A374-基于bert的细粒度中文仇恨识别评测的ner模型
【购买前必看】
1、关于我们
深度学习乐园是由python哥全职技术团队组建运营【团队成员为:复旦大学博士、华东理工爱丁堡博士、格拉斯哥博士、纽约大学硕士、浙江大学硕士】。
我们只做python业务,精通sklearn机器学习/torch深度学习/django/flask/vue全栈开发。
2、关于项目
我们从2018年开始,就专注于深度学习sci、ei、ccf、kaggle等,至今已有7年,共发表过10多篇顶刊顶会。
官网累积了数百个项目,已有3000多学员付费购买,圈子内有口皆碑:www.zzgcz.com (更多高级私密项目无法对外,联系微信定制:zzgcz_com)
3、售后承诺
包远程安装调试,所有项目均在本地运行通过,大部分都有截图和录屏。
支持二次修改,所有项目都是我们自己写的,改起来也非常容易。
加急定制1-2天可完成,这就是实力证明,远程验收满意后再付全款!
所有客户终身售后。兼职的人家都有主业,谁愿意持续服务你?
CCL25-Eval 任务10:细粒度中文仇恨识别评测
任务内容
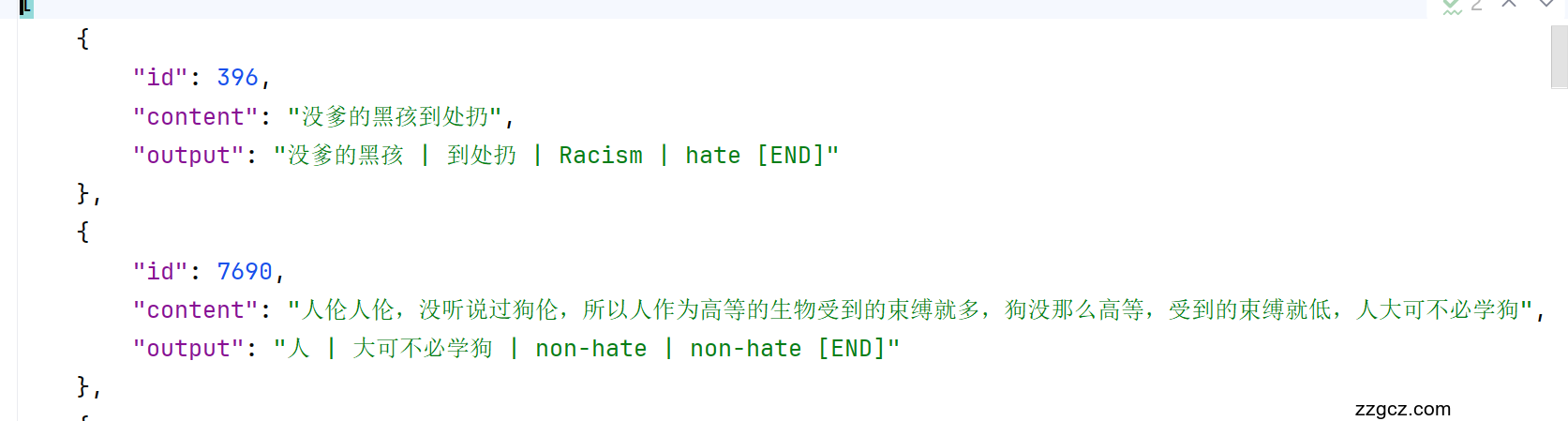
本次评测任务为细粒度片段级中文仇恨言论识别,基于给定的文本,任务的输入为社交媒体文本,输出为仇恨四元组,顺序依次为评论对象(Target)、论点(Argument)、目标群体(Targeted Group)、是否仇恨(Hateful)。具体说明如下:
评论对象(Target):帖子的评述对象,如一个人或一个群体。当实例无具体目标时设为NULL。
论点(Argument):包含对评论目标关键论点的信息片段。
目标群体(Targeted Group):指包含仇恨信息的评论对象-论点对涉及的目标群体。标注的目标群体包括“地域”、“种族”、“性别”、“LGBTQ”、“其他”共5类。如样例1中包含了对LGBTQ群体和艾滋病群体的仇恨信息。
是否仇恨(Hateful):评论对象-论点对是否构成了对某些群体的仇恨言论。
对于非仇恨文本和不包含特定群体的一般攻击性言论,同样需要对目标群体和观点进行抽取,并设为Non-hate。由于样本中可能有多个评论对象,因此可以包含多个四元组。 每个四元组中各个元素之间用" | "分割,并利用 [END] 结尾;如果一条样本中包含多个四元组,不同四元组之间利用 [SEP] 分割。请严格按照顺序和格式提交,不要省略空格,以免影响成绩。
下面提供两个数据样例:
输入: 你可真是头蠢驴,这都做不好。
输出: 你 | 蠢驴 | non-hate | non-hate [END]
输入: 老黑我是真的讨厌,媚黑的还倒贴。
输出: 老黑 | 讨厌 | Racism | hate [SEP] 媚黑的 | 倒贴 | Racism | hate [END]
将模型对测试集的输出内容按行保存到.txt文件中,如demo.txt文件。
本次评测鼓励参赛者充分发挥开源闭源大模型的能力来解决任务,同时也欢迎基于小模型进行建模。
评测数据
本次评测使用的中文仇恨言论四元组抽取数据集收集了贴吧、知乎等国内社交媒体平台的用户评论数据,为每条样本提供了高质量的二元分类标签,并对句子中的评论对象、论点和目标群体进行片段级标注。该数据集总计8000条中文数据,其中仇恨言论为4935,非仇恨言论为3065条。每条语句均包含一个或多个中文仇恨言论四元组,共计9405个,其中仇恨四元组5949个,非仇恨四元组3456个。
报告
一、引言
随着互联网和社交媒体的迅猛发展,网络言论自由与言论规范之间的冲突愈加明显。尤其是仇恨言论(Hate Speech)传播的广泛性和匿名性带来的社会负面影响已经成为全球关注的焦点。因此,构建有效的仇恨言论识别系统,自动化地从海量文本中定位仇恨言论、辨别其针对的具体群体,并确定仇恨言论的类型,对于维护网络空间的和谐具有重要现实意义。
二、任务背景
2.1 任务描述
本项目解决的问题为一个复杂的多任务学习任务,具体涉及以下三个子任务:
-
命名实体识别(NER):识别仇恨言论文本中的特定目标(TARGET)及论据(ARG),并以实体标注的方式进行。
-
群体多标签分类:确定仇恨言论所针对的群体类别,如性别、种族、地域、LGBTQ群体等。
-
仇恨言论二分类:判断给定文本是否为仇恨言论。
2.2 数据说明
本项目使用的数据集采用JSON格式,每条数据均包含文本内容(content)和相应的输出(output)。输出中明确包含了仇恨言论识别相关的标注信息,即目标实体、论据实体、群体标签及仇恨言论判别标签,使用特定符号(如"|"、"[SEP]"、"[END]")进行标注分割。
三、算法实现
3.1 模型结构
本项目基于预训练语言模型BERT实现多任务学习结构,具体采用的是hfl团队的chinese-roberta-wwm-ext模型,以此为基础进行微调,实现对NER、群体多标签和仇恨言论分类任务的统一处理。
具体任务实现方法如下:
-
NER任务:利用序列标注的策略,模型输出每个token的类别标签。
-
群体多标签分类任务:基于BERT模型的CLS向量输出一个多标签分类器。
-
仇恨言论分类任务:同样基于CLS向量输出二分类的logit值。
3.2 数据预处理
数据预处理分为以下几个重要环节:
-
字符级NER标签标注:原始文本中的目标和论据实体在字符级别进行标注,然后再通过tokenizer的offset_mapping机制对齐到token级别标签。
-
群体标签向量化:将数据中的群体标注转化为多标签one-hot编码。
-
文本截断与填充:通过tokenizer统一将文本填充或截断至最大长度(128)。
3.3 数据加载
本项目使用PyTorch框架提供的Dataset和DataLoader类加载和处理数据:
-
HateSpeechDataset类负责数据的读取、解析和预处理。
-
Dataset类方法__getitem__提供每个数据样本的信息,包括input_ids、attention_mask、ner_labels、group_labels和hate_label。
3.4 损失函数与训练策略
多任务联合训练中,不同任务采用不同的损失函数:
-
NER任务采用交叉熵损失(CrossEntropyLoss),忽略padding位置(标记为-100)。
-
群体多标签分类任务使用二元交叉熵损失(BCEWithLogitsLoss)。
-
仇恨言论分类同样使用二元交叉熵损失(BCEWithLogitsLoss)。
整体训练策略为联合优化,三种损失求和作为总损失进行梯度反向传播。
四、训练参数与策略
4.1 参数设定
主要参数包括:
-
学习率:3e-5。
-
批次大小:16。
-
Epoch数量:20。
-
优化器:AdamW,适合微调大型预训练语言模型。
4.2 模型优化与正则化
为防止过拟合,模型结构中引入了Dropout层,dropout比例设定为0.1。
五、实验过程
训练过程遵循以下步骤:
-
每个epoch进行批量训练。
-
监测并记录每个epoch的平均损失值。
-
若损失不稳定或出现梯度爆炸现象,则可进一步采取梯度裁剪(gradient clipping)策略。
六、模型评估(补充建议)
建议补充模型在验证或测试集上的评估。
-
NER任务评估可采用Precision、Recall及F1-score。
-
群体多标签分类可使用ROC曲线及AUC值。
-
仇恨言论分类任务可以通过准确率、精确率、召回率及F1分数进行全面评估。
七、讨论与改进方向
项目实现过程可能存在以下问题和改进空间:
-
NER任务可能出现实体标注的边界错误或重叠,后续可使用CRF(条件随机场)模型优化。
-
多任务学习中可能存在任务之间的相互干扰,后续可考虑增加损失权重调节参数或更复杂的动态损失权重调节策略。
-
模型的泛化能力仍需提升,可尝试数据增强技术(如回译、随机mask、同义词替换)增强模型的鲁棒性。
八、总结
本项目实现了基于BERT的多任务联合仇恨言论识别模型,成功地融合了命名实体识别、群体多标签分类与仇恨言论分类任务。通过精心的模型设计和合理的训练策略,模型能够有效地在多维度识别仇恨言论,有助于网络环境的净化。
九、附录:代码说明
-
BertForMultiTask类:包含了BERT基础模型及针对不同任务的三个线性分类器模块。
-
HateSpeechDataset类:实现了数据的载入、处理及批次的生成。
-
train函数:定义训练单个epoch的逻辑,返回epoch内的平均损失值。
安装
python3.11.9
pip install torch==2.4.1 --index-url https://download.pytorch.org/whl/cu121
pip install -r requirements.txt
预测结果:
