A367-基于 Boss 直聘大数据的岗位分析与智能就业服务研究

技术文档
一、项目概述
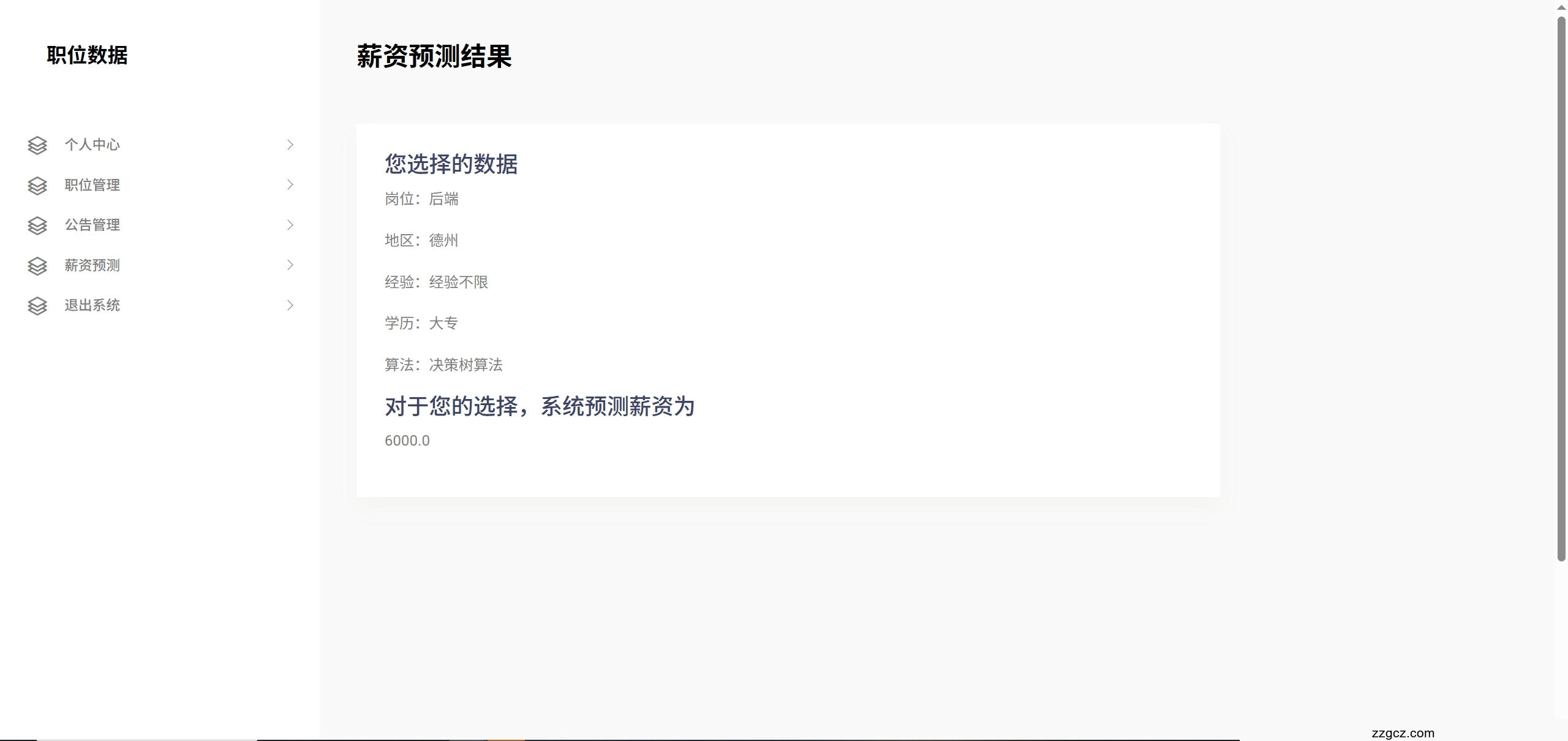
本系统旨在基于岗位招聘数据,结合用户输入的基本条件(如岗位名称、工作城市、工作经验、学历),预测其对应的市场月薪水平。系统实现了两种机器学习模型(K-近邻模型与决策树回归模型)的并行预测,并返回薪资估计结果。
二、系统架构
pgsql
CopyEdit
+--------------------+
| 用户输入条件 |
| - area |
| - experience |
| - record |
| - position |
+--------------------+
↓
+--------------------+
| 数据清洗与编码 |
| - 缺失值填充 |
| - 类别数值化 |
| - 特征映射构建 |
+--------------------+
↓
+-------------------------------+
| 模型1:KNN分类器 |
| 模型2:决策树回归器 |
| - 使用训练集拟合 |
| - 使用预测样本推断月薪 |
+-------------------------------+
↓
+--------------------+
| 输出预测薪资(单位:千元) |
+--------------------+
三、数据来源
*
数据源:招聘数据(本地CSV文件data2.csv,亦可替换为MySQL数据库读取)
*
*
字段示例:area(城市)、experience(经验)、record(学历)、position(岗位)、yuexin(月薪)
*
四、数据预处理
- 特征选择
输入特征字段:
area:工作城市(如北京、上海)
experience:经验要求(如“无需经验”、“1-3年”)
record:学历(如“本科”、“大专”)
position:岗位名称(如“数据分析师”、“测试工程师”)
输出字段:
yuexin:薪资字段(取招聘月薪中最低档,单位为千元)
- 数据清洗步骤
-
缺失值填充:统一填充为“未知”
薪资字段清洗
原始格式如:“8-10千/月”
提取最低值(“8”)并转换为整数(8)
重复值剔除:drop_duplicates()
分类变量编码:
将每一列的类别值映射为唯一整数编码(如:北京→0,上海→1)
五、模型设计与实现
- KNN 模型(K-Nearest Neighbors)
-
模型类型:KNeighborsClassifier
目标:将类别标签 yuexin(数值)作为分类目标进行预测
邻居数(K值):8
训练集划分:99%训练集,1%测试集
预测过程:
对用户输入的条件进行相同的映射编码
使用 .predict() 返回预测类别(即薪资区间)
- 决策树模型(Decision Tree)
模型类型:DecisionTreeRegressor
目标:对连续薪资数值进行回归预
训练集划分:99%训练集,1%测试集
预测过程
同样使用统一映射处理输入
调用 .predict() 返回精确数值型月薪预测(浮点数)
*
六、预测接口设计
def yuceact(position, area, experience, record):
# 构造输入字典
tiaojian = {
'position': position,
'area': area,
'experience': experience,
'record': record
}
# KNN预测
xinzi_knn = knnyuce(tiaojian)
# 决策树预测
xinzi_tree = jueceshhuyuece(tiaojian)
return {
'knn': xinzi_knn,
'decision_tree': xinzi_tree
}
调用示例:
yuceact(
position='产业规划策划师',
area='北京',
experience='无需经验',
record='本科'
)
输出示例:
KNN预测结果: 月薪 8 万决策树预测结果: 月薪 8.7 万
七、核心依赖环境
| 名称 | 版本要求 |
|---|---|
| Python | 3.7+ |
| pandas | >=1.0 |
| numpy | >=1.18 |
| scikit-learn | >=0.24 |
| pymysql | 用于数据库读取 |
| joblib | 用于模型持久化(可选) |