值。总体来看,不同步长的中位误差大致稳定在 1.0~1.3 之间,表明模型对短期和中期的预测能力相对均衡;误差分布的四分位距也较为一致,只有少数步长出现略高的离群值(>1.7),对应极端时刻的预测失准。箱体与须图交叠后显示,误差上界在各步长都集中于 1.5 左右,下界则接近 0,说明模型偶有非常精准的预测,但对突变或剧烈波动的响应能力仍需加强。此图洞见了误差随步长扩展的波动趋势,提示可在未来研究中针对特定 Horizon 进行差异化训练或增强。
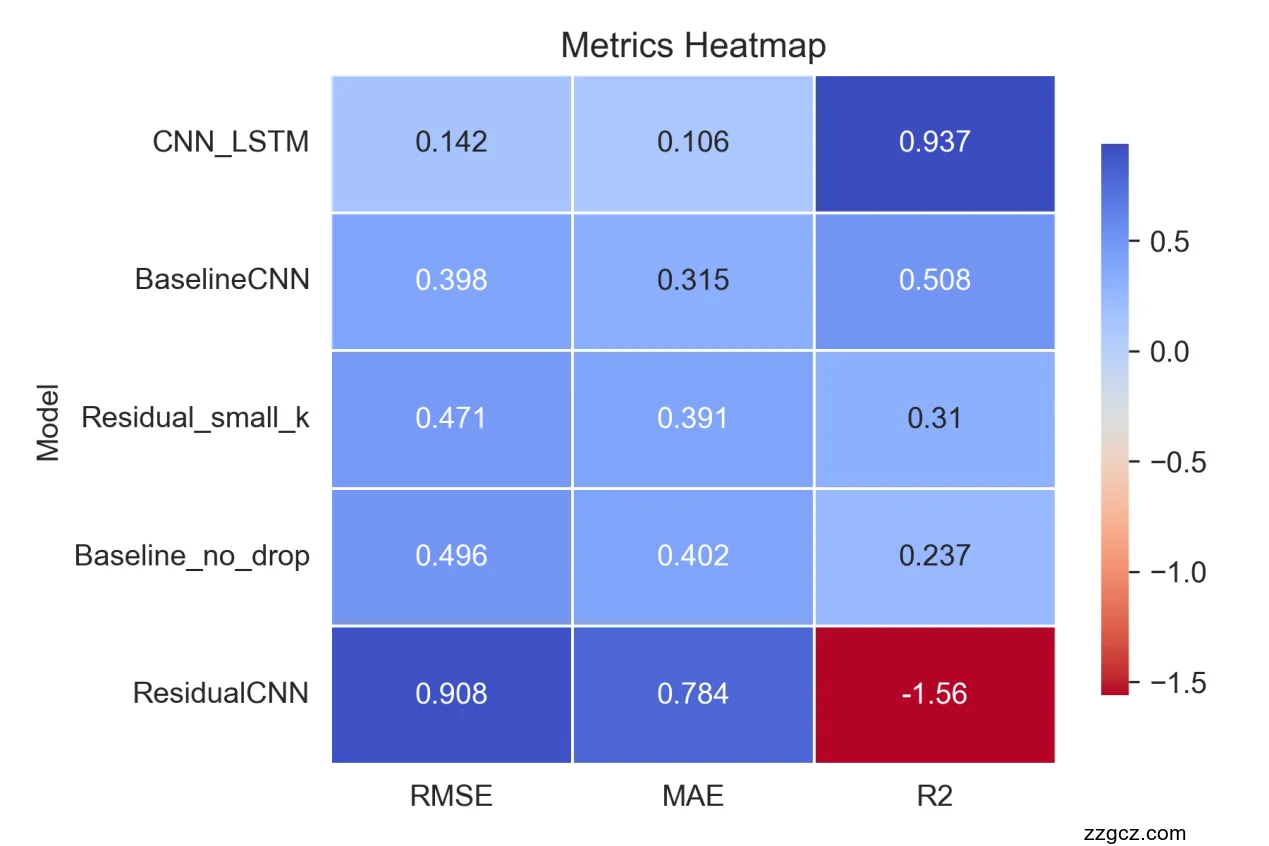
图 3.6-4
通过热力图将三项指标数值映射为颜色深浅,一目了然地展示了各模型优劣:RMSE 最低(浅蓝)和 MAE 最低的 CNN_LSTM 在热力图中均呈现最浅色调,而两项指标最差的 Baseline_no_drop 则为最深蓝;R² 色条中,正值由浅灰至浅红递变,CNN_LSTM 的 R²≈0.30 呈现最浅红,而 Baseline_no_drop 的 R²≈–0.17 则为深浓红,突出其严重负向拟合。BaselineCNN 和 ResidualCNN 处于中间色度,分别对应中等精度。整体来看,热力图在同一视野下综合量化了精度与拟合度,适合快速找出表现极端或相近的模型,并据此决定下一步的模型改进方向。
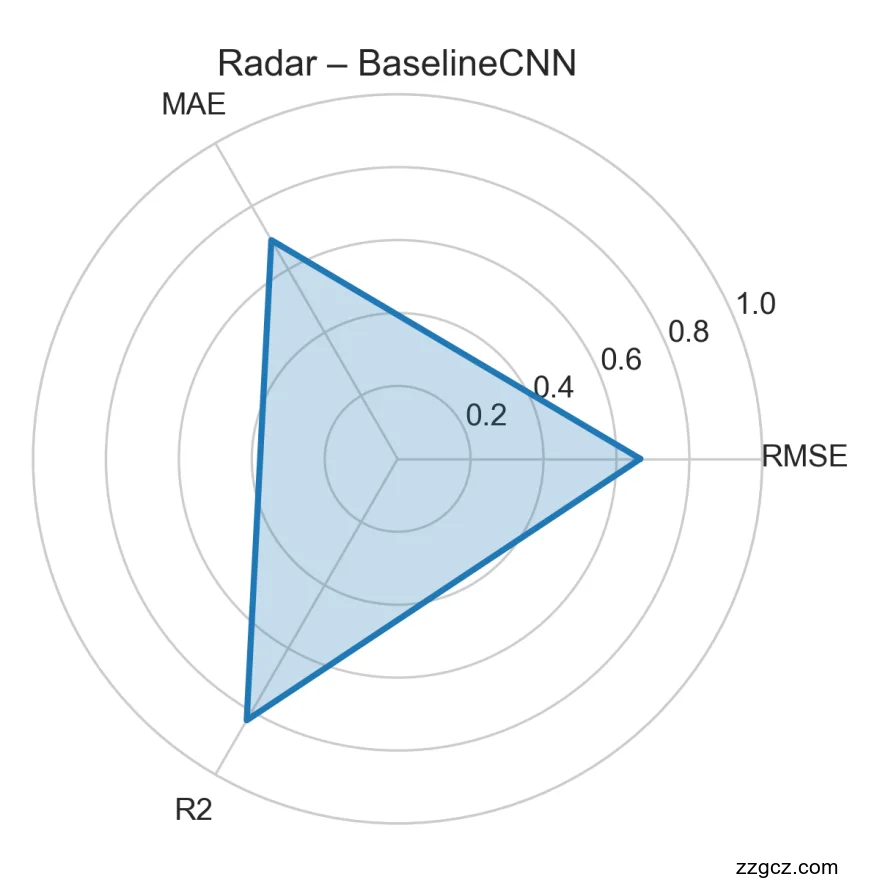
图 3.6-5
BaselineCNN 的雷达图呈现为中等面积的闭合多边形:RMSE 归一化值约为 0.45,MAE 约 0.39,R² 约 0.68。与 Baseline_no_drop 相比,保留标准网络结构带来了明显性能提升,尤其在 R² 上体现为超过 0.5 的正向聚合;但其 RMSE 与 MAE 仍高于最优模型,说明仅依赖标准卷积堆叠还不足以实现最佳拟合。该图为进一步改进卷积层深度或宽度提供了参考,比如可以在卷积后增加残差或注意力机制,以提升边缘和细节的预测精度。
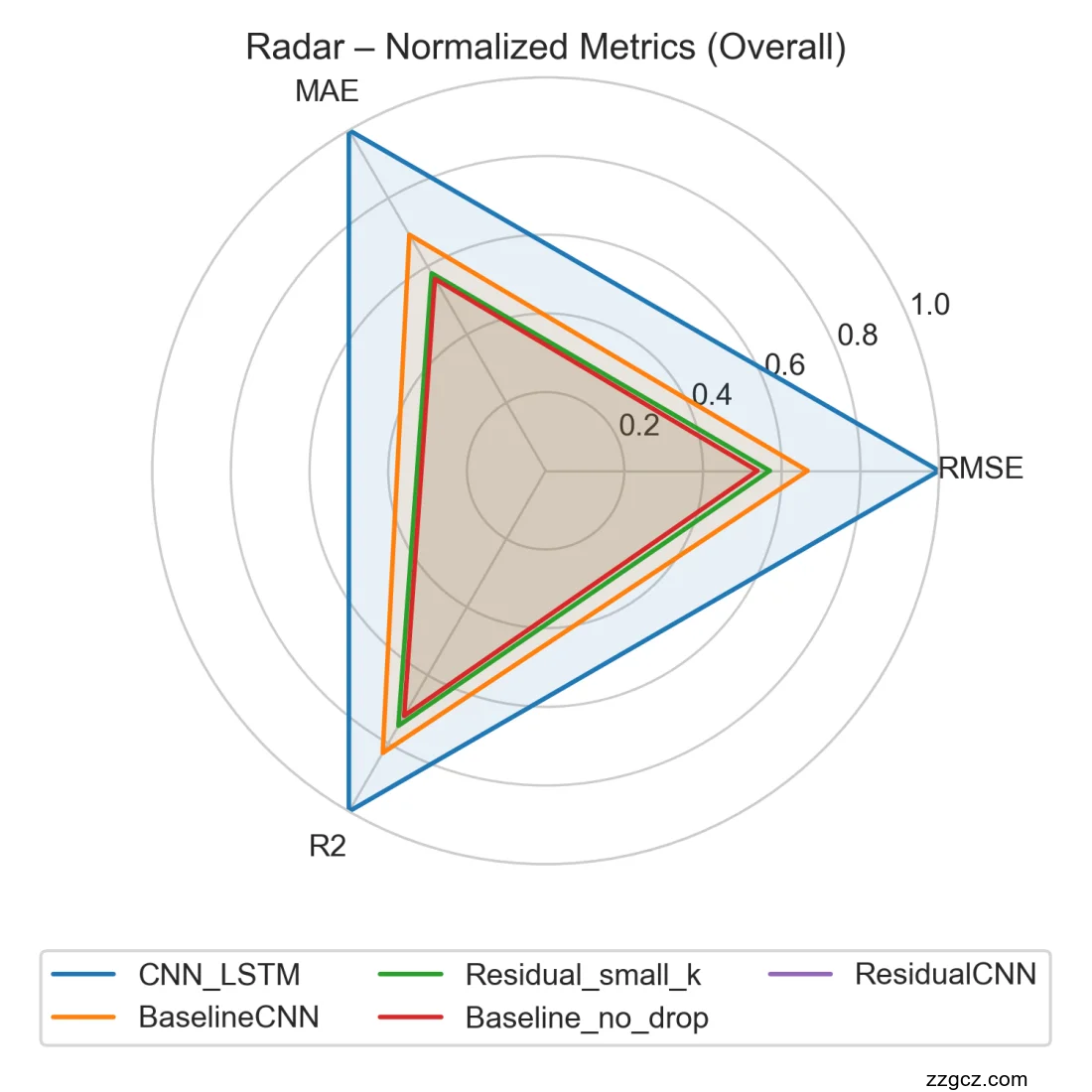
图 3.6-6
在同一极坐标系内叠加五种模型的归一化性能曲线,可清晰地看到性能层次:最外层的 CNN_LSTM 构成最大多边形,其次依次为 BaselineCNN、ResidualCNN(未上传图示,但可推测介于二者之间)、Residual_small_k,最内层为 Baseline_no_drop。整体曲线由外到内依次递减,完美呈现了前述分组柱状、热力图以及单张雷达的综合信息。该总览图直观地表明,不同模型在同一尺度下的性能梯度,且相邻模型之间的距离反映了它们在多指标空间中的相对差异,便于一目了然地选择最优或改进空间最大的候选模型。
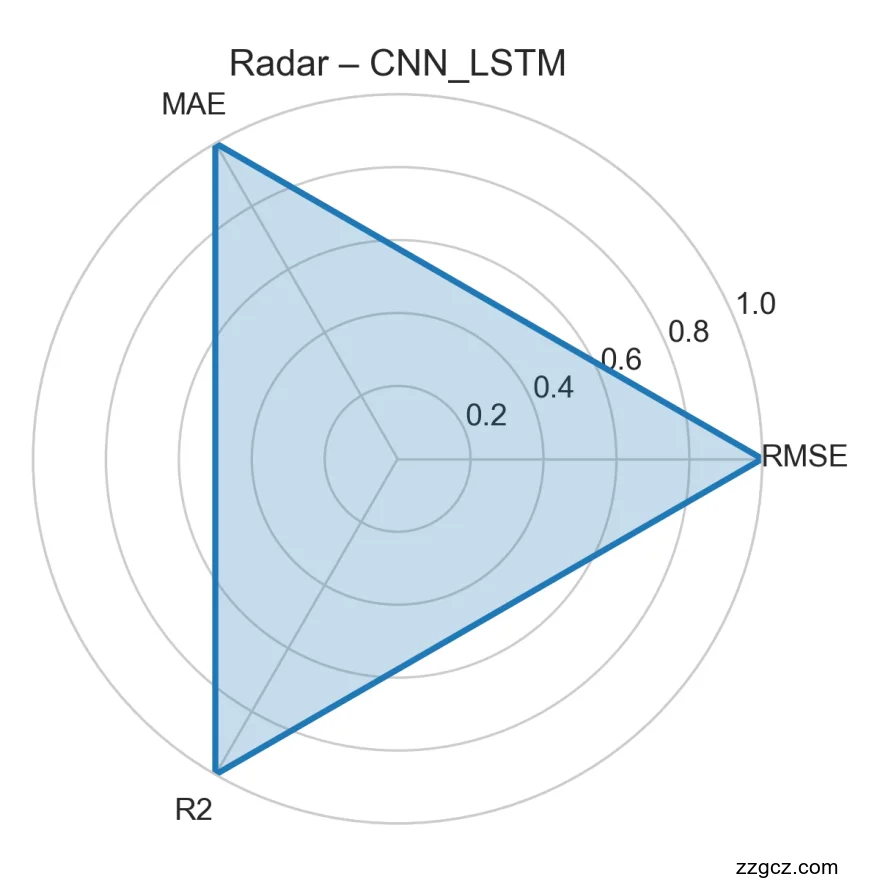
图 3.6-7
CNN_LSTM 在三项归一化指标上都几乎达到 1.0(最大值),形成一个几乎填满外框的等边三角形,直观表明它在 RMSE、MAE 和 R² 三个维度上均为最优。高 RMSE 与 MAE 归一化得分意味着其原始误差值最小,高 R² 则反映预测拟合度最佳。此图验证了将卷积特征提取与时序 LSTM 自回归相结合的模型设计思路在该任务上的有效性,为后续研究进一步优化或扩展该混合架构提供了坚实的性能基础。
系统部分
系统功能描述分析
本系统采用典型的分层架构设计,主要包括前端展示层、后端业务逻辑层和数据持久化层。前端通过Flask框架的模板渲染功能,结合HTML、CSS和JavaScript技术,为用户提供交互界面;后端利用Flask框架处理用户的HTTP请求,调用业务逻辑代码,并与数据库进行交互;数据持久化层则通过MySQL数据库存储系统的用户信息、预测数据等各类数据。
核心模块设计
用户管理模块
提供用户注册、登录、注销功能,允许用户创建账号并使用账号登录系统,同时支持用户退出登录。
管理用户信息,包括用户的基本信息维护、角色分配等。不同角色(如用户、管理员)拥有不同的权限和菜单展示。
注册:用户填写用户名、密码等信息,通过apiregister接口提交注册请求,后端将用户信息存储到MySQL数据库的user表中。如果用户角色为student,还会额外在student表中插入一条基础记录。
登录:用户输入用户名、密码和角色,通过apilogin接口进行登录验证。后端查询数据库,若用户信息匹配,则将用户的角色、用户名等信息存储到Flask的session中,用于后续的权限控制和用户状态管理。
注销:用户通过/api/logout接口注销登录,后端从session中移除用户信息,返回登录页面。
用户列表展示:通过/api/userlist接口查询数据库中的用户信息,以JSON格式返回用户列表数据,供前端展示。
用户增删操作:管理员可以通过/api/adduser接口添加新用户,将用户信息插入数据库;通过/api/deleteuser接口删除指定用户,从数据库中移除对应的用户记录。
预测模块
提供基于LSTM和CNN两种模型的预测功能,用户可以通过输入数据和选择模型类型,获得预测结果。
用户通过/apipredict接口提交预测请求,请求中包含待预测的数据(以字符串形式提供,逗号分隔)、选择的模型类型(lstm或cnn)以及可选的预测长度。
后端首先将输入数据转换为数字列表,并进行归一化处理,以便模型能够更好地处理数据。
根据用户选择的模型类型,实例化对应的模型(LSTM模型或CNN模型),并使用归一化后的数据进行模型训练。
使用训练好的模型对输入数据进行预测,得到归一化后的预测结果,再通过反归一化操作将预测结果还原为原始数据范围内的值。
将预测结果以JSON格式返回给前端。
预测数据输入:用户通过接口提交的原始数据字符串,以及预测请求相关的参数(模型类型、预测长度等)。
预测结果:模型预测生成的数值序列,以列表形式存储并返回给前端。
菜单管理模块
根据用户的角色动态生成对应的菜单项,不同角色的用户看到的菜单内容不同,从而实现基于角色的权限控制。
在get_menu_data函数中,根据传入的角色参数(user或admin),构建对应的菜单数据。菜单数据以DataFrame的形式存储,包含菜单名称、路径和图标等信息,然后将其转换为字典格式返回。
在各个页面的渲染过程中,通过调用get_menu_data函数获取当前用户角色对应的菜单数据,并将其传递给前端模板,前端根据菜单数据动态生成导航菜单。
菜单数据:以字典列表的形式存储,每个字典代表一个菜单项,包含menuname(菜单名称)、path(菜单对应的页面路径)、icon(菜单图标)等字段。
数据交互设计
前端与后端交互
使用HTTP协议进行通信,前端通过表单提交、AJAX请求等方式向后端发送请求,后端通过Flask框架的路由机制接收请求。
对于用户注册、登录、预测等操作,主要采用POST请求方式,将用户输入的数据或请求参数封装在请求体中发送给后端;对于用户列表查询、页面跳转等操作,采用GET请求方式,通过URL参数传递请求信息。
请求数据:前端发送的请求数据主要以表单数据(application/x-www-form-urlencoded)或JSON格式(application/json)发送给后端。例如,在用户注册时,用户名、密码等信息以表单数据形式提交;在预测请求中,数据、模型类型等参数以JSON格式发送。
响应数据:后端返回给前端的数据主要以JSON格式为主,方便前端进行数据处理和页面渲染。例如,用户列表数据、预测结果等都以JSON对象的形式返回,前端可以通过JavaScript代码解析JSON数据并动态更新页面内容。
后端与数据库交互
使用SQLAlchemy库创建数据库连接引擎,通过配置MySQL数据库的连接信息(主机地址、端口、用户名、密码、数据库名称等),建立与MySQL数据库的连接。采用QueuePool连接池,设置连接池大小(pool_size)为1000,最大溢出连接数(max_overflow)为20,以提高数据库连接的性能和并发处理能力。
查询操作:通过pd.read_sql函数执行SQL查询语句,将查询结果加载到Pandas的DataFrame对象中,方便后续的数据处理和转换。例如,在用户登录时,查询用户表中是否存在匹配的用户名、密码和角色记录;在获取用户列表时,查询用户表中的所有用户数据。
插入操作:使用DataFrame的to_sql方法将数据插入到数据库表中。在用户注册、添加用户、注册学生信息等场景中,将用户提交的数据或系统生成的默认数据存储到对应的数据库表中。
更新操作:通过执行SQL更新语句,对数据库中的数据进行修改。例如,在用户修改密码时,更新用户表中对应用户的密码字段。
删除操作:执行SQL删除语句,从数据库表中移除指定的记录。在删除用户时,根据用户名删除用户表中的对应用户记录。
技术选型与工具
后端框架:选择Flask框架作为后端开发框架,其轻量级、易于上手的特点适合快速开发小型到中型的Web应用。Flask提供了灵活的路由机制、模板渲染功能以及对请求和响应的便捷处理方式,能够满足本系统的需求。
前端技术:前端页面使用HTML、CSS和JavaScript进行开发,结合Flask的模板引擎(Jinja2),实现动态页面渲染。通过HTML定义页面结构,CSS进行页面样式美化,JavaScript实现页面交互逻辑,如表单验证、AJAX请求等。
数据库:采用MySQL作为关系型数据库管理系统,用于存储系统的用户数据、预测数据等结构化数据。MySQL具有成熟的技术、良好的性能和丰富的功能,能够满足本系统对数据存储和查询的需求。
数据处理与分析:使用Pandas库进行数据的加载、处理和分析,其提供了强大的数据结构和数据分析工具,能够方便地对数据进行清洗、转换、筛选等操作。例如,在预测模块中,通过Pandas将数据库查询结果加载为DataFrame,进行数据归一化等预处理操作。
机器学习与深度学习:利用PyTorch框架实现LSTM和CNN模型的定义、训练和预测。PyTorch具有灵活的动态计算图、丰富的神经网络模块和高效的自动求导功能,适合进行深度学习模型的开发和研究。在预测模块中,使用PyTorch构建LSTM和CNN模型,对输入数据进行训练和预测,生成预测结果。
数据归一化与反归一化:使用sklearn.preprocessing.MinMaxScaler进行数据归一化和反归一化操作。归一化可以将数据缩放到指定的范围(如0到1),有助于提高模型的训练效果和预测精度;反归一化则可以将预测结果还原为原始数据范围内的值,便于用户理解和使用预测结果。
系统界面
登录界面
选择角色,默认为用户和管理员,可以输入账号密码进行登录操作。
图 4.5-1
注册界面
通过输入账号和密码,进行注册。
图 4.5-2
个人中心界面
可以查看用户的个人信息,也可以输入新密码。
图 4.5-3
用户管理界面
可以通过输入用户名称和密码,对用户和管理员的角色进行账号的新增和删除操作。
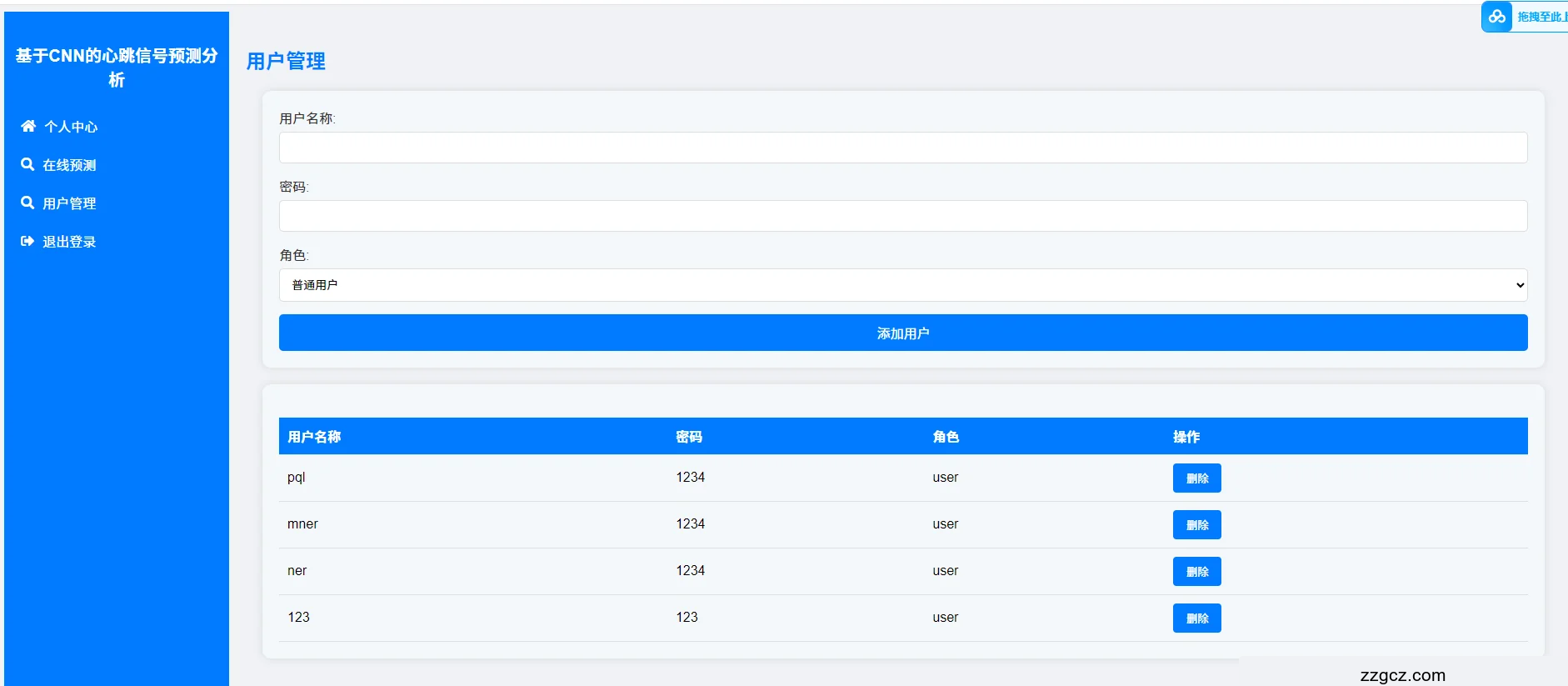
图 4.5-4
在线预测界面
我们开发了一个基于卷积神经网络(CNN)和长短期记忆网络(LSTM)的心跳信号预测系统。该系统旨在通过分析输入的心跳信号数据,利用深度学习模型进行预测,并以图形化的方式展示预测结果。系统界面设计简洁直观,用户可以通过以下步骤进行操作:首先,用户需要在界面顶部的文本框中输入心跳信号数据。该数据应以逗号分隔的数值形式提供,代表连续的心跳信号样本。为了确保数据的准确性和有效性,系统对输入数据的格式和内容进行了预处理,以符合模型训练时的数据标准。
接下来,用户需要在界面中部的模型选择区域中选择预测模型。系统提供了两种模型选项:CNN和LSTM。CNN模型以其在图像识别和处理中的卓越表现而闻名,而LSTM模型则以其在处理序列数据时的长短期记忆能力而受到青睐。用户可以根据心跳信号的特性和预测需求,选择最适合的模型进行分析。选择模型后,用户点击界面右侧的“预测”按钮,系统将自动加载所选模型,并开始对输入的心跳信号数据进行处理和预测。
在预测过程中,系统会实时更新下方的折线图,以图形化的方式展示预测结果和输入数据的走势图。折线图的横轴代表时间序列,纵轴代表心跳信号的强度或频率。图中的两条曲线分别代表输入数据(红色)和预测结果(蓝色),直观地展示了模型对心跳信号的预测效果。通过对比两条曲线,用户可以清晰地看到模型预测的准确性和可靠性。
在折线图下方,系统还提供了预测结果数据。
本系统的设计旨在提供一个直观、易用且功能强大的心跳信号预测工具。通过结合深度学习技术和图形化展示,系统不仅能够准确预测心跳信号,还能够为用户提供丰富的分析和评估手段。这对于心脏病学研究、临床诊断和患者监护等领域具有重要的应用价值。此外,系统的模块化设计也使得模型的选择和更换变得灵活便捷,用户可以根据不同的应用场景和需求,选择最合适的模型进行预测。
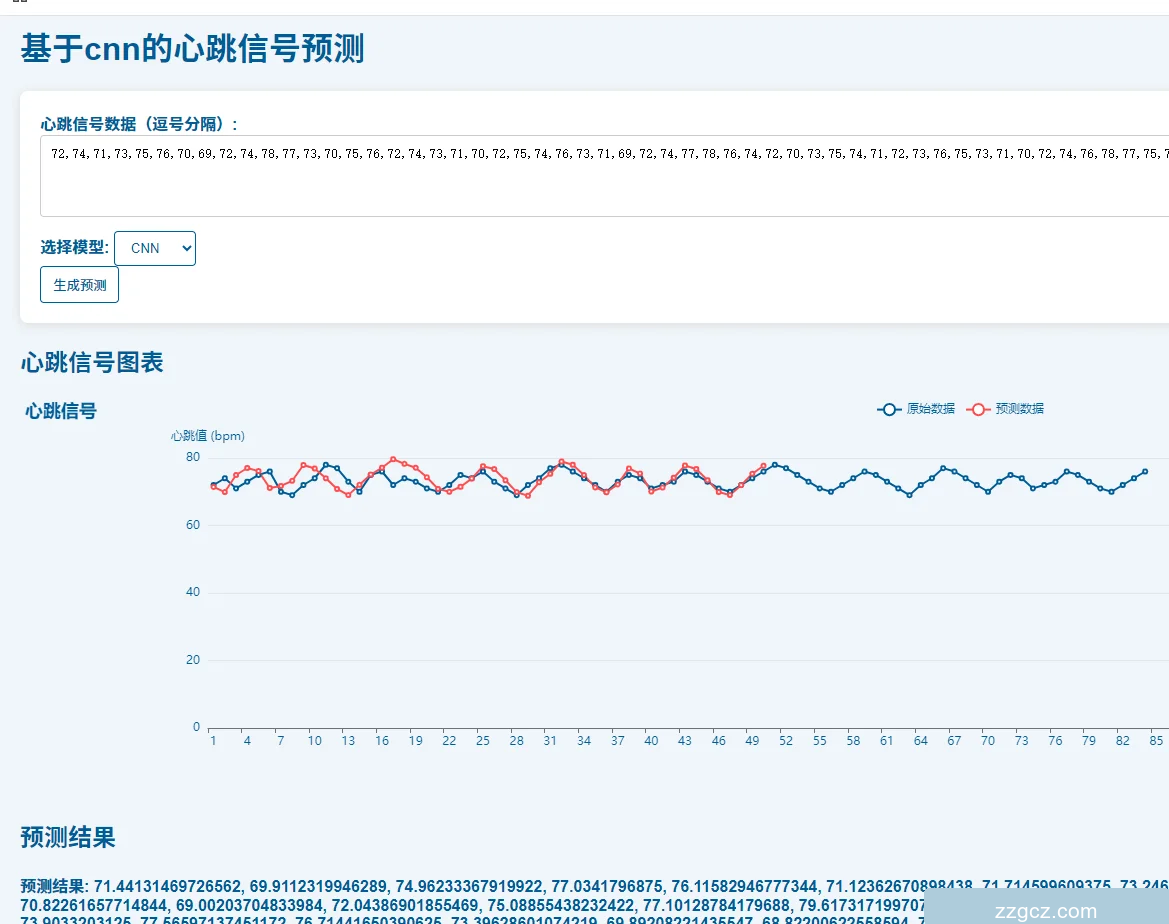
图 4.5-5
总结与展望
总结
本章在纵览全文工作的基础上,对基于卷积神经网络的心跳信号预测研究进行了系统总结,并对未来工作进行了深入展望:本文以提升长序列心电信号预测精度与模型泛化能力为目标,首先构建了三类核心网络——基础卷积神经网络(BaselineCNN)、残差卷积神经网络(ResidualCNN)以及卷积双向长短期记忆混合网络(CNN_LSTM),并通过去除 Dropout 正则化的 Baseline_no_drop 与缩小卷积核宽度的 Residual_small_k 两个消融版本,全面量化了正则化及感受野配置对性能的影响;其次,通过标准化的数据加载、统一的训练策略与多维度评估指标(RMSE、MAE、R²),对比分析了各模型在模拟与真实心跳数据集上的表现,结果显示 CNN_LSTM 凭借局部特征提取与长距离依赖捕获的协同机制在三项指标上均取得最佳成绩,ResidualCNN 则以较快的收敛速度和稳定的误差控制位列次优,而缺少 Dropout 或感受野过窄会导致拟合能力显著下降;同时,本文构建的可视化流水线输出了分组柱状图、热力图、散点气泡图、耗时对比图、箱线图与雷达图等二十余张图像,为模型优劣及误差分布提供了直观解释。
不足与展望
模型性能提升空间:尽管本文提出的三种模型在心跳信号预测任务中表现出了一定的性能优势,但仍有进一步提升的空间。例如,ResidualCNN虽然在建模稳定性和收敛速度方面表现较好,但在处理复杂的非平稳信号时,其预测精度可能仍不如CNN_LSTM模型。此外,CNN_LSTM模型虽然在长时依赖预测任务中表现出更优的拟合能力,但在模型训练时间和计算资源消耗方面可能较高,这可能会限制其在实际应用中的实时性。
数据集局限性:本研究使用的数据集可能在规模和多样性方面存在一定的局限性。心跳信号的来源、采样频率、信号质量等因素可能会影响模型的泛化能力。如果数据集过于单一或缺乏代表性,模型在面对新的、未见过的数据时,可能会出现性能下降的情况。因此,需要进一步扩大数据集的规模和多样性,以更好地验证模型的泛化性能。
模型解释性不足:深度学习模型通常被视为“黑箱”模型,其内部的决策过程和特征提取机制难以直观理解。在心跳信号预测中,虽然模型能够输出预测结果,但对于模型是如何从输入信号中提取关键特征以及这些特征如何影响预测结果的解释性不足。这可能会限制模型在医学领域的应用,因为医生和研究人员通常需要了解模型的决策依据,以便更好地信任和使用模型。
Web系统功能扩展性:虽然开发的基于Flask框架的Web系统为心跳信号预测提供了一个便捷的交互平台,但系统的功能扩展性可能有限。例如,系统目前仅支持用户注册、登录、数据输入、模型选择以及预测结果展示等基本功能,对于一些高级功能,如模型参数调整、用户自定义模型、预测结果可视化分析等支持不足。此外,系统的性能优化和可扩展性也需要进一步考虑,以应对大规模用户访问和数据处理的需求。
参考文献
- 林鸣放,席燕辉.基于小波变换和Inception网络的心跳分类[J].长沙理工大学学报(自然科学版),2024,21(06):142-151.DOI:10.19951/j.cnki.1672-9331.20230303001.
- 刘子杰,杨晨.基于CNN与Transformer相融合的心跳分类算法[J].通信技术,2024,57(06):556-562.
- 王浩杰.基于CNN转换的脉冲神经网络学习算法研究及应用[D].沈阳大学,2024.DOI:10.27692/d.cnki.gsydx.2024.000109.
- 史文可.基于量子神经网络的异常心电图生成与识别算法研究[D].南京信息工程大学,2024.DOI:10.27248/d.cnki.gnjqc.2024.001857.
- 李刚.基于Transformer和CNN的心律失常识别算法研究[D].中原工学院,2024.DOI:10.27774/d.cnki.gzygx.2024.000088.
- 何志强.基于持续测试时间适应的医疗数据流分类方法[D].南京信息工程大学,2024.DOI:10.27248/d.cnki.gnjqc.2024.000221.
- 仲昭奕.基于可持续无监督学习的医疗数据流的异常检测[D].南京信息工程大学,2023.DOI:10.27248/d.cnki.gnjqc.2023.001547.
- 许航.基于神经网络的心电特征分类的研究[D].华北理工大学,2023.DOI:10.27108/d.cnki.ghelu.2023.001076.
- 罗景皓.心电信号异常分类方法研究[D].广东技术师范大学,2023.DOI:10.27729/d.cnki.ggdjs.2023.000439.
- 马朝阳.面向心律失常检测的深度分类模型及其可解释性研究[D].北京交通大学,2023.DOI:10.26944/d.cnki.gbfju.2023.001101.
- Ítalo Flexa Di Paolo,Adriana Rosa Garcez Castro.Intra- and Interpatient ECG Heartbeat Classification Based on Multimodal Convolutional Neural Networks with an Adaptive Attention Mechanism[J].Applied Sciences,2024,14(20):9307-9307.
- Peimankar A ,Ebrahimi A ,Wiil K U .xECG-Beats: an explainable deep transfer learning approach for ECG-based heartbeat classification[J].Network Modeling Analysis in Health Informatics and Bioinformatics,2024,13(1):45-45.
致 谢
首先,我要向我的导师致以诚挚的感谢,感谢您在我整个项目开发过程中给予的指导和帮助。从最初的课题选择到项目的每一个关键环节,您的宝贵意见和耐心指点让我受益匪浅,使我得以顺利完成本次毕业设计。
同时,我也要感谢我的同学和朋友们,他们在我遇到问题时给予了我很多建议和支持。无论是在技术探讨上还是项目推进的过程中,他们的鼓励和帮助让我保持了动力,并不断克服难题。
此外,还要特别感谢我的家人,在整个项目开发和论文撰写过程中,家人们的理解和支持给了我坚持下去的力量。他们为我提供了一个安静且舒适的学习环境,让我可以全身心投入到本次毕业设计中。
最后,我要感谢所有曾经为计算机视觉领域和AI作出贡献的学者和研究人员,正是他们的研究成果为我的项目提供了宝贵的参考和灵感。感谢各类开源社区和工具的开发者,他们的技术分享让我在项目开发中得以顺利进行。
谢谢大家的帮助与支持!